1、二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树
*若它的左子树不为空则左子树上所有的节点的值都小于根节点的值
*若它的右子树不为空则右子树上所有的节点的值都大于根节点的值
*它的左右子树也分别是一棵二叉搜索树
*二叉搜索树的中序遍历是有序的
*查找某一个值,相当于类似二分查找

2、插入一个元素
*如果是空树的情况下
创建一个节点,让root直接引用就可以了
*根据二叉搜索树的性质,判断当前节点值与传入值的大小,让当前节点移动到左边或者右边
*在current遍历的过程中,要用一个prev记录他的父节点
*当current==null时,根据传入的元素值,与父节点的值作比较,插入到左或者右

3、删除元素操作
设删除的节点为cur,待删除的双亲节点为parent
3.1、cur.left==null
*cur是root则root=cur.right
*cur不是root,cur是parent.left,则parent.left=cur.right
*cur不是root,cur是parent.right,则parent.right=cur.right
3.2、cur.right==null
*cur是root,则root=cur.left
*cur不是root,cur是parent.left,则parent.left=cur.left
*cur不是root,cur是parent.right,则parent.right=cur.left
3.3、cur.left!=null&&cur.right!=null
public class BinarySearchTree {
//定义节点类
public static class TreeNode {
int value;
TreeNode left;
TreeNode right;
public TreeNode(int value) {
this.value = value;
}
}
//定义根节点
public TreeNode root;
//查找指定值
public boolean search(int value) {
//1、判断根节点是否为空
if (root == null) {
return false;
}
//2、定义一个用来遍历的节点
TreeNode current = root;
while (current != null) {
//3、判断节点值是否相等
if (value == current.value) {
return true;
}
//4、根据value和当前节点的值判断继续向左或向右移动
if (value < current.value) {
current = current.left;
} else {
current = current.right;
}
}
return false;
}
/**
* 插入元素
*
* @param value 要插入的值
* @return
*/
public boolean insert(int value) {
TreeNode node = new TreeNode(value);
//1、判断根节点是否为空
if (root == null) {
root = node;
return true;
}
//2、遍历二叉搜索树
TreeNode current = root;
//用来记录current节点
TreeNode prev = null;
while (current != null) {
//判断是否相等
if (current.value == value) {
//如果相等直接返回
return false;
}
//找到真正插入的位置
prev = current;
if (current.value > value) {
current = current.left;
} else {
current = current.right;
}
}
//当current==null时,prev就在一个叶子节点的位置
//根据prev的值确定新节点的位置
if (prev.value> value) {
prev.left = node;
} else {
prev.right = node;
}
return true;
}
/**
* 删除指定的元素
*
* @param value
* @return
*/
public boolean remove(int value) {
//条件判空
if (root == null) {
return false;
}
//找到要删除的元素
TreeNode current = root;
TreeNode parent = null;
while (current != null) {
if (current.value == value) {
removeNode(parent, current);
return true;
}
//记录父节点
parent = current;
if (value < current.value) {
current = current.left;
} else {
current = current.right;
}
}
return false;
}
//删除节点
private void removeNode(TreeNode parent, TreeNode current) {
if (current.left == null) {
//当左孩子节点为空时进入
if (current == root) {
//把要删除的右节点赋给root
root = current.right;
} else if (current == parent.left) {
//当前节点是父节点的左节点时
parent.left = current.right;
} else {
//当前节点是父节点的右节点时
parent.right = current.right;
}
} else if (current.right == null) {
//当前节点时根结点时
if (current == root) {
root = current.left;
} else if (current == parent.left) {
//当前节点是父节点的左孩子节点时
parent.left = current.left;
} else {
//当前节点是父节点的右孩子节点时
parent.right = current.left;
}
} else {
//用来定义便利的几个变量
TreeNode target = current.right;
TreeNode parentTarget = current;
//向左去找最小值
while (target.left != null) {
parentTarget = target;
target = target.left;
}
//到达叶子节点
current.value = target.value;
//删除target节点
if (target == parentTarget.left) {
parentTarget.left = target.right;
} else {
parentTarget.right = target.right;
}
}
}
/**
* 中序遍历
*
* @param node
* @return
*/
public String inOrder(TreeNode node) {
StringBuilder sb = new StringBuilder();
if (node == null) {
return sb.toString();
}
//先处理左
String left = inOrder(node.left);
sb.append(left);
//处理根节点
sb.append(node.value+" ");
//处理右
String right=inOrder(node.right);
sb.append(right);
return sb.toString();
}
}
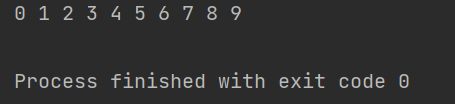
4、测试类
public class TestBinaryTree {
public static void main(String[] args) {
int[] array={5,3,7,1,4,6,8,0,2,9};
BinarySearchTree binarySearchTree=new BinarySearchTree();
for(int i=0;i<array.length;i++){
binarySearchTree.insert(array[i]);
}
System.out.println(binarySearchTree.inOrder(binarySearchTree.root));
}
}
6、桶排序是计数排序的扩展版本,计数排序可以看成每个桶只存储相同元素,而桶排序中每个桶只存储一定范围的元素,通过映射函数,将待排序数组中的每一个元素映射到各个对应的桶中,对每个桶中的元素进行排序,最后将非空桶中的元素逐个放入原序列中。
桶排序需要尽量保证元素分散均匀,否则当所有数据放在一个桶中,桶排序失效

时间和空间复杂度取决于 桶中应用的排序算法
public class HashBucket {
//定义一个节点对象
public static class Node{
int key;
int value;
Node next;
public Node(int key,int value){
this.key=key;
this.value=value;
}
}
//定义哈希桶
private Node[] bucket;
//当前有效的元素个数
static int size;
//定义负载因子
private final float DEFAULT_LOAD_FACTORY=0.75f;
public HashBucket(){
bucket=new Node[8];
}
/**
* 写入操作
* @param key
* @param value
* @return
*/
public int put(int key,int value){
//1、根据key的值计算下标
int index=key%bucket.length;
//2、拿到对应下标的元素,这个元素就是链表的头节点
Node current=bucket[index];
//3、遍历链表是否存在key相同的元素
while(current!=null){
//找到的情况下
if(current.key==key){
int oldValue=current.value;
current.value=value;
return oldValue;
}
current=current.next;
}
//4、遍历完链表之后,创建新节点
Node node=new Node(key,value);
//5、让新节点的next引用当前下标的节点
node.next=bucket[index];
//6、让当前下标存放新节点
bucket[index]=node;
//7、有效个数加一
//size是桶的有效个数
size++;
//8、判断当前有效桶的个数是否超过负载因子
if(locaderFactor()>=DEFAULT_LOAD_FACTORY){
//9、扩容
resize();
}
return 0;
}
/**
* 扩容数组
*/
private void resize() {
//1、按二倍大小扩容
Node[] array=new Node[bucket.length*2];
//2、取出所有元素,重新hash
for (int i = 0; i < bucket.length; i++) {
//2.1、取出hash桶中第一个节点,向下遍历
Node current=bucket[i];
while(current!=null){
//2.2、记录下一个节点
Node nextNode=current.next;
//2.3、对当前节点进行重新hash
int index=current.key/bucket.length;
//2.4、把节点放到新的桶位中
current.next=array[index];
array[index]=current;
//2.5、移动到下一个节点
current=nextNode;
}
}
//更新成员变量为新的数组
bucket=array;
}
private float locaderFactor() {
return size*1.0f/bucket.length;
}
/**
* 根据key查找相应的value
* @param key
* @return
*/
public int get(int key){
//根据key算出响应的下标
int index=key%bucket.length;
//开始遍历下标里面的链表
Node current=bucket[index];
while(current!=null){
if(current.key==key){
return current.value;
}
//向后移动节点
current=current.next;
}
return -1;
}
}
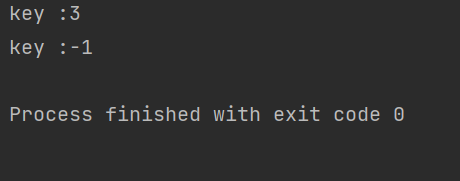
测试类:
public class TestHashBucket {
public static void main(String[] args) {
HashBucket hashBucket=new HashBucket();
hashBucket.put(1,2);
hashBucket.put(2,3);
hashBucket.put(3,4);
hashBucket.put(4,5);
hashBucket.put(5,6);
System.out.println("key :"+hashBucket.get(2));
System.out.println("key :"+hashBucket.get(20));
}
}
![[架构之路-204]- 常见的需求分析技术:结构化分析与面向对象分析](https://img-blog.csdnimg.cn/9355ae02c9ff42418f8d5f87968c690d.png)