近年来,计算机视觉取得了显着进步,特别是在图像分割和目标检测任务方面。 Segment Anything Model (SAM) 是最近的一项重大突破,这是一种多功能的深度学习模型,旨在有效地从图像和输入提示中预测对象掩码。 通过利用强大的编码器和解码器,SAM 能够处理范围广泛的分割任务,使其成为研究人员和开发人员等的宝贵工具。

推荐:用 NSDT设计器 快速搭建可编程3D场景
1、SAM简介
SAM 使用图像编码器(通常是视觉转换器 (ViT))来提取图像嵌入,作为掩码预测的基础。 该模型还包含一个提示编码器,它对各种类型的输入提示进行编码,例如点坐标、边界框和低分辨率掩码输入。 然后将这些编码的提示连同图像嵌入一起输入掩码解码器以生成最终的对象掩码。
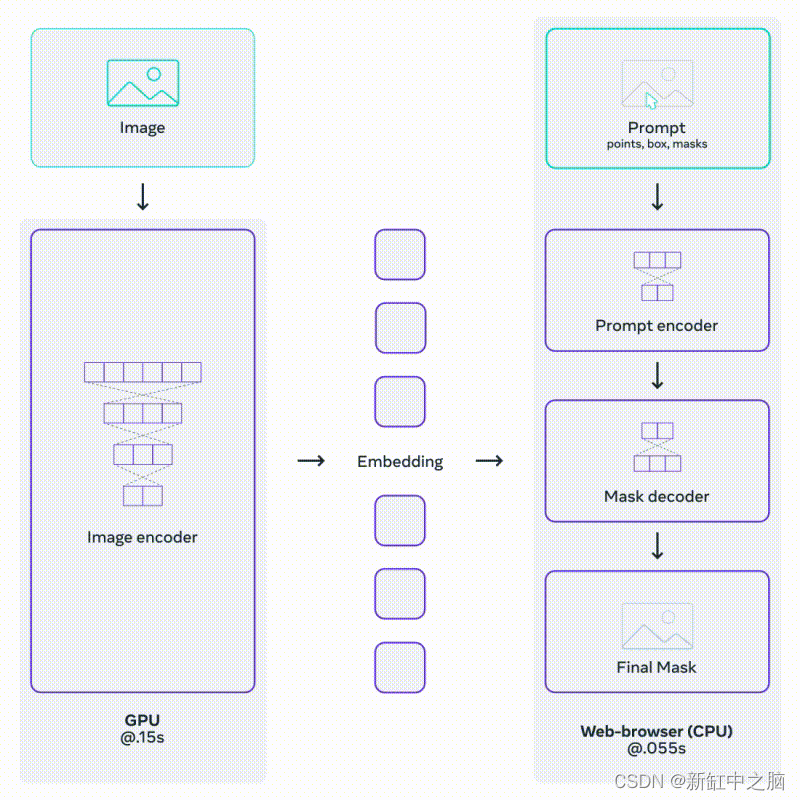
上述架构允许在已经编码的图像上进行快速和轻便的提示。
SAM 旨在处理各种提示,包括:
- Mask:可以提供一个粗糙的、低分辨率的二进制掩码作为初始输入来指导模型。
- Point:用户可以输入 [x, y] 坐标及其类型(前景或背景)以帮助定义对象边界。
- Box:可以使用坐标 [x1, y1, x2, y2] 指定边界框,以告知模型对象的位置和大小。
- Text:文本提示也可用于提供额外的上下文或指定感兴趣的对象。
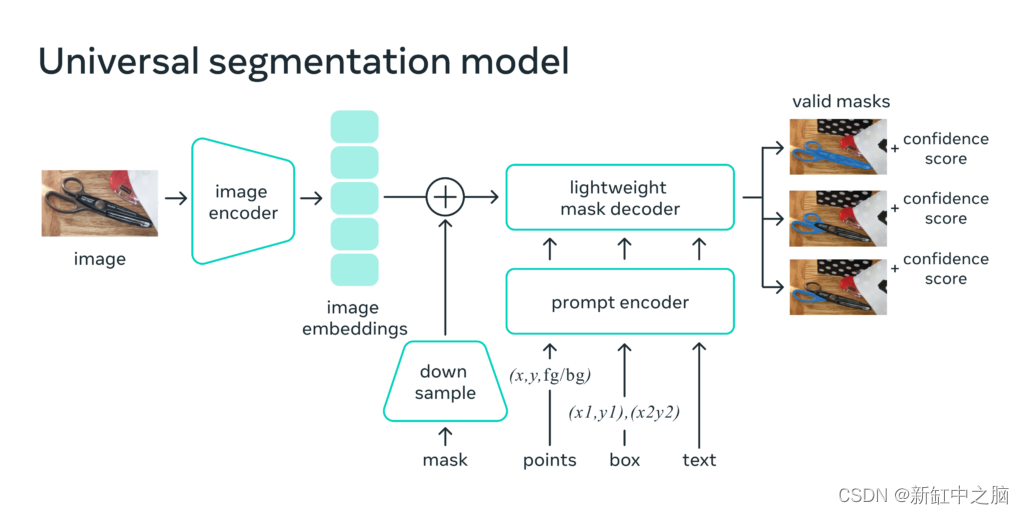
深入研究 SAM 的架构,我们可以探索其关键组件:
- 图像编码器:SAM默认的图像编码器是ViT-H,但也可以根据具体要求使用ViT-L或ViT-B。
- 下采样:为了降低提示二进制掩码的分辨率,采用了一系列卷积层。
- 提示编码器:位置嵌入用于对各种输入提示进行编码,这有助于告知模型图像中对象的位置和上下文。
- Mask 解码器:修改后的 transformer 编码器用作 mask 解码器,将编码的提示和图像嵌入转换为最终的对象掩码。
- 有效掩码:对于任何给定的提示,SAM 都会生成三个最相关的掩码,为用户提供一系列可供选择的选项。
他们使用 focal、dice 和 IoU 损失的加权组合来训练模型。 权重分别为 20、1、1。
SAM 的优势在于它的适应性和灵活性,因为它可以使用不同的提示类型来生成准确的分割掩码。 与作为各种自然语言处理应用程序的强大基础的基础语言模型 (LLM) 非常相似,SAM 也为计算机视觉任务提供了坚实的基础。 该模型的架构旨在促进下游任务的轻松微调,使其能够针对特定用例或领域进行定制。 通过针对特定任务数据微调 SAM,开发人员可以增强其性能并确保其满足其应用程序的独特要求。
这种微调能力不仅让 SAM 在各种场景下都能获得令人印象深刻的性能,而且还促进了更高效的开发过程。 以预训练模型为起点,开发人员可以专注于针对他们的特定任务优化模型,而不是从头开始。 这种方法不仅节省了时间和资源,而且还利用了预训练模型中编码的广泛知识,从而使系统更加稳健和准确。
2、自然语言提示
文本提示与 SAM 的集成使模型能够执行高度特定和上下文感知的对象分割。 通过利用自然语言提示,可以引导 SAM 根据感兴趣的对象的语义特性、属性或与场景中其他对象的关系来分割感兴趣的对象。
在训练 SAM 的过程中,使用最大的公开可用的 CLIP 模型(ViT-L/14@336px)来计算文本和图像嵌入。 这些嵌入在用于训练过程之前被归一化。
为了生成训练提示,首先将每个掩码周围的边界框扩展一个范围为 1x 到 2x 的随机因子。 然后将展开的框裁剪成正方形以保持其纵横比并将大小调整为 336×336 像素。 在将作物送入 CLIP 图像编码器之前,掩膜外的像素以 50% 的概率被清零。 Masked attention 在编码器的最后一层使用,以确保嵌入集中在对象上,将输出 token 的注意力限制在 mask 内的图像位置。 输出标记嵌入作为最终提示。 在训练过程中,首先提供基于 CLIP 的提示,然后是迭代点提示以改进预测。
对于推理,未修改的 CLIP 文本编码器用于为 SAM 创建提示。 该模型依赖于 CLIP 实现的文本和图像嵌入的对齐,这使得在没有显式文本监督的情况下进行训练,同时仍然使用基于文本的提示进行推理。 这种方法允许 SAM 有效地利用自然语言提示来实现准确和上下文感知的分割结果。
不幸的是,Meta 还没有发布带有文本编码器的 SAM 的权重。
3、lang-segment-anything
lang-segment-anything 库结合了 GroundingDino 和 SAM 的优势,提供了一种创新的对象检测和分割方法。
最初,GroundingDino 执行零样本文本到边界框对象检测,根据自然语言描述有效地识别图像中感兴趣的对象。 然后将这些边界框用作 SAM 模型的输入提示,该模型会为已识别的对象生成精确的分割掩码。
from PIL import Image
from lang_sam import LangSAM
from lang_sam.utils import draw_image
model = LangSAM()
image_pil = Image.open('./assets/car.jpeg').convert("RGB")
text_prompt = 'car, wheel'
masks, boxes, labels, logits = model.predict(image_pil, text_prompt)
image = draw_image(image_pil, masks, boxes, labels)

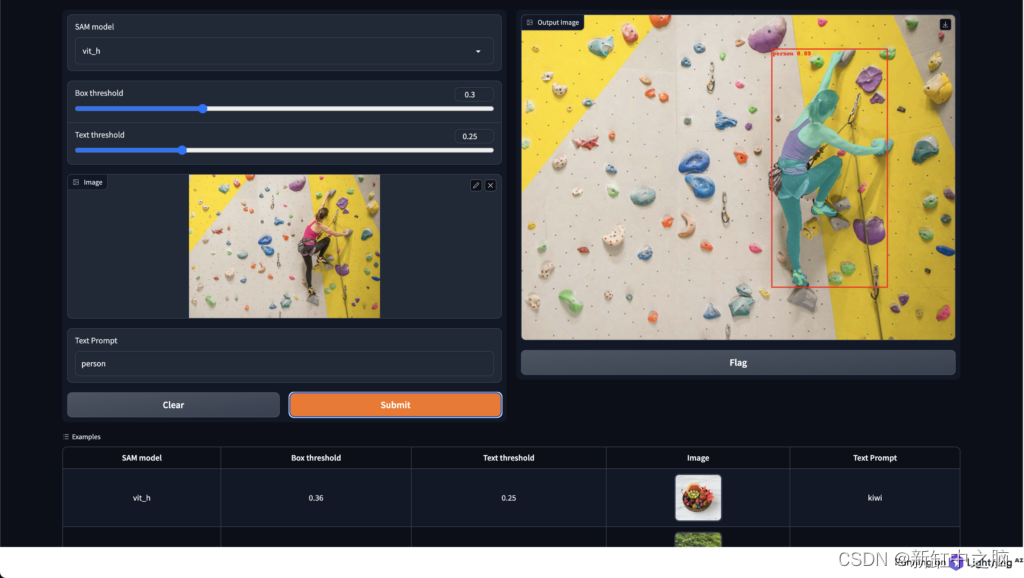
4、Lightening应用
你可以使用 Lightning AI App 框架快速部署应用程序。 我们将使用 ServeGradio 组件来部署带有 UI 的模型。 可以在此处了解有关 ServeGradio 的更多信息。
import os
import gradio as gr
import lightning as L
import numpy as np
from lightning.app.components.serve import ServeGradio
from PIL import Image
from lang_sam import LangSAM
from lang_sam import SAM_MODELS
from lang_sam.utils import draw_image
from lang_sam.utils import load_image
class LitGradio(ServeGradio):
inputs = [
gr.Dropdown(choices=list(SAM_MODELS.keys()), label="SAM model", value="vit_h"),
gr.Slider(0, 1, value=0.3, label="Box threshold"),
gr.Slider(0, 1, value=0.25, label="Text threshold"),
gr.Image(type="filepath", label='Image'),
gr.Textbox(lines=1, label="Text Prompt"),
]
outputs = [gr.outputs.Image(type="pil", label="Output Image")]
def __init__(self, sam_type="vit_h"):
super().__init__()
self.ready = False
self.sam_type = sam_type
def predict(self, sam_type, box_threshold, text_threshold, image_path, text_prompt):
print("Predicting... ", sam_type, box_threshold, text_threshold, image_path, text_prompt)
if sam_type != self.model.sam_type:
self.model.build_sam(sam_type)
image_pil = load_image(image_path)
masks, boxes, phrases, logits = self.model.predict(image_pil, text_prompt, box_threshold, text_threshold)
labels = [f"{phrase} {logit:.2f}" for phrase, logit in zip(phrases, logits)]
image_array = np.asarray(image_pil)
image = draw_image(image_array, masks, boxes, labels)
image = Image.fromarray(np.uint8(image)).convert("RGB")
return image
def build_model(self, sam_type="vit_h"):
model = LangSAM(sam_type)
self.ready = True
return model
app = L.LightningApp(LitGradio())
就这样,应用程序在浏览器中启动了!
5、结论
这就是我们对 Segment Anything Model 的介绍。 很明显,SAM 是计算机视觉研究人员和开发人员的宝贵工具,它能够处理各种分割任务并适应不同的提示类型。 它的架构易于实施,使其具有足够的通用性,可以针对特定的用例和领域进行定制。 总体而言,SAM 已迅速成为机器学习社区的重要资产,并且肯定会继续在该领域掀起波澜。
原文链接:用自然语言分割图像 — BimAnt