大数据:数据表操作,分区表
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
与此同时,既然要考网警之数据分析应用岗,那必然要考数据挖掘基础知识,今天开始咱们就对数据挖掘方面的东西好生讲讲 最最最重要的就是大数据,什么行测和面试都是小问题,最难最最重要的就是大数据技术相关的知识笔试
文章目录
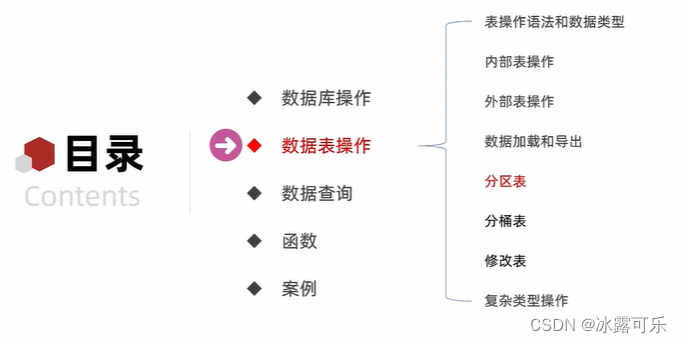
- 大数据:数据表操作,分区表
- @[TOC](文章目录)
- 大数据:分区表
- 分桶表
- 修改表
- 复杂操作array类型
- map数据类型
- struct数据类型
- hive反正就是基于MapReduce的sql框架,它能写sql又能做分布式计算,这些知识好好复习,对于未来考网络警察很有帮助的。
- 总结
文章目录
- 大数据:数据表操作,分区表
- @[TOC](文章目录)
- 大数据:分区表
- 分桶表
- 修改表
- 复杂操作array类型
- map数据类型
- struct数据类型
- hive反正就是基于MapReduce的sql框架,它能写sql又能做分布式计算,这些知识好好复习,对于未来考网络警察很有帮助的。
- 总结
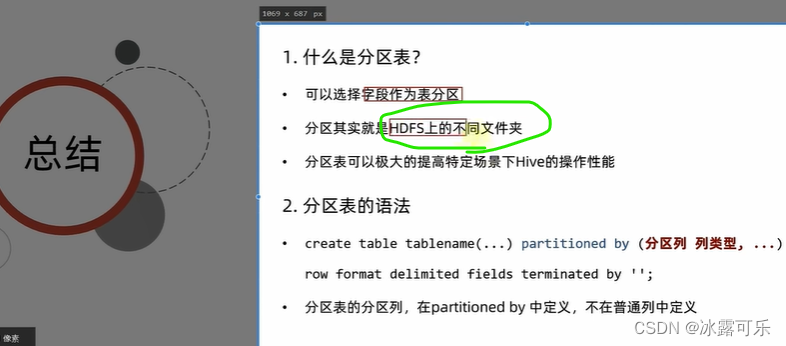
大数据:分区表


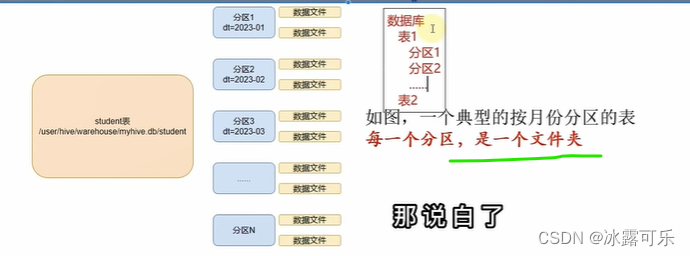
物理上就是文件夹分开
美滋滋

语法是
partitioned by(字段,列类型)


注入数据是放5月的那个分区
这样的话,相当于指定了一个字段属性
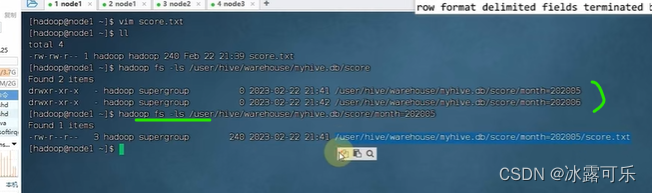
分区就会继续构建子文件夹
美滋滋

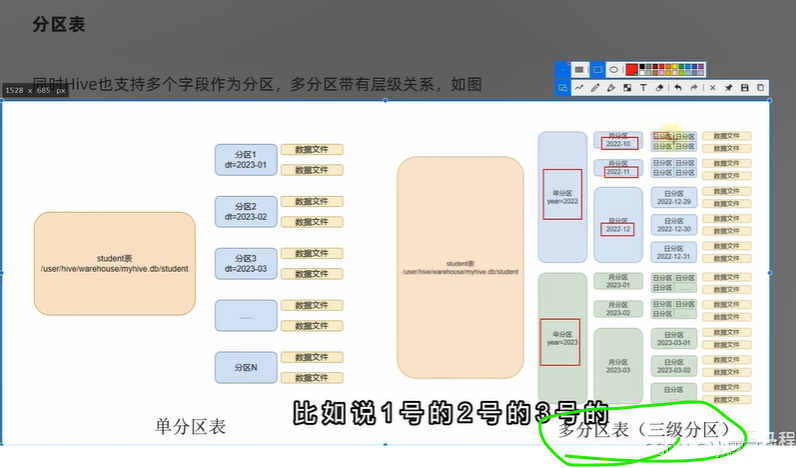
多级分区

相当于仨文件目录
注入数据
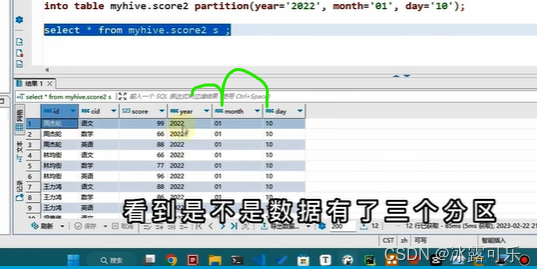
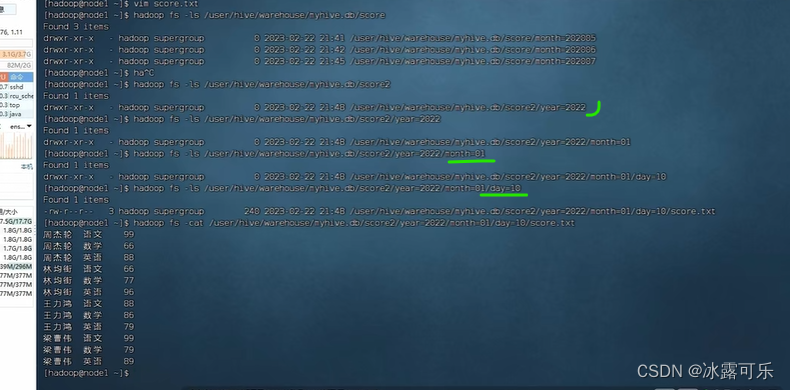
缩小查询范围
过滤条件,跟sql很类似
分桶表

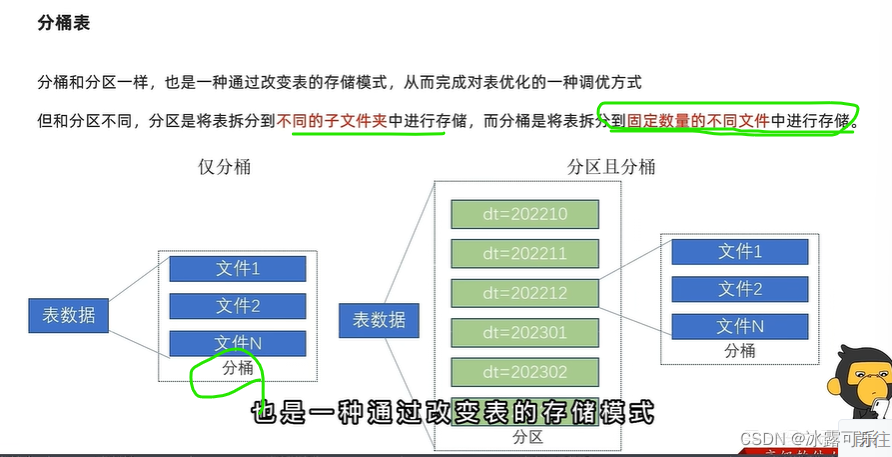
分桶是为了负载均衡
文件的数量固定
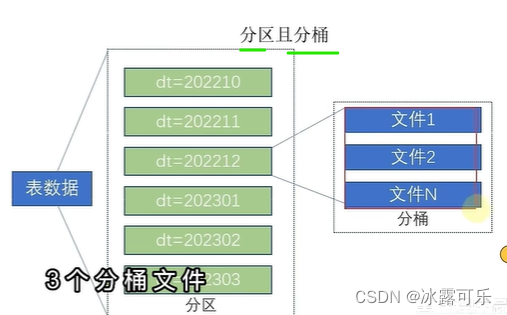
目的是负载均衡
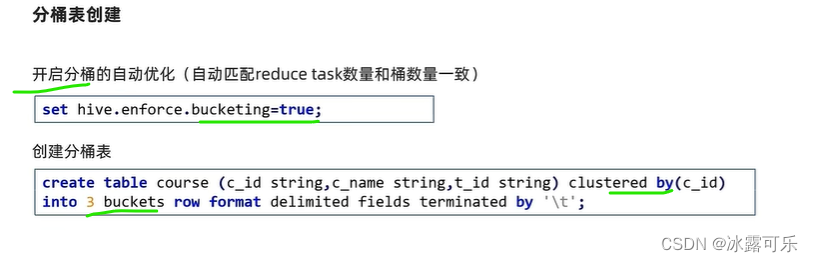
reduce的数量和分桶一样
估计就是为了方便计算通道匹配
clustered by(字段) into k buckets
关键字
分桶,利用哪个字段来分桶
哈希值随机分桶,牛逼的
算法里面学过的

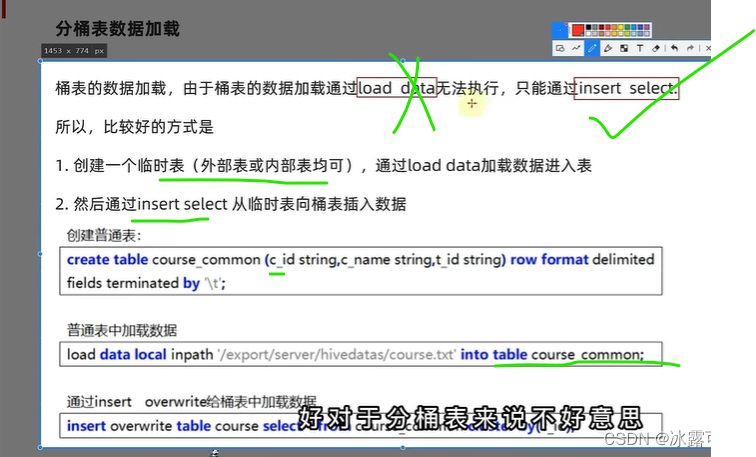
load中转
做一个表,不能从数据直接干到分桶表中
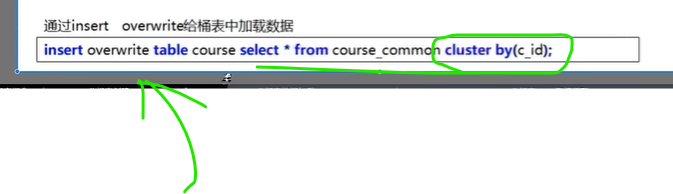
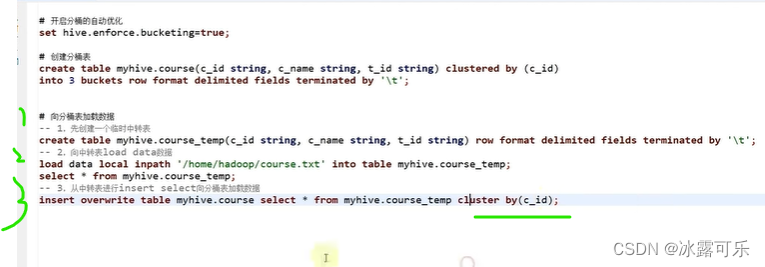
分桶
建表是clustered by
导入数据是cluster
没有ed
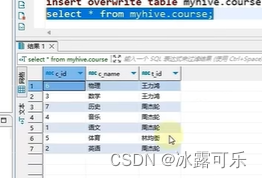
看看hdfs
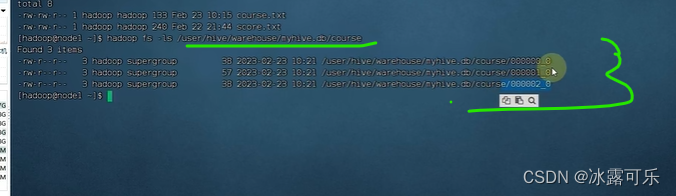
指定了分桶的数量是3
按照cid这个字段来分桶
分桶原理就是哈希表映射
cid哈希值%3
就行了
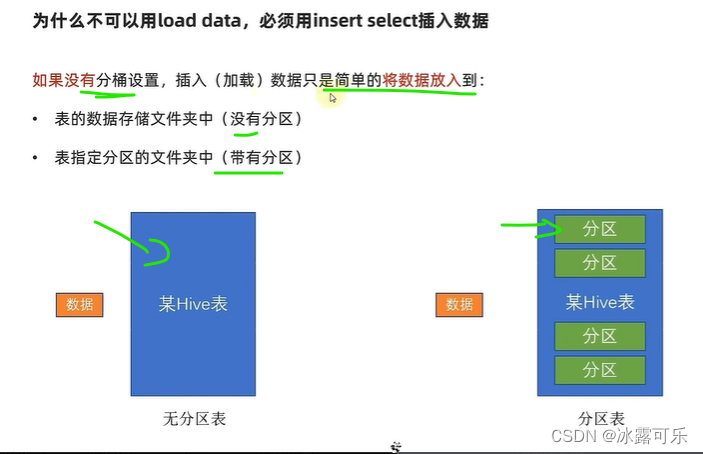
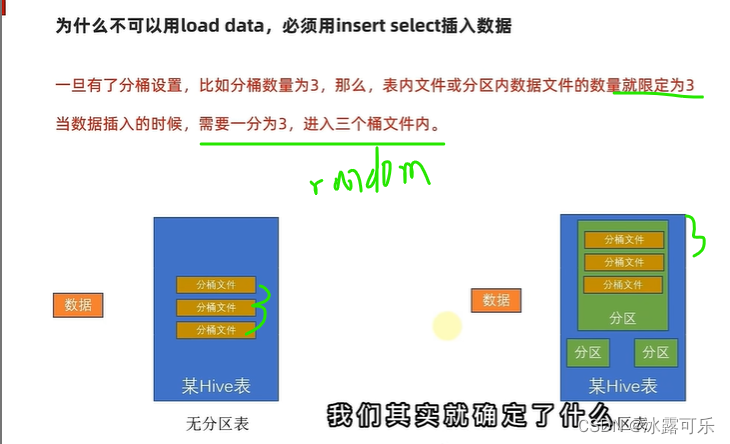
数据需要一分为三
你不能直接干进去
还需要计算去向

只要计算,就必须要过MapReduce
于是load data干不了,它不会触发的
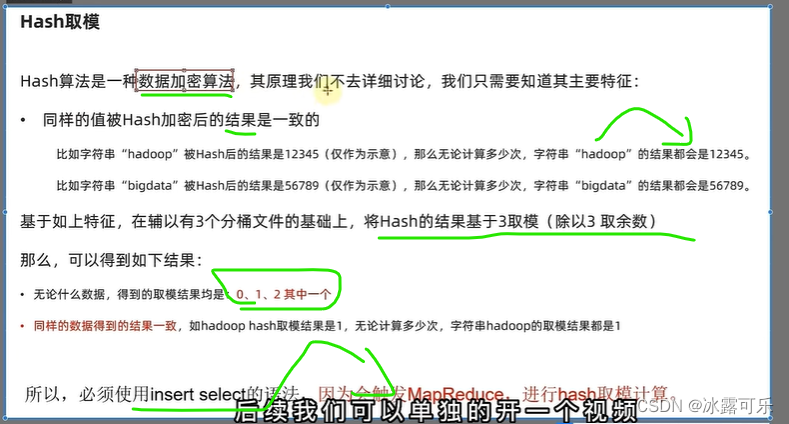

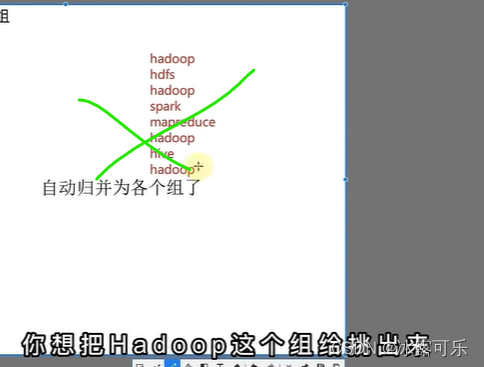
所以每个桶,不见得里面的东西是一样的

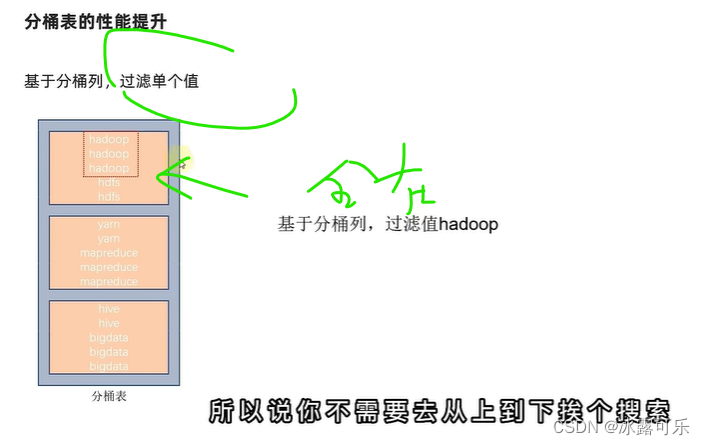
分桶的目的就是确定某些数据,一定在同一个桶中
不必去找别的桶
懂吗
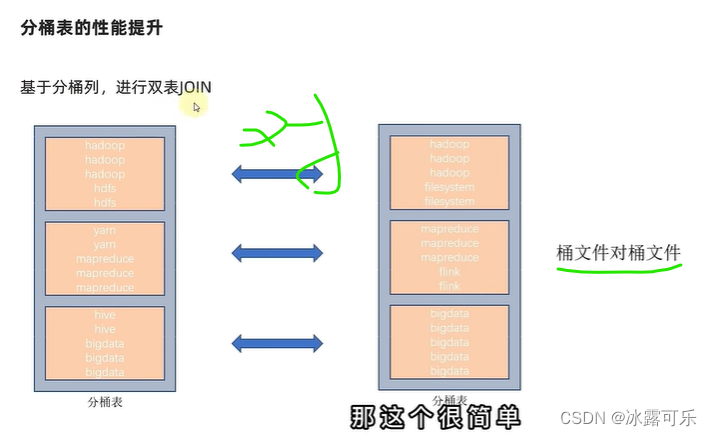
对应join,合并即可
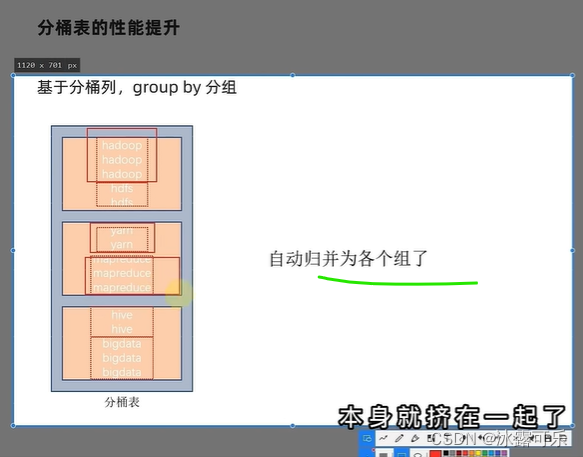
自然成组
修改表


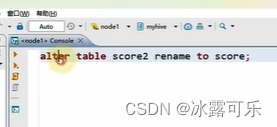
修改表名
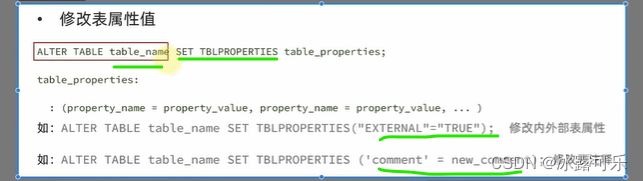
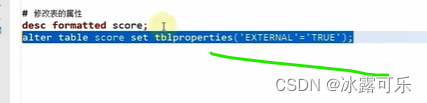
修改表的属性,内部表,外部表


添加文件夹
修改文件夹名字
删除文件夹
分区就是文件夹分级

没必要搞分区
不要操作分区的骚操作

加列

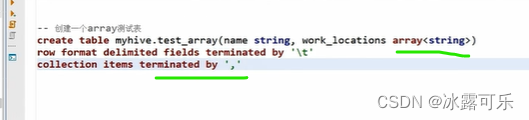
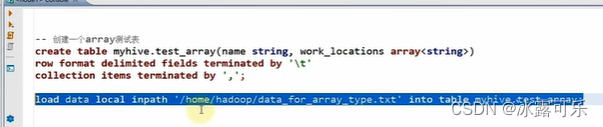
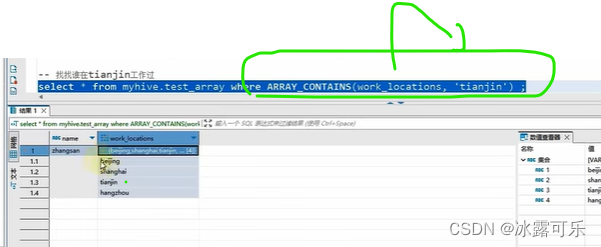
复杂操作array类型



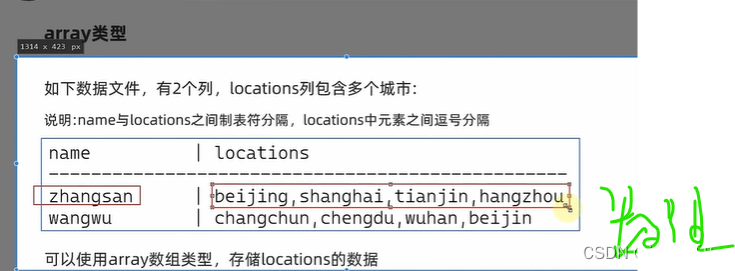
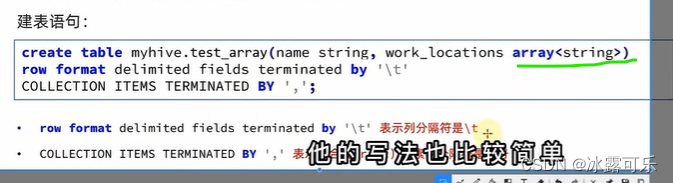

数组内部是逗号分割

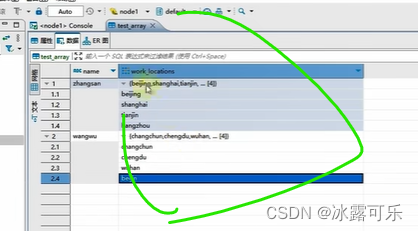
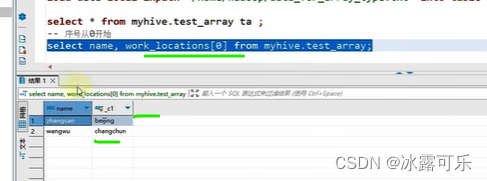
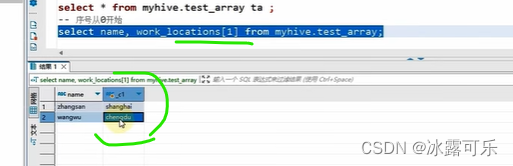
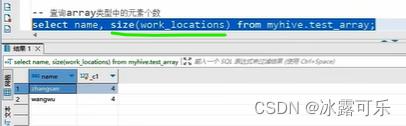
统计数组个数
不管python,java,c++,还是sql,hive,都类似的,核心思想不变的
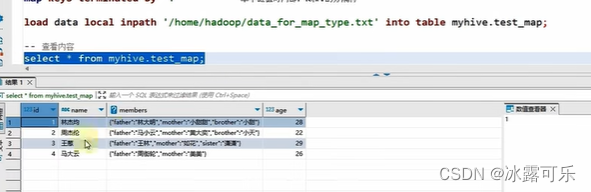
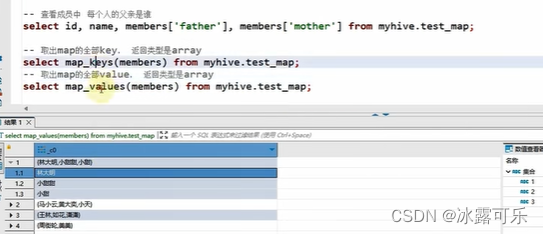
map数据类型
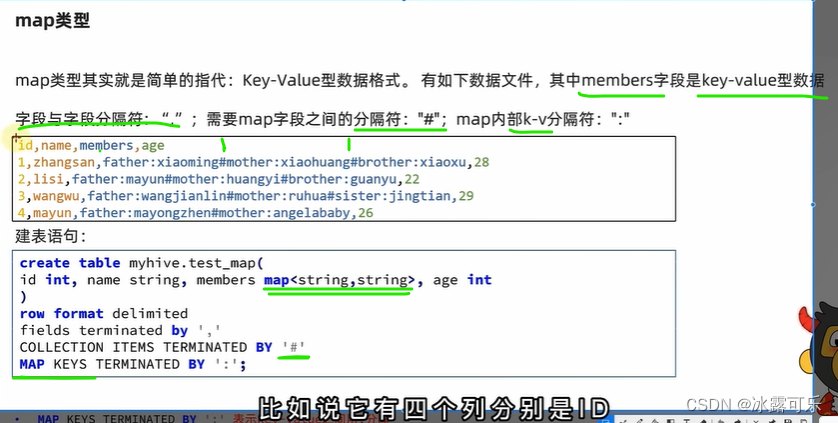
集合项目之间以#分隔
map键值对通过:分隔
好说
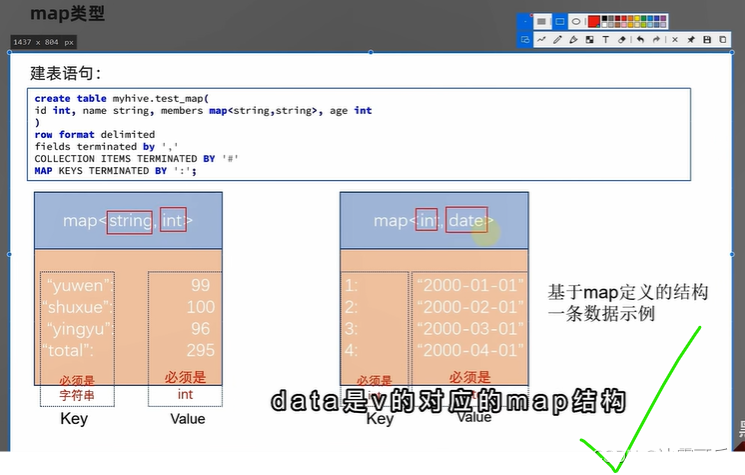
map类型,这个比sql牛逼啊


python中的字典
就是kv键值对
好说
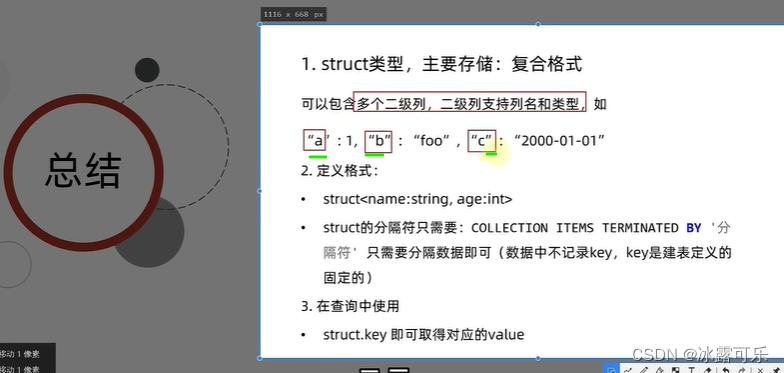
struct数据类型
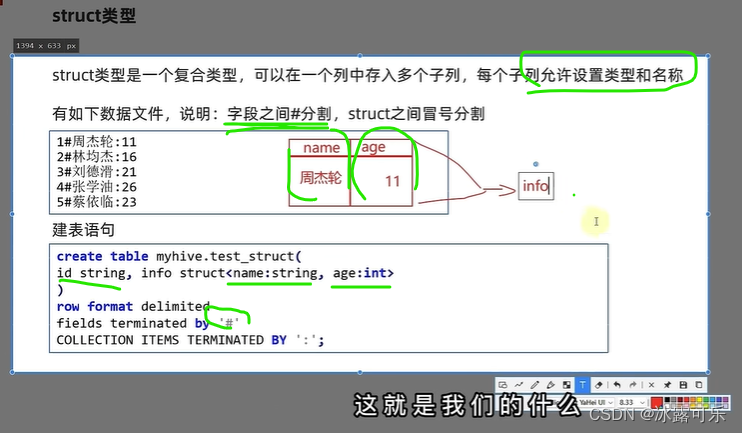
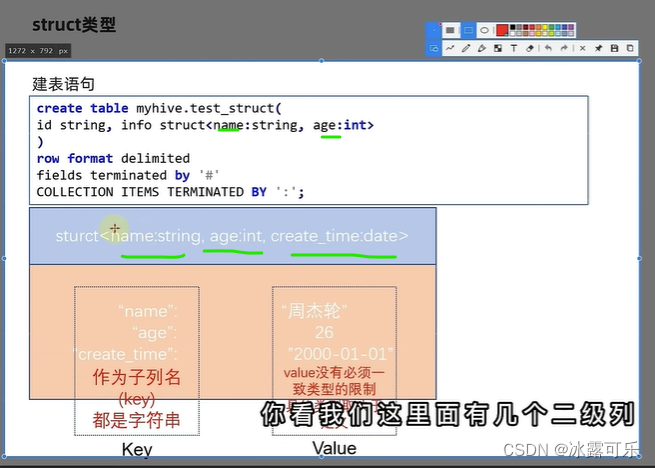
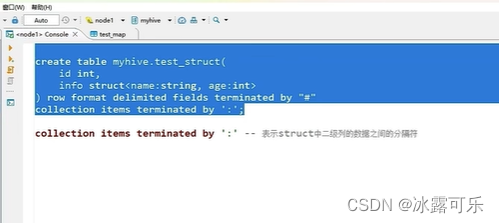
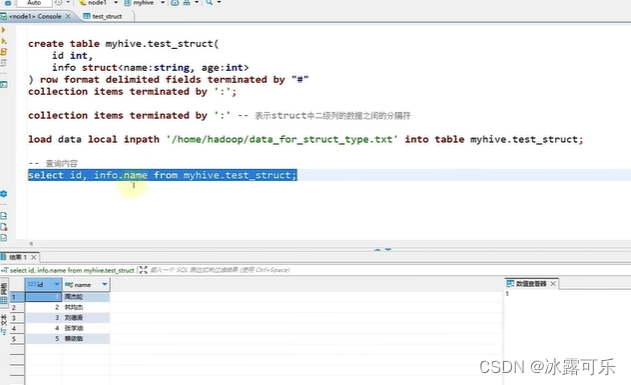
结构体,c中的
hive反正就是基于MapReduce的sql框架,它能写sql又能做分布式计算,这些知识好好复习,对于未来考网络警察很有帮助的。
总结
提示:重要经验:
1)
2)学好oracle,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。