目录
依赖注入大致要点
依赖注入大致流程
Bean的预实例化
doGetBean
createBean
完备Bean的创建过程
createBeanInstance
populateBean
-
依赖注入大致要点
- Spring在Bean实例的创建过程中做了很多精细化控制
- finishBeanFactoryInitialization方法里面的preInstantiateSingletons()会去初始化那些非延时加载的bean实例
- 而ApplicationContext容器默认管理的bean都是非延迟的单例,所以如果没有特别的设置,bean都会在这里被调用getBean方法去实例化
- AbstractBeanFactory: 抽象类,里面提供一个获取bean实例的方法doGetBean,根据不同的scope进行不同的处理
- DefaultSingletonRegistry:单例bean默认的实现类,里面是bean而不是beanDefinition,里面有一个方法会尝试从三级缓存里获得bean实例,(三级缓存是为了解决循环依赖的问题,循环依赖:类A里面套类B,类B又有A的情况)
- 如果缓存里没有bean实例,那么容器就会创建出来,因此就会来到AbstractAutowiredCapableBeanFactory,在doCreateBean方法里面光创建Bean实例是不够的,还需要看看实例的属性有没有被@Autowired或者@Value标记
- AbstractAutowiredCapableBeanFactory:自动装配的服务
- applyMergeBeanDefinitionPostProcessors: 对合并后的BeanDifination做后置处理
- populateBean: 考虑被标记之后,对属性进行依赖注入
- AutowiredAnnotationBeanPostProcessor: 做属性的后置处理,再来到DefaultListableBeanFactory这里去解析依赖关系(因为BeanDefinition都保存在这里),找到bean之间的依赖关系之后使用DependencyDescriptor里面的injectionPoint进行注入
-
依赖注入大致流程
- IOC容器在初始化过程中建立了BeanDefinition的数据结构,接下来就需要进行依赖注入,处理Bean之间的依赖关系
- 通常,可以通过lazy-init属性控制Bean的实例化(依赖注入)时机
- 当lazy-init=true时,依赖注入会发生在第一次向容器获取Bean时(getBean)
- 当lazy-init=false时,会在容器初始化的过程中将所有的singleton bean提前进行实例化和依赖注入,因此singleton bean的依赖注入是容器初始化过程的一部分,这也是我们常用的ApplicationContext的默认配置
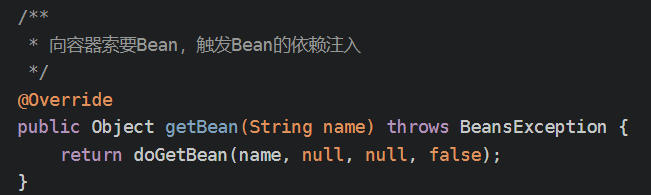
- getBean触发依赖注入
- 1-getBean
- 2-createBean
- 到这里就已经得到依赖注入后的Bean实例了,这个过程看起来十分简单
- 但实际上有两个要点需要格外关注:
- 其一,创建Bean实例(createBeanInstance)
- 其二,进行依赖注入(populateBean)
- 1-getBean
-
Bean的预实例化
- Bean配置了lazy-init=false属性时,IOC容器会在初始化的时候对Bean进行预实例化,这时将会提前触发Bean的依赖注入过程
- 回到AbstractApplicationContext的refresh方法中,这里是IOC容器初始化的入口,在这个方法中可以看到调用了finishBeanFactoryInitialization方法,这个方法将会对非延迟加载的单例Bean进行预实例化
- 在预实例化的过程中调用了getBean方法来触发Bean的依赖注入
-
doGetBean
- 规范化beanName:transformedBeanName
- BeanFactoryUtils.transformedBeanName方法是去除FactoryBean类型的bean的前缀“&”,里面有do…while循环保证beanName前缀无“&”
- canonicalName方法是将bean中配置的别名转化为实际的beanName,也是采用do…while循环进行获取
- doGetBean方法开始会调用getsingleton()方法尝试获取bean实例
- Spring中对于单例的bean是采用三个缓存分别来实现bean的管理,一级缓存(singletonObjects)、二级缓存(earlySingletonObjects)、三级缓存(singletonFactories)
- 三种缓存作用如下:
- (1)一级缓存singletonObjects主要是存储Spring中一些实例化完成好的bean,也是常说的IOC容器,实际上就是一个并发map
- (2)二级缓存earlySingletonObjects主要是存储提前暴露的,未完成好的bean,如循环依赖时属性未注入时的bean
- (3)三级缓存singletonFactories主要是为了解决循环依赖,保存一些bean的创建单例时的ObjectFactory,用于获得bean
- 完备的bean实例会被保存在一级缓存singletonObjects,不完备的bean实例被保存在二级缓存earlySingletonObjects或者三级缓存singletonFactories里
- 并且实例只能存在于三层中的某一层
- getSingleton方法是委托DefaultSingletonBeanRegistry类来实现,默认支持单例循环依赖
- 如果该bean实例为空,则继续执行下面的代码
- 如果bean实例不为空,则调用getObjectForBeanInstance()方法;获取Bean实例
- 这里提到的实例不为空解释一下,当使用applicationcontext的实现类或者是beanfactory来加载bean.xml文件(或者是application.xml文件,总之是用xml的形式将某个类加入到Spring应用上下文中),有可能会采用非延迟加载的形式
- 而非延迟加载就意味着某个bean在applicationcontext的实现类调用getbean方法之前(applicationcontext的实现类加载bean.xml文件之后),bean就已经实例化了
- 然后这里的getObjectForBeanInstance存在的意义在于:
- 从缓存中得到了bean是原始状态,并不一定是我们最终想要的bean,需要对bean进行实例化
- 我们需要对工厂bean进行处理,真正需要的是工厂bean中定义的factory-method方法中返回的bean,而getObjectForBeanInstance就是完成这个工作的
- getObjectForBeanInstance最终调用Factorybean中的getobject()方法
- 其实如果我们对xml中的bean进行实例化,可以在xml的factory-method中声明一个自定义类,然后该类需要实现FactoryBean中的getobject方法,所以说FactoryBean就是负责将Spring应用上下文中的bean进行实例化的
- getObjectForBeanInstance()方法中,通过源码可知,如果当前 Bean的类型是FactoryBean,则在getBean时不是直接返回当前 Bean实例,而是先获取Bean实例,然后调用其工厂方法

- 然后在getObjectFromFactoryBean中调用

- doGetObjectFromFactoryBean中调用
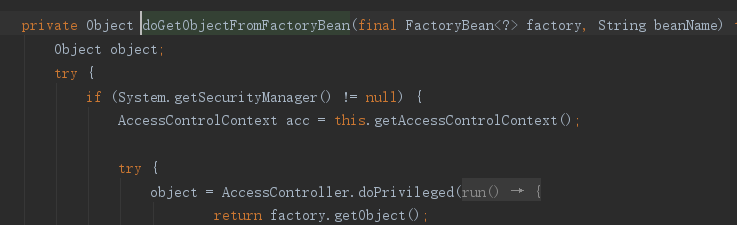
- FactoryBean中的getObject()方法
- 如果Bean实例为空,上述所有代码就不会执行,而是执行接下来的代码
- 接下来的代码会去获取当前bean工厂的父工厂,这里是递归的获取父工厂 ,获取了当前bean工厂的祖先工厂
- 递归获取bean:getParentBeanFactory
- 自定义容器与spring的AbstractBeanFactory递归获取bean,父类容器中获取bean即AbstractBeanFactory中的doGetBean,此处其实是防止自定义容器实现doGetBean中未找到则在AbstractBeanFactory容器中再次获取
- 若ParentBeanFactory不为空且beanDefinitionMap中没有这个bean,则调用 ParentBeanFactory 的getbean()方法
- 若ParentBeanFactory为空或者beanDefinitionMap中有这个bean,则执行接下来的代码
- 接下来的getBean()方法用于解决当前bean所依赖的其他bean的实例化

- 然后就是几个if判断,用于判断当前bean的scope,诸如singleton,prototype,session和request之类的
- 这里是对于singleton类型的bean所做的处理

- 对于singleton类型的bean,new ObjectFactory<Object>()是接口式的匿名内部类(java中有三种匿名内部类的方式)
- 重写了getObject()方法,里面调用了createBean()
- 这里的createBean()方法,是AbstractAutowiredCapableBeanFactory中的createBean()
- createBean调用的第一个方法是

- 第二个方法

- 第三个方法

- 关于doCreateBean()方法,它调用的第一个方法是

- 该方法里面利用ConstutorResolver类中的autowireconstructor()完成了构造方法的注入
- 然后调用

- populateBean使用bean定义中的属性值填充给定BeanWrapper中的bean实例
- initializeBean负责初始化给定的bean实例,应用工厂回调以及init方法和bean后处理器
- 优化缓存bean:markBeanAsCreated
- Spring在创建bean前会处理下该bean是否允许重复创建即合并覆盖原有的bean,使用alreadyCreated变量(Set)存储防止重复
- depends-on依赖实例化:isDependent
- isDependent方法检查该bean是否有循环依赖,如果存在相互先实例化的关系则抛出异常
- 此处的depend-on属性中是指当前bean实例化之前必须先实例化该属性值中bean,与我们常说的循环依赖是不一样的,该处仅仅是检查该bean必须在另一个bean实例化的前面,可以被注入也可以不被注入
-
createBean

- 方法结构:
- 在AbstractBeanFactory中,createBean的方法并未实现,而是将具体创建bean的工作留给了子类,是一个典型的模版方法:

- 在AbstractAutowireCapableBeanFactory 中实现了该方法

- 为什么使用RootBeanDefinition接收BeanDefinition实例?
- 因为有的bean有parent属性,将child和parent属性合并后归并到chile里面,而如果是普通的bean,RootBeanDefinition也可以接收
- 代码对应步骤:
- 根据设置的class属性或者className来解析、加载class
- 对override属性进行标记和验证(bean XML配置中的lookup-method和replace-method属性)
- 应用初始化前的后处理器,如果处理器中返回了AOP的代理对象,则直接返回该单例对象,不需要继续创建
- 创建bean
- 初始化前的后处理器:InstantiationAwareBeanPostProcessor
- createBean方法中调用了resolveBeforeInstantiation 方法做些前置处理,并且如果在这个方法中返回了bean的话(AOP代理对象或者自定义对象),就直接返回这个bean,不再继续后面的创建步骤

- 1-实例化前的后处理器
- 2-实例化后的后处理器
- 如果实例化前的后处理器创建了一个代理对象,才会继续应用实例化后的后处理器
- 应用后处理器的方法与1中类似,只不过调用的是 postProcessBeforeInstantiation ,而后者调用的是 postProcessAfterInstantiation
- doCreateBean
- 1-如果是单例则首先清除缓存
- 2-实例化bean,并使用BeanWarpper包装
- 如果存在工厂方法,则使用工厂方法实例化
- 如果有多个构造函数,则根据传入的参数确定构造函数进行初始化
- 使用默认的构造函数初始化
- 3-应用MergedBeanDefinitionPostProcessor,Autowired注解就是在这样完成的解析工作
- 4-依赖处理;如果A和B存在循环依赖,那么Spring在创建B的时候,需要自动注入A时,并不会直接创建再次创建A,而是通过放入缓存中A的ObjectFactory来创建实例,这样就解决了循环依赖的问题
- 5-属性填充;所有需要的属性都在这一步注入到bean
- 6-循环依赖检查
- 7-注册DisposableBean;如果配置了destroy-method,这里需要注册,以便在销毁时调用
- 8-完成创建并返回
-
完备Bean的创建过程
- getBean方法被执行时会调用doGetBean方法,它先尝试从缓存中获取bean实例(getSingleton)
- 如果缓存中没有,doGetBean方法会去调用createBean方法,在调用里面的doCreateBean方法进行创建bean实例
- doCreateBean方法执行之后会将ObjectFactory这个实例给注册到三级缓存
- 在调用doGetBean时就会来到缓存里去调用singletonFactory.getObject()(也就是getEarlyBeanReference开始执行)获取bean实例,再将实例存到二级缓存里,清空三级缓存实例,将完备的bean实例逐层返回
- 最后返回到doGetBean方法里,调用getSingleton方法(不同于上面那个)里的addSingleton,将返回的实例添加到一级缓存里,将完备bean二级、三级缓存给移除
-
createBeanInstance
- 在doCreateBean方法中,首先会创建bean的实例,负责创建的方法为createBeanInstance
- 代码逻辑如下:
- 如果bean定义中存在 InstanceSupplier ,会使用这个回调接口创建对象(应该是3.X以后新加的,3.X的源码中没有)
- 根据配置的factoryMethodName或factory-mtehod创建bean
- 解析构造函数并进行实例化
- 因为一个类可能有多个构造函数,所以需要根据配置文件中配置的参数或者传入的参数确定最终调用的构造函数
- 因为判断过程会比较消耗性能,所以Spring会将解析、确定好的构造函数缓存到BeanDefinition中的resolvedConstructorOrFactoryMethod字段中
- 在下次创建相同bean的时候,会直接从RootBeanDefinition中的属性resolvedConstructorOrFactoryMethod缓存的值获取,避免再次解析
- 在这个过程中,通过默认构造方法(无参构造)是基本的实例化策略,这个策略Spring的实现中提供了两种创建Bean的方式:
- 其一,通过JVM反射创建Bean实例
- 其二,通过cgLib动态代理创建Bean实例
-
populateBean
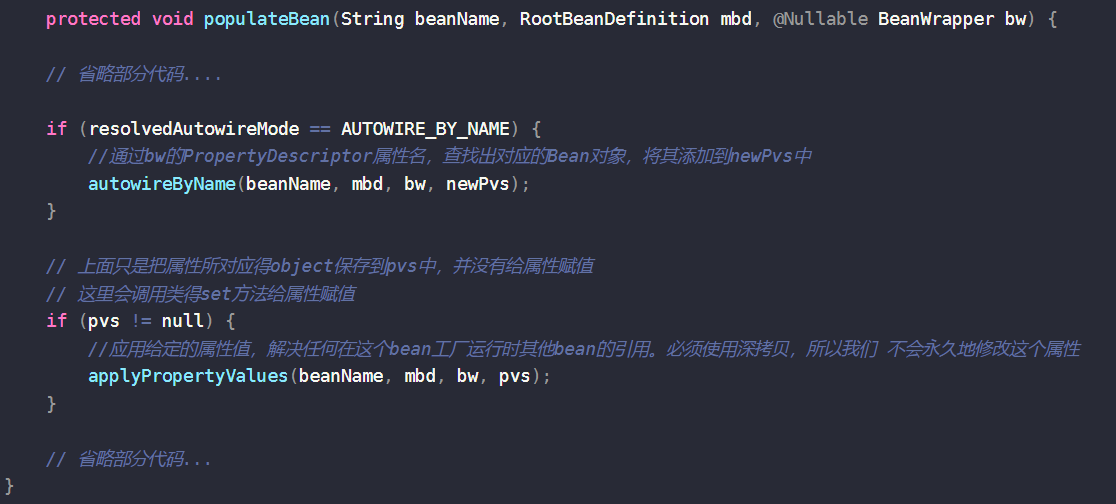
- IOC 容器初始化启动时,抽象类 AbstractAutowireCapableBeanFactory 的 doCreateBean() 方法里面的 populateBean() 方法
- 它是进行 bean 的属性数据填充注入的方法
- 属性填充主要是对自动注入(autowired)的处理,大致可以把他分为三类:
- autowireByName:通过名字对属性填充
- AbstractAutowireCapableBeanFactory#populateBean():完成属性的自动注入
- 通过属性的name找到对应的Bean对象,保存到pvs的propertyValueList里面
- 然后再遍历propertyValueList,通过反射调用当前对象的set方法给属性赋值
- AbstractAutowireCapableBeanFactory#autowireByName():获取当前beanName的非简单类型属性名
- 并且遍历这些属性名,能在容器中找到当前属性名的对象,则添加到pvs的propertyValueList中
- autowireByName主要完成以下逻辑:
- 1-获取需要填充对象的非简单类型的属性名
- 2-遍历第一步获取的属性名,调用getBean方法从容器中获取此属性名对应的object
- 3-然后,如果能找到,则把此属性名和object对象保存到pvs的propertyValueList里面
- autowireByType:通过类型对属性填充
- 1---AbstractAutowireCapableBeanFactory#populateBean():完成属性的自动注入
- 通过bw的PropertyDescriptor属性类型,查找出对应的Bean对象
- 将其添加到pvs的propertyValueList中,然后遍历propertyValueList通过反射调用当前对象的set方法给属性赋值
- 2---AbstractAutowireCapableBeanFactory#autowireByType():
- 获取当前对象的非简单类型的属性名数组propertyNames
- 遍历属性名数组propertyNames,获取当前属性名所对应的类型filedType
- 通过filedType找到匹配的候选Bean对象
- 把属性名以及bean对象添加到pvs的propertyValueList里面
- 3---DefaultListableBeanFactory#doResolveDependency():根据属性类型去查找合适的候选bean对象
- 首先考虑以下预先解决的信息尝试调用该工厂解决这种依赖关系的快捷方式来获取beanName对应的bean对象
- 尝试使用descriptor的默认值作为最近候选Bean对象
- 针对类型是stream,数组,Collection类型且对象类型是接口,Map类型 进行解析与依赖类型匹配的 候选Bean对象
- 查找与type匹配的候选bean对象
- 如果以上都没找到,则抛出异常
- 4---DefaultListableBeanFactory#resolveMultipleBeans():需要注入的类型是stream,array,collection,map类型的话,解析出来他们的引用类型(如List则会解析出people类型),然后从beanFactory中查找所有是people类型的对象组成相应的集合返回(如,List会查找出所有的people对象组装成List类型返回)
- stream类型:调用findAutowireCandidates查找出beanFactory中所有符合类型的bean组装成stream返回
- array类型:调用findAutowireCandidates查找出beanFactory中所有符合类型的bean组装成array返回
- collection类型:调用findAutowireCandidates查找出beanFactory中所有符合类型的bean组装成Collection返回
- Map类型:调用findAutowireCandidates查找出beanFactory中所有符合类型的bean组装成Map返回
- @Autowired:通过bean的后置处理器AutowiredAnnotationBeanPostProcessor对@Autowired注解属性填充
- AutowiredAnnotationBeanPostProcessor#postProcessProperties():从缓存中取出这个bean对应的依赖注入的元信息
- InjectionMetadata:其中属性injectedElements记录了当前类需要注入的所有属性
- InjectionMetadata#inject():遍历需要注入的所有属性elementsToIterate,一个一个属性注入
- AutowiredAnnotationBeanPostProcessor#inject():调用beanFactory.resolveDependency()方法找出所要注入的候选bean然后通过反射给属性赋值
- beanFactory.resolveDependency()方法上面已经分析过了,此处省略
- applyPropertyValues()给放入pvs中的属性赋值
- 上面分析过,通过autowireByName,autowireByType注入时都会把找到的属性和对象放入到pvs的propertyValueList
- 所以此处applyPropertyValues()方法是对里面的属性进行赋值操作的