.# 机器学习算法系列之 – 朴素贝叶斯
朴素贝叶斯法是基于概率统计,特征条件独立假设的分类方法,是一种非常常用的机器学习算法;通常用于处理文本分类和情感分析等自然语言处理任务中。相对于其他复杂的模型,朴素贝叶斯算法具有简单、易于实现、高效和良好的准确性等特点。
算法基础
概率论基础
条件概率
事件B已经发生的条件下,事件A发生的概率,称为事件A在给定事件B的条件概率,表示为P(A|B)
P
(
A
∣
B
)
=
P
(
A
∣
B
)
P
(
B
)
P(A|B)= \frac{P(A|B)}{P(B)}
P(A∣B)=P(B)P(A∣B)
其中,P(A∩B)=P(A|B)P(B)=P(B|A)P(A)
全概率公式
假设:样本空间S是由两个事件A与A’组成的和。如下图中,红色部分是事件A,绿色部分是事件A’,它们共同构成了样本空间S,且无交集

此时,依据全概率公式,事件B发生的概率P(B):
P
(
B
)
=
P
(
A
′
∩
B
)
+
P
(
A
∩
B
)
=
P
(
B
∣
A
′
)
P
(
A
′
)
+
P
(
B
∣
A
)
P
(
A
)
P(B)=P(A'∩B)+P(A∩B)=P(B|A')P(A')+P(B|A)P(A)
P(B)=P(A′∩B)+P(A∩B)=P(B∣A′)P(A′)+P(B∣A)P(A)
总结 全概率公式: P ( B ) = ∑ i = 1 n P ( B ∣ A i ) P ( A i ) P(B)=\sum_{i=1}^{n}P(B|A_i)P(A_i) P(B)=∑i=1nP(B∣Ai)P(Ai)
事件独立性
当公式P(A1,A2,…,An)=P(A1)P(A2)…P(An)成立时,则称A1,A2,…,An为相互独立的事件。表示每个事件发生的概率互不影响。
贝叶斯定理
关于概率方面的基础(正概率问题、逆概率问题,先验概率、后验概率)请读者自行了解,贝叶斯属于逆概率问题。我们先来看看贝叶斯公式的表达
P
(
A
∣
B
)
=
P
(
A
)
P
(
B
∣
A
)
P
(
B
)
P(A|B)=P(A)\frac{P(B|A)}{P(B)}
P(A∣B)=P(A)P(B)P(B∣A)
其中,P(A|B) 是指后验概率,即在给定观测到的 B 事件发生之后,A 事件发生的概率;P(A) 是指先验概率,即在没有任何其他信息的情况下,A 事件发生的概率;P(B|A) 是指似然度或条件概率,即在 A 事件已经发生的情况下,B 事件发生的概率;P(B) 是指证据因子,即 B 事件发生的概率,二者比值构成一个可能性函数。
贝叶斯定理核心思想
基于贝叶斯公式来进行分类。
它假设所有特征之间都是独立同分布的,从而化了模型计算的过程。
在文本分类中,我们可以使用朴素贝叶斯算法来计算一个文档属于某个类别的概率。
具体而言,我们可以首先根据训练数据集,计算每个单词(或者 n-gram 构成的词组)在每个类别中出现的概率,以及每个类别先验概率。然后可以使用贝叶斯公式来计算文档属于每个类别的概率,并选择概率最大的类别作为该文档的分类结果。
- 也就是,在主观判断的基础上,先估计一个值(先验概率),然后根据观察的新信息不断修正(可能性函数)
也就是:新信息出现后A的概率=A的概率 x 新信息带来的调整
贝叶斯决策论
算法概述
对于给定的训练数据集,首先基于特征条件独立假设学习输入输出的联合概率分布;然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y。实现方法简单有效,学习与预测的效率都很高,很常用。
贝叶斯决策论(Bayesian decision theory):概率框架下实施决策
的基本方法。对于分类任务,在所有相关概率已知的情形下,贝叶
斯决策论考虑如何基于概率和误判损失来选择最优的类别标记
- 期望损失
N种可能的类别标记 Y = { c 1 , c 2 , c 3 , . . . , c N } , λ i j Y=\{c_1,c_2,c_3,...,c_N\},\lambda_{ij} Y={c1,c2,c3,...,cN},λij表示将一个真实标记为 c j c_j cj的样本误分类为 c i c_i ci产生的损失,也叫“条件风险”:
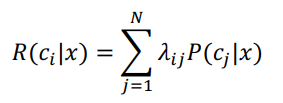
于是,贝叶斯判定准则:为最小化总体风险,只需要每个样本选择那
个能使条件风险R(c|x)最小的类别标记,即
h ∗ ( x ) = a r g m i n c ∈ Y R ( c ∣ x ) h^*(x)=arg min_{c\in Y}R(c|x) h∗(x)=argminc∈YR(c∣x)
此处h为贝叶斯最优分类器
假设目标是最小化分类错误率,则误判损失 λ i j \lambda_{ij} λij可以写为
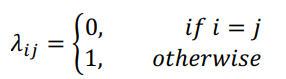
此时条件风险:
R
(
c
∣
x
)
=
1
−
P
(
c
∣
x
)
R(c|x)=1-P(c|x)
R(c∣x)=1−P(c∣x)
于是,最小化分类错误率的贝叶斯分类器为:
h
∗
(
x
)
=
a
r
g
m
a
x
c
∈
Y
P
(
c
∣
x
)
h^*(x)=arg\ max_{c\in Y}P(c|x)
h∗(x)=arg maxc∈YP(c∣x)
即对每个样本x,选择能使后验概率P(c|x)最大的类别标记
贝叶斯分类模型
朴素贝叶斯分类模型
朴素贝叶斯通过训练数据集学习联合概率分布P(X,Y)。具体要先学习先验概率分布P(Y= c k c_k ck)以及条件概率分布P(X=x|Y= c k c_k ck),进一步学习到联合概率分布。
其中后验概率的计算根据贝叶斯定理进行
朴素贝叶斯法实际上是生成数据的机制,所以属于生成模型。条件独立假设等于是说用于分类的特征,在类确定的条件下都是条件独立的。这一假设使朴素贝叶斯法变得简单,但有时会牺牲一定的分类准确率,在分类对给定的输入x通过学习到的模型计算后验概率分布P(c|x),将后验概率最大的类作为x的类输出。
最后得到 朴素贝叶斯分类器的表达式:
y
=
a
r
g
m
a
x
c
k
P
(
Y
=
c
k
)
∏
j
P
(
X
j
=
x
j
∣
Y
=
c
k
)
y=arg\ max_{c_k}P(Y=c_k)\prod_jP(X^j=x^j|Y=c_k)
y=arg maxckP(Y=ck)j∏P(Xj=xj∣Y=ck)
后验概率最大化的含义(朴素贝叶斯原理)
等价于期望风险最小化。
首先,假设选择0-1损失函数:
L
(
Y
,
f
(
X
)
)
=
{
1
,
Y
≠
f
(
X
)
0
,
Y
=
f
(
X
)
L(Y,f(X))= \begin{cases} 1,Y\neq f(X)\\ 0,Y=f(X) \end{cases}
L(Y,f(X))={1,Y=f(X)0,Y=f(X)
f(X)为分类决策函数。此时期望风险函数为
R
e
x
p
(
f
)
=
E
[
L
(
Y
,
f
(
X
)
)
]
R_{exp}(f)=E[L(Y,f(X))]
Rexp(f)=E[L(Y,f(X))],此处期望是对联合分布P(X,Y)取的。再由此取得条件期望
R
e
x
p
(
f
)
=
E
X
∑
k
=
1
K
[
L
(
c
k
,
f
(
X
)
)
]
P
(
c
k
∣
X
)
R_{exp}(f)=E_X\sum^K_{k=1}[L(c_k,f(X))]P(c_k|X)
Rexp(f)=EXk=1∑K[L(ck,f(X))]P(ck∣X)
可以看出,为了使得期望风险最小化,我们只需要对X=x逐个极小化,由此便可得到:
f
(
x
)
=
a
r
g
m
i
n
y
∈
Y
∑
k
=
1
K
L
(
c
k
,
y
)
P
(
c
k
∣
X
=
x
)
=
a
r
g
m
i
n
y
∈
Y
∑
k
=
1
K
P
(
y
≠
c
k
∣
X
=
x
)
=
a
r
g
m
i
n
y
∈
Y
(
1
−
P
(
y
=
c
k
∣
X
=
x
)
)
=
a
r
g
m
a
x
y
∈
Y
P
(
y
=
c
k
∣
X
=
x
)
f(x)=arg\ min_{y\in Y}\sum^K_{k=1}L(c_k,y)P(c_k|X=x)\\ =arg\ min_{y\in Y}\sum^K_{k=1}P(y\neq c_k|X=x)\\ =arg\ min_{y\in Y}(1-P(y=c_k|X=x)) =arg\ max_{y\in Y}P(y=c_k|X=x)
f(x)=arg miny∈Yk=1∑KL(ck,y)P(ck∣X=x)=arg miny∈Yk=1∑KP(y=ck∣X=x)=arg miny∈Y(1−P(y=ck∣X=x))=arg maxy∈YP(y=ck∣X=x)
这样一来,根据期望风险最小化准则就得到了后验概率最大化准则:
f
(
x
)
=
a
r
g
m
a
x
y
∈
Y
P
(
c
k
∣
X
=
x
)
f(x)=arg\ max_{y\in Y}P(c_k|X=x)
f(x)=arg maxy∈YP(ck∣X=x)
也就是==“朴素贝叶斯法”所采取的原理==
由此,朴素贝叶斯分类器的训练过程,就是基于训练集估计先验概率P©,并为每个属性估计条件概率 P ( x j ∣ c ) P(x^j|c) P(xj∣c)
-
估计先验概率:
令Dc是训练集D中第c类样本组成的集合,若有充足的独立同分
布样本,则先验概率P© 为
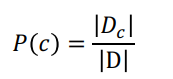
-
估计条件概率
离散型:令 D c , x i D_{c,x_i} Dc,xi表示 D c D_c Dc在第i个属性上取值为 x i x_i xi的样本组成的集合,则条件概率 P ( x i ∣ c ) P(x_i|c) P(xi∣c)为
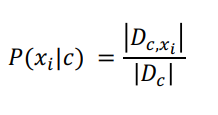
连续型:对于连续属性考虑概率密度函数,假定
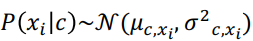
μ c , x i 和 σ c , x i 2 \mu_{c,x_i}和\sigma^2_{c,x_i} μc,xi和σc,xi2分别为第c类样本在第i个属性上取值的均值和方差,则
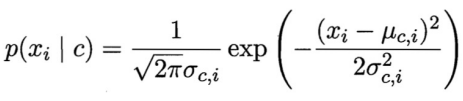
算法步骤
综上,我们可以总结出朴素贝叶斯分类模型求解的基本步骤
1、计算先验概率
2、计算条件概率
3、对于给定实例,计算
P
(
Y
=
c
k
)
∏
j
P
(
X
j
=
x
j
∣
Y
=
c
k
)
,
k
=
1
,
2
,
.
.
.
,
K
P(Y=c_k)\prod_jP(X^j=x^j|Y=c_k),k=1,2,...,K
P(Y=ck)∏jP(Xj=xj∣Y=ck),k=1,2,...,K
4、确定实例x的类y=
a
r
g
m
a
x
c
k
P
(
Y
=
c
k
)
∏
j
P
(
X
j
=
x
j
∣
Y
=
c
k
)
arg\ max_{c_k}P(Y=c_k)\prod_jP(X^j=x^j|Y=c_k)
arg maxckP(Y=ck)∏jP(Xj=xj∣Y=ck)
贝叶斯估计
若当某个属性值在训练样本中从未出现过时,估计条件概率时,连乘结果都会为0,此时会影响到后验概率计算的结果,产生偏差分类。
解决办法:贝叶斯估计。
具体而言,条件概率的贝叶斯估计是:
P
λ
(
X
j
=
a
j
l
∣
Y
=
c
k
)
=
∑
i
=
1
N
I
(
x
i
j
=
a
j
l
,
y
i
=
c
k
)
+
λ
∑
i
=
1
N
I
(
y
i
=
c
k
)
+
S
j
λ
P_\lambda(X^j=a_{jl|Y=c_k})=\frac{\sum^N_{i=1}I(x_i^j=a_{jl},y_i=c_k)+\lambda}{\sum^N_{i=1}I(y_i=c_k)+S_j\lambda}
Pλ(Xj=ajl∣Y=ck)=∑i=1NI(yi=ck)+Sjλ∑i=1NI(xij=ajl,yi=ck)+λ
通常取
λ
\lambda
λ为1,此时称为拉普拉斯平滑。
同样,先验概率的贝叶斯估计是
P
λ
(
Y
=
c
k
)
=
∑
i
=
1
N
I
(
y
i
=
c
k
)
+
λ
N
+
K
λ
P_\lambda(Y=c_k)=\frac{\sum^N_{i=1}I(y_i=c_k)+\lambda}{N+K\lambda}
Pλ(Y=ck)=N+Kλ∑i=1NI(yi=ck)+λ
朴素贝叶斯分类模型的使用
- 若对预测速度要求高:预计算所有概率估值,使用时“查表”
- 若数据更替频繁:不进行任何训练,收到预测请求时再估值(懒惰学习 , lazy learning)
- 若数据不断增加:基于现有估值,对新样本涉及的概率估值进行修正(增量学习 , incremental learning
优缺点
优点:
• 朴素贝叶斯模型有稳定的分类效率;
• 对小规模的数据表现很好,能处理多分类任务;
• 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
缺点:
• 朴素贝叶斯假定每个变量之间是相互独立的,但是现实中的数据
往往都具有一定的相关性,很少有完全独立的;
• 由于我们是通过先验和数据来决定后验的概率从而决定分类,所
以分类决策存在一定的错误率
算法实战
朴素贝叶斯算法实战可参考该博客:《《机器学习实战》第四章 Python3代码-(亲自修改测试可成功运行)
总结
总结来说,朴素贝叶斯算法是一种简单、高效、易于实现的器学习算法,特别适用于文本分类和情感分析等自然语言处理任务。在实际应用中,我们可以使用不同变体的朴素贝叶斯算法来处理不同类型的数据。
参考
《统计学习方法》,李航, 清华大学出版社,第二版
《机器学习》,周志华,清华大学出版社
以上就是关于决策树的分享,若有不妥之处,欢迎各路大佬不吝赐教~
喜欢的伙伴点个赞,顺便收藏、关注一下吧~