你是否碰到过点击网站上的按钮或链接,网页数据进行了刷新,但浏览器上显示的网址却没有任何变化的情况,这其实就是利用Ajax跳转的网页。本期笔者将以东方财富网为例展示如何获取Ajax跳转的网页内容,本文主要内容如下:
目录
1. Ajax跳转的网页
2. Selenium模拟爬取
3. 寻找真实数据接口
4.代码实现
1. Ajax跳转的网页
上一期的数据获取文章通过爬取网页上的交互式图表,获取了东方财富网上的基金净值数据,但有粉丝私信说这个数据并不全,东方财富只抽取了部分日期的净值数据进行了展示。本期笔者将通过另一种方法爬取所有的NAV数据。
其实东财是有完整的历史净值数据的,但是一旦选择图一右上角成立以来的数据,东财就开始偷懒。可能是出于获得更快的网页响应速度,东财选择只抽取部分的净值数据进行展示。有时是在一个月中抽取一天,有时候是抽取两天。

图一:东方财富网基金净值图表
显然通过这种方式已经无法拿到所有完整数据了,但笔者很快就发现东财上另一个网址:
(000189)基金历史净值 ,这个网址通过表格的形式将所有历史数据展示出来,但这种表格的难点在于无论怎么点击下面的页数,浏览器上显示的网址都没有任何变化。如图二:
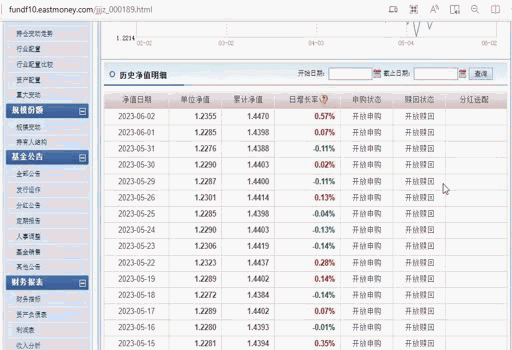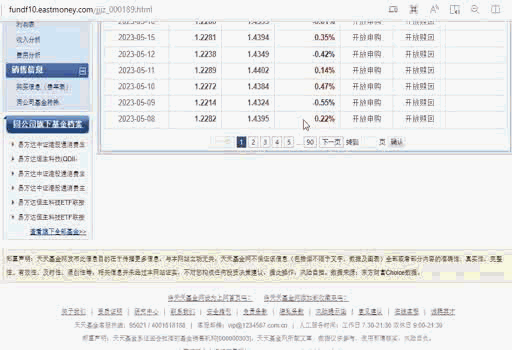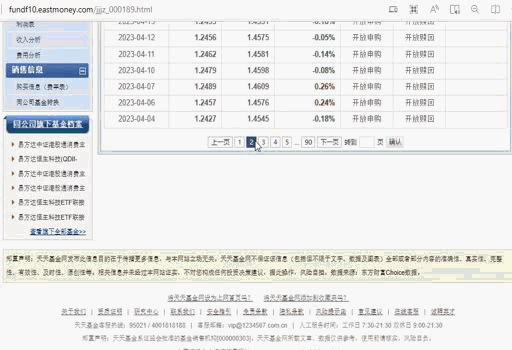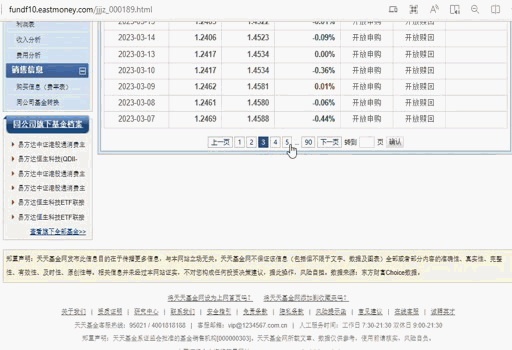
图二:基金净值列表与浏览器网址
2. Selenium模拟爬取
点击下一页,浏览器上显示的网址却没有任何变化,这其实就是Ajax跳转的网页,普通的通过解析浏览器网址已经失效。
但这个本质上与js动态加载类似,都是需要某些事件触发才会刷新数据,并且浏览器网址还能保持不变。笔者之前出过一期selenium模拟爬虫,模拟爬虫用在这种网页上也是有效的,通过模拟点击网页的方式不断的获取后面的页数就可以不断地获取数据,但缺点是非常缓慢。
3. 寻找真实数据接口
还有一种非常直接的思路:既然网站需要将数据展示出来,这中间就一定需要一个步骤——请求服务器上的数据,只要我们可以拦截到浏览器向服务器发送的真实请求就可以轻易破解。该方法的难点在于如何在这么多的请求中找到那个真实请求,网上其实有很多抓包工具可以解析然后搜索到那个请求。但笔者本次爬取的东方财富网较为简单,只需要打开网络监控,然后点击下一页就可以轻易获取到真实请求的地址。
首先打开网页:(000189)基金历史净值 。等待网页刷新完成后再按F12,此时是没有任何请求的。
重点来了,点击第二页按钮,这时就会发现网络监控捕获到请求,如下图的第三个红框:
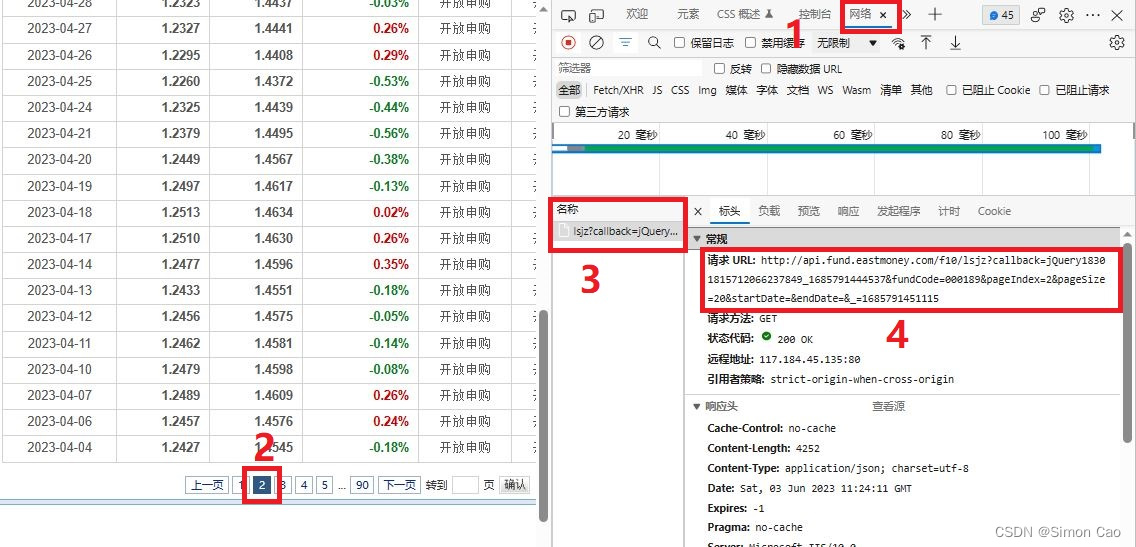
图三:获取请求的步骤
点击第三个红框就会展示出该请求的详细信息,第4个红框即是净值数据的接口地址。
就这样,什么抓包工具都不需要,轻松且愉快就获得了接口地址。
下面是笔者获取到的地址信息:
http://api.fund.eastmoney.com/f10/lsjz?callback=jQuery18301815712066237849_1685791444537&fundCode=000189&pageIndex=2&pageSize=20&startDate=&endDate=&_=1685791451115其中,fundCode参数是基金代码,pageIndex是第几页,pageSize是一页上返回多少条数据。下面就非常简单了,不断循环pageIndex参数就可以将所有数据全部拿下来。
4.代码实现
因为这个接口是可以设置每页返回数据量的,这里可以设置一个大一些的数字,这样可以避免频繁请求给服务器造成压力,下面笔者将参数设置成500。下面也用到headers模拟请求技术,不明白的可以看笔者上一期数据获取文章。获取到网页数据后就是字符串的日常操作了,感觉没什么好讲解的,直接写成模块:
def craw_data(code, page_num): # 基金代码,页码
url = "http://api.fund.eastmoney.com/f10/lsjz?callback=jQuery18308048793570706319_1685784091702&fundCode="+code+"&pageIndex="+page_num+"&pageSize=500&startDate=&endDate=&"
headers = {"Referer": "http://fundf10.eastmoney.com/"}
re = requests.get(url, headers = headers)
df = re.text
if len(df) > 300: # 获取内容超过300个字符一般说明成功获得数据了
df = df.split('LSJZList":[{"')[1].split('}],"FundType"')[0] # 提取数据主体
df = df.replace('null', '"null"') # 添加“”号方便后续拆分
df = df.replace('""', '"null"') # 空值统一替换为null
data_set = []
for data in df.split('"},{"'):
data = data.split('","')
row = {}
for i in data:
i = i.split('":"')
row[i[0]] = i[1]
data_set.append(row)
data_set = pd.DataFrame(data_set)
data_set = data_set[["FSRQ", "DWJZ", "LJJZ", "JZZZL"]]
data_set.columns = np.array(["日期", "单位净值", "累计净值", "日增长率"])
data_set["日增长率"] = data_set["日增长率"].replace("null", 0)
data_set[["单位净值", "累计净值", "日增长率"]] = data_set[["单位净值", "累计净值", "日增长率"]].astype("float") # 转化为浮点类型数据
data_set.set_index("日期", inplace=True)
return pd.DataFrame(data_set)
else: # 没有获得数据
return pd.DataFrame()下面循环调用,加入一个判断条件,如果返回的空数据集,说明所有数据都爬取完了,停止循环:
code = "000165"
nav_data = pd.DataFrame()
for page_num in range(1, 1000): # 一般不太可能超过1000页
data_set = craw_data(code, str(page_num))
if len(data_set) != 0:
nav_data = pd.concat([nav_data, data_set], axis=0)
else: # 停止循环
break
print("正在获取{}页, 共获取{}条数据\r".format(page_num, len(nav_data)), end="")运行后获取数据如下:
单位净值 累计净值 日增长率
日期
2023-06-02 2.1610 3.5660 3.5660
2023-06-01 2.1440 3.5490 3.5490
2023-05-31 2.1430 3.5480 3.5480
2023-05-30 2.1530 3.5580 3.5580
2023-05-29 2.1510 3.5560 3.5560
... ... ... ...
2013-10-25 0.9980 0.9980 0.9980
2013-10-18 1.0030 1.0030 1.0030
2013-10-11 1.0040 1.0040 1.0040
2013-09-30 1.0000 1.0000 1.0000
2013-09-27 1.0000 1.0000 1.0000
2345 rows × 3 columns可以看到,笔者成功获取了完整的净值数据,共2345条数据。
只要有所有的基金代码列表,这个程序可以将所有的基金数据全部拿到,但笔者建议最好加入一些随机暂停模块,防止封IP。。。
最后展示一下获取到的净值走势:
nav_data = nav_data[::-1]
nav_data["累计净值"].plot()运行得图四:
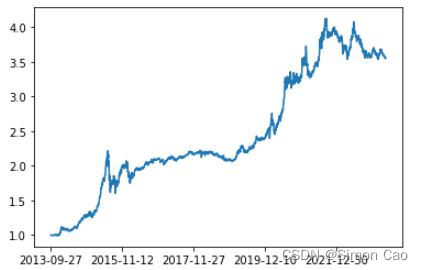
图四:累计净值走势
5. 系列往期速览
| 数据获取系列往期文章 | |
| 专栏名称 | 文章传送门 |
| 金融数据获取 | 获取网站交互式图表背后的数据 |
| 当爬虫遇上要鼠标滚轮滚动才会刷新数据的网页 | |
| Fama-French及PSM | |
| Grinold Kroner(GK)模型(本期) | |
| 增速g的测算 | |
| PE指标平滑 | |
| PE Band | |