随机数发生器设计(三)- 熵估计和健康测试
- 熵估计
- 健康测试
熵估计
考虑都熵源的多样性,建立一个通用的熵估计模型比较困难。本文采用nist.sp.800-90B推荐的Markov评估。详见 https://doi.org/10.6028/NIST.SP.800-90B。
执行Markov评估时,熵估计模块会对熵池内部所有数据进行熵估计。Markov评估方式如下图所示。

Markov熵估计流程描述如下:
1、 收集106熵源数据作为熵评估数据。
2、 对熵评估数据统计0和1出现的概率P0和P1。
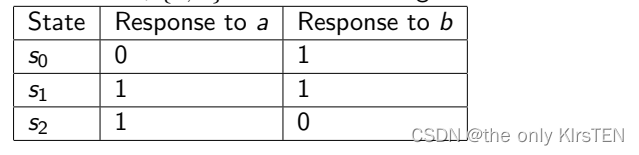
3、 统计00、01、10和11出现的概率P00、P01、P10和P11。
4、 计算P0,0、P0,1、P1,0和P1,1。其中P0,0= P00/(P00+ P01),P0,1= P01/(P00+ P01),P1,0= P10/(P10+ P11),P1,1= P11/(P10+ P11)。
5、 利用P0,0、P0,1、P1,0和P1,1计算表格对应序列最大的概率pmax。
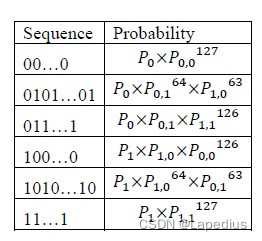
6、 将上表中最大的概率pmax代入min(-log2(pmax)/128,1),结果即为Markov评估最小熵。
def markovEstimate(epsilon:bitarray):
N0 = 0
N1 = 0
N00 = N01 = N10= N11 = 0
lastN = 2
for i in epsilon:
if i == 0:
N0 += 1
if lastN == 1:
N10 += 1
elif lastN == 0:
N00 += 1
else:
N1 += 1
if lastN == 1:
N11 += 1
elif lastN == 0:
N01 += 1
lastN = i
P0 = N0/len(epsilon)
P1 = 1-P0
P00 = N00/(N00 + N01)
P01 = N01/(N00 + N01)
P10 = N10/(N10 + N11)
P11 = N11/(N10 + N11)
sequence = [P0*(P00**127), P0*(P01**64)*(P10**63),P0*(P01**1)*(P11**126),P1*(P10**1)*(P00**126),P1*(P10**64)*(P01**63),P1*(P11**127)]#,];
pmax = max(sequence)
minentropy = min(-math.log2(pmax)/128,1)
return minentropy
对时间信息、CPU信息、RAM信息、磁盘信息和网络信息共5个熵源分别连续采集106比特样本,使用Markov评估方式进行熵估计,结果如下表所示。
| 项目 | 时间信息 | CPU信息 | RAM信息 | 磁盘信息 | 网络信息 |
|---|---|---|---|---|---|
| 单次样本长度(字节) | 4 | 16 | 8 | 8 | 8 |
| 采集样本(bit) | 1000000 | 1000000 | 1000000 | 1000000 | 1000000 |
| 熵估计结果 | 0.68 | 0.89 | 0.41 | 0.48 | 0.72 |
采集熵估计样本数据代码如下。
def generateEntropyTestFile():
temp = bitarray()
tempbytes = bytes()
#generate entropy source bits
#source 1
for i in range(int(10**6/8/4)):
tempbytes += RNG_Generate_Raw_Entropy_Source1()
temp.frombytes(tempbytes)
of = open('./randomsamples/entropysample1.bin','wb')
temp.tofile(of)
of.close()
#source 2
tempbytes2 = bytes()
temp2 = bitarray()
for i in range(int(10**6/8/16)):
tempbytes2 += RNG_Generate_Raw_Entropy_Source2()
tempbytes2 += bytes(RNG_Generate_Raw_Entropy_Source2()[0:8])
temp2.frombytes(tempbytes2)
of2 = open('./randomsamples/entropysample2.bin','wb')
temp2.tofile(of2)
of2.close()
#source 3
tempbytes3 = bytes()
temp3 = bitarray()
for i in range(int(10**6/8/8)):
tempbytes3 += RNG_Generate_Raw_Entropy_Source3()
temp3.frombytes(tempbytes3)
of3 = open('./randomsamples/entropysample3.bin','wb')
temp3.tofile(of3)
of3.close()
#source 4
temp4 = bitarray()
tempbytes4 = bytes()
for i in range(int(10**6/8/8)):
tempbytes4 += RNG_Generate_Raw_Entropy_Source4()
temp4.frombytes(tempbytes4)
of4 = open('./randomsamples/entropysample4.bin','wb')
temp4.tofile(of4)
of4.close()
#source 5
temp5 = bitarray()
tempbytes5 = bytes()
for i in range(int(10**6/8/8)):
tempbytes5 += RNG_Generate_Raw_Entropy_Source5()
temp5.frombytes(tempbytes5)
of5 = open('./randomsamples/entropysample5.bin','wb')
temp5.tofile(of5)
of5.close()
return
健康测试
健康测试包括上电健康测试和连续健康测试。
1)上电健康测试内容:
测试时间:上电健康测试在产品启动时执行。
测试内容:对1024个熵源输出的连续样本进行连续健康测试。
测试方法:重复计数测试
测试样本大小:熵源输出的样本。时间样本为4字节,CPU信息样本为16字节,RAM信息为8字节,磁盘信息为8字节,网络信息8字节。
通过条件:未产生连续11个相同的样本。
处理方法:未通过则返回错误,不能继续使用熵源输出的数据。
#entropy source poweron health test
for i in range(1024):
if RNG_Continuous_Health_Test(RNG_Generate_Raw_Entropy_Source1()) == -1:
return 0x80100001
for i in range(1024):
if RNG_Continuous_Health_Test(RNG_Generate_Raw_Entropy_Source2()) == -1:
return 0x80100002
for i in range(1024):
if RNG_Continuous_Health_Test(RNG_Generate_Raw_Entropy_Source3()) == -1:
return 0x80100003
for i in range(1024):
if RNG_Continuous_Health_Test(RNG_Generate_Raw_Entropy_Source4()) == -1:
return 0x80100004
for i in range(1024):
if RNG_Continuous_Health_Test(RNG_Generate_Raw_Entropy_Source5()) == -1:
return 0x8010005
2)连续健康测试内容:
测试时间:在熵源输入数据时执行。
测试内容:对熵源输出的连续样本进行测试。
测试方法:重复计数测试
测试样本大小:熵源输出的样本。时间样本为4字节,CPU信息样本为16字节,RAM信息为8字节,磁盘信息为8字节,网络信息8字节。
通过条件:未产生连续11个相同的样本。
处理方法:未通过则不能继续使用熵源输出的数据。
def RNG_Continuous_Health_Test(nextRawEntropy:bytes):
global H
C = 1+ math.ceil(20/H)
B = 1
global curRawEntropy
if nextRawEntropy == curRawEntropy:
B += 1
if B >= C:
return -1
else:#not equel, pass
B = 1
curRawEntropy = nextRawEntropy
return 0
如果商用密码产品认证中遇到问题,欢迎加微信symmrz或13720098215沟通。