1. 存储引擎
MySQL 中特有的术语。
(Oracle 有,但不叫这个名字)
是一种表存储 / 组织数据的方式
不同的存储引擎,表存储数据的方式不同
1.1 查看存储引擎
命令: show engines \g(或大写:G)
support 为 yes 即支持存储引擎
default 即不指定情况下默认为存储引擎
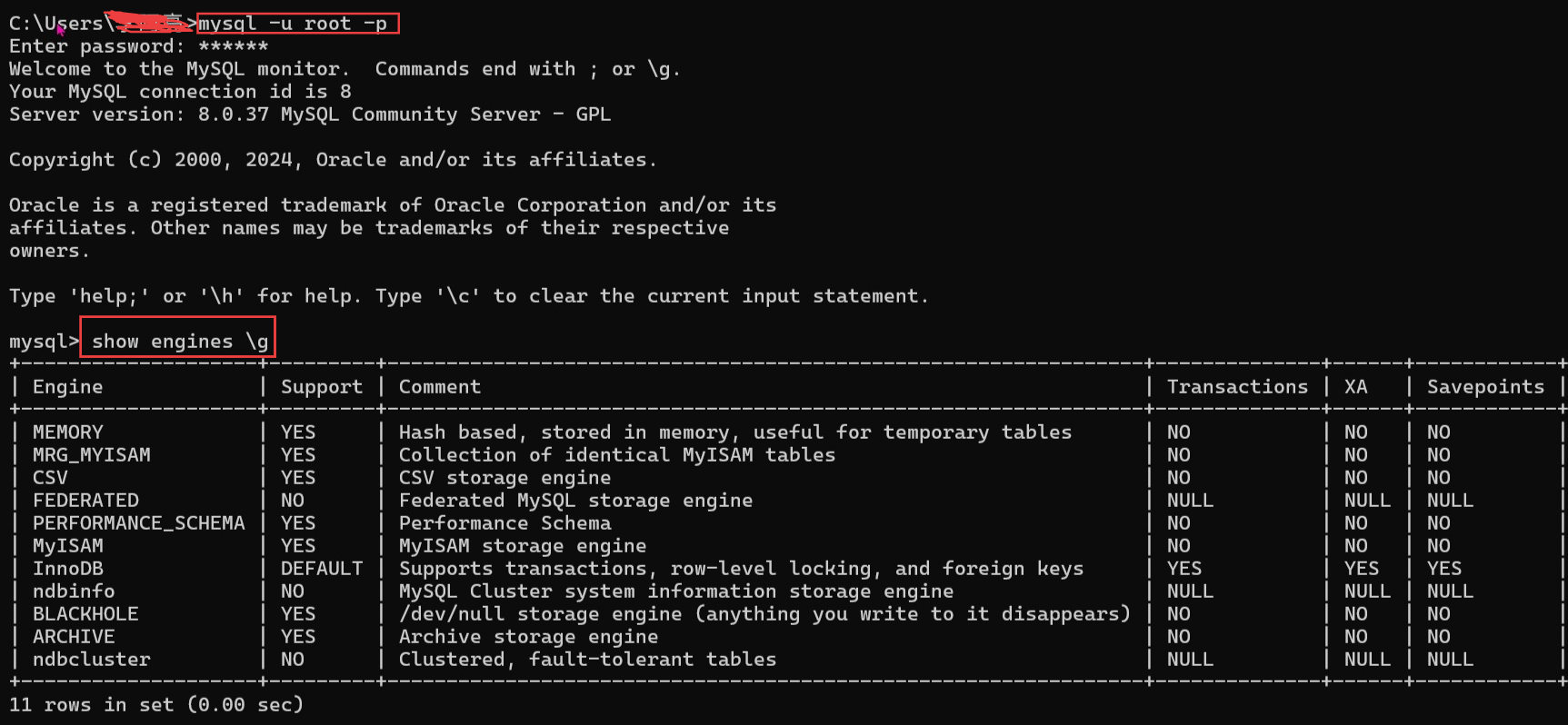
不同版本支持的存储引擎不同。
1.2 常用存储引擎
1.2.1 MyISAM
管理的表具有以下特征:
使用三个文件表示每个表:
格式文件:存储表结构的定义(mytable.frm)
数据文件:存储表行的内容(mytable.MYD)
索引文件:存储表上的索引(mytable.MYI)
(索引:类似于书的目录,可缩小扫描范围,提高检索效率。
只要是主键,或带有 unique 约束的字段,会自动创建索引)
特点:可被转换为压缩,只读表来节省空间;
不支持事务机制,安全性低;
1.2.2 InnoDB
MySQL 的默认存储引擎,同样是一个重量级的存储引擎
支持事务,支持数据库崩溃后自动恢复机制
支持多版本(MCVV)和 行级锁定
特点:支持事务,以保证数据的安全;
效率不高,不能压缩或转换为只读,不能很好的节省存储空间
1.2.3 MEMORY
数据存储在内存中,且行的长度固定
表的数据及索引被存储在内存中
(内存是直接取得,硬盘是机械行为)
特点:查询效率最高,不需要和硬盘交互
不安全,关机之后数据消失。数据和索引都在内存当中
2. 事务(transaction)
2.1 概述
一个事务就是一个完整的业务逻辑,是一个最小的工作单元,不能再分。
要么同时成功,要么同时失败;
只有 DML(增删改:insert,delete,update) 语句才会有事务一说,其他语句和事务无关;
因此,只要操作一旦涉及数据的增,删,改,那么一定要考虑安全问题
一个事务本质上就是多条 DML 语句同时成功或同时失败
2.2 原理
事务开启:
insert insert delete delete update update
事务结束!
InnoDB存储引擎:提供一组用来记录事务性活动的日志文件
事物的执行过程中,每一条 DML 的操作都会记录到 “ 事务性活动的日志文件 ” 中
且事物的执行过程中,可以提交事务,也可以回滚事务;
提交事务:清空事务性活动的日志文件,将数据全部彻底持久化到数据库表中。
标志着事务全部成功的结束,
回滚事务:将之前所有的 DML 操作全部撤销,并清空事务性活动的日志文件。
标志着事务全部失败的结束。
2.3 提交/回滚
提交:commit
回滚:rollback(回滚永远只能回滚到上一次的提交点!)
MySQL 默认支持自动提交事务:每执行一条 DML 语句,就提交一次
自动提交不符合开发习惯。一个业务通常需要多个 DML 语句 共同执行才能完成。为了保证数据的安全,必须要求同时成功之后再提交,所以不能执行一条就提交一条。
关闭自动提交:start transaction
2.4 ACID 特性
A:原子性
事务是最小的工作单元,不可再分。
C:一致性
同一个事务中,所有的操作必须同时成功,或者同时失败,以保证数据的一致性。
I:隔离性
A 事务与 B 事务之间有一定的隔离
D:持久性
事务提交,相当于将没有保存到硬盘的数据保存到硬盘上
2.4.1 隔离性
好比学生时代,教室与教室之间通过一堵墙隔离开;
事务与事务之间的“墙”有厚薄之分;
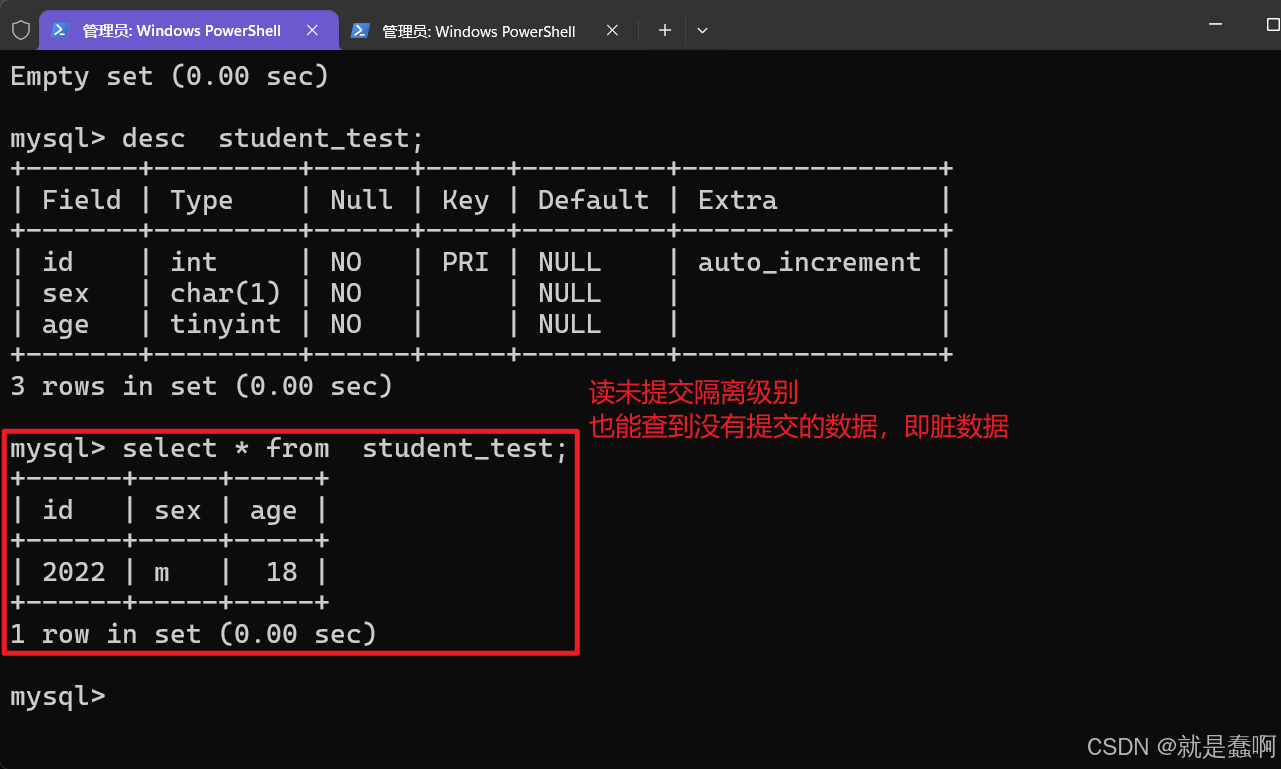
读未提交(read uncommitted):最低隔离级别。【没有提交就读到了】
事务 A 可以读取到事务 B 未提交的数据。即脏读(Dirty Read)现象
这种隔离级别一般都是理论上的,大多数数据库隔离级别二档起步
读已提交(read committed):【提交之后才能读到】
事务 A 只能读取到事务 B 提交之后的数据
优点:解决了脏读的现象
缺点:不可重复读取数据:事务A开启之后,读到了3条数据,同时事务B在不断提交数据。当前事务还没有结束,第二次读取的时候,读到的数据是4条。
可重复读(repeatable read):【MySQL 默认事务隔离级别】【提交之后也读不到,永远读取的都是刚开启事务时的数据】
事务 A 开启之后,不管多久,每一次在事务 A 中读取到的数据都是一致的。
即使事务 B 已经将数据修改并提交,事务 A 读取到的数据还是没有发生改变。
优点:解决了不可重复读取数据
缺点:会出现幻影读,每一次读取到的数据都是幻想,不够真实。
序列化 / 串行化(serializable):最高隔离级别
效率最低,解决了所有的问题
这种隔离级别表示事务排队,不能并发
2.4.2 隔离级别演示
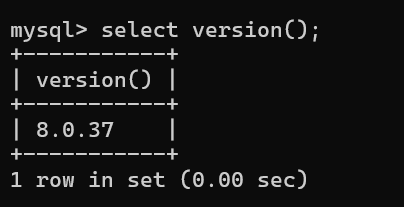
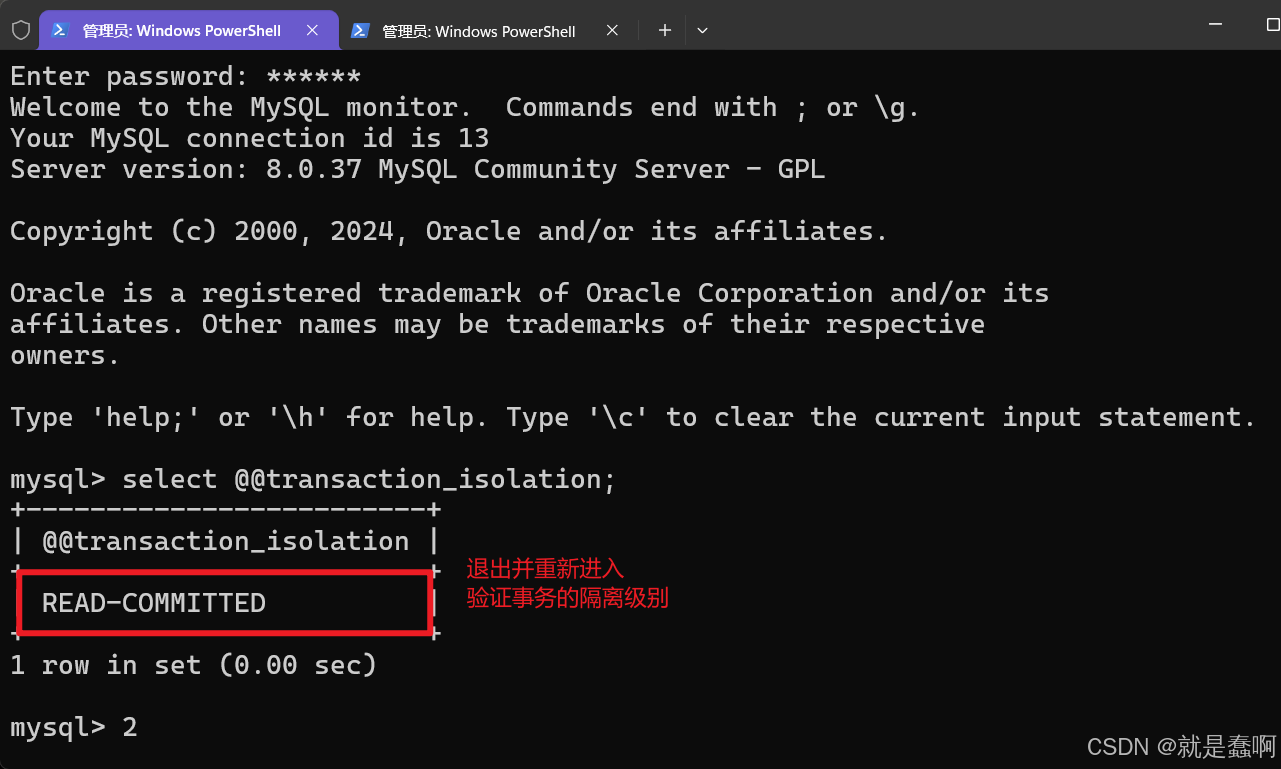
查看隔离级别: select @@transaction_isolation;
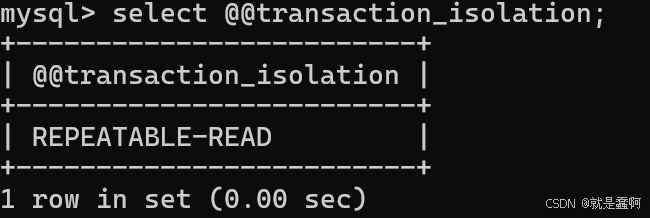
修改事务隔离级别:set global transaction isolation level xxxxxx;
(1)验证 :read uncommitted
设置 MySQL 隔离级别: set global transaction isolation level read uncommitted;

退出并重新进入,验证隔离级别是否设置正确;
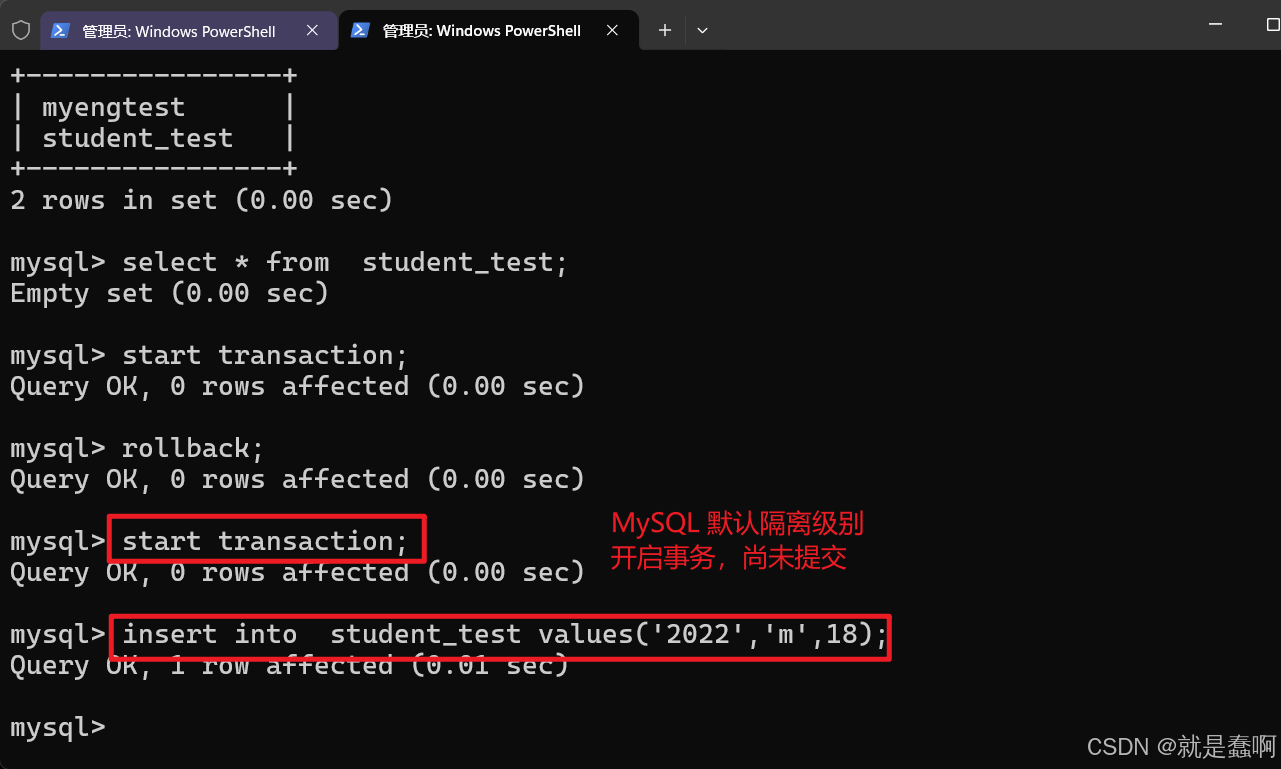
右侧窗口开启事务,插入数据,左侧窗口 MySQL 的隔离级别已经被修改为 读未提交。
所以右侧窗口的事务还没有提交,左侧就可以读取到;
即没有提交就读到了,这就是 读未提交;
(2)验证:read committed
设置左侧窗口 事务隔离级别: set global transaction isolation level read uncommitted;
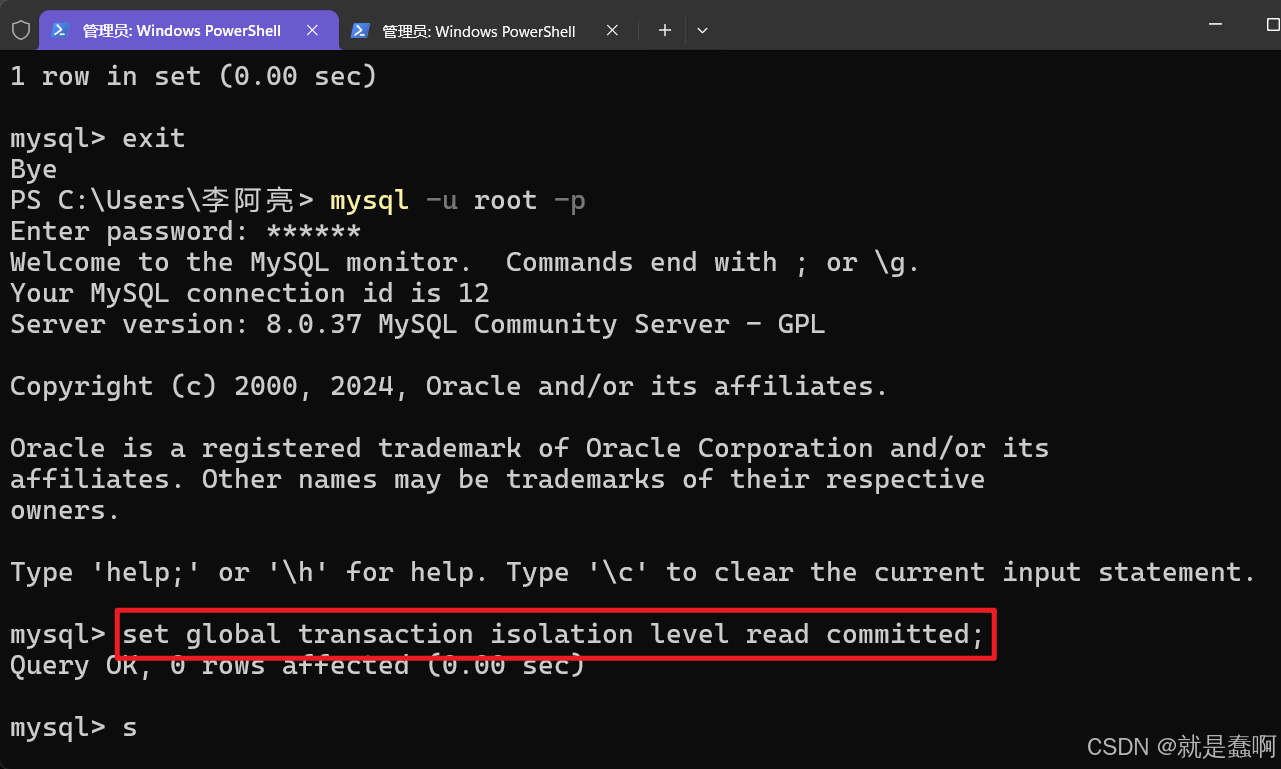
开启一个事务,插入一条数据,不提交,在左侧窗口设置的 读已提交的数据库中,没有查询到新插入的数据;
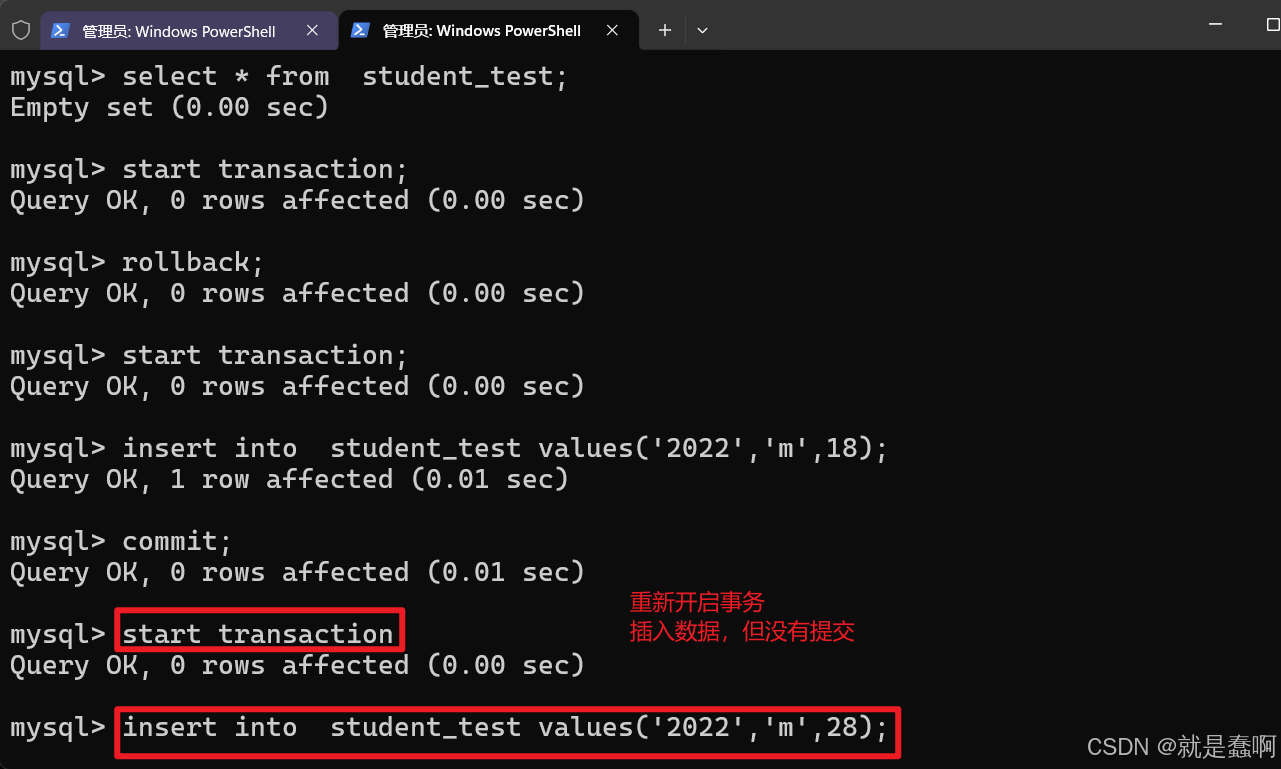
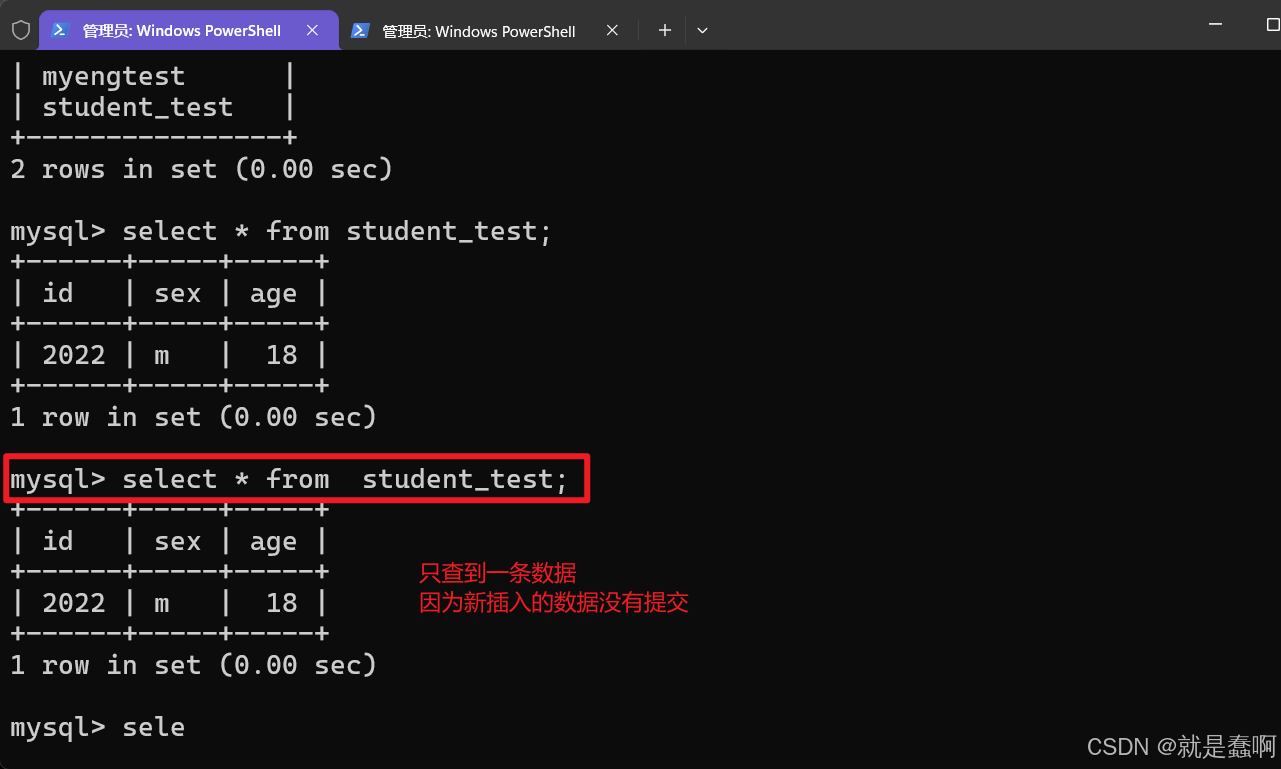
右侧窗口中的事务提交后,左侧窗口才能查询到。
这就是提交之后才能读取到的 读已提交事务隔离机制;
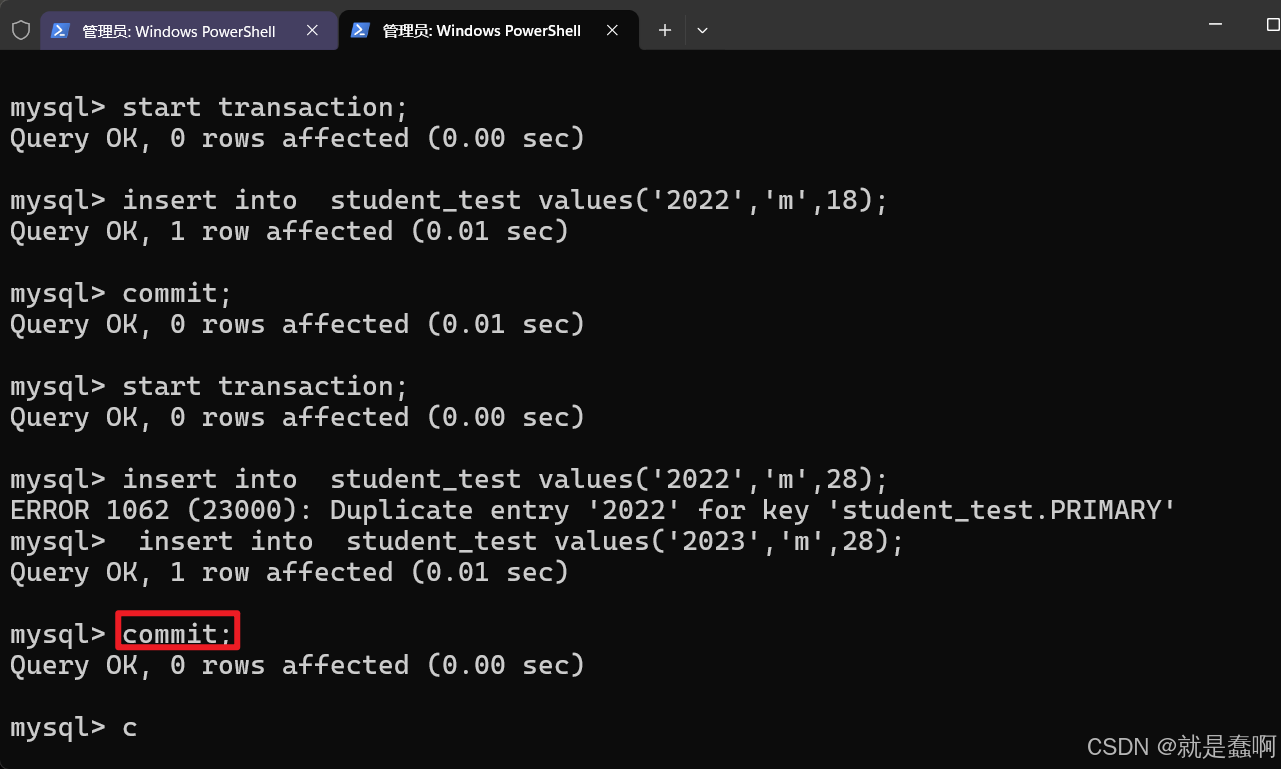
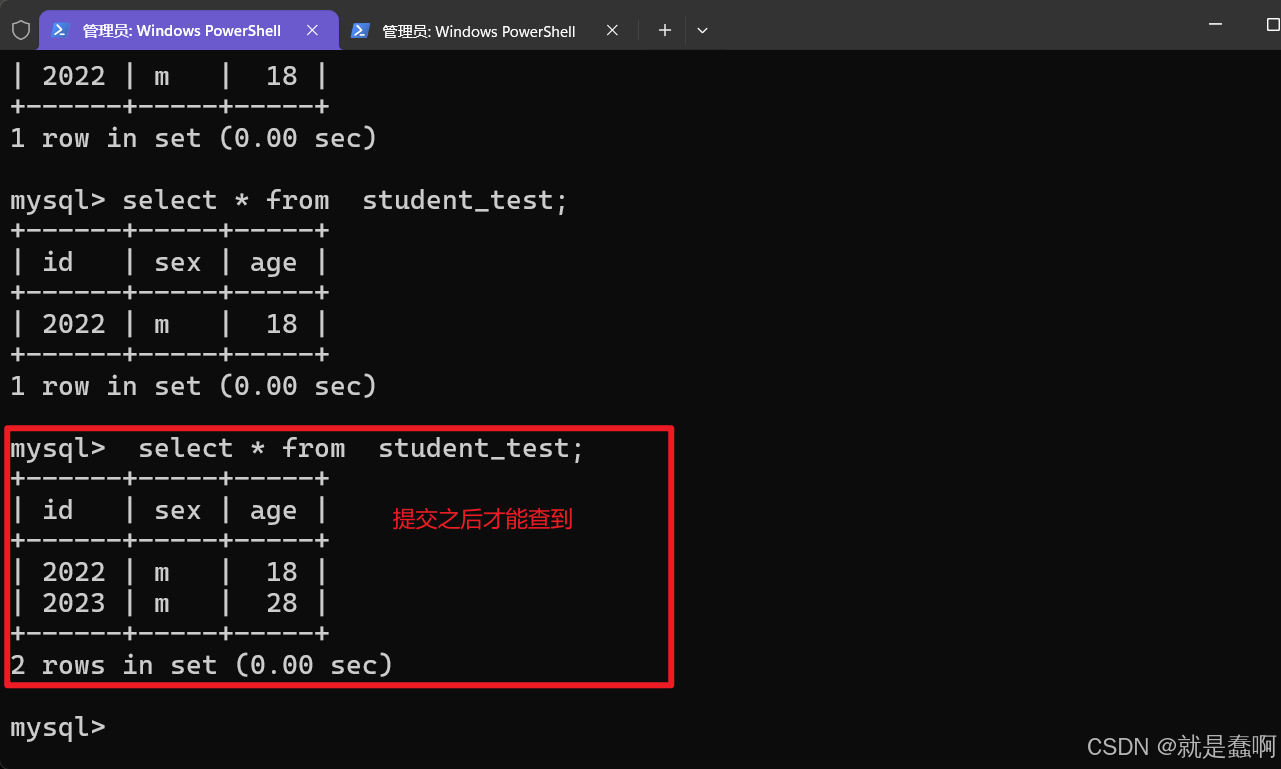
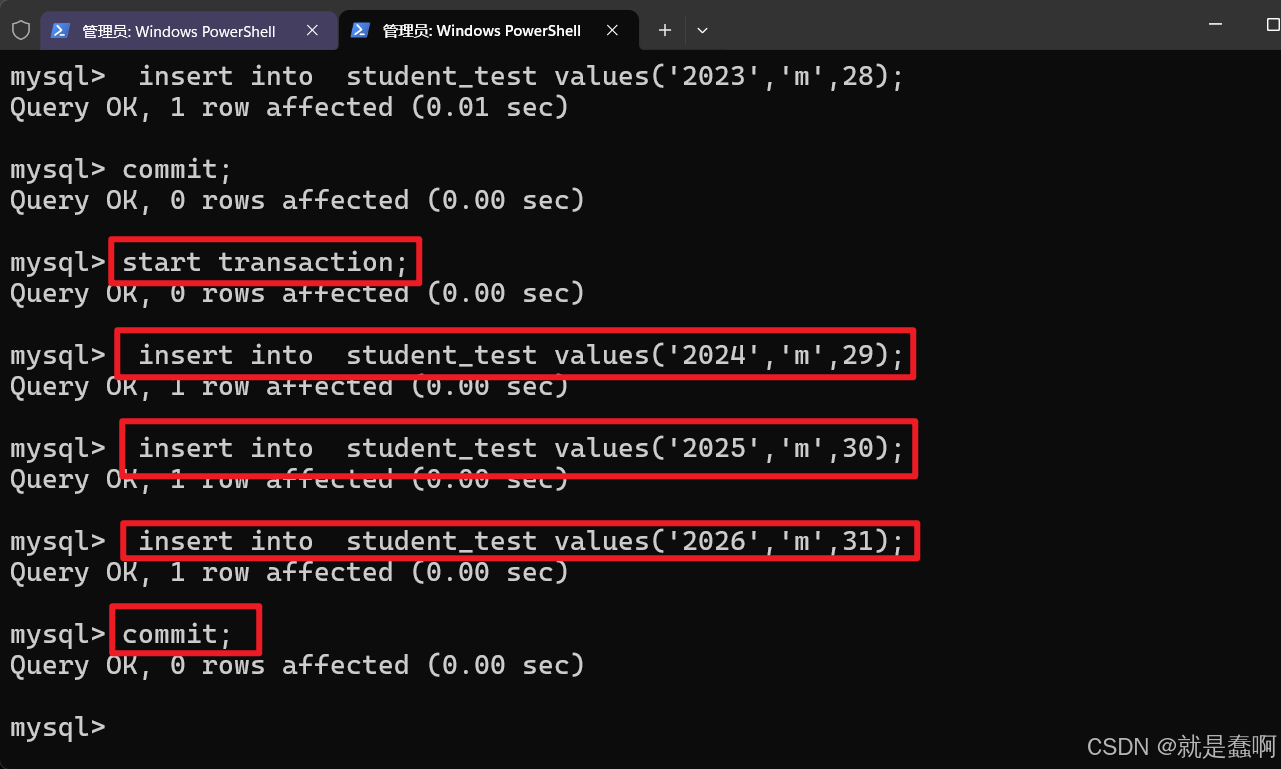
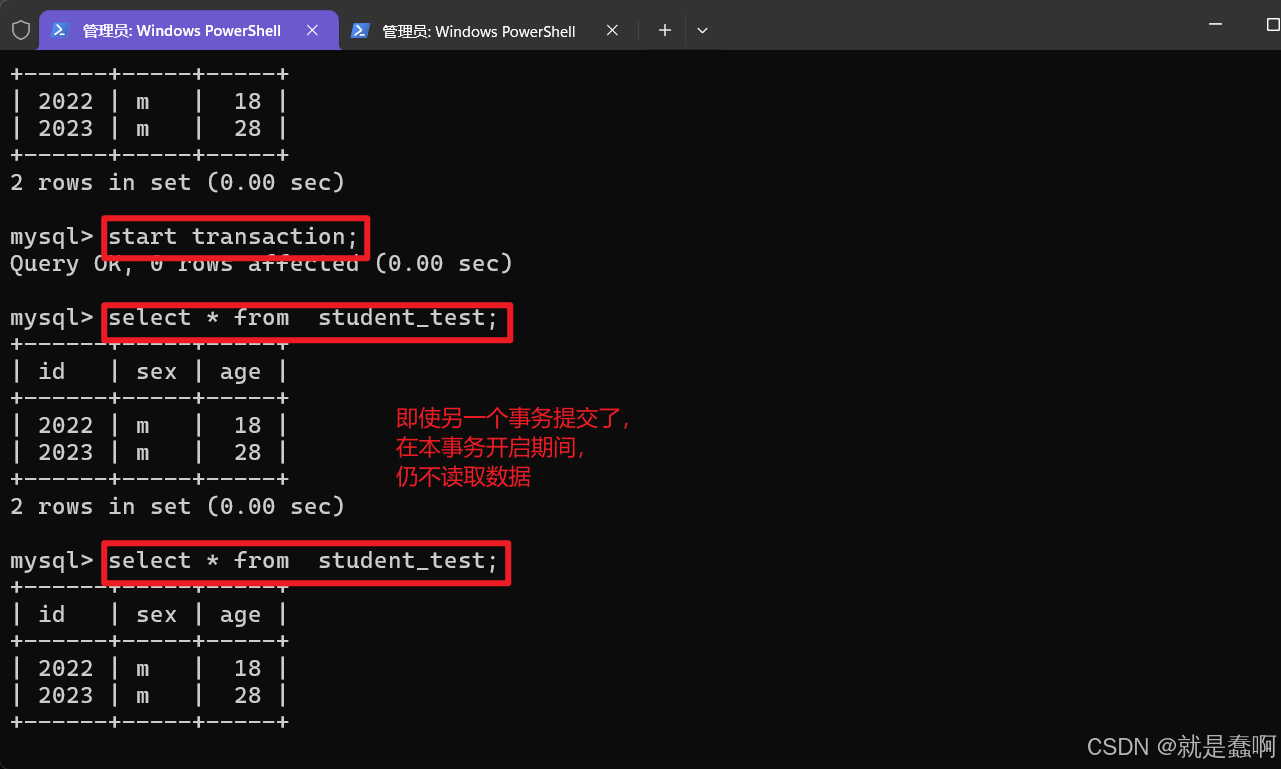
(3)验证:repeatable read
设置左侧窗口 事务隔离级别: set global transaction isolation level repeatable read;
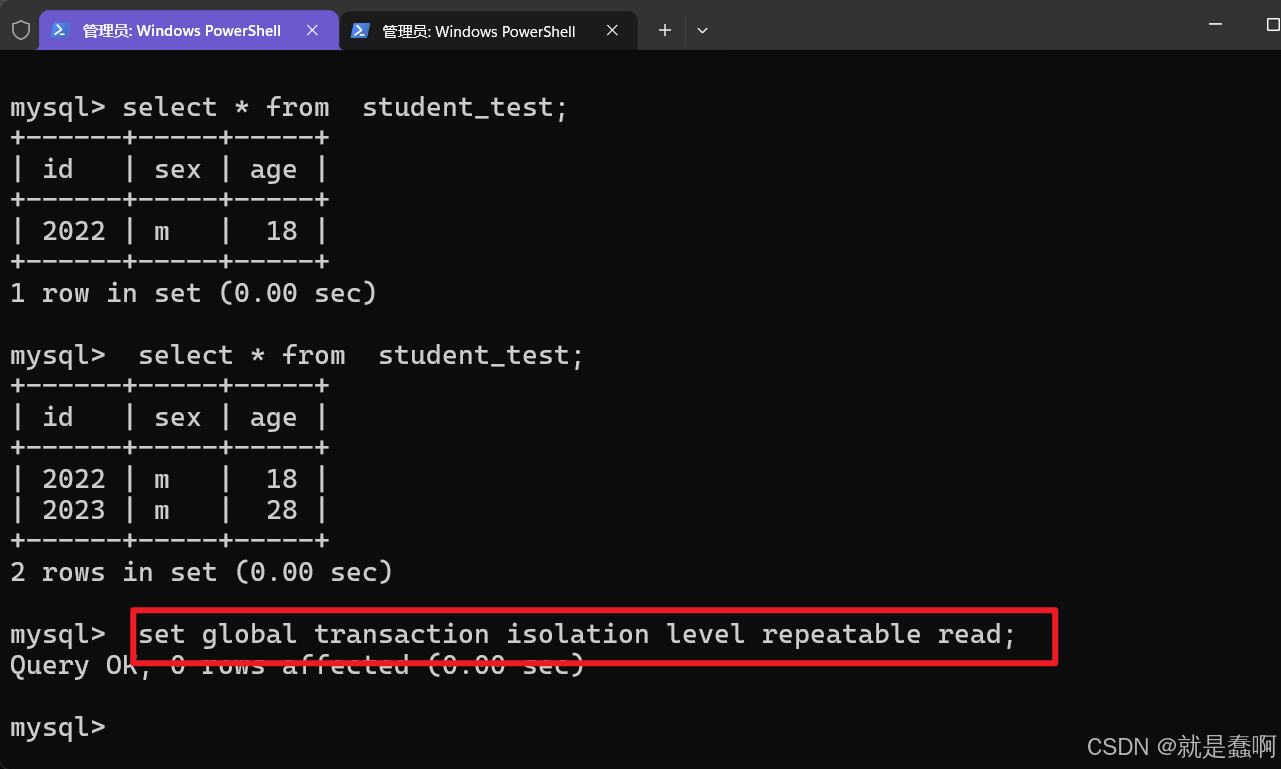
右侧窗口开启事务并插入数据,最后提交。
左侧窗口在本事务开启期间,没有”刷新“数据
这就是提交之后也读不到,永远读取的都是刚开启事务时的数据 的可重复读事务机制
(4)验证:serializable
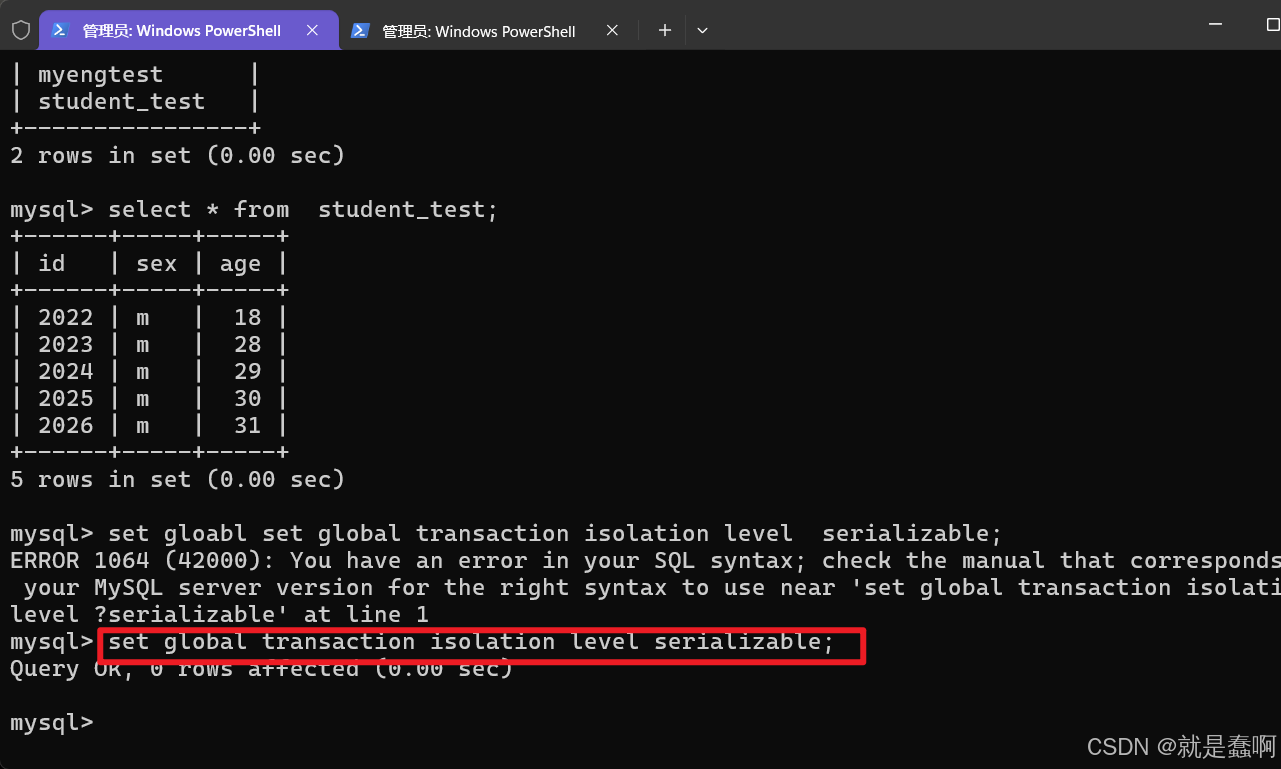
设置左侧窗口 事务隔离级别: set global transaction isolation level serializable;
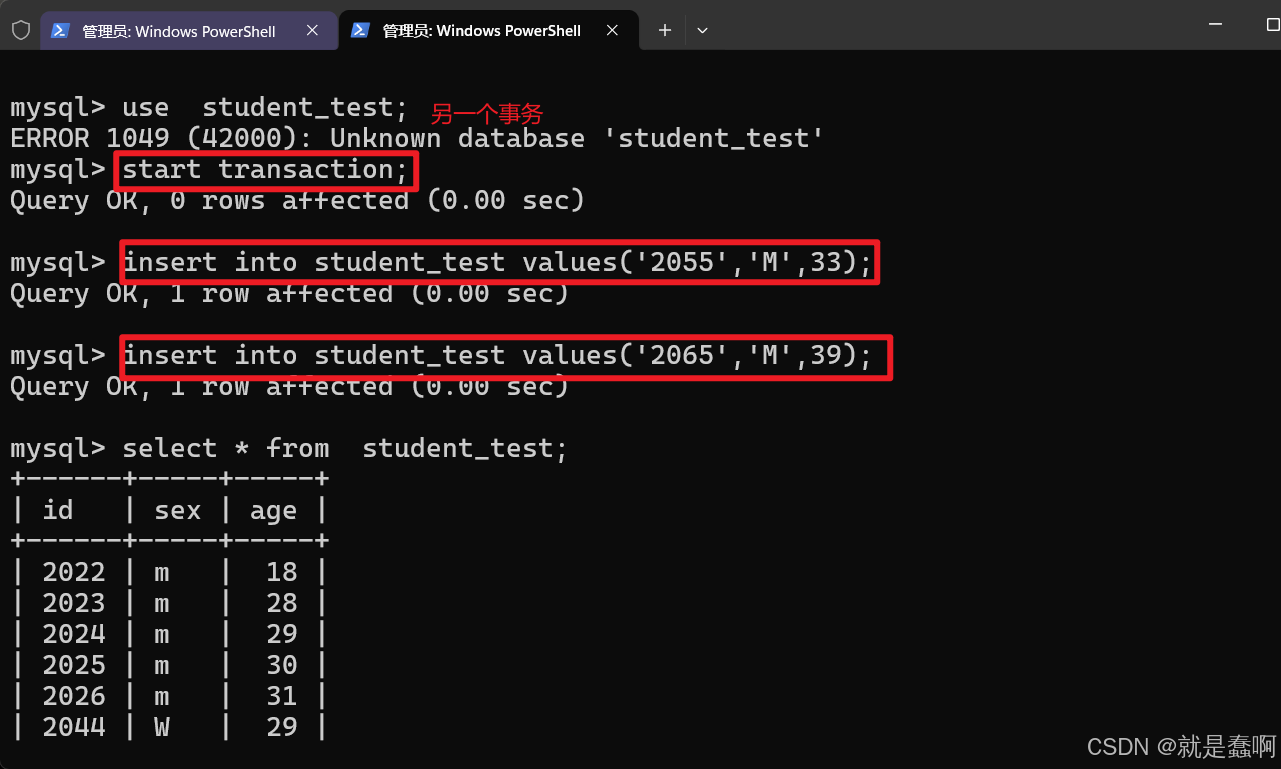
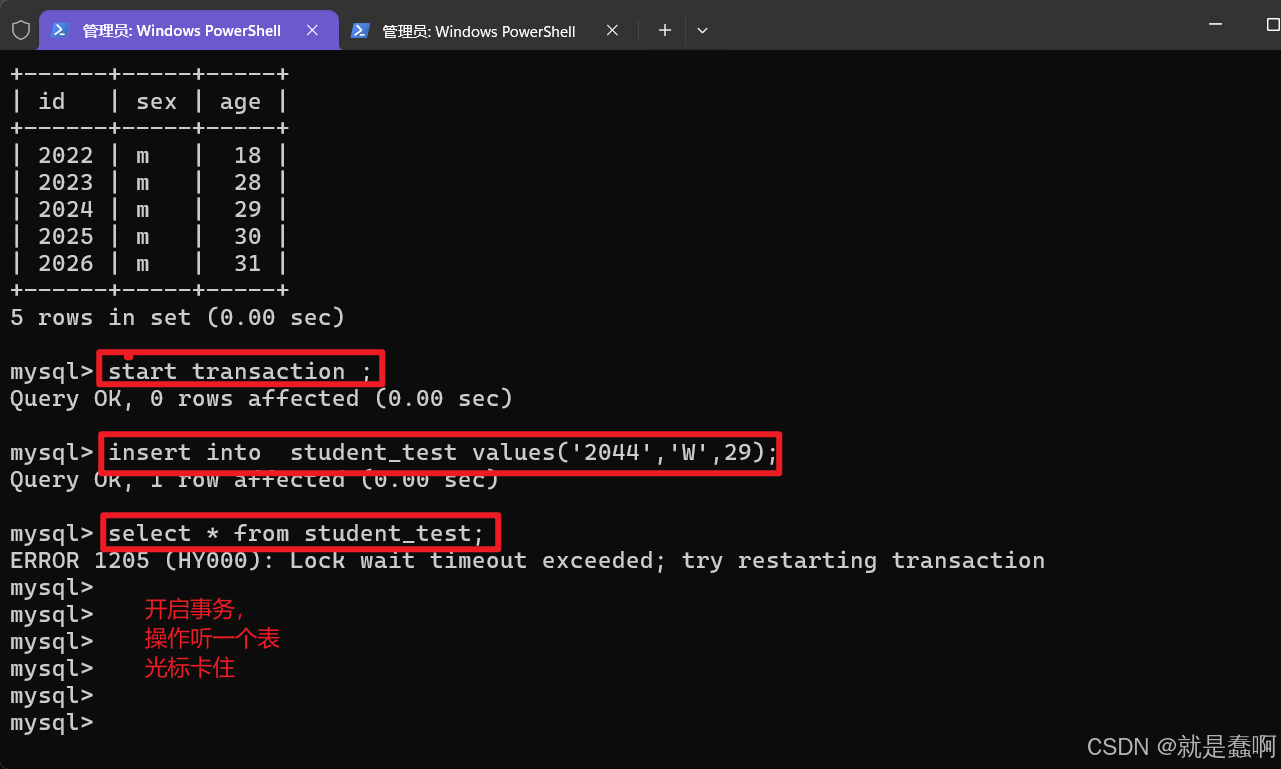
右侧与左侧窗口都开启一个事务,操作同一张表
光标会卡住
这就是事务排队,不能并发 的序列化事务机制
3. 索引(index)
3.1 概述
索引是一种提高查询效率的机制,相当于一本书的目录,为了缩小扫描范围而存在;
索引添加在数据库表的字段上,多个字段联合起来也可以添加索引;
3.2 查询
MySQL 在查询方面主要有两种方式:全表扫描;根据索引检索;
例如:select * from test where name = 'zhangsan'
如果没有给 name 字段添加/创建索引,MySQL 会进行全扫描,将 name 字段的每一个值都比对一遍,效率比较低。
3.3 排序
汉语字典的目录按照 ” a-b-c... “ 排序,MySQL 的目录 / 索引 也需要排序
索引的排序与 TreeSet(TreeMap) 相同,底层是一个自平衡的二叉树。
MySQL 当中,索引是一个 B-Tree 数据结构;
遵循左小右大原则存放,采用中序遍历获取数据;
3.4 原理
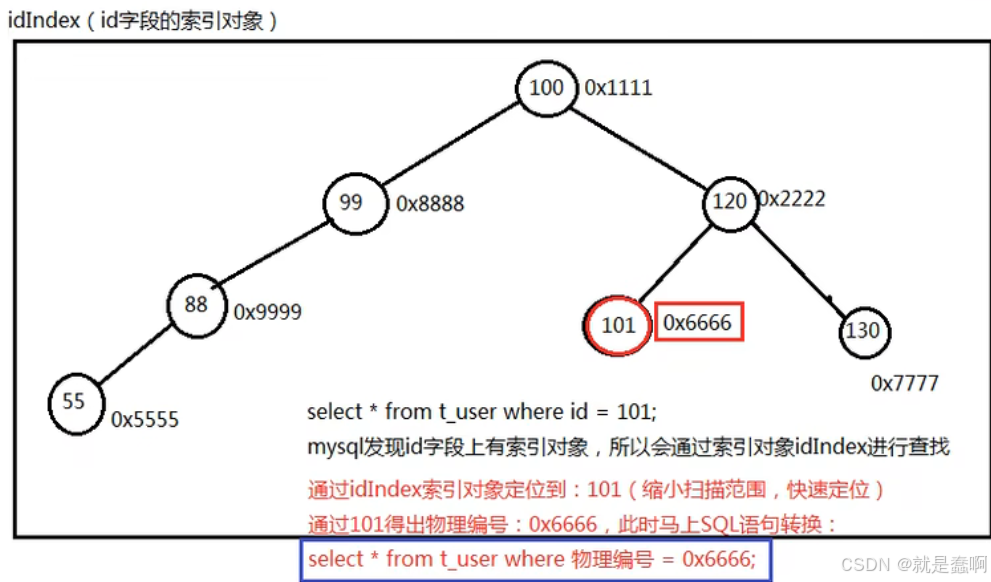
任何数据库当中主键都会自动添加索引对象,若字段被 unique 约束,也会自动创建索引对象
任何数据库当中,任何一张表的任何一条记录在硬盘存储上都有一个硬盘的物理存储编号;
MySQL 当中,索引是一个单独的对象;
不同的存储引擎中索引以不同的形式存在,:
MyISAM 存储引擎中,索引存储在一个 .MYI 文件中
InnoDB 存储引擎中,索引存储在一个逻辑名称叫做 tablespace 当中
MEMORY 存储引擎中,索引存储在内存当中

3.5 条件
不要随意添加索引,索引需要不断维护,太多反而会降低系统性能
以下是添加索引的条件:
1. 数据量庞大(每个硬件环境不同,庞大的标准也不同)
2. 该字段经常出现在 where 的后面,以条件的形式存在
3. 该字段很少的 DML 操作(DML 后,索引需要重新排序)
数据库优化后,对于速度的提升不是一星半点,可能是成千上万倍;
建议通过主键或者通过 unique 约束的字段进行查询,效率较高;
3.6 创建/删除索引
创建索引:create index 索引名称 on 表名(字段名)
删除索引:drop index 索引名称 on 表名
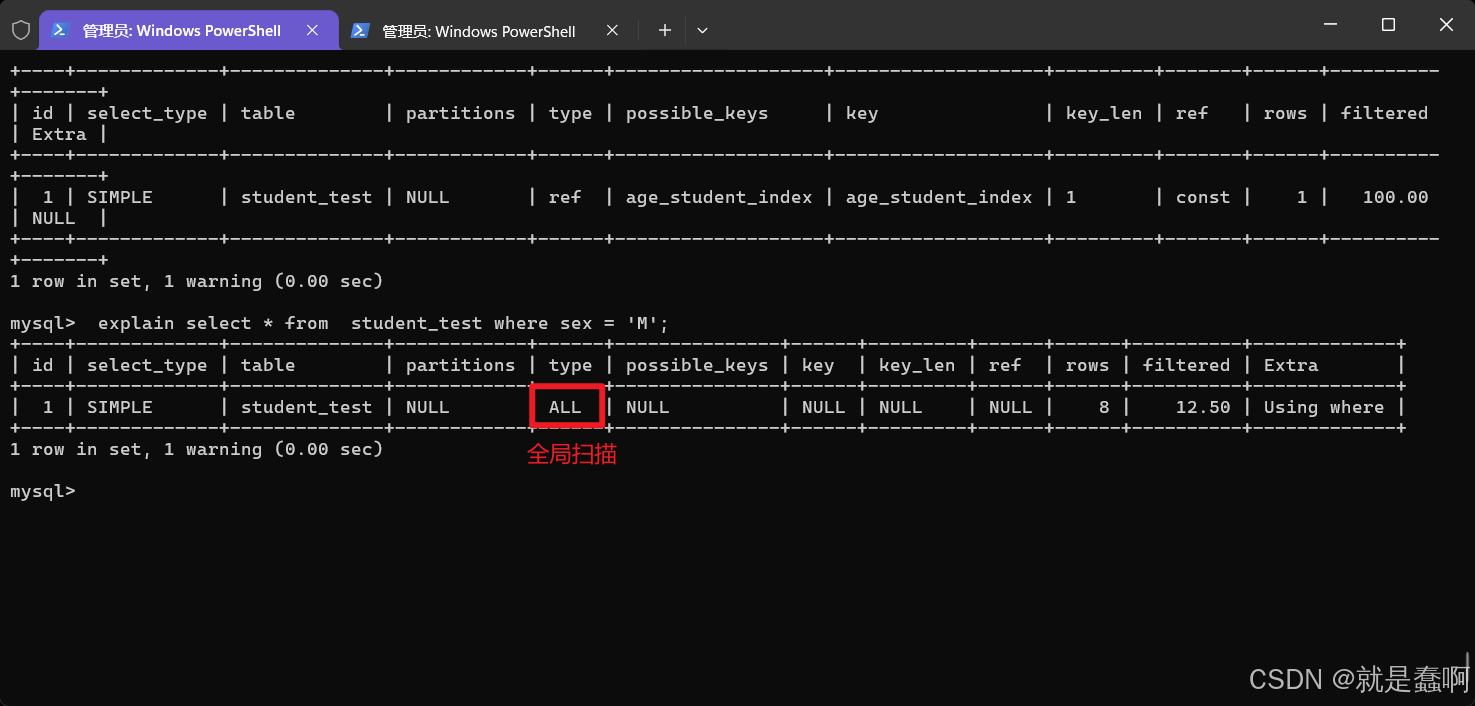
查询是否使用索引:explain select * from 表名 where 条件(与索引相关字段)
创建索引:
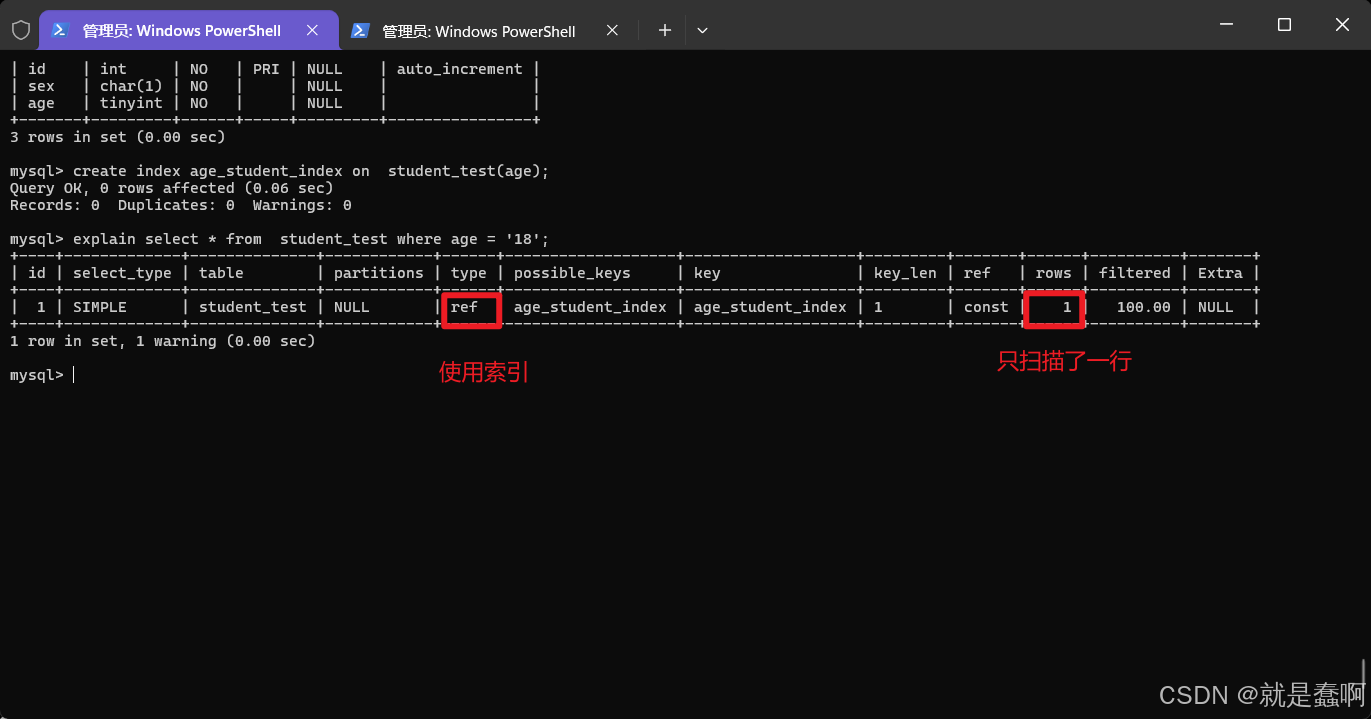
查询是否使用索引:
删除索引:
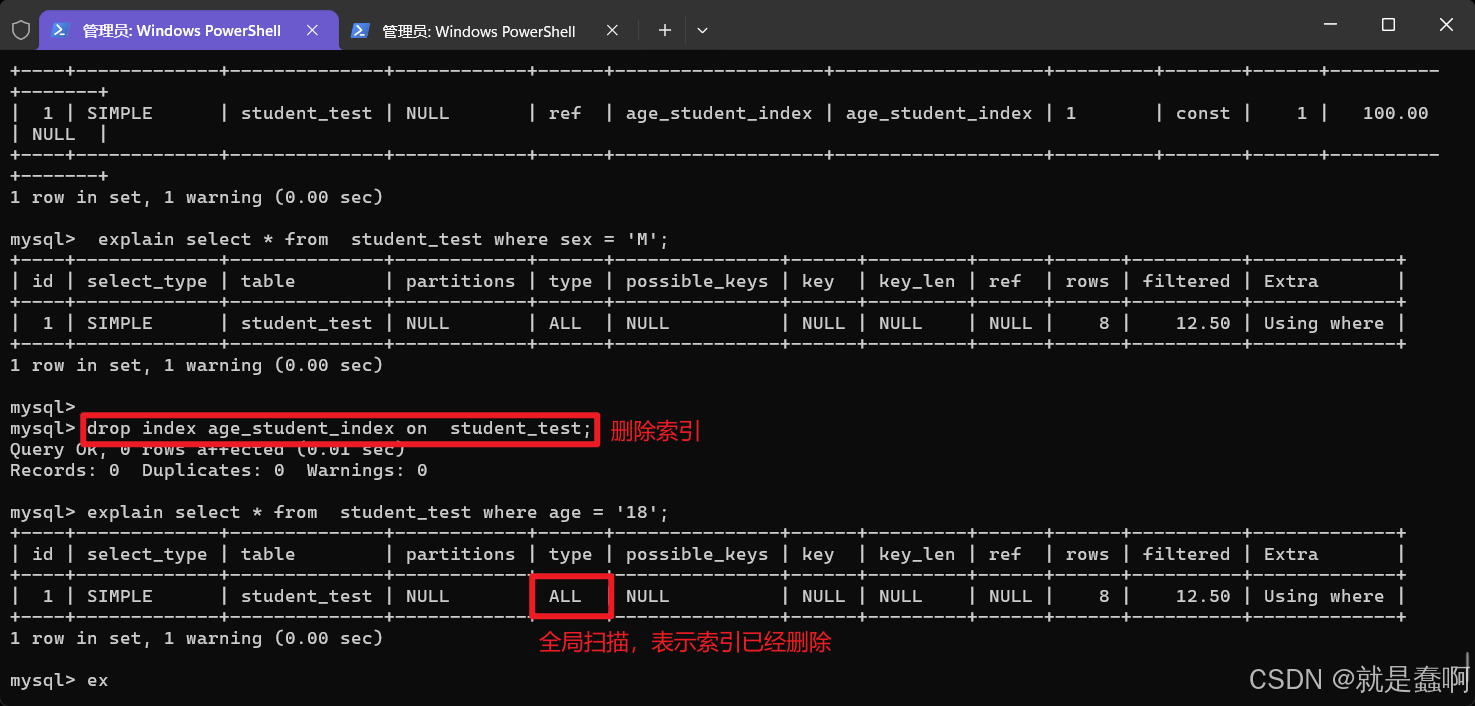
3.7 索引失效
(1)模糊查询中以 ” % “ 开始
select * from Student where name = ' % L '
原因:在比对的时候,数据的开头是 ” % “,不知道是什么东西,当然无法进行比对;
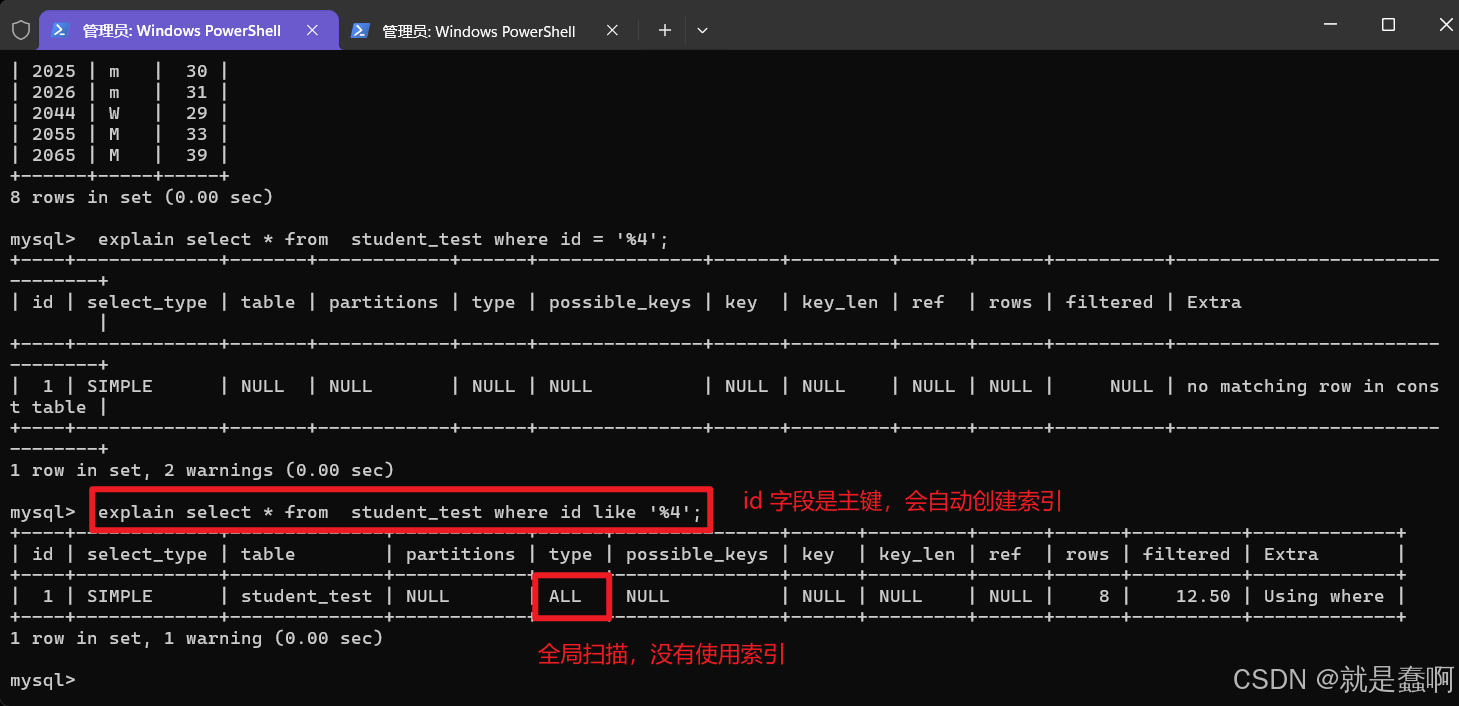
(2)使用 or 会索引失效
使用 or,要求 or 两边的条件字段都要有索引
所以,尽量使用 ‘ union ’ 替换 ‘ or ’ ;
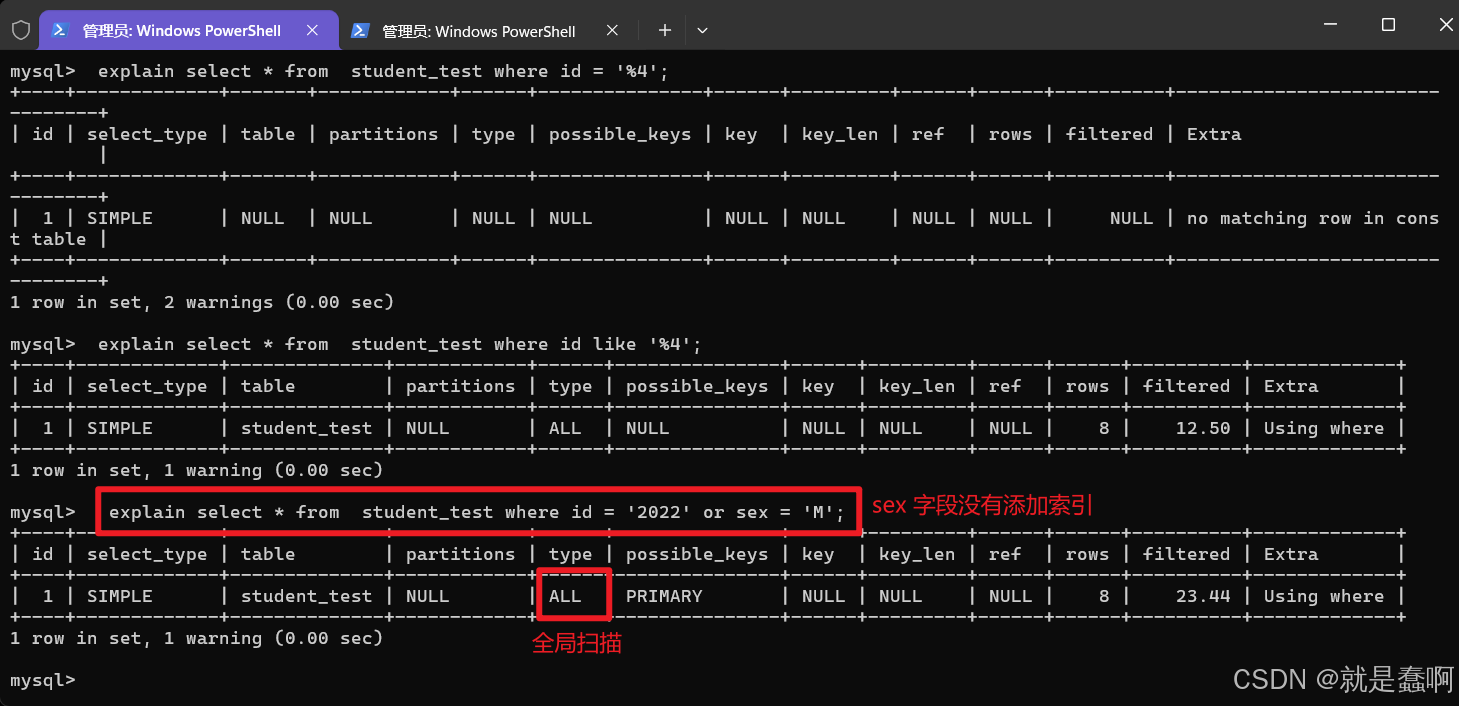
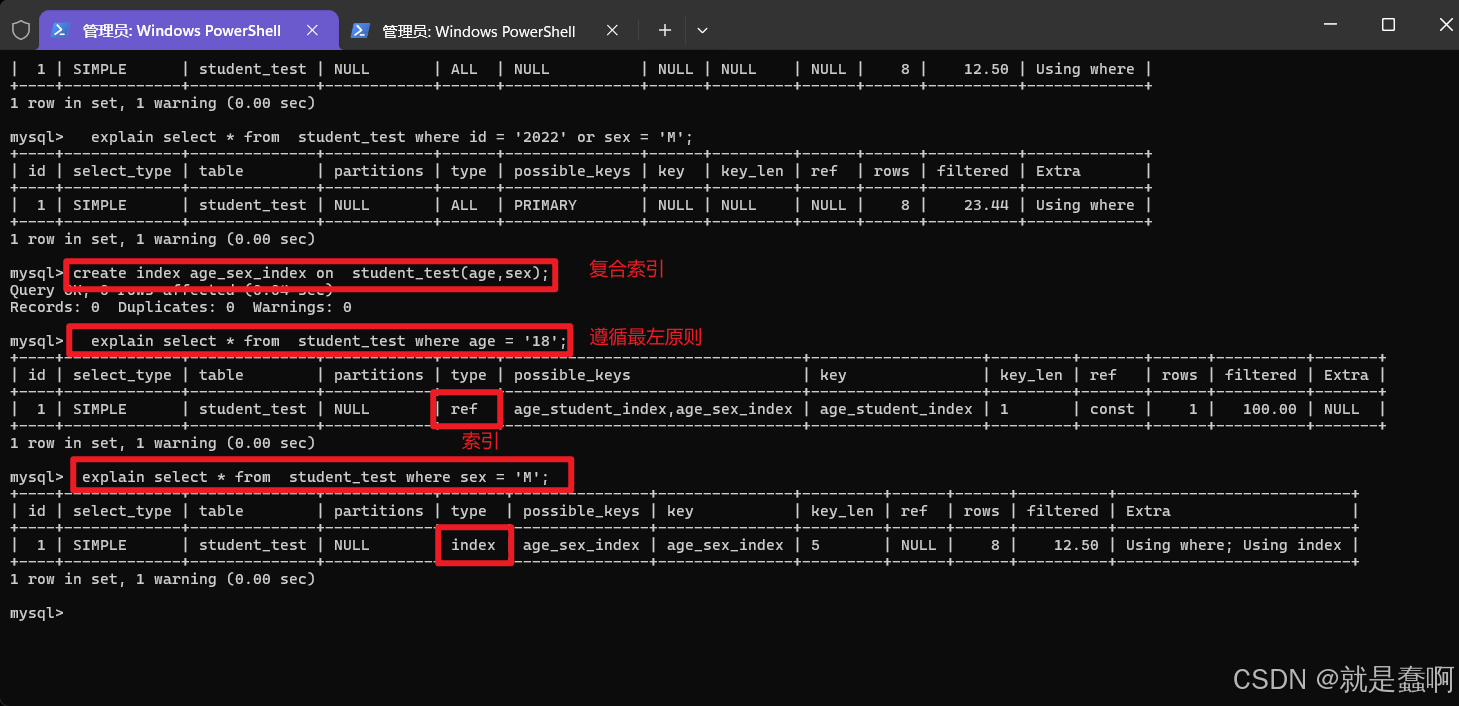
(3)使用复合索引
复合索引:两个字段或者更多的字段联合起来添加一个索引,叫做复合索引;
使用复合索引的时候,没有使用左侧的列查找,索引失效
即遵循最左原则
(4)where 当中索引列参加运算
where 当中索引列参加运算,索引失效
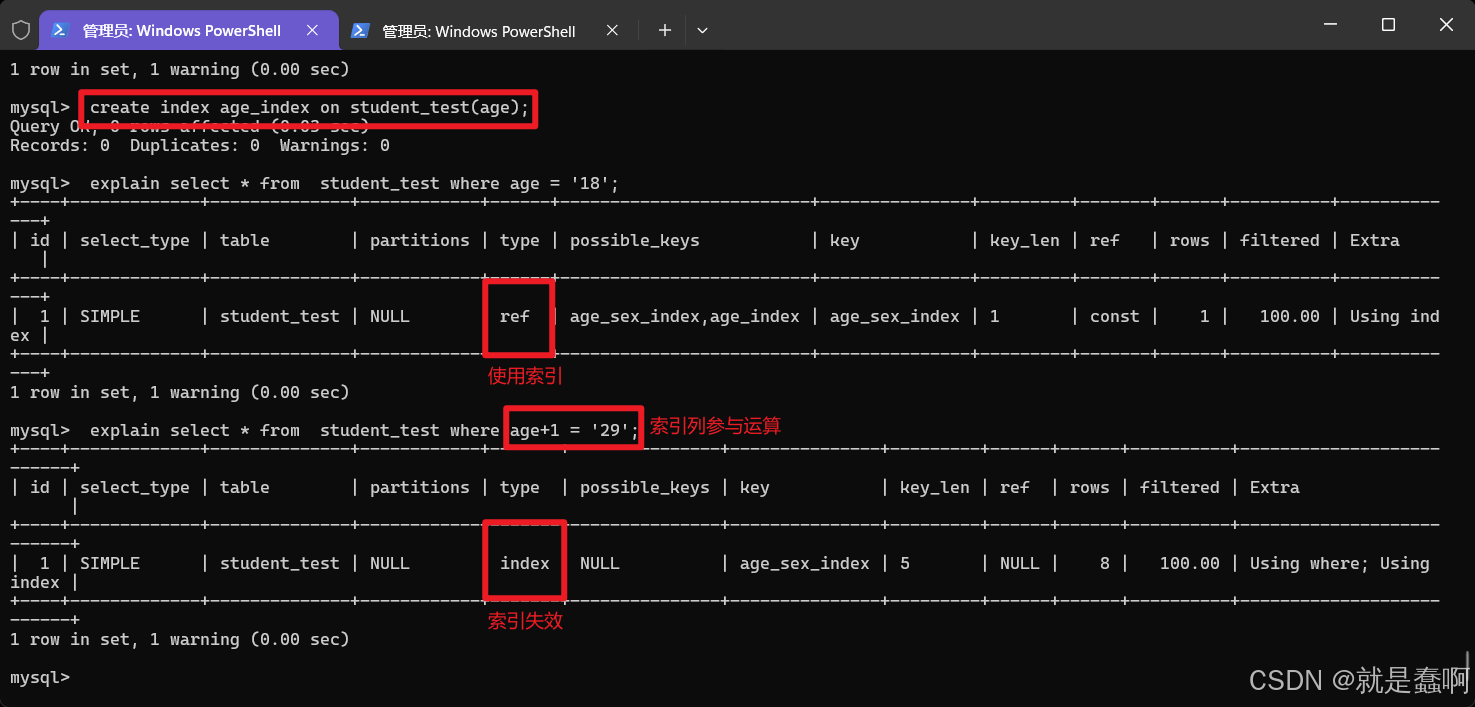
(5)索引列使用函数
where 当中索引列使用函数
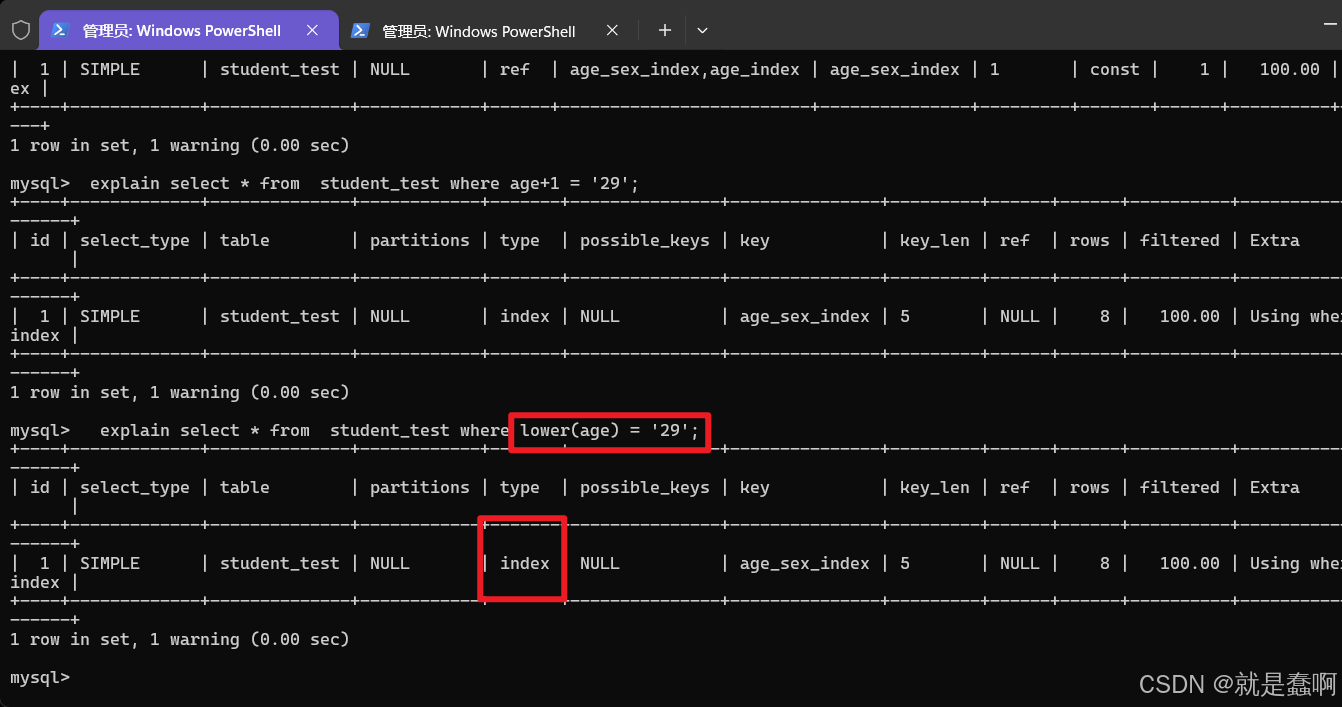
除此之外,还有其他索引失效的情况,这里不一一详举;