一、概述
title:QLORA: Efficient Finetuning of Quantized LLMs
论文地址:https://arxiv.org/pdf/2305.14314.pdf
代码:GitHub - artidoro/qlora: QLoRA: Efficient Finetuning of Quantized LLMs and https://github.com/TimDettmers/bitsandbytes
1.1 Motivation
- 直接训练650亿参数的LLaMA进行16位微调需要780GB内存,成本太高。
- 最近量化技术能降低LLM内存使用量,但是一般适应语推理阶段,其用在训练阶段效果就拉跨。
1.2 Methods
- 本文证明可以在4-bit量化微调带来的损失,可以完全通过adpter来优化,达到原始16-bit微调的精度(chatgpt的99.3%),并极大程度的降低内存使用量同时降低训练时间。
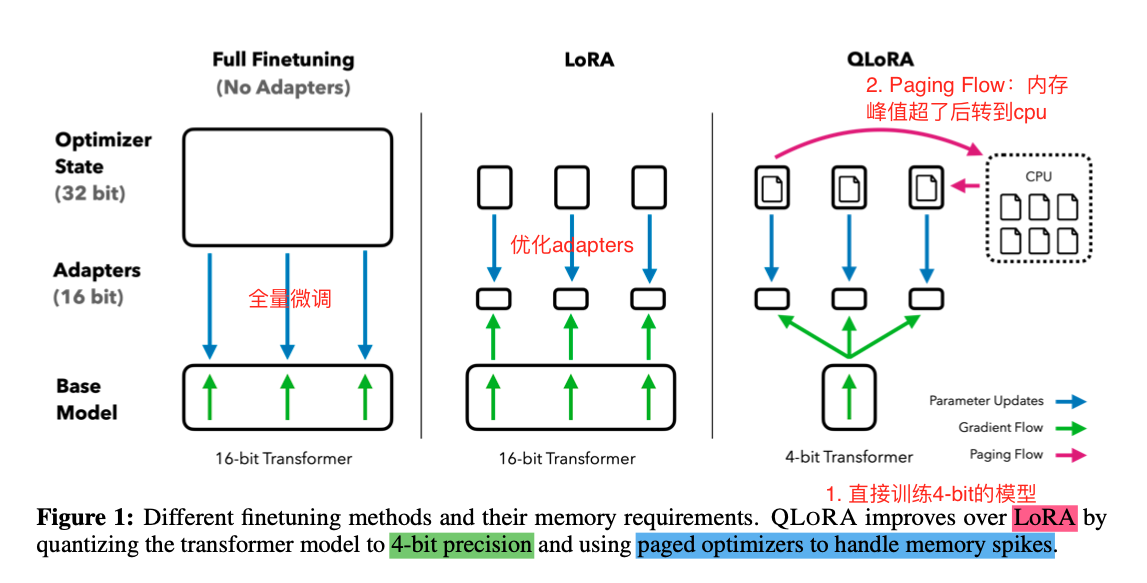
- QLoRA方法要点如下:
-
- 直接使用4-bit精度的量化
- 利用Paging Flow优化内存spikes问题
- with LoRA
- 实验:利用QLoRA微调了1000多个模型,在8个instruction的数据集上,提供了instruction following和chatbot的详细分析结果。
- 本文用到的一些节约内存同时不牺牲精度的方法解读:
-
- 4-bit NormalFloat(NF4):一种新的数据类型,在信息理论上优于正常分布的权重,基于Quantile Quantization技术开发,通过估计输入张量的分位数来保证每个量化区间分配相等的值。
-
-
- Quantile是一种统计学术语,指的是将数据集分成几个等份的过程,每个等份包含相同数量的数据点。例如,将一个包含100个数据点的数据集分成四个等份,每个等份包含25个数据点。
- Quantization是一种数字信号处理技术,用于将连续信号(如音频或图像)转换为离散信号。这种技术可以用于压缩数据或减少存储空间,同时尽可能地保留原始信号的信息。
- Quantile quantization可能指的是将数据集分成几个等份,并将每个等份量化为离散值。这种技术可能用于数据压缩或降低数据存储需求。
-
-
- Double Quantization:双重量化通过量化量化常数来减少平均内存占用【量化的量化?】
-
-
- “双量化”指的是数字信号处理中的一个概念,其中信号被量化两次。量化是用有限数量的离散值逼近连续信号的过程。在双量化中,信号首先被量化到较粗的分辨率,然后再被量化到较细的分辨率。这种技术可用于图像和音频压缩等各种应用,有助于减少表示信号所需的数据量,同时保持信号的整体质量。双重量化也称为逐次逼近量化。
-
-
- Paged Optimizers:这种技术利用了NVIDIA统一内存的特性,实现了CPU和GPU之间自动的页面转换。当GPU内存不足时,Paged Optimizers技术会自动将优化器状态转移到CPU内存,以确保优化器的正常运行。
-
-
- Paged Optimizers:分页优化器,是一种能够在CPU和GPU之间自动转换优化器状态的技术。
- NVIDIA统一内存:一种将CPU和GPU内存统一管理的技术,可以让CPU和GPU共享同一块内存,从而减少数据传输的时间和开销。
-
1.3 Conclusion
- 本文验证了将量化技术用在训练阶段,利用本文4-bit微调技术QLoRA,能够利用48GB内存的GPU去微调65B参数的模型(正常需要780GB内存),达到ChatGPT99.3%的效果。
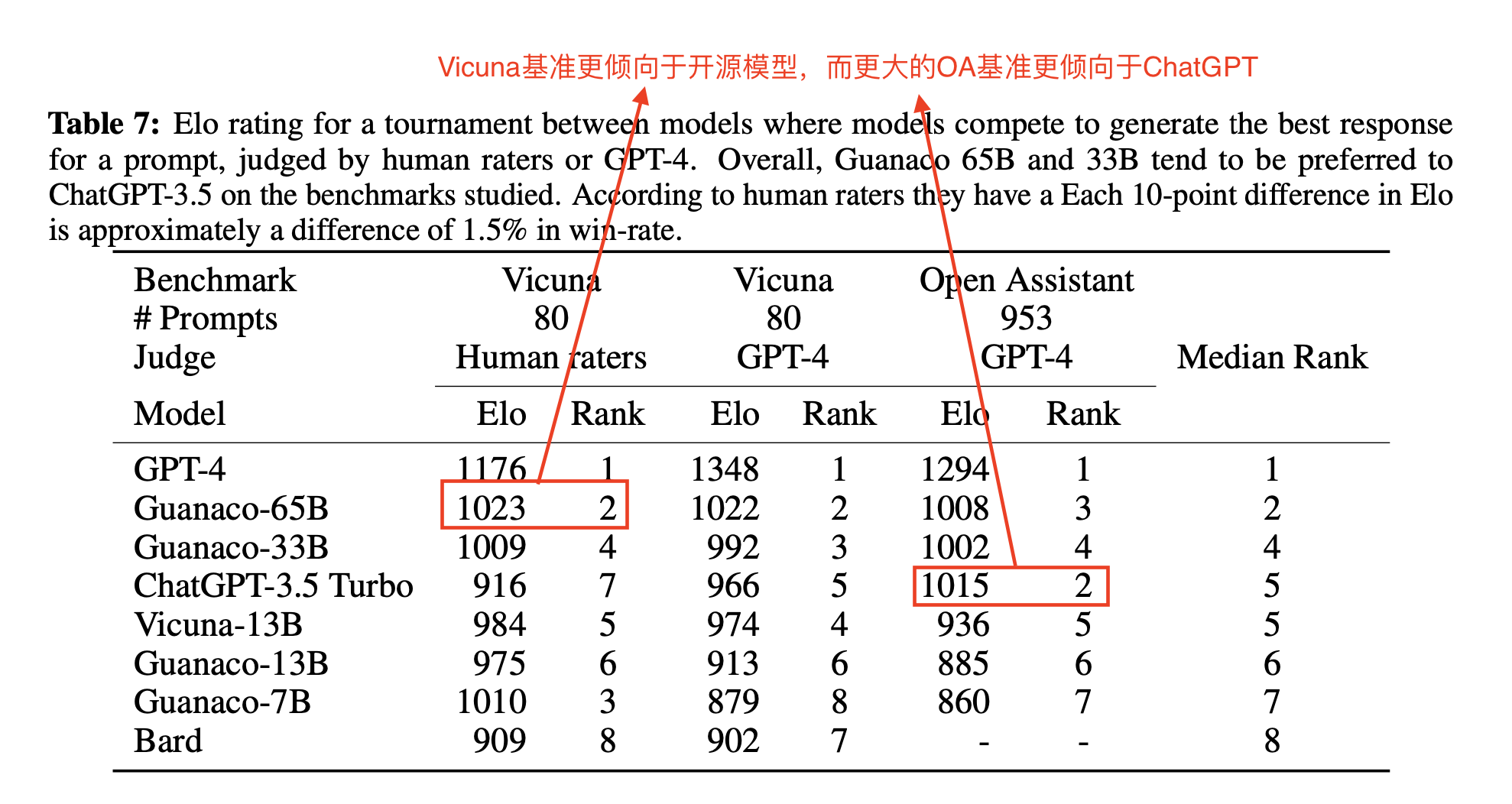
- Guanaco在Vicuna benchmark上表现不错,达到了ChatGPT99.3%的效果。
- 表明QLoRA可以利用一个小的高精度的数据集,到达一个sota的结果(甚至用更小的模型)。
- GPT-4可以作为一个评估,相对于人类来说更便宜更可靠。
- 当前的chatbot benchmarks可能不太可信。
- lemon-picked分析证明了Guanaco比ChatGPT差的地方。
二、详细内容
1 4-bit QLoRA与16-bit LoRA在Alpaca数据集上RougeL分数对比
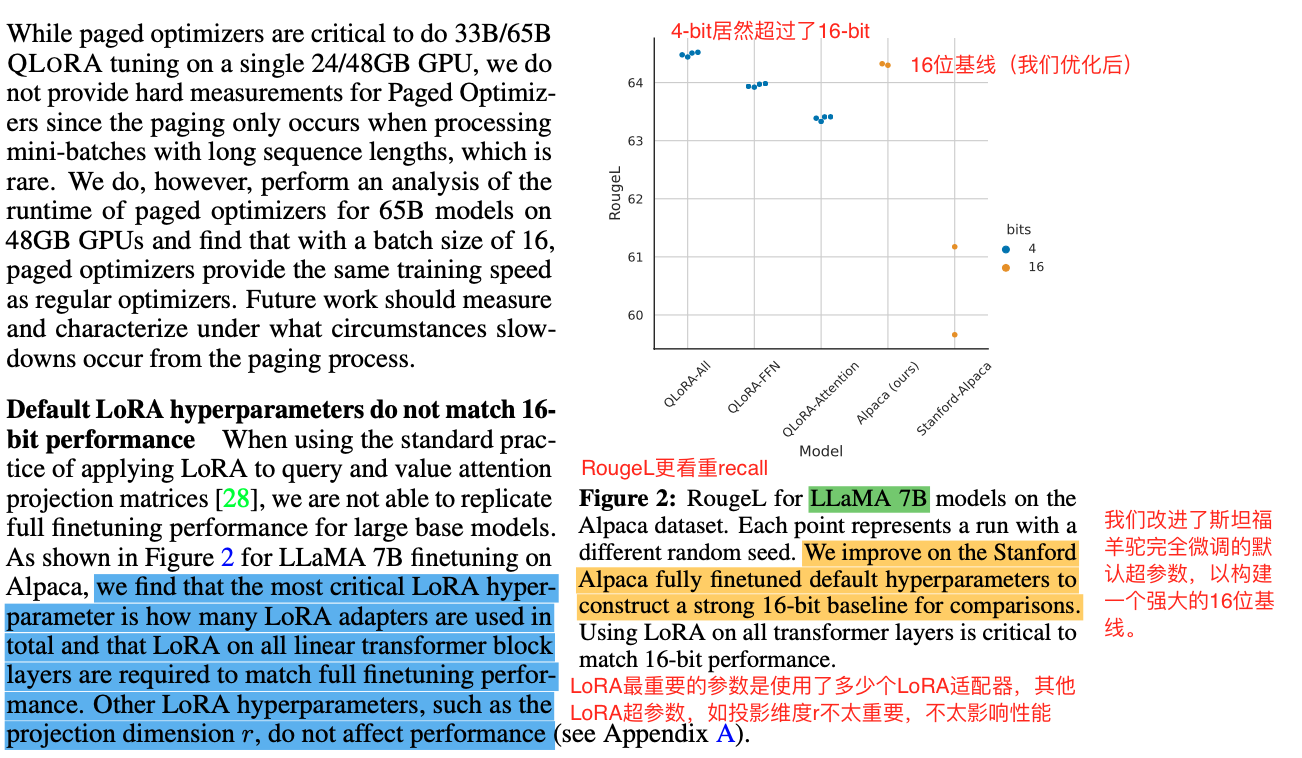
- 结论:QLoRA 4-bit训练的模型,可以追平升值超过LoRA 16-bit的模型,说明4-bit + adpater训练量化模型达到比较好的效果是可行的。
- 数据集:Alpaca dataset
- 基础模型:LLaMA 7B
- 评价指标:RougeL
- 说明:原始stanford的分数在60,61左右,本文优化参数后,可以到64+
- LoRA-ALL:在所有线性的transformer block层上用LoRA adapter结构效果最好,超过了Alpaca的LoRA强基线
2 不同的4-bit数据类型对效果的影响

- 结论:NFloat效果比原始的Float效果好很多,DQ(Double Quantization)可以进一步优化对内存的控制。
- zero-shot实验:尝试了不同大小模型(125M-65B)【OPT,BLOOM,Pythia,LLaMA】,各种数据类型下的zero-shot效果
-
- 模型效果:NFloat + DQ > NFloat > Float
- Float:基础的4-bit float类型
- NFloat:NormalFloat,精度带来比较大的提升
- NFloat + DQ:NormalFloat + Double Quantization,内存控制效果更好,精度提升不大
- NF4:4-bit NormalFloat
2 与LoRA 16位微调对比 vs 量化微调(4、8、16)+adapter【GLUE以及Super-NaturalInstructions数据集】

- 无论是使用16位、8位还是4位的适配器方法,都能够复制全16位微调的基准的性能。这说明,尽管量化过程中会存在性能损失,但通过适配器微调(是指LoRA吗?),完全可以恢复这些性能。
- 数据集:GLUE,Super-NaturalInstructions
3 不同大小模型下4-bit QLoRA和16位精度对比【few-shot实验】

- FP4比16位微调低1个百分点
- NFloat4 + DQ可以和BFloat 16持平
- 数据集:5-shot MMLU
- 背景知识:MMLU数据集是一个多模态的语言理解数据集,由清华大学自然语言处理与社会人文计算实验室发布。该数据集包含了中英文文本和语音,覆盖了多种任务,如情感分析、自然语言推理、问答等。MMLU数据集的目的是为了促进多模态语言理解领域的研究和发展。如果您需要更详细的信息,可以访问清华大学自然语言处理与社会人文计算实验室的官网。
4 基于QLoRA的大模型微调实验【Vicuna基准达到ChatGPT的99.3%】【Vicuna基准比26GB的Alpaca高20个点】
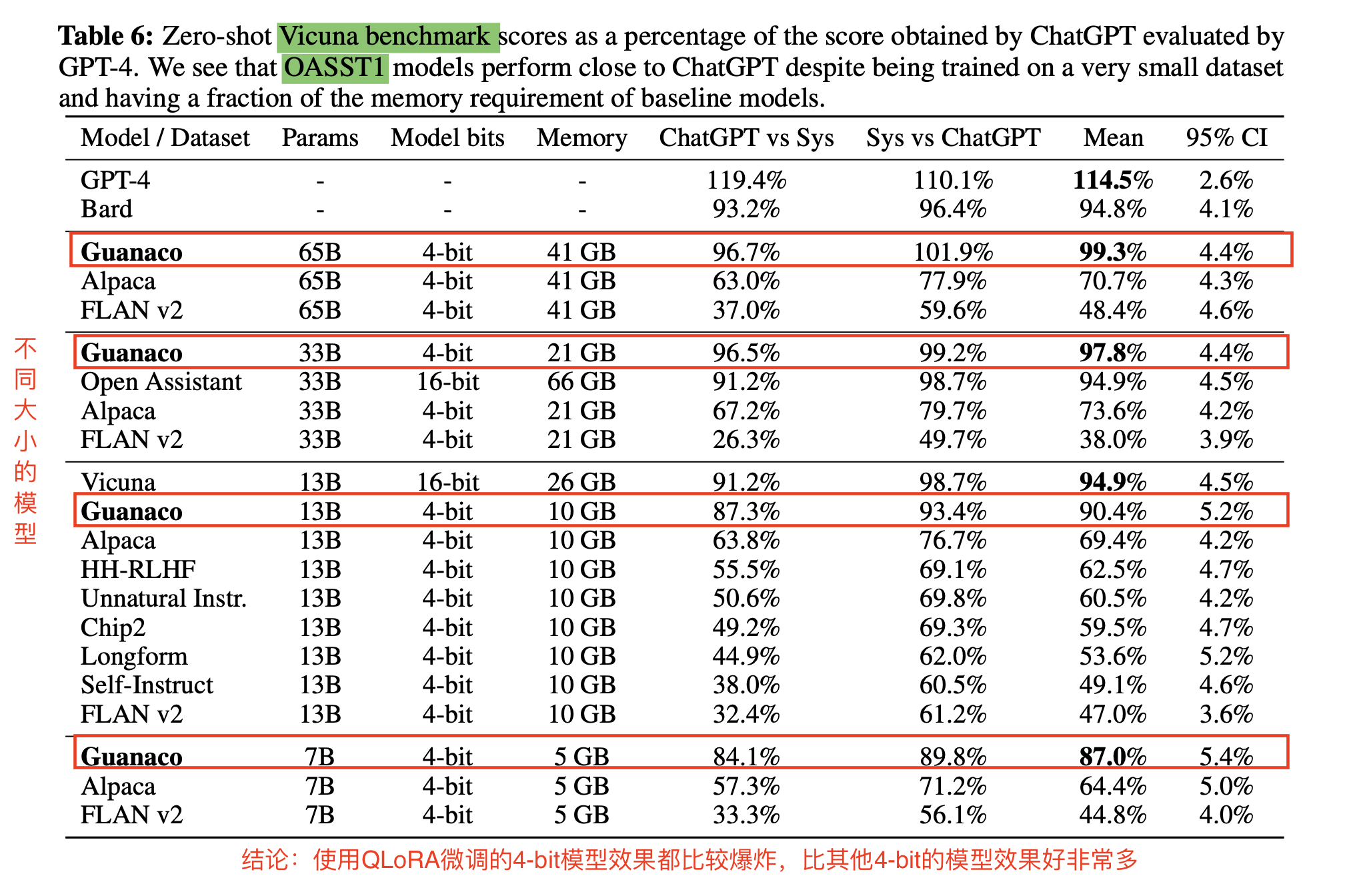
- 实验总结:使用QLoRA微调的4-bit模型效果都比较爆炸,比其他4-bit的模型效果好非常多
- 实验方法:基于不同大小的模型,对OASST1【OpenAssistant Conversations数据集】利用QLoRA方法微调得到Guanaco
- 实验结果:使用GPT-4来当裁判,通过4-bit微调后,65B的模型在Vicuna benchmark的zero-shot表现排在第二,7B参数的模型(仅需要5GB内存),比Alpaca高20个点,效果非常好
- 数据集:Vicuna benchmark
- 背景知识:
-
- "OpenAssistant Conversations (OASST1)"是一个人工生成的、人工注释的助手式对话语料库,包含161,443条来自35种不同语言的消息,注释了461,292个质量评分,形成了超过10,000个完全注释的对话树。
- "Vicuna"是一个开源聊天机器人,它通过在ShareGPT上共享的用户对话fine-tuning LLaMA进行训练。Vicuna-13B表现出了令人印象深刻的性能,在使用GPT-4作为基准进行初步评估时,在90%以上的情况下优于其他模型,如LLaMA和Stanford Alpaca 。
5 定性分析

- 总结:
-
- Vicuna基准【Vicuna benchmark】更倾向于开源模型,而更大的OA【open assistant】基准更倾向于ChatGPT
- 强大的MMLU性能并不意味着强大的聊天机器人性能,反之亦然
- 4位QLORA是有效的,可以产生与ChatGPT竞争的最先进的聊天机器人
三、参考文献
- QLoRA:一种高效LLMs微调方法,48G内存可调LLaMA-65B (开源):QLoRA:一种高效LLMs微调方法,48G内存可调LLaMA-65B (开源)