刚开始跟着网上的教程做,把环境安装错了,后来直接用GitHub的官方教程来安装环境。
地址是yolov5官方团队代码及教程,看readme文件就可以。
系列文章:
基于Yolov5目标检测的物体分类识别及定位(一) -- 数据集原图获取与标注
基于Yolov5目标检测的物体分类识别及定位(二) -- yolov5运行环境搭建及label格式转换
目录
环境搭建
数据集格式转换
文件夹配置
标签文件的格式转换
更改配置文件
训练模型
环境搭建
很简单,不要想的复杂。
先下载完整的官方代码。地址在开头,下完解压。
用conda为例,新建一个python3.8的版本的环境,可以就叫yolov5,然后进入下好的代码文件夹根目录,命令行激活新建的yolov5这个环境,并运行下面这句话来安装所有的必须的依赖包:
pip install -r requirements.txt没错,你没看错也没想错,就是在conda环境里用pip安装,我刚开始不知道,用conda install去挨个安装,最后还是失败重来,真的浪费时间。
等待全部安装好后,应该是这个效果:
如果下载太慢或者网络问题失败报错,建议进行换源。教程在我另外的博客中:
Anaconda使用conda连接网络时,出现网络错误CondaHTTPError(包括Anaconda安装与入门)
使用Python的pip方法安装第三方包时,很慢或者失败的问题
数据集格式转换
文件夹配置
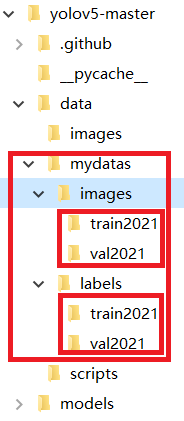
环境搭建好后,在项目的data文件夹中,新建mydatas文件夹,用来放自己做好的数据集。
在mydatas文件夹中,新建images文件夹和labels文件夹。
在images文件夹和labels文件夹中,都新建train2021文件夹和val2021文件夹。
效果为:
把数据集的图片直接放入images/train2021/中(也可以留出一部分做验证集、测试集)。
标签文件的格式转换
这一步很重要,大部分报错都因为这个。而最终判断是否成功运行起来的标志就是,如果你用的是笔记本,散热风扇有没有突然满速运转hhh
接下来把标签文件放入 labels/train2021/中,但是不是把上一篇文章的一堆json文件放过来,而是把那些json转换为txt文件,因为yolov5需要的标签文件就是txt文件。这里借用一张知乎的博客截图,需要注意的是这一项需要把字符串对应顺序换成012345的数字,不然报错。
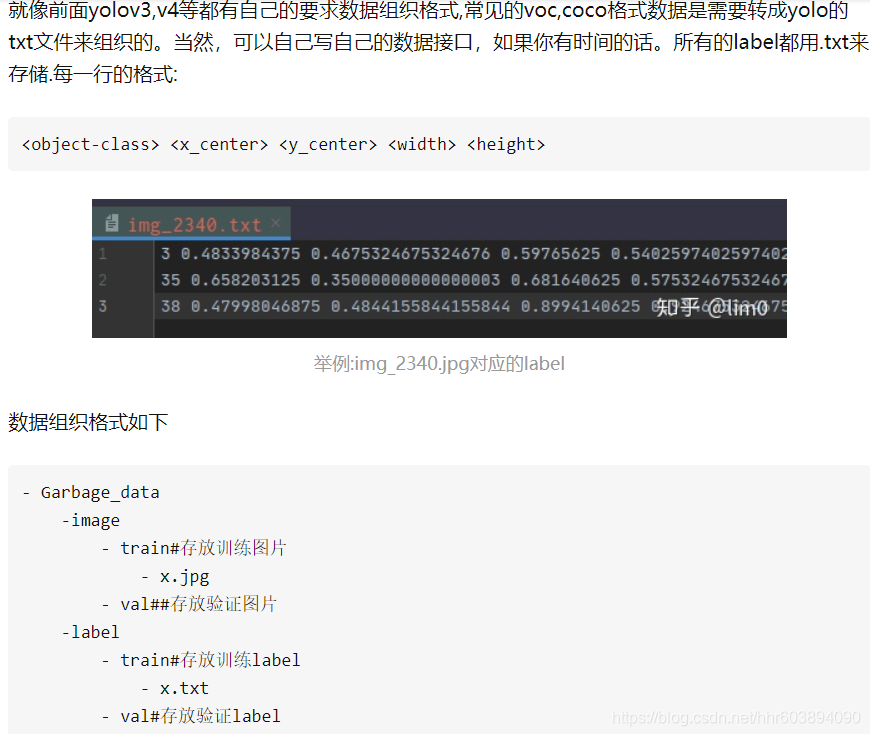
需要注意的是json文件经过loads方法读取后是dict类型,而如果里面有嵌套的第二层json数据,会读取为list类型,不能通过简单的[‘key’]取出数据,需要安装并用jsonpath模块(简单有效),以 $.. 模式寻找第二层子节点。
load() 或 loads() :用于读取json文件,返回的是dict格式。
dump() 或 dumps() :用于写入json文件,写入的是str格式。jsonpath基本语法:
value = jsonpath(theJsonData, '$..label')后面的 描述 的规则是:

以下是多个文本内容的文件的合并代码以及格式转换代码。
# 合并一个文件夹下的多个文本内容形式的文件
# 通用于txt、csv、json等的简单合并
import os
filedir = './yourdir'
filenames = os.listdir(filedir) # 获取当前文件夹中的文件名称列表
f = open('result.json','w') # 打开当前目录下的result文件,如果没有则创建
i = 0
for filename in filenames: # 先遍历文件名
i += 1
print(i)
if i > 0:
filepath = filedir + '\\' + filename
print(filepath)
#遍历单个文件,读取行数
for line in open(filepath,encoding = 'gbk', errors = 'ignore'):
# print(str(line))
f.writelines(line)
f.write('\n') # 最后换行
f.close() # 关闭文件
# 转换json为txt,并按规则计算坐标
import os
import json
from jsonpath import jsonpath
filedir = ''./yourdir/'
str2float = {'yourLabel_1':0, 'yourLabel_2':1, 'yourLabel_3':2, 'yourLabel_4':3, 'yourLabel_5':4, 'yourLabel_6':5}
def jsontotxt(jsonfile):
txt_path = './txts/'
imginfo = json.load(open(filedir + jsonfile))
fn = txt_path + imginfo['imagePath'].replace('.jpg', '.txt')
file = open(fn, 'a')
print(fn)
height = imginfo['imageHeight']
weight = imginfo['imageWidth']
category = jsonpath(imginfo, '$..label')[0] # 最有效,取子节点,返回列表(假列表),取第一个就是str
category = str2float[category]
# 通过字典把字符串格式的标签名换成012345,解决 could not convert string to float 的报错
pointsValue = jsonpath(imginfo, '$..points') # 有的图标了多个矩形,是个真列表
for ap in pointsValue: # 将坐标换算成yolov5的需求格式:相对坐标
x1,y1 = ap[0]
x2,y2 = ap[1]
x = ((x2+x1)/2)/weight
y = ((y2+y1)/2)/height
w = (x2-x1)/weight
h = (y2-y1)/height
x = round(x,8)
y = round(y,8)
w = round(w,8)
h = round(h,8)
file.write(str(category) + ' ')
file.write(str(x) + ' ')
file.write(str(y) + ' ')
file.write(str(w) + ' ')
file.write(str(h) + '\n')
file.close()
if __name__ == "__main__":
filenames = os.listdir(filedir)
for filename in filenames:
jsontotxt(filename) # 处理
更改配置文件
接下来修改配置文件(也可以自己新建),由于我还是初学者,所以先直接修改模板文件。
1、项目的data目录下的coco128.yaml文件修改:
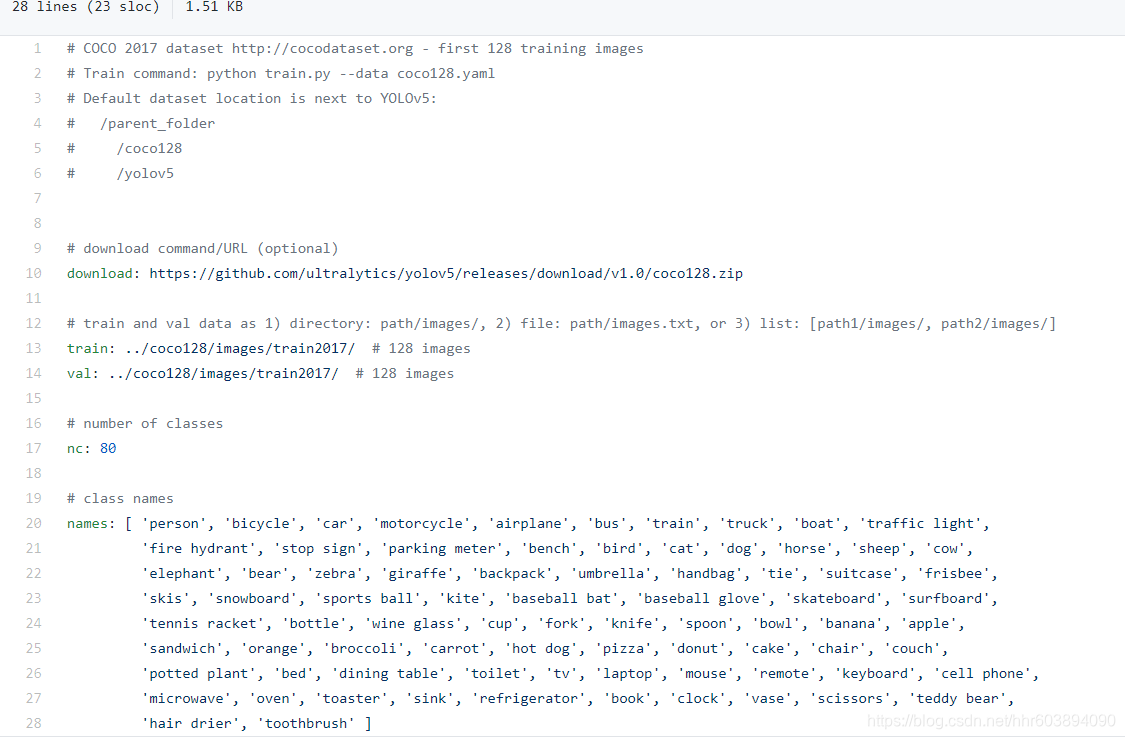
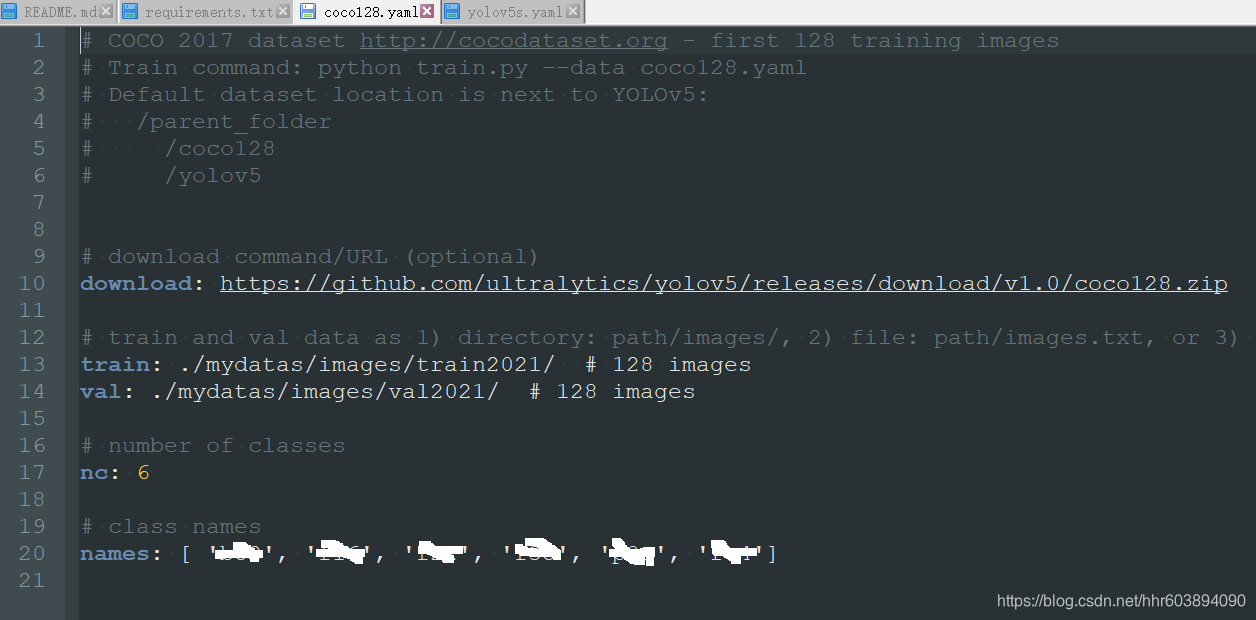
我们需要修改的是 train: 和 val: 和 nc: 和 names: [ 'a', 'b', 'c'] 四行,分别对应训练图片的路径,验证图片的路径,以及数据集的类别的数量,和那些类别的名字。改完的效果例子(sm隐藏):
2、项目的models目录下的yolov5s.yaml(也可选择其他的模型方法)文件修改:
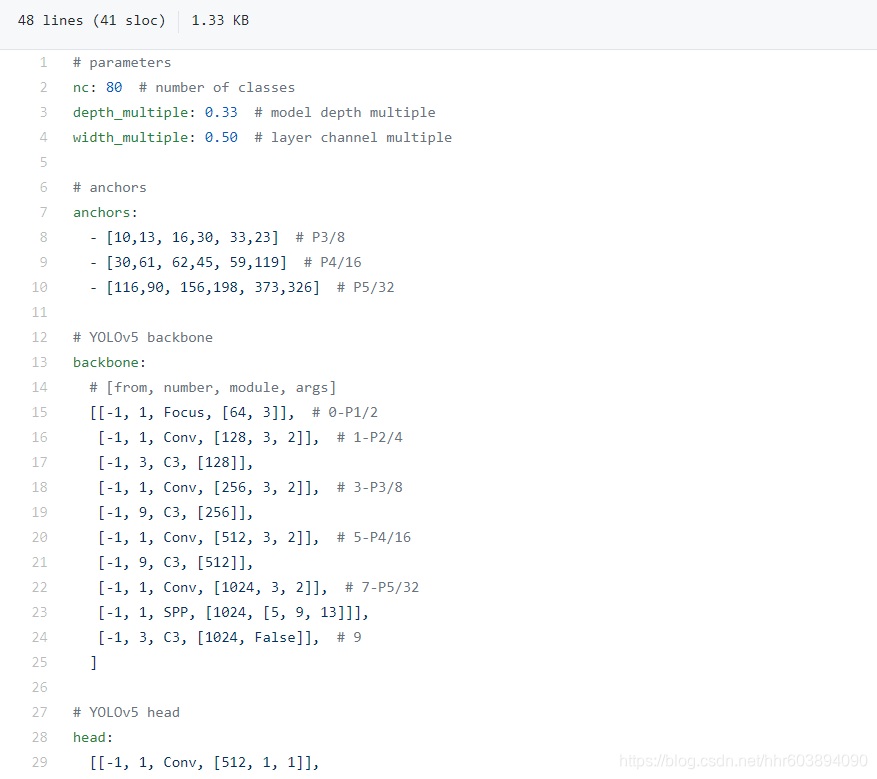
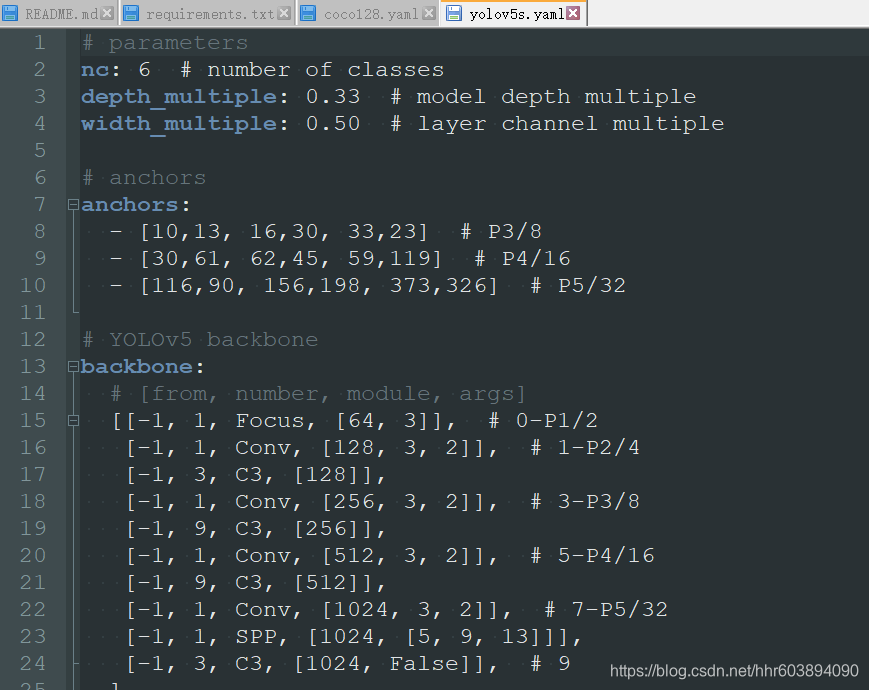
这个文件只需要修改 nc: 那行,跟上一个文件对应就可以。改完的例子:
3、修改时需要注意的问题是,train: 和 val: 以及 nc: 和 name: 的后面要有一个空格,原来的模板里就有,修改的时候不要删除就可以,跟后面的路径和数字隔开,不然会报错。
训练模型
在项目根目录运行命令,如果报错就按照错误信息修改命令或文件,或依赖包,或者重新配置环境。
python train.py --img 640 --batch 16 --epochs 5 --data ./data/coco128.yaml --cfg ./models/yolov5s.yaml --weights weighs/yolov5s.pt有点长,我们分开解读一下参数。
–img:输入网络的图片经预处理后的照片尺寸
–batch:每次输入网络的照片数量,这里如果太大了会超过gpu的显存,根据实际情况调整
–epoch:代表要训练的循环次数,根据你的想法调
–data:上一步更改的第一个文件
–cfg:上一步更改的第二个文件
–weights:开发团队训练好的模型,用来进行迁移训练,可以加上也可以不加,不加的话可能就是训练效果不好以及训练时长更长。官方训练好的模型需要自己fq去作者给的链接去下载,放在weighs文件夹中。
模型的百度云链接:百度网盘 请输入提取码
提取码:8g6c
作者团队是利用tensorboard来可视化训练过程的,训练开始会在主目录生成一个runs文件.利用tensorboard打开即可(需要TensorFlow环境)。
tensorboard --logdir=./runs运行5个Epoch之后,就得到了一个初版训练模型(运行中的JPEG corrupt的报错不用管,会自动跳过然后继续训练)。
参考文章:
https://github.com/ultralytics/yolov5/readme.md
yolov5训练自己的数据集(垃圾检测分类) - 知乎
https://blog.csdn.net/yapifeitu/article/details/106932503