一、 Redis中,使用有序集合(sorted set)实现滚动分页的原理如下:
- 将每个文档的 score 值设置为时间戳(或根据其他规则计算的分数),将文档的 ID 作为 value,然后将其添加到有序集合中。
- 获取当前时间戳,作为查询时间点。
- 使用 ZRANGEBYSCORE 命令根据 score 值范围查询出 score 值在当前时间戳之前的所有文档 ID。
- 返回查询结果作为当前页的结果集。
- 将当前页的最后一个文档 ID 作为新的查询起点,重复以上步骤,直到遍历所有文档。
二、Redis中,(sorted set)命令详细说明
Redis中的sorted set(有序集合)是一个数据结构,它允许你存储一组有序的元素(成员),每个元素可以有一个分数(score),分数可以用于排序、限制范围或聚合操作等。sorted set是自动排序的,并且所有的成员都是唯一的,不允许重复。
以下是在Redis中操作sorted set的命令:
1 ZADD key score member:
向有序集合中添加一个元素。
ZADD myset 7.5 "apple"
ZADD myset 9.0 "orange"
ZADD myset 8.2 "banana"
2 ZRANGE key start stop [WITHSCORES]:
返回有序集合中指定范围内的元素。
ZRANGE myset 0 -1 WITHSCORES
ZRANGE myset 1 2 WITHSCORES
结果:
127.0.0.1:6379> ZRANGE myset 0 -1 WITHSCORES
1) "apple"
2) "7.5"
3) "banna"
4) "8.1999999999999993"
5) "orange"
6) "9"
127.0.0.1:6379> ZRANGE myset 1 2 WITHSCORES
1) "banna"
2) "8.1999999999999993"
3) "orange"
4) "9"
3 ZREVRANGE key start stop [WITHSCORES]:
返回有序集合中指定范围内的元素,按照分数从大到小排序,与 ZRANGE 返回的结果相反。
ZREVRANGE myset 0 -1 WITHSCORES
ZREVRANGE myset 1 2 WITHSCORES
结果:
127.0.0.1:6379> ZREVRANGE myset 0 -1 withscores
1) "orange"
2) "9"
3) "banna"
4) "8.1999999999999993"
5) "apple"
6) "7.5"
127.0.0.1:6379> ZREVRANGE myset 1 2 withscores
1) "banna"
2) "8.1999999999999993"
3) "apple"
4) "7.5"
4 ZREM key member:
从有序集合中删除指定元素。
ZREM myset "apple"
ZREM myset "banana"
5 ZCARD key:
返回有序集合中元素的数量。
ZCARD myset
127.0.0.1:6379> ZCARD myset
(integer) 2
6 ZSCORE key member:
返回指定元素在有序集合中的分数。
ZSCORE myset "banana"
127.0.0.1:6379> ZSCORE myset "banana"
"7.9000000000000004"
7 ZREMRANGEBYSCORE key min max:
删除有序集合中分数在指定范围内的所有元素
127.0.0.1:6379> ZREMRANGEBYSCORE myset 6.5 8.5
(integer) 2
8 ZREMRANGE BY PRIORITY key min max:
删除有序集合中优先级在指定范围内的所有元素。与ZREMRANGE BY SCORE命令类似。
三、具体实现步骤如下:
1 向有序集合中添加文档:
在文档添加时,为每个文档添加一个时间戳作为score值,并将其文档ID作为value值。例如,使用以下Java代码向有序集合中添加文档:
ZAddArgs zAddArgs = new ZAddArgs(score, value);
redis.zAdd("docs", zAddArgs);
2 获取当前时间戳:
使用Java的System.currentTimeMillis()方法获取当前时间戳。
3 查询score值在当前时间戳之前的文档ID
使用以下Java代码查询有序集合中score值在当前时间戳之前的文档ID:
ZRangeArgs zRangeArgs = new ZRangeArgs(0, -1, score -> score < System.currentTimeMillis());
List<String> docIds = redis.zRangeByScore("docs", zRangeArgs);
其中,ZRangeArgs构造函数中的参数0表示起始位置为0,-1表示结束位置为集合末尾,score -> score < System.currentTimeMillis()表示只返回score值小于当前时间戳的文档ID。
4 返回查询结果作为当前页的结果集:
将查到的文档ID作为当前页的结果集返回。
5 将当前页的最后一个文档ID作为新的查询起点,重复以上步骤,直到遍历所有文档。
例如,使用以下Java代码将当前页的最后一个文档ID作为新的查询起点:
String lastDocId = docIds.get(docIds.size() - 1);
docIds = redis.zRangeByScore("docs", new ZRangeArgs(0, -1, score -> score < System.currentTimeMillis() - 86400000L), lastDocId, "LIMIT");
其中,ZRangeArgs构造函数中的参数表示从集合的起始位置开始返回文档ID,lastDocId表示只返回大于lastDocId且score值小于当前时间戳的文档ID,86400000L表示一天的毫秒数,表示向前滚动一页。
四、实例
1 回顾传统分页
传统的分页 前端参数一般传入当前页数curpage和页面长度paegsize 最终通过数据库limit curpage*(pageszie-1),pageszie 实现分页 假设两参数分别为1,5 即 limit 0,5 也就是查询序号0到4的5条数据 这时如果数据库新增了一条数据其序号为1。
如果查询下一页即limit 5,5 查询序号为5 到9的数据
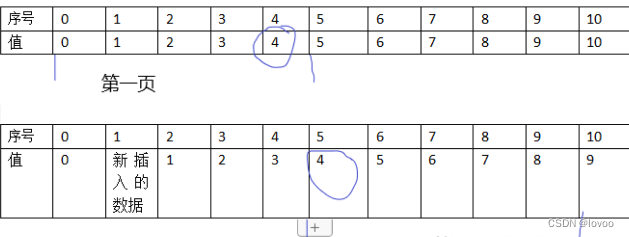
如图所示,很显然值为四的数据被重复查了。 查了下比较流行的做法就是新增一个字段,记录数据插入的时间。 然后查寻第一页的时候记录当前时间,之后每次分页查询都需要带上这个时间 把比这个时间大的数据排除。该方案挺不错,但是要修改数据库,费事.
2 使用Redis的zset分页
1 分页存在的问题
每次插入数据库成功时,额外保存一份<数据id,插入时间>到redis的有序集合里 。这时就可以通过插入时间分页了。第一次查询返回按时间排序前1到5的数据, 然后记录当前的时间6 。 之后的查询带上这个时间。 返回从 比这个时间小的第一个数据(即为5)和其后的四条数据。
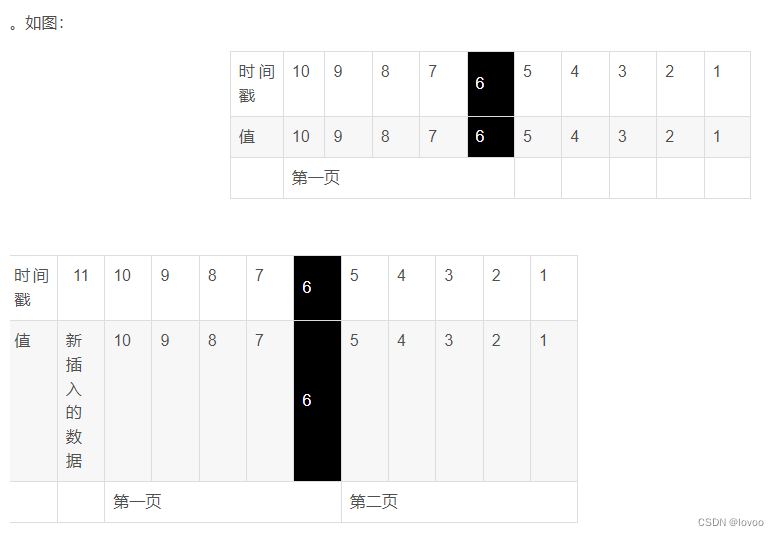
但是这也有个问题 假如同一时间新增很多条相同数据怎么办。
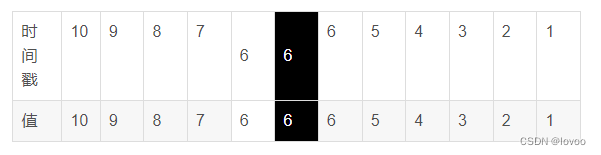
引入个新的变量offset 记录返回的数据中有几个和 他们最后一个数据时间相同 上图
第一次查询返回 10 9 8 7 6 6即为2。 然后下一次查询的参数即为最后一个数据的时间戳6 ,偏移量2 ,就能确定是从第三个6开始了
2 分页方法说明
ZREVRANGEBYSCORE key Max Min LIMIT offset count
ZREVRANGEBYSCORE z1 5 0 withscores limit 1 3
分页参数:
max: 当前时间戳 | 上一次查询人最小时间戳
min:0 最小值,不变
offset: 0 | 取决于上一次的结果,与最小元素的个数
count: 3 分页的页面大小,相当于pageSize
3 在点评小程序的应用
在本小程序中,我们要将粉丝关注我的博客数排序
- 保存博客时,将我的博客发送到粉丝的信箱,也就是按粉丝的id与博客id对保存到redis中
@PostMapping
public Result saveBlog(@RequestBody Blog blog) {
// 获取登录用户
UserDTO user = UserHolder.getUser();
Long userId = user.getId();
blog.setUserId(userId);
// 保存探店博客
if (blogService.save(blog)) {
Long currTime = System.currentTimeMillis();
// 博客推送给关注作者的人
// 1获得关注该作者的用户列表
List<Follow> follows = followService.query().select("user_id").eq("follow_user_id", userId).list();
for (Follow follow : follows
) {
Long followId = follow.getUserId();
//
String key = RedisConstants.FEED_KEY + followId;
stringRedisTemplate.opsForZSet().add(key,String.valueOf(blog.getId()),currTime);
}
// 返回id
return Result.ok(blog.getId());
}
return Result.fail("发布笔记失败");
}
- 读取信箱,按评分进行分页
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
//1 获取当前用户
Long userId = UserHolder.getUser().getId();
//2 查询收件箱
String key = RedisKey.FEED_KEY + userId;
//3 解析数据 blogId、minTime时间戳、offset
Set<ZSetOperations.TypedTuple<String>> tuples = stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0, max, offset, 2);
//4 非空判断
if (tuples == null || tuples.isEmpty()) {
return Result.ok();
}
//5 遍历
long minTime = 0; //获取时间错最小值,遍历完最后一个值
int offsetResutl = 1; //偏移量,为最小值的个数
List<Long> ids = new ArrayList<>(tuples.size());
for (ZSetOperations.TypedTuple<String> tuple : tuples) {
long time = tuple.getScore().longValue();
if(time == minTime){
offsetResutl ++ ;
}else {
//如果与最小时间不同,则最小时间重新赋值,将 offsetFirst重新赋值为1
minTime = time;
offsetResutl = 1;
}
String blogId = tuple.getValue();
ids.add(Long.valueOf(blogId));
}
//6 根据id 查询blog
String idsStr = StrUtil.join(",", ids);
List<Blog> blogs = this.lambdaQuery().eq(Blog::getId, ids).last("order by field(id," + idsStr + ")").list();
//7 封装结果
ScrollResult scrollResult = new ScrollResult();
scrollResult.setList(blogs);
scrollResult.setOffset(offsetResutl);
scrollResult.setMinTime(minTime);
return Result.ok(scrollResult);
}
UserHolder 实体类
public class UserHolder {
private static final ThreadLocal<UserDTO> tl = new ThreadLocal<>();
public static void saveUser(UserDTO user){
tl.set(user);
}
public static UserDTO getUser(){
return tl.get();
}
public static void removeUser(){
tl.remove();
}
}
UserDTO 实体类
@Data
public class UserDTO {
private Long id;
private String nickName;
private String icon;
}
Blog 实体类
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
@TableName("tb_blog")
public class Blog implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
/**
* 商户id
*/
private Long shopId;
/**
* 用户id
*/
private Long userId;
/**
* 用户图标
*/
@TableField(exist = false)
private String icon;
/**
* 用户姓名
*/
@TableField(exist = false)
private String name;
/**
* 是否点赞过了
*/
@TableField(exist = false)
private Boolean isLike;
/**
* 标题
*/
private String title;
/**
* 探店的照片,最多9张,多张以","隔开
*/
private String images;
/**
* 探店的文字描述
*/
private String content;
/**
* 点赞数量
*/
private Integer liked;
/**
* 评论数量
*/
private Integer comments;
/**
* 创建时间
*/
private LocalDateTime createTime;
/**
* 更新时间
*/
private LocalDateTime updateTime;
}
Result实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Result {
private Boolean success;
private String errorMsg;
private Object data;
private Long total;
public static Result ok(){
return new Result(true, null, null, null);
}
public static Result ok(Object data){
return new Result(true, null, data, null);
}
public static Result ok(List<?> data, Long total){
return new Result(true, null, data, total);
}
public static Result fail(String errorMsg){
return new Result(false, errorMsg, null, null);
}
}
Follow实体类
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
@TableName("tb_follow")
public class Follow implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
/**
* 用户id
*/
private Long userId;
/**
* 关联的用户id
*/
private Long followUserId;
/**
* 创建时间
*/
private LocalDateTime createTime;
}
五、源码下载
https://gitee.com/charlinchenlin/koo-erp