note
文章目录
- note
- 一、DLRM模型
- 1. 特征工程和embedding层
- 2. butterfly shuffle
- 3. 模型结构
- 二、模型部署
- Reference
一、DLRM模型
DLRM是2020年meta提出的工业界推荐算法模型,模型结构非常简单,也没用到什么attention机制等的东西,更多是注重在推荐系统稀疏特征场景下的落地。
1. 特征工程和embedding层
- 模型的特征工程部分被分成了两块,一块是基于类别等离散属性的one-hot编码形成的稀疏矩阵;一块是基于数值等连续属性的稠密矩阵;
- sparse feature:离散的类别特征,通过embedding层转为稠密embedding;通过Embedding将其映射成一个稠密的连续值。假设one-hot编码后的向量是
e
i
e_i
ei, 向量中除了第
i
\mathrm{i}
i 个位 置为1外, 通过Embedding后得到的embedding向量为
w
i
w_i
wi如下,其中
W ∈ R m × d W \in \mathbb{R}^{\mathrm{m} \times \mathrm{d}} W∈Rm×d:
w i T = e i T W \mathrm{w}_{\mathrm{i}}^{\mathrm{T}}=\mathrm{e}_{\mathrm{i}}^{\mathrm{T}} \mathrm{W} wiT=eiTW- 特征交叉:类似deepfm中的FM层特征交叉
- dense feature:DLRM中选择的处理方法是通过MLP多层感知机将所有的连续特征转化成一个与离散特征同样维度的embedding向量, 如下图的黄色部分。

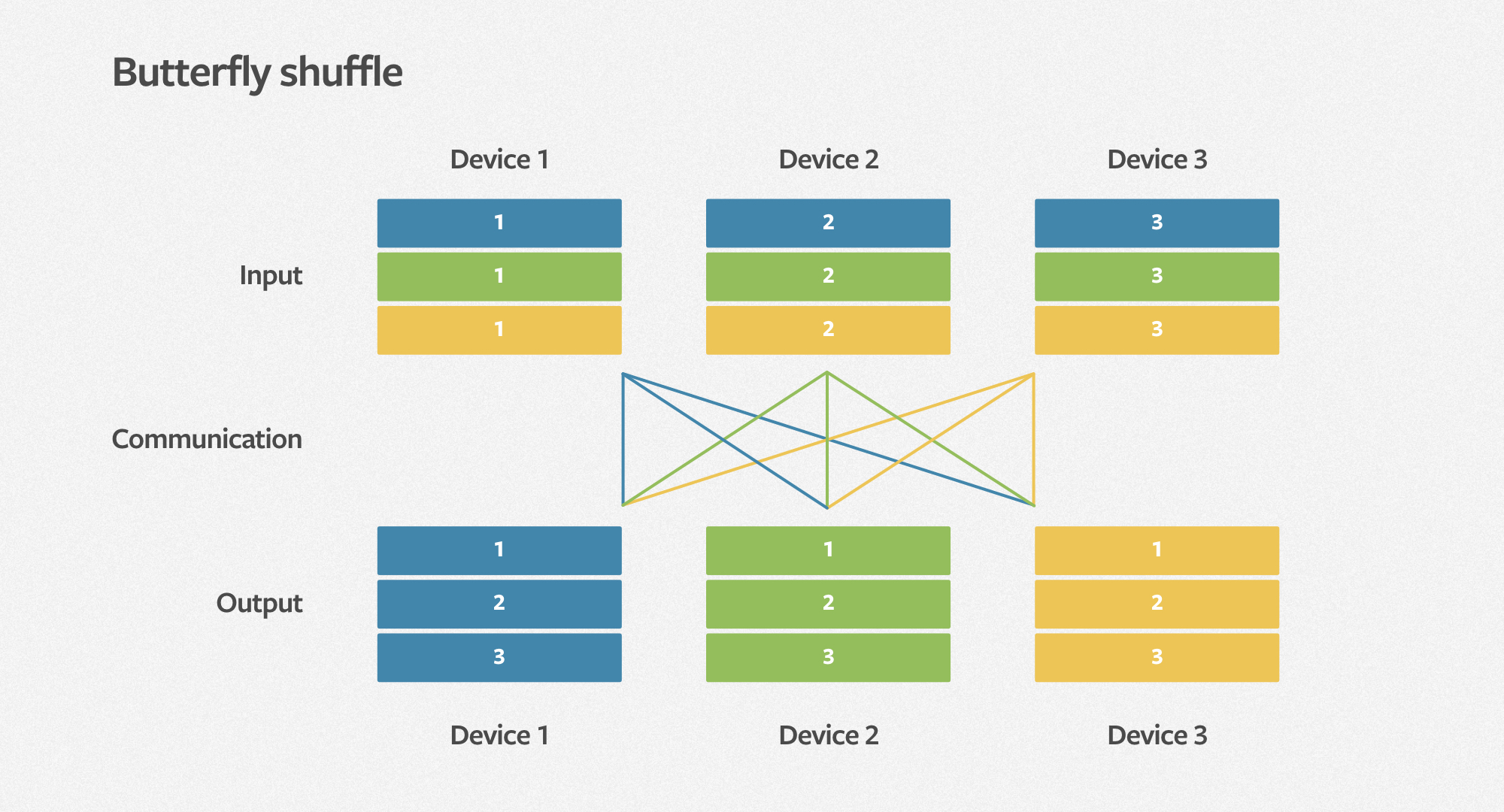
2. butterfly shuffle
为了提高MLP的并行和embedding table的高效存储,DLRM使用一种all-to-all的通信原语,butterfly shuffle。
3. 模型结构
eb_configs = [
EmbeddingBagConfig(
name=f"t_{feature_name}",
embedding_dim=model_config.embedding_dim,
num_embeddings=model_config.num_embeddings_per_feature[feature_idx],
feature_names=[feature_name],
)
for feature_idx, feature_name in enumerate(
model_config.id_list_features_keys
)
]
# Creates an EmbeddingBagCollection without allocating any memory
ebc = EmbeddingBagCollection(tables=eb_configs, device=torch.device("meta"))
module = DLRM(
embedding_bag_collection=ebc,
dense_in_features=model_config.dense_in_features,
dense_arch_layer_sizes=model_config.dense_arch_layer_sizes,
over_arch_layer_sizes=model_config.over_arch_layer_sizes,
dense_device=device,
)
summary(module)
模型结构:可通过torchinfo.summary展示
======================================================================
Layer (type:depth-idx) Param #
======================================================================
DLRM --
├─SparseArch: 1-1 --
│ └─EmbeddingBagCollection: 2-1 --
│ │ └─ModuleDict: 3-1 11,388,433,600
├─DenseArch: 1-2 --
│ └─MLP: 2-2 --
│ │ └─Sequential: 3-2 154,944
├─InteractionArch: 1-3 --
├─OverArch: 1-4 --
│ └─Sequential: 2-3 --
│ │ └─MLP: 3-3 606,976
│ │ └─Linear: 3-4 257
======================================================================
Total params: 11,389,195,777
Trainable params: 11,389,195,777
Non-trainable params: 0
======================================================================
二、模型部署
#!/bin/bash
torch-model-archiver --model-name dlrm,\
--version 1.0, \
--serialized-file "/root/test/torchrec_dlrm/dlrm.pt",\
--model-file dlrm_factory.py, \
--extra-file dlrm_model_config.py, \
--handler dlrm_handler.py, \
--force
# 打包推荐模型
python create_dlrm_mar.py
mkdir model_store
mv dlrm.mar model_store
# 启动服务
torchserve --start --model-store model_store --models dlrm=dlrm.mar
# curl测试model
curl -H "Content-Type: application/json" --data @sample_data.json http://127.0.0.1:8080/predictions/dlrm
#{
# "score": -0.05748695507645607
#}
Reference
[1] https://github.com/facebookresearch/dlrm
[2] https://ai.facebook.com/blog/dlrm-an-advanced-open-source-deep-learning-recommendation-model/





![[激光原理与应用-69]:激光焊接的10大常见缺陷及解决方法](https://img-blog.csdnimg.cn/img_convert/e6729b60670d0f3ec1c4e4531bb348f3.jpeg)
![[架构之路-203] - 对系统需求类型的进一步澄清](https://img-blog.csdnimg.cn/3b12bffe074b41c480a0733e5f2854d5.png)