目录
【堆】
堆中插入和删除元素
堆排序
【堆的常见应用】
应用1:优先级队列
(1)合并有序小文件
(2)定时器功能
应用2:计算排行榜中前K个数据
应用3:求中位数
应用4:计算接口的 99% 响应时间
【每日一练:对称的二叉树】
【堆】
堆(Heap):是一个完全二叉树,堆中每个节点的值都大于等于(或者小于等于)其左右子节点的值。也就是说,对于一个堆层序遍历,从上层往下层遍历后的数据应该是有序的。
大顶堆:每个节点的值都大于等于子树中每个节点值,数据从上到下越来越小;小顶堆:每个节点的值都小于等于子树中每个节点值,数据从上到下越来越大。
完全二叉树:除了最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列。

完全二叉树适合用数组来存储,因为不需要存储左右子节点的指针,直接通过数组的下标就可以找到一个节点的左右子节点和父节点。 数组中下标为 i 的节点的左子节点就是下标为 i∗2 的节点,右子节点就是下标为 i∗2+1 的节点,父节点就是下标为 i/2 的节点。注意这里为了方便计算,设定数组下标从1开始。

堆中插入和删除元素
(1)在堆中插入元素:插入元素后,还要满足堆的特性,保持数据层次上的顺序(由小到大,或者由大到小)。对于一个大顶堆,如果新插入的元素在堆的最底层,需要对这个元素和上层的元素比较大小,如果比上层的元素大,则需要上浮操作(也叫做:从下往上的堆化方法),也就是一层一层的进行比较交换,如下图所示:
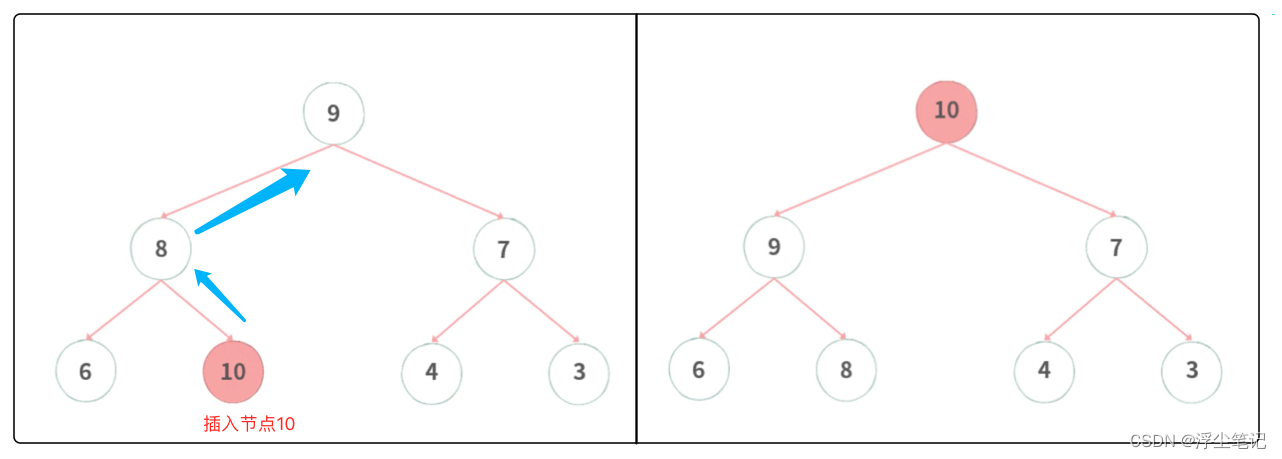
(2)从堆中删除元素:和插入元素同理,需要判断要删除的元素和上下层的大小关系,其实可以把上面插入的操作反过来理解,对应的操作是下沉操作(也叫做:从上往下的堆化方法),如下图所示:

上面的过程使用Go语言代码实现如下(点此查看源代码):
package main
import "fmt"
// 堆结构体
type Heap struct {
data []int //存储堆元素的数组,下标从1开始
cap int //堆中可以存储的最大元素个数(容量)
len int //堆中已经存储的元素个数(长度)
}
// 初始化一个堆
func NewHeap(capacity int) *Heap {
heap := &Heap{}
heap.cap = capacity
heap.data = make([]int, capacity+1)
heap.len = 0
return heap
}
// 大顶堆插入元素,从下往上堆化
func (heap *Heap) insert(data int) {
//判断堆是否已经满了
if heap.len == heap.cap {
return
}
heap.len++
heap.data[heap.len] = data
//和父节点互相比较大小
i := heap.len
parent := i / 2
for parent > 0 && heap.data[parent] < heap.data[i] { //元素上浮,从下往上堆化
swap(heap.data, parent, i) //和父节点的元素交换位置
i = parent
parent = i / 2
}
}
// 大顶堆删除元素,从上往下堆化
func (heap *Heap) removeMax() {
//判断堆是否已经满了
if heap.len == 0 {
return
}
//交换元素
swap(heap.data, 1, heap.len)
heap.data[heap.len] = 0
heap.len--
//元素下沉,从上往下堆化
for i := 1; i <= heap.len/2; {
maxIndex := i
if heap.data[i] < heap.data[i*2] {
maxIndex = i * 2
}
if i*2+1 <= heap.len && heap.data[maxIndex] < heap.data[i*2+1] {
maxIndex = i*2 + 1
}
if maxIndex == i {
break
}
swap(heap.data, i, maxIndex)
i = maxIndex
}
}
// 交换数组中两个元素
func swap(a []int, i int, j int) {
a[i], a[j] = a[j], a[i]
}
func main() {
//初始化堆,并插入6个元素
heap := NewHeap(7)
heap.insert(3)
heap.insert(4)
heap.insert(6)
heap.insert(7)
heap.insert(8)
heap.insert(9)
fmt.Println(heap) //&{[0 9 7 8 3 6 4 0] 7 6}
//给堆中插入一个新元素 10
heap.insert(10)
fmt.Println(heap) //&{[0 10 7 9 3 6 4 8] 7 7}
//移除堆中最大的元素
heap.removeMax()
fmt.Println(heap) //&{[0 9 7 8 3 6 4 0] 7 6}
}在堆中插入和删除元素的过程是顺着一颗完全二叉树的分支路径比较的,如果堆中有n个元素,在堆中插入元素和删除元素的时间复杂度都是O(logn)。
堆排序
之前在 数据结构与算法07:高效的排序算法 里面说过归并排序和快速排序的时间复杂度是O(nlogn),使用堆实现的排序叫做堆排序,可以实现O(nlogn)时间复杂度,O(1)空间复杂度(属于原地排序算法)。
- 堆排序包括建堆和排序两个操作,建堆的过程需要遍历堆中的所有元素,所以建堆的时间复杂度是 O(n);实际排序过程的时间复杂度是 O(nlogn),所以堆排序整体的时间复杂度是 O(nlogn)。
- 堆排序不是稳定的排序算法,因为在排序的过程,有可能将堆的最后一个节点跟堆顶节点互换,所以就有可能改变值相同数据的原始相对顺序。
使用Go语言实现堆排序的代码如下(源代码)
package main
import "fmt"
// 堆排序,数据由小到大排序,数组下标从1开始
func HeapSort(a []int) {
length := len(a) - 1
buidHeap(a, length)
k := length
for k >= 1 {
swap(a, 1, k)
heapifyUpToDown(a, 1, k-1)
k--
}
}
// 构建堆
func buidHeap(a []int, n int) {
// 从后往前处理数组
for i := n / 2; i >= 1; i-- {
heapifyUpToDown(a, i, n)
}
}
// 从上往下堆化,top为当前节点
func heapifyUpToDown(a []int, top int, count int) {
for i := top; i <= count/2; {
maxIndex := i
if a[i] < a[i*2] {
maxIndex = i * 2
}
if i*2+1 <= count && a[maxIndex] < a[i*2+1] {
maxIndex = i*2 + 1
}
if maxIndex == i {
break
}
swap(a, i, maxIndex)
i = maxIndex
}
}
// 交换数组中两个元素
func swap(a []int, i int, j int) {
a[i], a[j] = a[j], a[i]
}
func main() {
//下标从1开始的数组,方便构建堆
arr := []int{0, 8, 12, 3, 7, 19, 20, 6, 5}
HeapSort(arr)
fmt.Println(arr) //[0 3 5 6 7 8 12 19 20]
}【问】快速排序和堆排序的时间复杂度都是 O(nlogn),而且堆排序比快速排序的时间复杂度还要稳定,但是快速排序的性能要比堆排序好,为什么?
- 快速排序的数据是顺序访问的,而堆排序的数据是跳着访问的,这样对 CPU 缓存是不友好的;
- 对于同样的数据,在排序过程中,堆排序算法的数据交换次数要比快速排序多,对于一组已经有序的数据来说,经过建堆之后,数据反而变得更无序了;
【堆的常见应用】
应用1:优先级队列
在 数据结构与算法04:队列 中说过,队列是一种先进先出的数据结构,但是某些场景下需要实现“插队”的功能,比如购买了VIP的用户优先处理,这个时候就要用到优先级队列了,相当于在传统的队列中增加了一个“优先级”的概念,优先级高的数据即使是后面进来的,也可以优先出队。赫夫曼编码、图的最短路径、最小生成树算法等 都使用到了优先级队列。
如果使用传统的线性数据结构(比如数组或链表)来实现优先级队列,需要遍历队列中的所有元素才能找到优先级高的数据,所以时间复杂度为 O(n)。用堆来实现优先级队列是最高效的,一个大顶堆可以看作是一个优先级队列,取出优先级最高的元素就相当于取出堆顶元素。需要注意,取出堆顶元素就是上面分析的“删除堆顶元素”,删除后会在堆顶部产生空位,需要从上往下堆化来生成新的堆顶元素。
举个例子,原本当前的队列顺序是A->B->C,突然来了个VIP用户S,插队排到了A的前面,此时的队列就是S->A->B->C,当这个VIP用户S出队之后,那么下一个就是原来的对头元素A出队。
(1)合并有序小文件
负载均衡的多台服务器上分布着时间由小到大顺序排列的日志文件,现在大数据团队需要对这些分散在多台机器上的日志文件合并成一个有序的日志文件,就可以使用优先级队列。假设现在有10台机器,每台机器上的某一个日志文件是100MB,日志文件都是有序的。
从这10个文件中各取第一条日志的时间字符串放入数组中,然后比较大小,把最小时间的日志数据放入到小顶堆中,堆顶的元素就是优先级队列队首的元素,然后将这条日志放入到另外一个大文件中,并将其从堆中删除;然后再继续从原来的日志文件中取出下一条日志放入到堆中,重复这个过程,就可以将10个小日志文件的数据依次放入到大文件中。这个操作中,删除堆顶数据和往堆中插入数据的时间复杂度都是 O(logn),n表示堆中的数据个数(这里就是10)。如果使用线性的数组实现的话需要O(n)的时间复杂度。
(2)定时器功能
假设需要在指定时间点执行一些脚本, 传统的做法是写一个定时任务(crontab),每隔固定的时间间隔(比如1分钟)校验是否到达了其中几个脚本的执行时间,比如下面这样:
| 时间 | 任务 |
| 00:01 | 统计昨日用户增量 |
| 00:50 | 备份数据库 |
| 10:11 | 给用户推送系统消息 |
| 12:00 | ... ... |
如果使用Linux定时器crontab每隔1分钟执行一个脚本,在这个脚本里面需要判断当前时间是否到达了设定的时间,这样做会存在两个问题: (1) 开始执行某个任务的时候,任务的约定执行时间离当前时间可能还有很久,前面很多次扫描其实都是无用功;(2) 每次都要扫描整个任务列表,如果任务列表很大的话会比较耗时。
针对这个情况,可以使用优先级队列来实现,将任务按照设定的执行时间存储在优先级队列中,队列头部(也就是小顶堆的堆顶)存储的是最先执行的任务,定时器拿队头任务的执行时间点与当前时间点相减得到一个时间间隔 T,表示从当前时间开始需要等待多久才会有第一个任务需要被执行。这样定时器就可以设定在T秒之后再来执行任务,从当前时间点到 (T-1) 秒这段时间里定时器都不需要做任何事情。当 T 秒时间过去之后,定时器取优先级队列中队头的任务执行,然后再计算新的队头任务的执行时间点与当前时间点的差值T2,这个值就是定时器执行下一个任务需要等待的时间。
应用2:计算排行榜中前K个数据
很多网站或者APP都会有排行榜,比如歌曲排行榜TOP200,热搜排行榜TOP10等等,比如下面是百度热搜电影榜TOP10:

搜索引擎每天会接收大量的用户搜索请求,会把用户输入的搜索关键词记录下来,然后再离线地统计分析,然后得到最热门的 Top10 搜索关键词。假设现在有一个包含 10 亿个搜索关键词的日志文件,如何能快速获取到热门榜 Top 10 的搜索关键词?这个问题可以抽象为获取 Top(K)大的元素,分析如下:
(1)针对静态数据集合离线统计关键词,数据集合确定好之后不会再变。
实现思路是:首先可以通过散列表 或者 平衡二叉搜索树 来记录关键词出现的次数。假设选用散列表,顺序扫描这 10 亿个搜索关键词,当扫描到某个关键词时去散列表中查询,如果存在就将对应的次数加一,如果不存在就将它插入到散列表并记录次数为 1。以此类推,等遍历完这 10 亿个搜索关键词之后,散列表中就存储了不重复的搜索关键词以及出现的次数。
然后维护一个大小为K的小顶堆,顺序遍历散列表,从中取出一个数据与堆顶元素比较,如果这个元素比堆顶元素大,就把当前堆顶元素出队删除,并且将这个新取出的元素插入到堆中;如果取出的元素比堆顶元素小,则跳过不做处理,继续遍历散列表。等散列表中的数据都遍历完之后,堆中的数据就是前 K 大数据了。遍历数组需要 O(n) 的时间复杂度,一次堆化操作需要 O(logK) 的时间复杂度,所以最坏情况下n 个元素都入堆一次,所以时间复杂度就是O(nlogK)。
- 假设 10 亿条搜索关键词中不重复的有 1 亿条,如果每个搜索关键词的平均长度是 50 个字节,那存储 1亿个关键词大概需要 5GB 的内存空间。而散列表因为要避免频繁冲突,不会选择太大的装载因子,所以消耗的内存空间就更多了。假设一台机器只有 1GB 的可用内存空间,无法一次性将所有的搜索关键词加入到内存中,怎么优化?
- 可以将10亿条搜索关键词先通过哈希算法分片到 10 个文件中,创建 10 个空文件 00,01,02,……,09,遍历这 10 亿个关键词,并且通过某个哈希算法对其求哈希值,然后哈希值%10取模,得到的结果就是这个搜索关键词应该被分到的文件编号。
- 对这 10 亿个关键词分片之后,每个文件都只有1亿的关键词,去除掉重复的可能就只有 1000 万个。每个关键词平均 50 个字节,所以总的大小就是 500MB,1GB 的内存就可以放得下。针对每个包含 1亿条搜索关键词的文件,利用散列表和堆分别计算出Top 10,然后把这10个 Top 10 放在一块总共100个关键词,然后在这 100 个关键词中找到出现次数最多的 10 个关键词就可以了。
(2)针对动态数据集合,会有数据动态加入,排行榜需要实时的更新。
实现思路是:维护一个大小为K的小顶堆,默认堆为空。当有某个关键词被搜索的时候,把这个元素和当前堆顶元素(这里的元素是关键词的搜索次数)进行比较,如果这个新的元素比堆顶元素大,就把当前堆顶元素出队删除,并且将这个新的元素插入到堆中的最底层;如果这个新元素比堆顶元素小则跳过不做处理。这样一来堆中的数据就是前K大数据了,获取的时候把这个小顶堆反过来就是排行榜实时从大到小的Top(k)。
应用3:求中位数
中位数就是有序集合里面中间的那个数据,一般是第 n/2 位置的元素。对于一组静态数据的中位数是固定的,可以排序后返回 n/2 位置的元素;但是如果是动态变化的数据集合,中位数也在不断变动,需要每次排序,效率就会下降。
如果使用堆,可以不用排序就能高效地计算中位数。实现思路:
- 需要维护两个堆:一个大顶堆和一个小顶堆,大顶堆中存储前半部分数据,小顶堆中存储后半部分数据,并且小顶堆中的数据都大于大顶堆中的数据,这样大顶堆中的堆顶元素就是中位数。
- 对n个数据从小到大排序,如果n是偶数,那么大顶堆中存储前面 n/2 个数据,小顶堆中存储后面 n/2 个数据;如果n是奇数,那么大顶堆中存储前面 (n/2)+1 个数据,小顶堆中存储后面 n/2 个数据。
- 如果新加入的数据<=大顶堆的堆顶元素,就将这个新数据插入到大顶堆;如果新加入的数据>=小顶堆的堆顶元素,就将这个新数据插入到小顶堆。如果因为奇数或者偶数变化的情况导致两个堆的数据出现问题,则动态调整两个堆的元素。
- 插入数据中堆化过程的时间复杂度是 O(logn);获取中位数只需要返回大顶堆的堆顶元素就可以了,时间复杂度就是 O(1)。
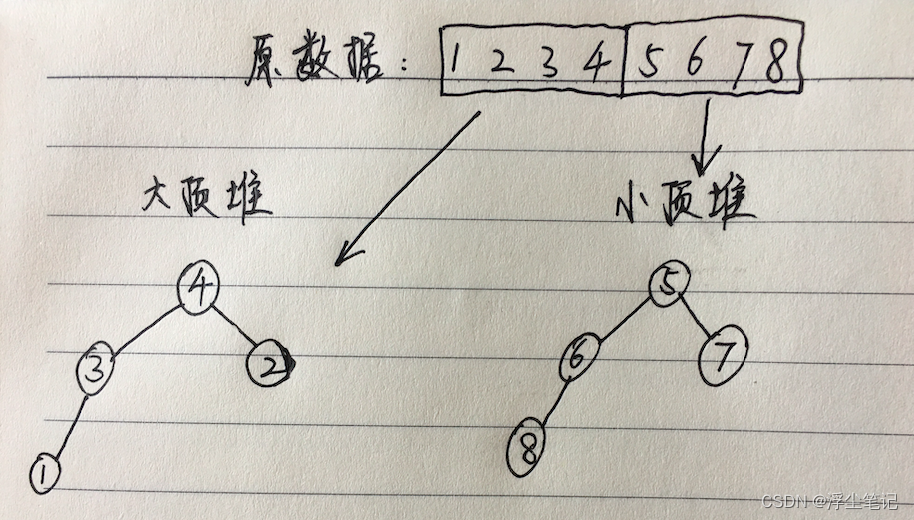
应用4:计算接口的 99% 响应时间
利用上面的中位数的逻辑,可以把接口的50%响应时间当做中位数,那么要计算99%响应时间也是这个思路。如果某个接口被请求了100次,把这100次接口的响应时间按照从小到大排列,排在第99的那个数据就是 99% 响应时间,也叫 99 百分位响应时间。 可以维护一个大顶堆和一个小顶堆,假设当前的请求总数是n,大顶堆中保存 n*99% 个数据,小顶堆中保存 n*1% 个数据,那么大顶堆的堆顶元素就是 99% 响应时间。
每次插入一个数据的时候要判断这个数据跟大顶堆和小顶堆堆顶数据的大小关系,然后决定插入到哪个堆中。如果新插入的数据比大顶堆的堆顶数据小,那就插入大顶堆;如果这个新插入的数据比小顶堆的堆顶数据大,那就插入小顶堆。但是为了保持大顶堆中的数据占 99%,小顶堆中的数据占 1%,在每次新插入数据之后都要重新计算此时的大顶堆和小顶堆中的数据个数是否还符合 99:1 这个比例。如果不符合就将一个堆中的数据移动到另一个堆,直到满足这个比例。这个操作和上面说的中位数的逻辑类似。
通过这样的方法,每次插入数据可能会涉及几个数据的堆化操作,所以时间复杂度是 O(logn);每次求 99% 响应时间的时候直接返回大顶堆中的堆顶数据即可,时间复杂度是 O(1)。
【每日一练:对称的二叉树】
力扣剑指 Offer 28. 对称的二叉树
请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1
/ \
2 2
/ \ / \
3 4 4 3
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:1
/ \
2 2
\ \
3 3示例 1:输入:root = [1,2,2,3,4,4,3],输出:true
示例 2:输入:root = [1,2,2,null,3,null,3],输出:false(源代码)
package main
import "fmt"
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
// 二叉树的根节点
func TreeRoot(root *TreeNode) bool {
if root == nil {
return true
}
return isSymmetric(root.Left, root.Right)
}
// 对左子树和右子树分别递归判断是否对称
func isSymmetric(left *TreeNode, right *TreeNode) bool {
if left == nil && right == nil {
return true
}
if left == nil || right == nil {
return false
}
if left.Val != right.Val {
return false
}
if !isSymmetric(left.Left, right.Right) || !isSymmetric(left.Right, right.Left) {
return false
}
return true
}
func main() {
tree1 := &TreeNode{Val: 1,
Left: &TreeNode{Val: 2,
Left: &TreeNode{Val: 3},
Right: &TreeNode{Val: 4},
},
Right: &TreeNode{Val: 2,
Left: &TreeNode{Val: 4},
Right: &TreeNode{Val: 3},
},
}
fmt.Println(TreeRoot(tree1)) //true
tree2 := &TreeNode{Val: 1,
Left: &TreeNode{Val: 2,
Right: &TreeNode{Val: 3},
},
Right: &TreeNode{Val: 2,
Right: &TreeNode{Val: 3},
},
}
fmt.Println(TreeRoot(tree2)) //false
}