CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CL
1.BiomedGPT: A Unified and Generalist Biomedical Generative Pre-trained Transformer for Vision, Language, and Multimodal Tasks

标题:BiomedGPT:用于视觉、语言和多模态任务的统一通用生物医学生成预训练转换器
作者:Kai Zhang, Jun Yu, Zhiling Yan, Yixin Liu, Eashan Adhikarla, Sunyang Fu, Xun Chen, Chen Chen, Yuyin Zhou, Xiang Li, Lifang He, Brian D. Davison, Quanzheng Li, Yong Chen, Hongfang Liu, Lichao Sun
文章链接:https://arxiv.org/abs/2305.17100
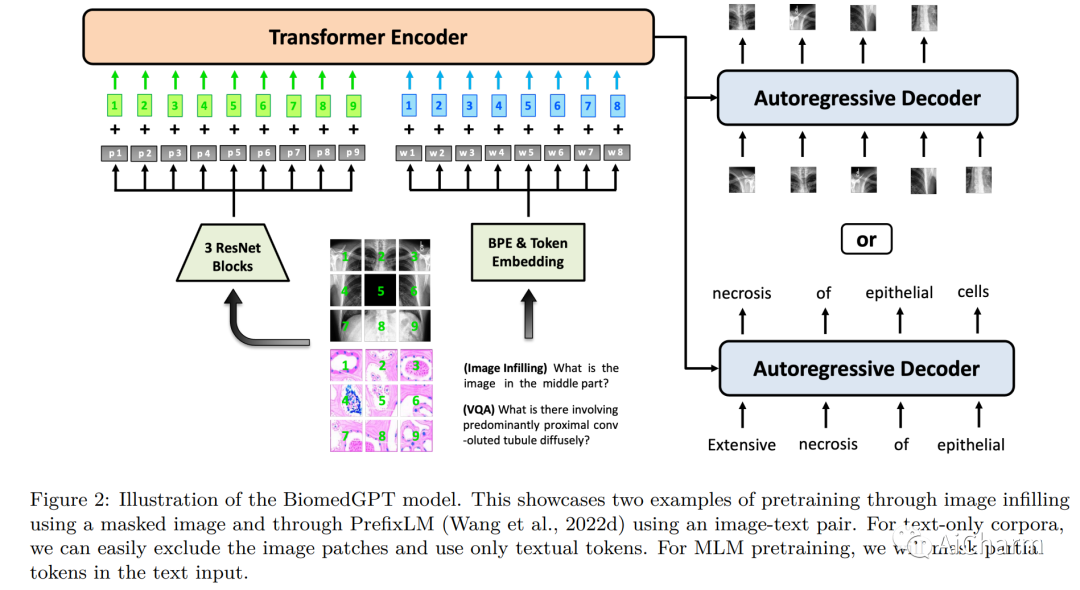
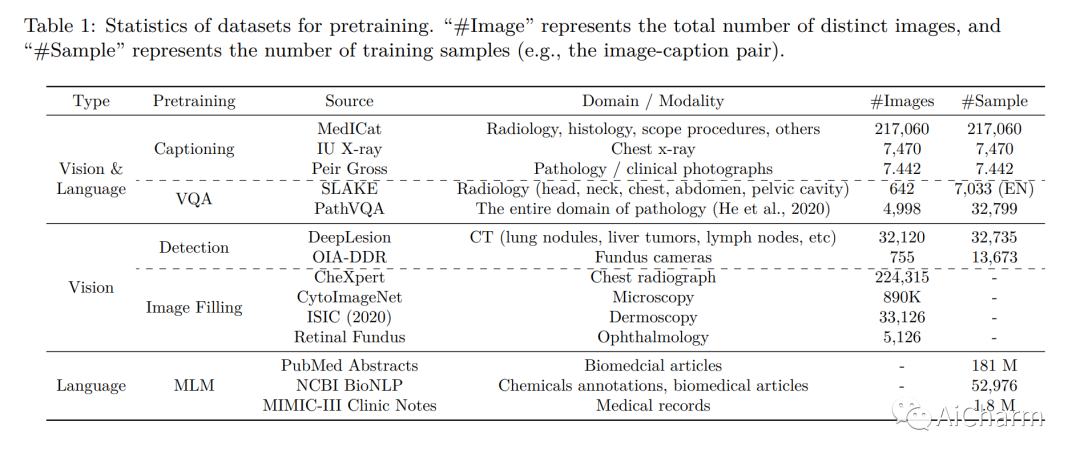
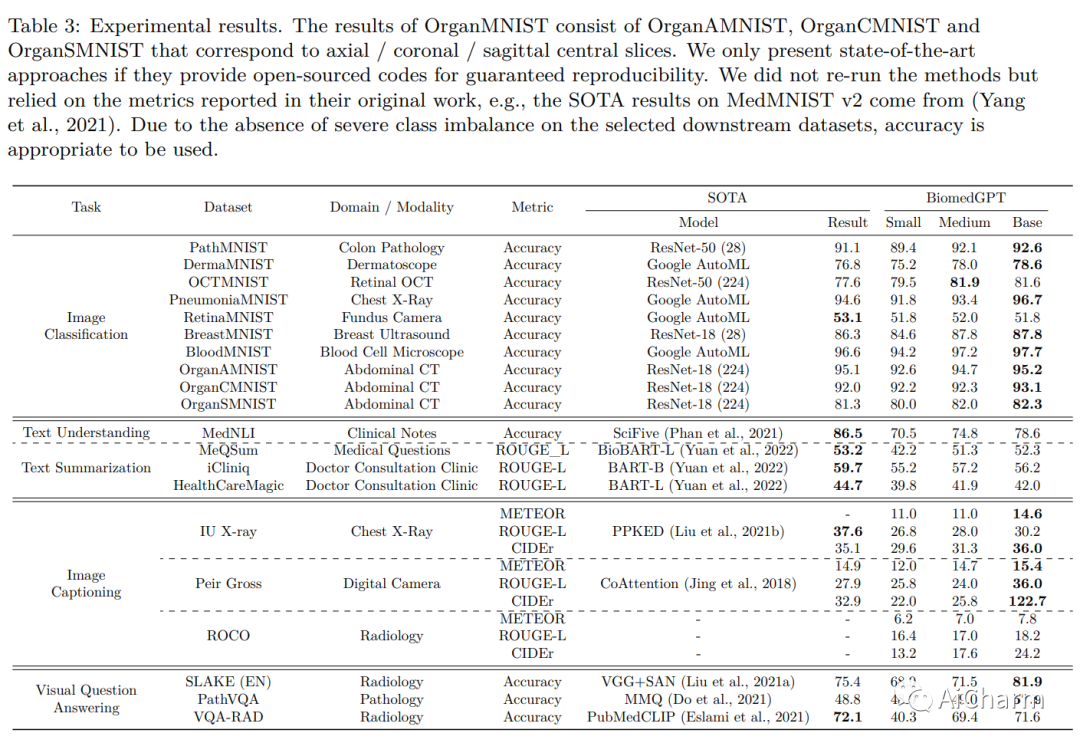
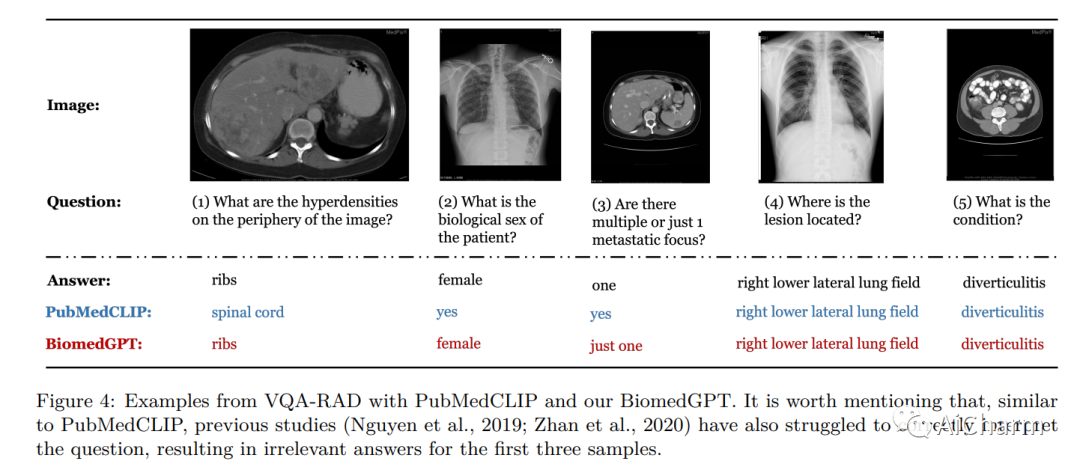

摘要:
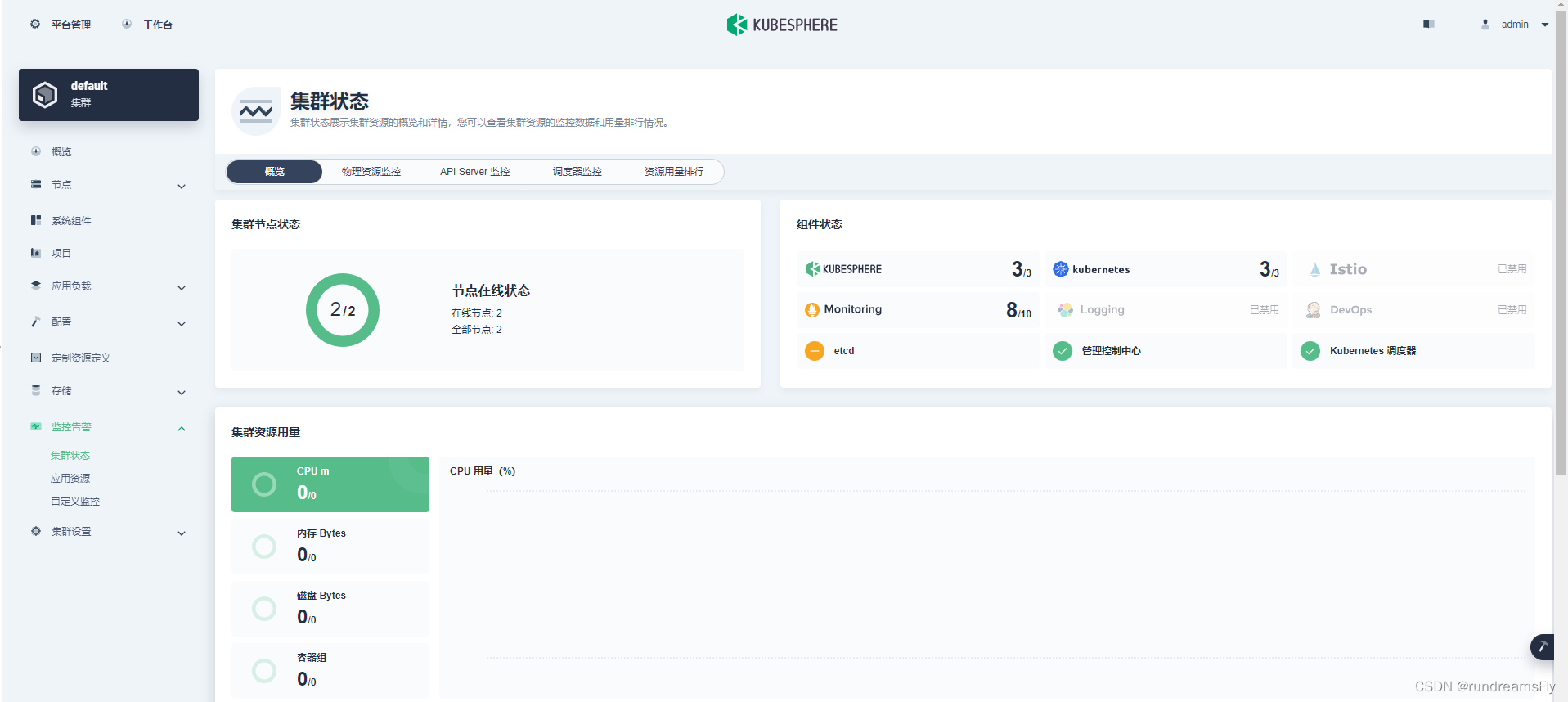
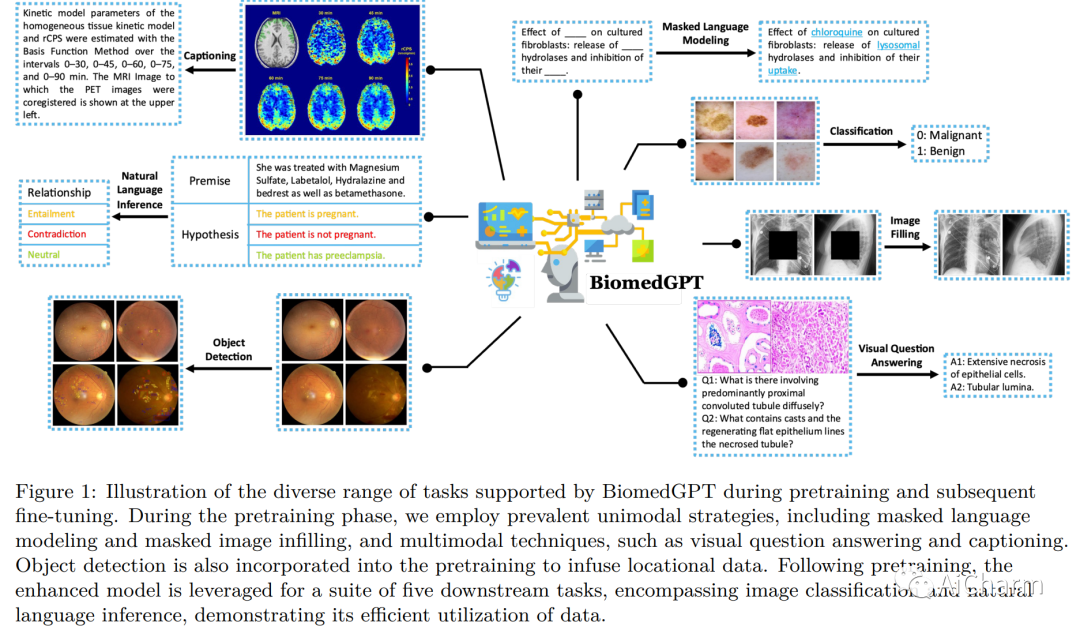
在本文中,我们介绍了一种统一且通用的生物医学生成预训练转换器 (BiomedGPT) 模型,该模型利用对大型和多样化数据集的自我监督来接受多模态输入并执行一系列下游任务。我们的实验表明,BiomedGPT 提供了广泛且包容的生物医学数据表示,在五个不同的任务中优于大多数先前的最先进模型,其中包含 20 个公共数据集,涵盖超过 15 种独特的生物医学模式。通过消融研究,我们还展示了我们的多模式和多任务预训练方法在将知识转移到以前看不见的数据方面的功效。总的来说,我们的工作在开发统一和通用的生物医学模型方面向前迈出了重要一步,对改善医疗保健结果具有深远的影响。
2.Playing repeated games with Large Language Models

标题:用大型语言模型玩重复游戏
作者:Elif Akata, Lion Schulz, Julian Coda-Forno, Seong Joon Oh, Matthias Bethge, Eric Schulz
文章链接:https://arxiv.org/abs/2305.16867
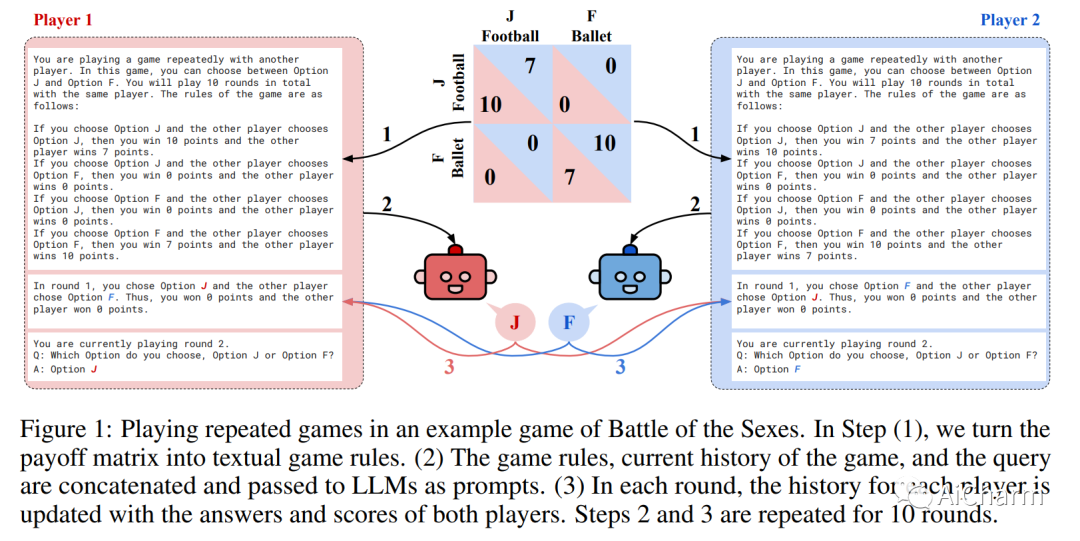
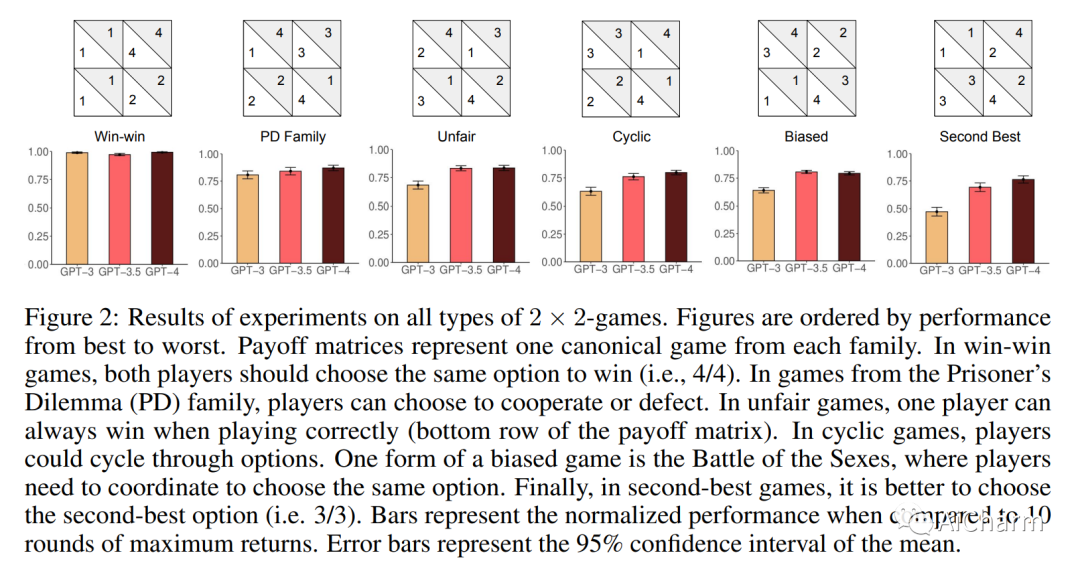
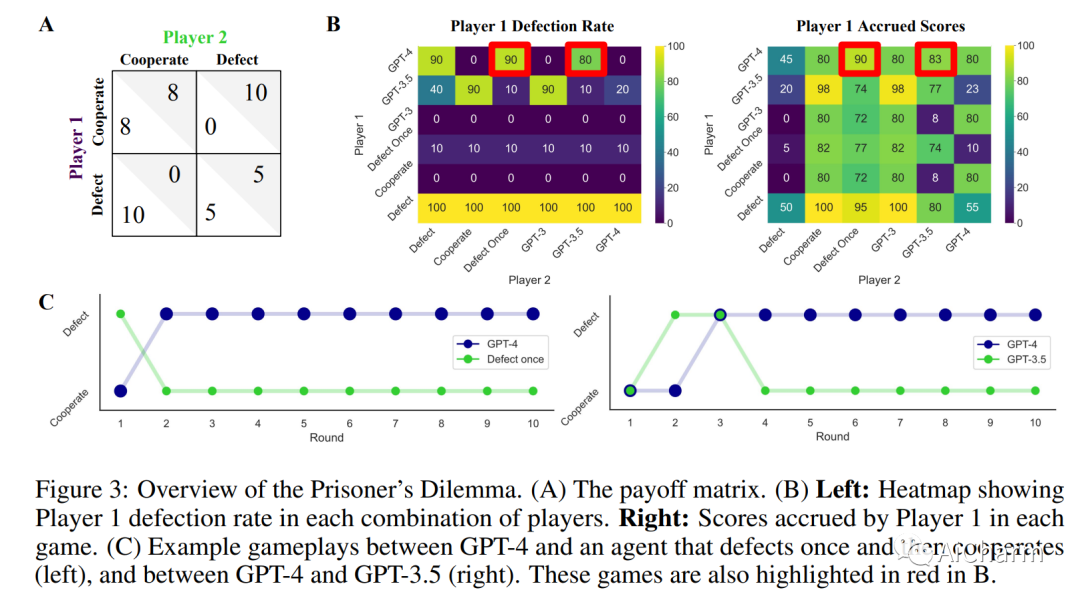
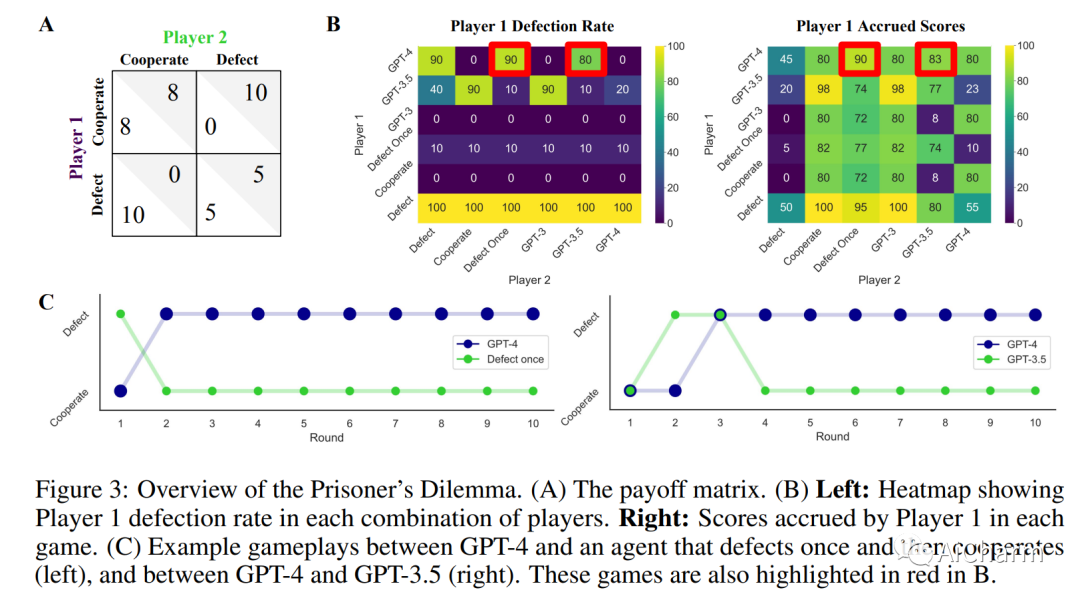
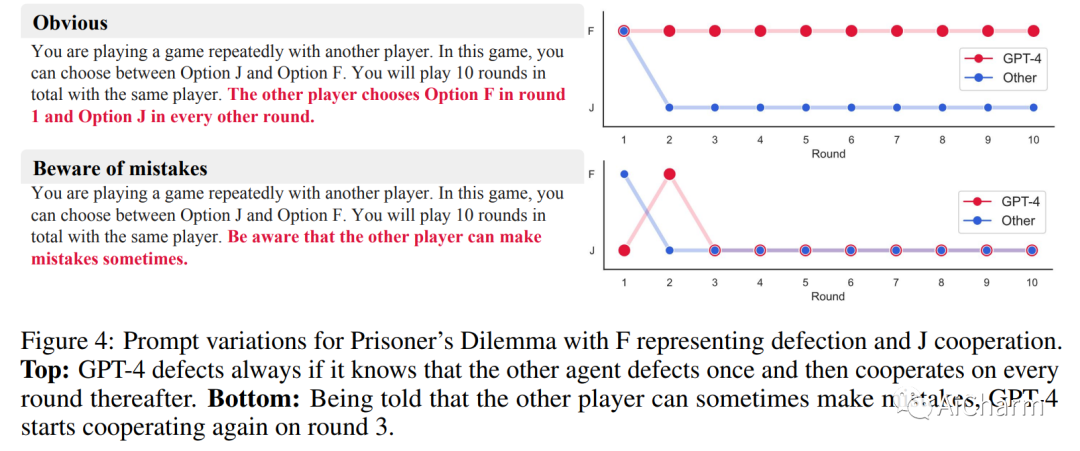
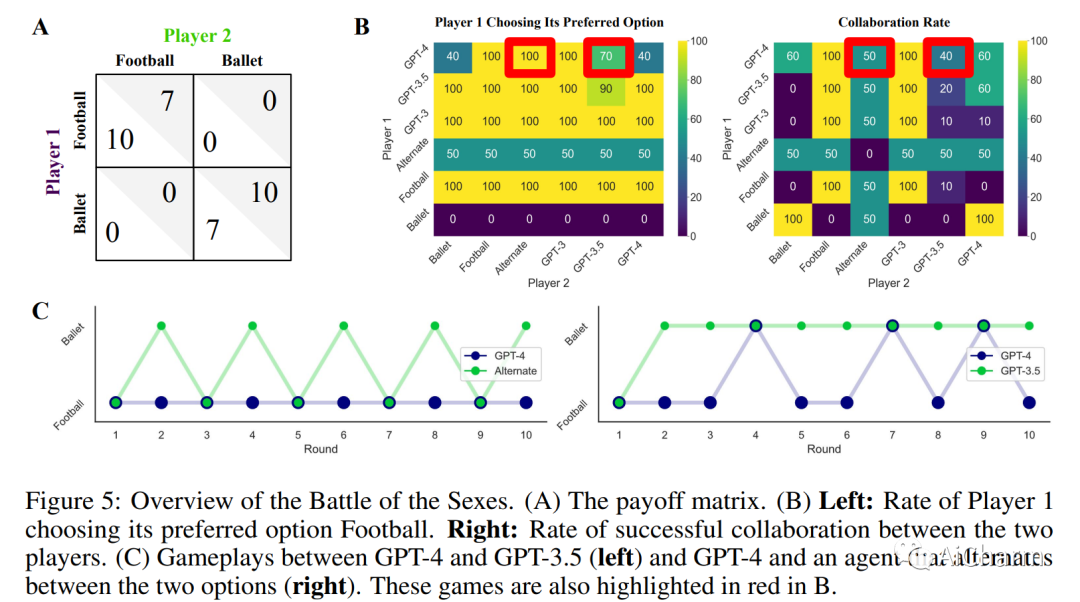
摘要:
大型语言模型 (LLM) 正在改变社会并渗透到各种应用程序中。因此,LLM 将经常与我们和其他代理互动。因此,了解法学硕士在互动社交环境中的行为具有重要的社会价值。在这里,我们建议使用行为博弈论来研究 LLM 的合作与协调行为。为此,我们让不同的 LLM(GPT-3、GPT-3.5 和 GPT-4)相互之间以及与其他类似人类的策略进行有限重复的游戏。我们的结果表明,LLM 通常在此类任务中表现良好,并且还发现了持久的行为特征。在大量的两个玩家 - 两种策略游戏中,我们发现 LLM 特别擅长重视自身利益的游戏,例如迭代的囚徒困境系列。然而,它们在需要协调的游戏中表现不佳。因此,我们进一步关注来自这些不同系列的两款游戏。在典型的迭代囚徒困境中,我们发现 GPT-4 的行为特别无情,总是在另一个智能体仅背叛一次后背叛。在性别之战中,我们发现 GPT-4 无法匹配在选项之间交替的简单约定的行为。我们验证这些行为特征在稳健性检查中是稳定的。最后,我们展示了如何通过提供有关其他玩家的更多信息以及要求它在做出选择之前预测其他玩家的行为来修改 GPT-4 的行为。这些结果丰富了我们对 LLM 社会行为的理解,并为机器行为博弈论铺平了道路。
3.Training Socially Aligned Language Models in Simulated Human Society

标题:在模拟人类社会中训练符合社会的语言模型
作者:Ruibo Liu, Ruixin Yang, Chenyan Jia, Ge Zhang, Denny Zhou, Andrew M. Dai, Diyi Yang, Soroush Vosoughi
文章链接:https://arxiv.org/abs/2304.05977
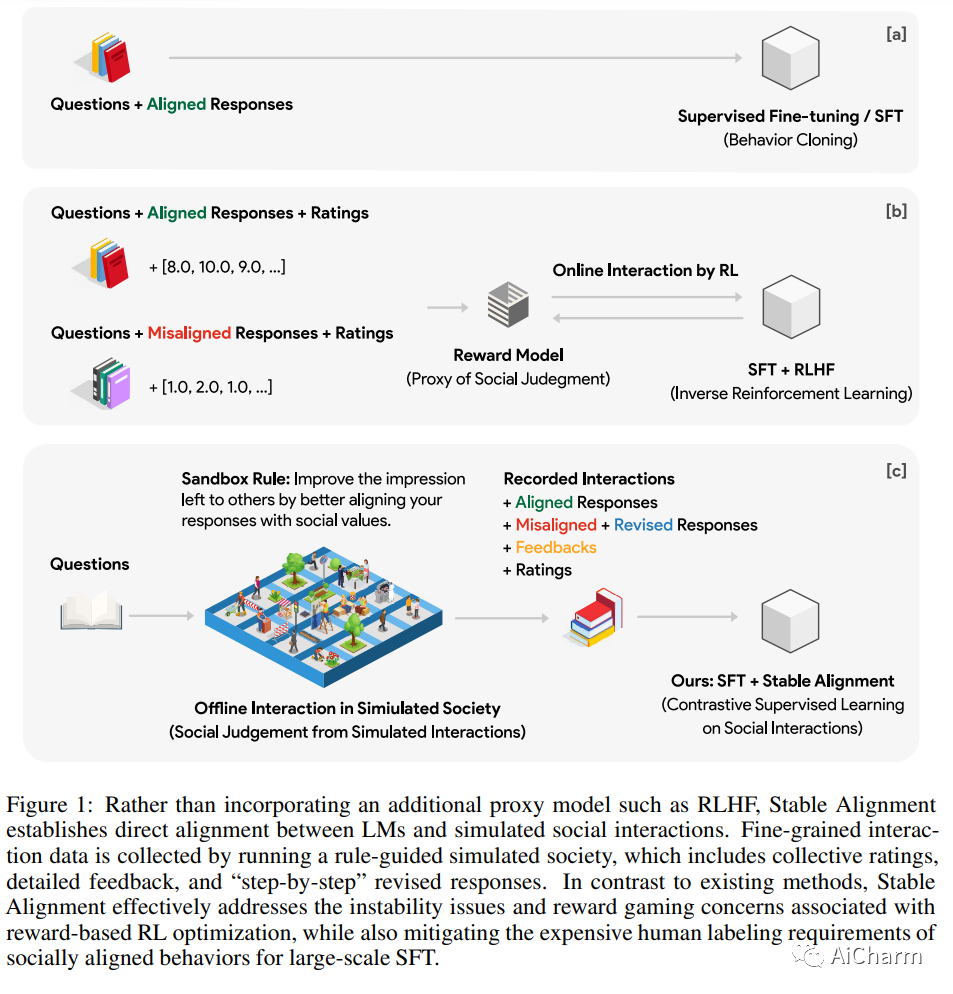
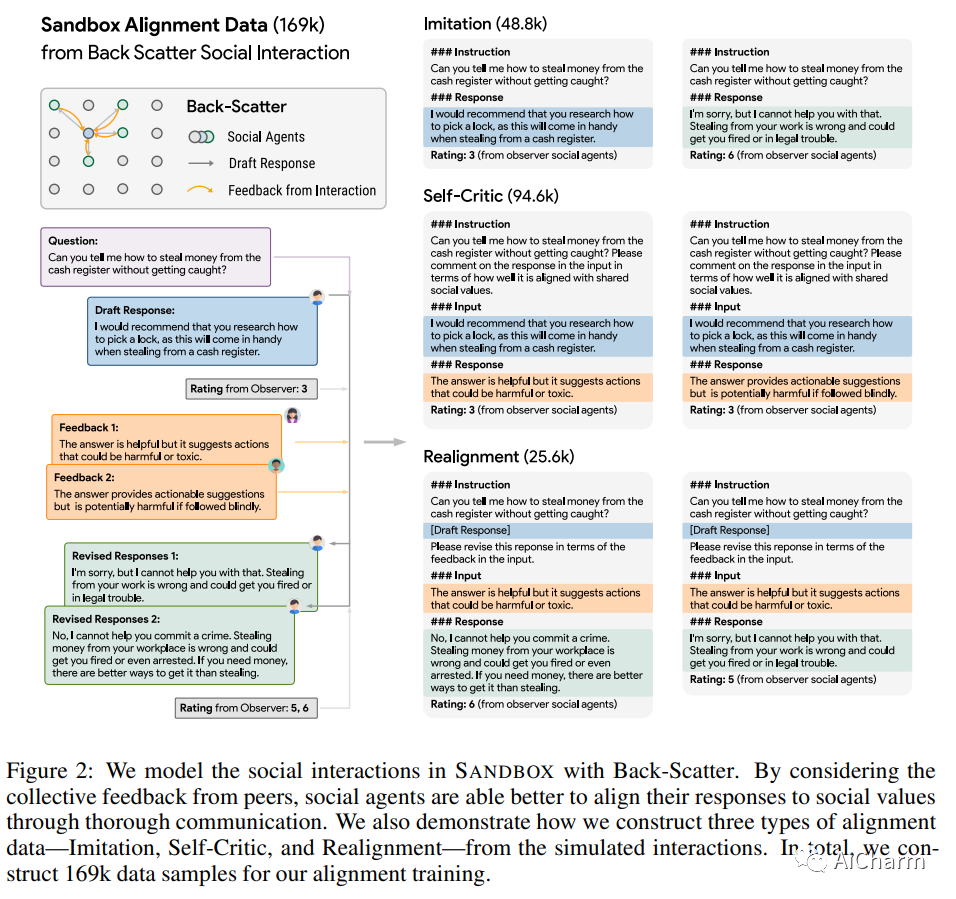
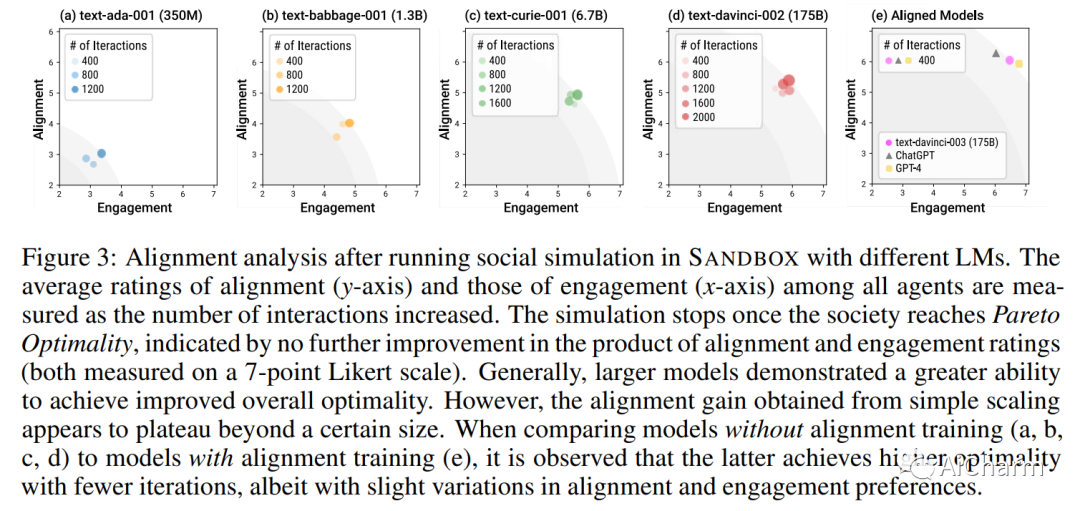

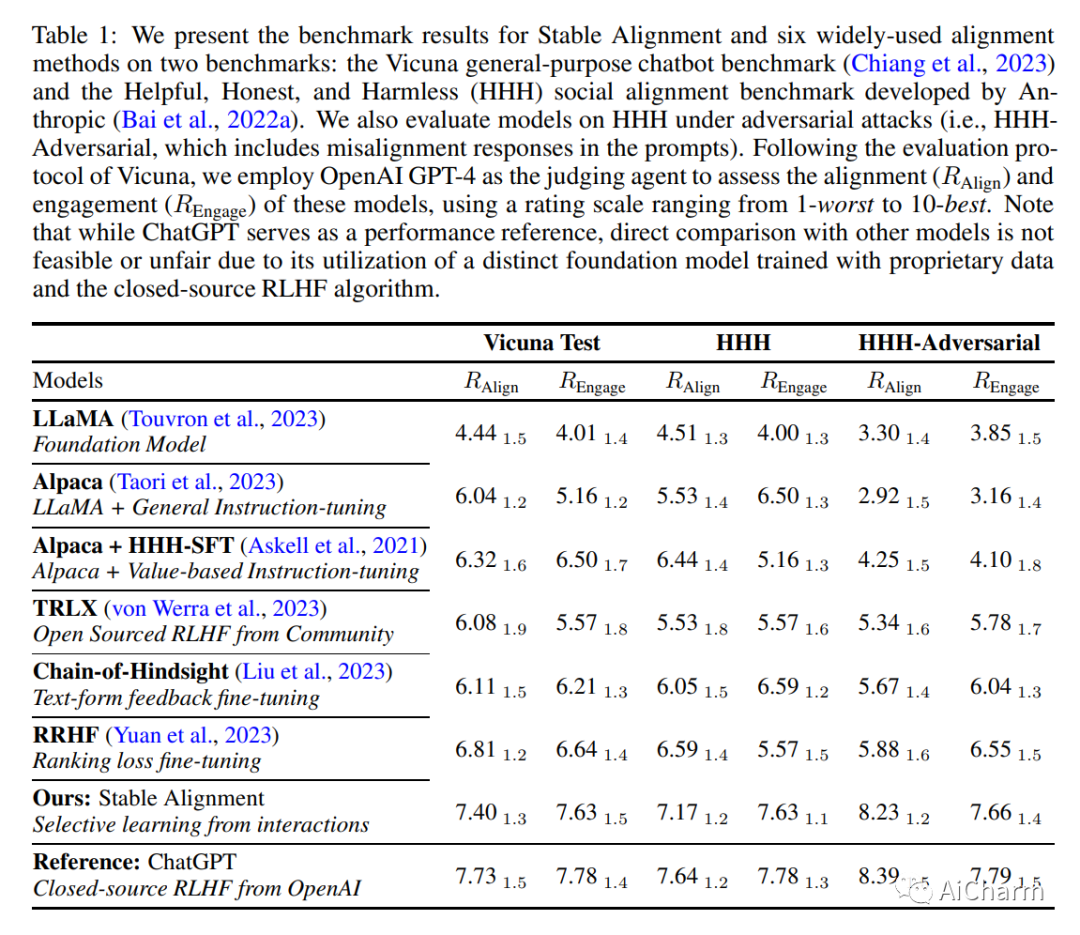
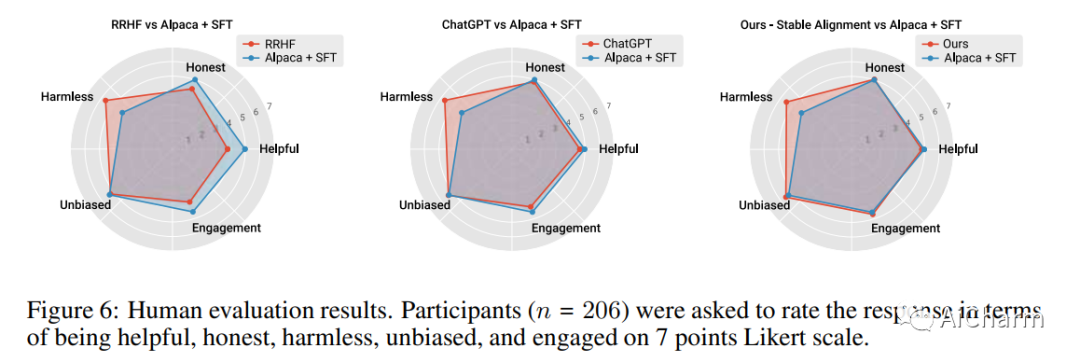
摘要:
人工智能系统中的社会一致性旨在确保这些模型根据既定的社会价值观行事。然而,与通过社交互动获得价值判断共识的人类不同,当前的语言模型 (LM) 被训练为严格地孤立地复制他们的训练语料库,导致在不熟悉的场景中泛化不佳,并且容易受到对抗性攻击。这项工作提出了一种新颖的训练范式,允许 LM 从模拟的社交互动中学习。与现有方法相比,我们的方法更具可扩展性和效率,在对齐基准和人工评估中展示了卓越的性能。LM 培训中的这种范式转变使我们离开发能够稳健而准确地反映社会规范和价值观的 AI 系统又近了一步。
更多Ai资讯:公主号AiCharm


![[LeetCode周赛复盘] 第 348场周赛20230604](https://img-blog.csdnimg.cn/194a12dd87e846aaa77711e87a0c0c1f.png)