文章目录
- 为什么要解析特征层
- 如何可视化特征层
- 可视化结果如何
❤️ 🧡 💛 💚 💙 💜 🖤 🤍 🤎 💔 ❣️ 💕 💞 💓 💗 💖 💘 💝 ❤️ 🧡 💛 💚 💙 💜 🖤 🤍 🤎 💔 ❣️ 💕 💞 💓 💗 💖 💘 💝
为什么要解析特征层
在深度学习中,特征层是指神经网络中的一组层,在输入数据经过前几层后,将其分析和抽象为更高层次的特征表示。这些特征层对于网络的性能和训练结果有关键的影响。因此,在深度学习网络的训练过程中,对每一层特征层进行可视化和保存,可以帮助研究者更全面地了解网络内部的运作情况,并通过可视化结果的更新来调整网络的超参数和架构,从而提升网络的性能和训练效果。此外,特征层的可视化结果也可以帮助深度学习研究者和工程师更好地理解网络的决策过程和提高解释性。
如何可视化特征层
以ResNet系列为例,在网络训练过程中,我们找到网络定义的forward函数,如下面代码:
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=10, # 种类修改的地方,是几种就把这个改成几
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet50(num_classes=1000, include_top=True, plot_fm=False, name=""):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top, plot_fm=plot_fm, name=name)
这个代码展示了resnet网络整体架构
在训练阶段我们可以加载模型(创建优化器之前)
model = resnet50()
if pretrained:
# 加载预训练权重文件
#model.load_state_dict(torch.load('预训练权重文件路径'))
pass
model.fc = nn.Linear(model.fc.in_features, num_classes)
criterion = nn.CrossEntropyLoss()
知道了整体网络架构之后,我们可以在网络结构中加入可视化特征的代码,如下所示
import time
import matplotlib.pyplot as plt
import numpy as np
def draw_features(width,height,x,savename):
tic=time.time()
fig = plt.figure(figsize=(16, 16))
fig.subplots_adjust(left=0.05, right=0.95, bottom=0.05, top=0.95, wspace=0.05, hspace=0.05)
for i in range(width*height):
plt.subplot(height,width, i + 1)
plt.axis('off')
# plt.tight_layout()
img = x[0, i, :, :]
pmin = np.min(img)
pmax = np.max(img)
img = (img - pmin) / (pmax - pmin + 0.000001)
plt.imshow(img, cmap='gray')
print("{}/{}".format(i,width*height))
fig.savefig(savename, dpi=100)
fig.clf()
plt.close()
print("time:{}".format(time.time()-tic))
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=10, # 种类修改的地方,是几种就把这个改成几
include_top=True,
groups=1,
width_per_group=64,
plot_fm=False,name=""): # plot_fm控制是否要绘制特征图,name控制保存文件的名字
super(ResNet, self).__init__()
self.plot_fm = plot_fm
self.savepath='data/resultck/feature_map_save_{}'.format(name) # 创建保存特征图的位置
os.makedirs(self.savepath, exist_ok=True)
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
if self.plot_fm:
x = self.conv1(x)
draw_features(8,8,x.cpu().detach().numpy(),"{}/f1_conv1.png".format(self.savepath)) # 绘制第一个卷积层所有通道的可视化情况
print("{}/f1_conv1.png".format(self.savepath))
x = self.bn1(x)
draw_features(8, 8, x.cpu().detach().numpy(),"{}/f2_bn1.png".format(self.savepath))
print("{}/f2_bn1.png".format(self.savepath))
x = self.relu(x)
draw_features(8, 8, x.cpu().detach().numpy(),"{}/f3_relu.png".format(self.savepath))
print("{}/f3_relu.png".format(self.savepath))
x = self.maxpool(x)
draw_features(8, 8, x.cpu().detach().numpy(),"{}/f4_maxpool.png".format(self.savepath))
print("{}/f4_maxpool.png".format(self.savepath))
x = self.layer1(x)
draw_features(16, 16, x.cpu().detach().numpy(), "{}/f5_layer1.png".format(self.savepath))
print("{}/f5_layer1.png".format(self.savepath))
x = self.layer2(x)
draw_features(16, 32, x.cpu().detach().numpy(), "{}/f6_layer2.png".format(self.savepath))
print("{}/f6_layer2.png".format(self.savepath))
x = self.layer3(x)
draw_features(32, 32, x.cpu().detach().numpy(), "{}/f7_layer3.png".format(self.savepath))
print("{}/f7_layer3.png".format(self.savepath))
x = self.layer4(x)
draw_features(32, 32, x.cpu().detach().numpy()[:, 0:1024, :, :], "{}/f8_layer4.png".format(self.savepath))
print("{}/f8_layer4.png".format(self.savepath))
if self.include_top:
x = self.avgpool(x)
plt.plot(np.linspace(1, 2048, 2048), x.cpu().detach().numpy()[0, :, 0, 0])
plt.savefig("{}/f9_avgpool.png".format(self.savepath))
plt.clf()
plt.close()
x = torch.flatten(x, 1)
x = self.fc(x)
else:
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet50(num_classes=1000, include_top=True, plot_fm=False, name=""):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top, plot_fm=plot_fm, name=name)
if modelName == "resnet50":
model = resnet50(plot_fm=plot_fm,name=modelName)
if pretrained:
# 加载预训练权重文件
#model.load_state_dict(torch.load('预训练权重文件路径'))
pass
注意
1. draw_features(8,8,x.cpu()…;这里的8,8意思是这里的通道数是64,也就是8*8。如果不清楚可以通过 print(x.cpu().detach().numpy().shape)查看
2. draw_features(32, 32, x.cpu().detach().numpy()[:, 0:1024, :, :], “{}/f8_layer4.png”.format(self.savepath))这里的1024表示最大通道数。
可视化结果如何
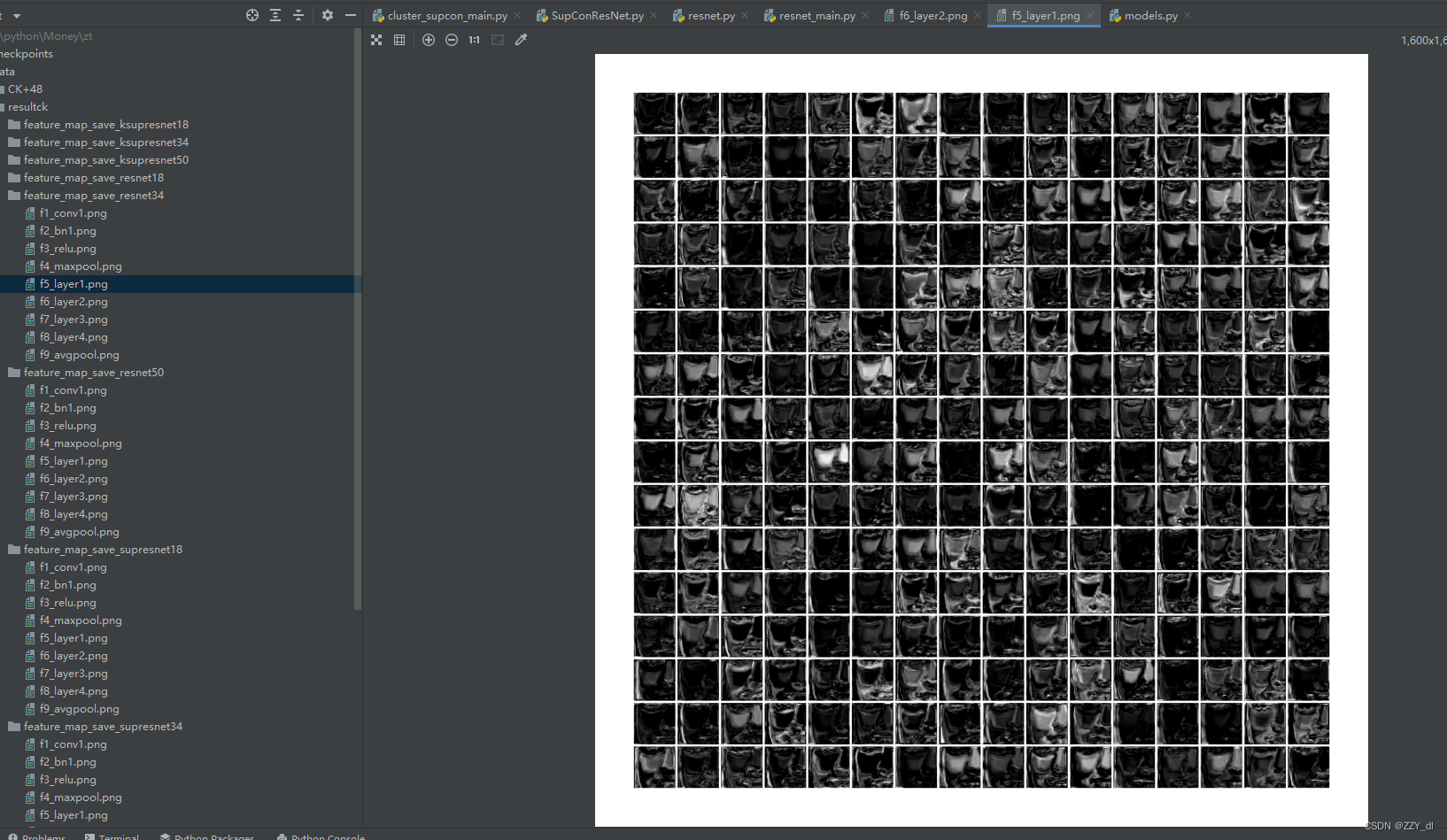

通过这样可视化,你可以清楚的看到每层特征的处理情况,以及对比不同网络下不同层的特征训练情况,通过对比可以发现哪种方法更有效。新的特征可视化情况会覆盖原始的特征可视化图,如果要在网页上实时显示,可以利用tensorboard工具来解决。可参考这篇博客:链接
非常感谢您的阅读!如果您觉得这篇文章对您有帮助,请点赞支持,您的支持是我写作的最大动力!同时,欢迎关注我的博客,我将持续分享更多深度学习、计算机视觉等方面的内容!
❤️ 🧡 💛 💚 💙 💜 🖤 🤍 🤎 💔 ❣️ 💕 💞 💓 💗 💖 💘 💝 ❤️ 🧡 💛 💚 💙 💜 🖤 🤍 🤎 💔 ❣️ 💕 💞 💓 💗 💖 💘 💝