文章目录
- 数据库约束
- NULL约束
- UNIQUE:唯一约束
- DEFAULT:默认值约束
- PRIMARY KEY:主键约束
- FOREIGN KEY:外键约束
- 表的设计——一对一、一对多、多对多
- 增删改查进阶
- 聚合函数
- Group by分组
- having:分组后的条件过滤
- 联合查询
- 内连接
- 外连接
- 自连接
- 子查询(嵌套查询)
- 合并查询
- UNION ALL
- UNION
数据库约束
约束: 按照一定条件进行规范的做事
表定义的时候,某些字段保存的数据,需要按照一定的约束条件
NULL约束
字段 null: 该字段可以为null(空)
字段 not null :该字段不允许为null
CREATE TABLE student1(
id INT NOT NULL,
sn INT,
name VARCHAR(20),
qq_mail VARCHAR(20)
);
其中,id字段设为NOT NULL, 当该字段插入null值时,会报错


UNIQUE:唯一约束
约束 该字段 值是唯一的,不能重复的。
-- 重新设置学生表结构
DROP TABLE IF EXISTS student1;
CREATE TABLE student1 (
id INT NOT NULL,
sn INT UNIQUE,
name VARCHAR(20),
qq_mail VARCHAR(20)
);

DEFAULT:默认值约束
某个字段,设置了default及默认值,插入的时候,该列不插入,就会插入默认值.
-- 重新设置学生表结构
DROP TABLE IF EXISTS student1;
CREATE TABLE student1 (
id INT NOT NULL,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20)
);
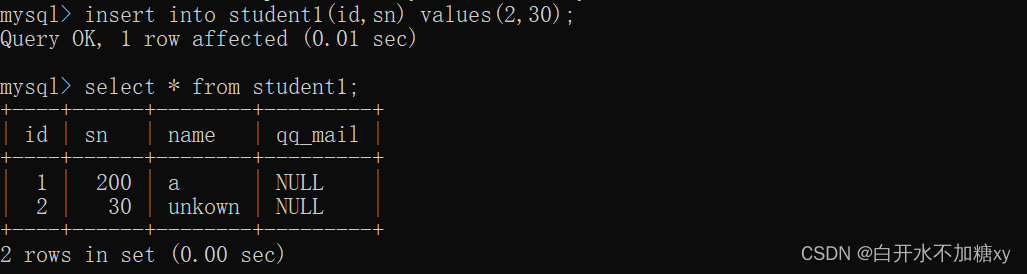
显式的插入数据,即使是null,默认值也不会生效:

插入字段不使用name,才会插入默认值:
PRIMARY KEY:主键约束
主键一般就用于某张表,标识唯一的一条数据
primary key = not null unique
-- 重新设置学生表结构
DROP TABLE IF EXISTS student1;
CREATE TABLE student1 (
id INT NOT NULL PRIMARY KEY auto_increment,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20)
);
主键字段,不插入,或是插入重复,就会报错:

简单看,一张表,一般都需要设计一个主键
如果使用整型主键,还可以结合auto_increment,表示从1开始,++自增
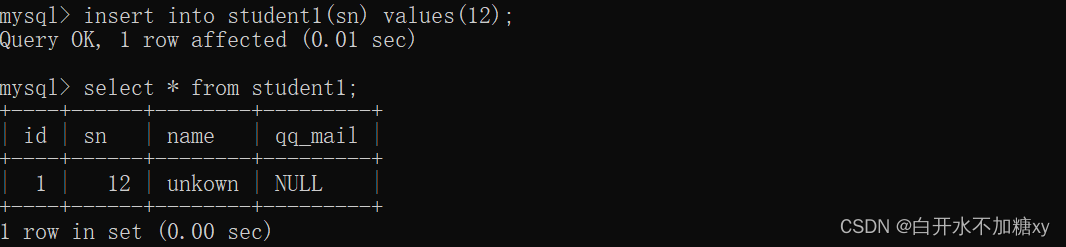
主键指定为自增的方式,就可以不插入数据,自动从1开始,依次递增:
FOREIGN KEY:外键约束
外键用于关联其他表的主键或唯一键
foreign key (字段名) references 主表(列)
班级表主键id:
-- 创建班级表,有使用MySQL关键字作为字段时,需要使用``来标识
DROP TABLE IF EXISTS classes;
CREATE TABLE classes (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
`desc` VARCHAR(100)
);
学生表:一个学生对应一个班级,一个班级对应多个学生
-- 重新设置学生表结构
DROP TABLE IF EXISTS student1;
CREATE TABLE student1 (
id INT PRIMARY KEY auto_increment,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20),
classes_id int,
FOREIGN KEY (classes_id) REFERENCES classes(id)
);
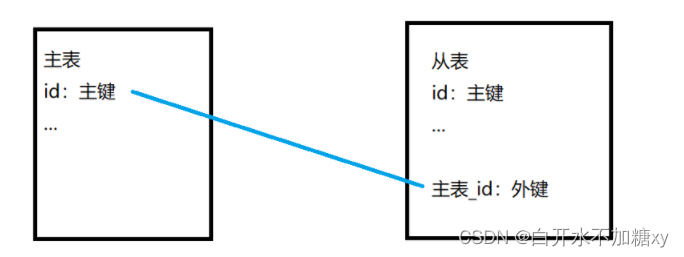
主表的主键 关联 从表的外键(实际上,建立外键,不一定非使用主键来关联,只是最常用主键和外键关联)
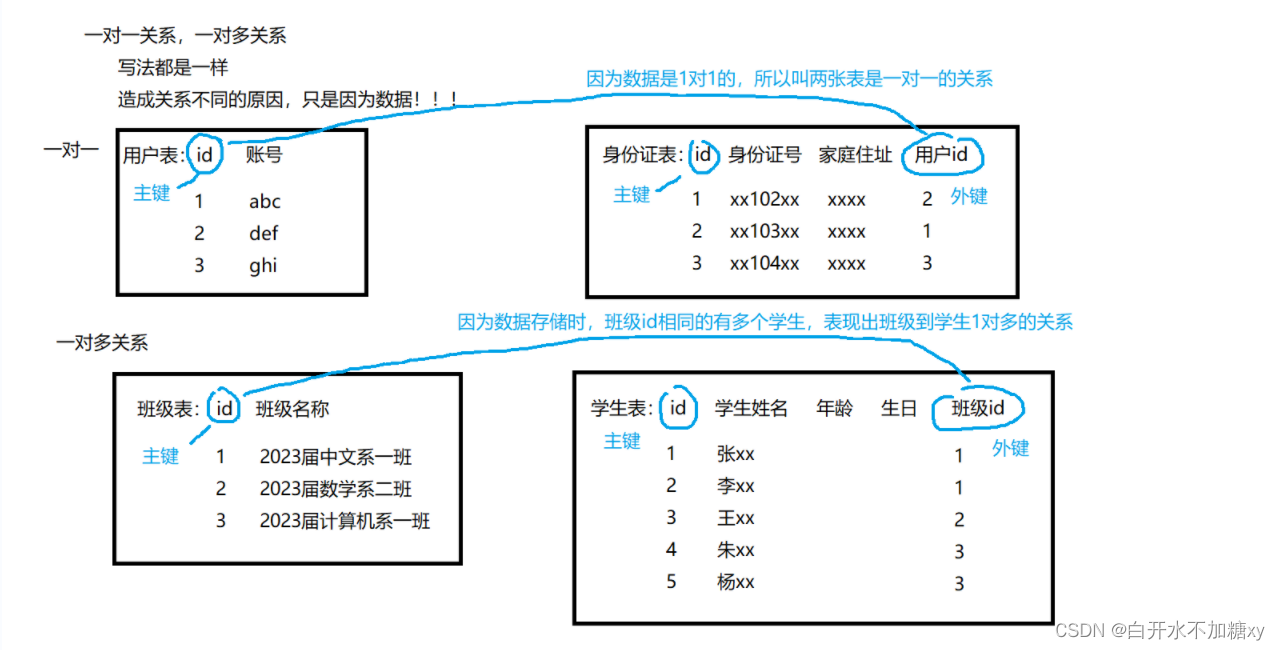
表的设计——一对一、一对多、多对多
一对一 一对多
多对多
表设计时候:
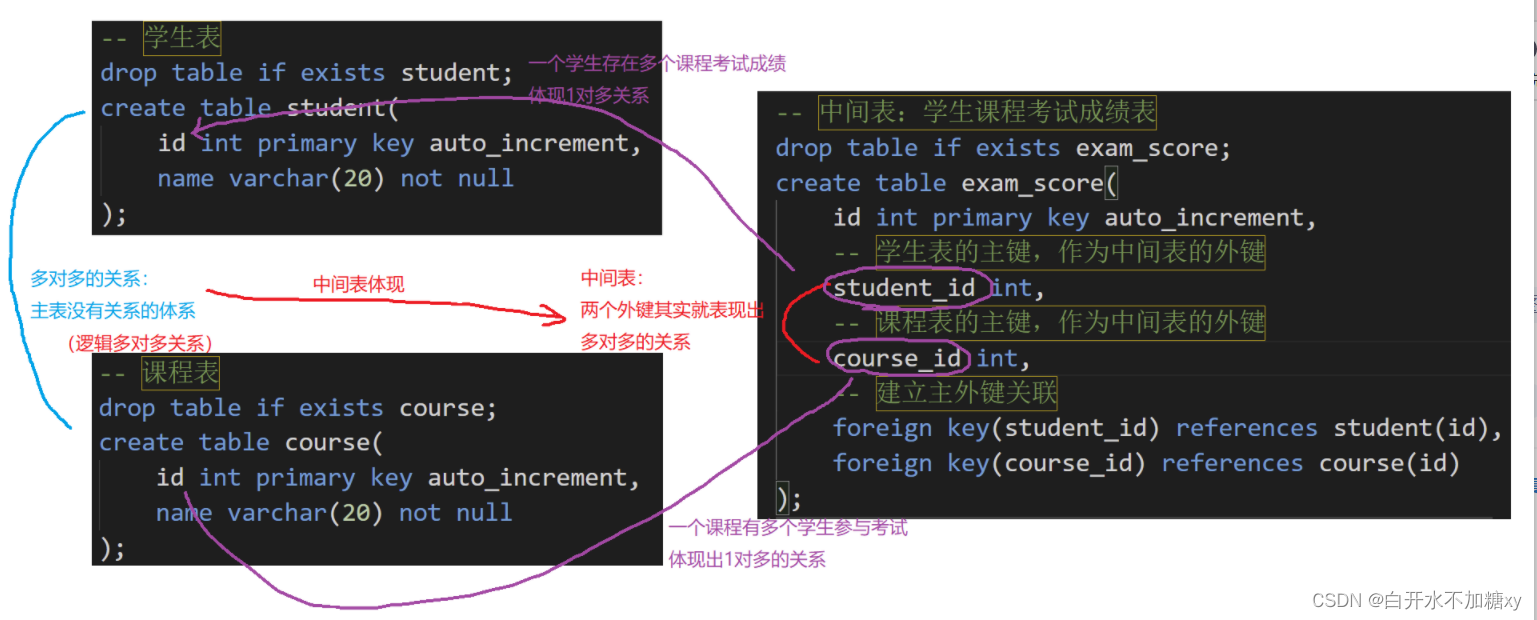
1.两张主表建立多对多关系:这个多对多关系,在两张主表中,没有外键体现。
2.使用一张单独中间表,来表示 两张主表 多对多关系。
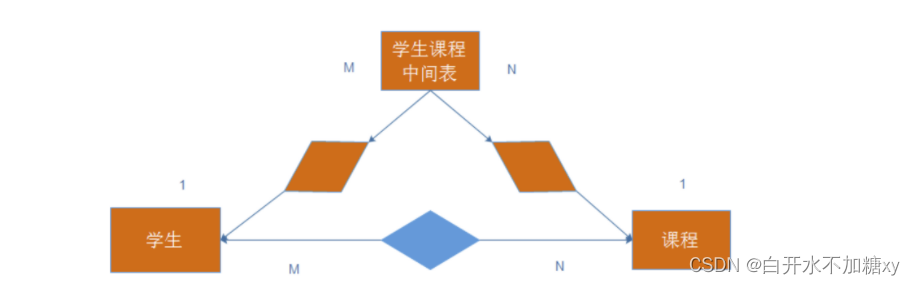
学生和课程,在某个业务发生后,就可能产生关系如:
考试:1个学生考多门课程,一门课程有多个学生考试
设计上:使用中间表保存
(1)两个外键:分别关联两张主表的主键
(2〉还可能设计一些业务的字段:如我们这里就是考试成绩
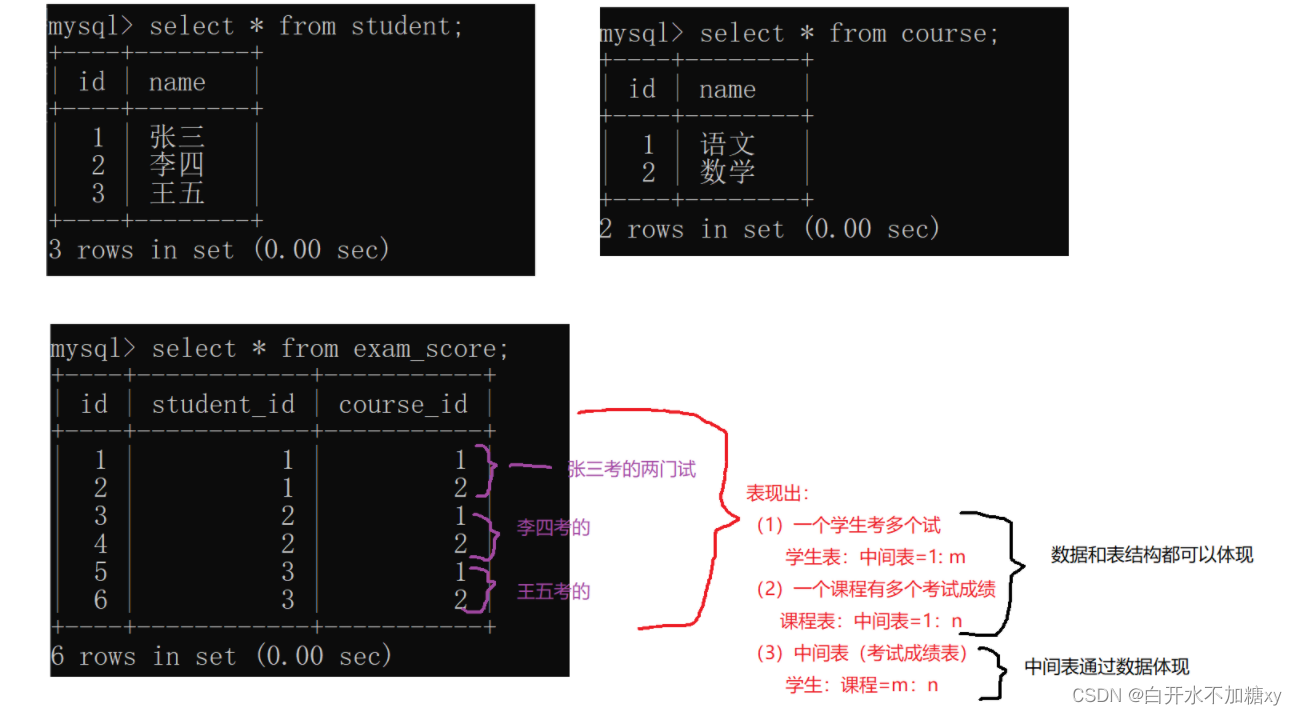
表结构上:只有两个1对多关系。
-- 班级表
drop table if exists classes;
create table classes (
id int primary key auto_increment,
name varchar(20)
);
insert into classes(name) values('2022届中文系一班');
insert into classes(name) values('2022届数学系二班');
drop table if exists student;
create table student(
id int primary key auto_increment,
name varchar(20) not null,
classes_id int,
foreign key (classes_id) references classes(id)
);
insert into student(name, classes_id) values('张三', 1);
insert into student(name, classes_id) values('李四', 1);
insert into student(name, classes_id) values('王五', 2);
drop table if exists course;
create table course(
id int primary key auto_increment,
name varchar(20) not null
);
insert into course(name) values ('语文');
insert into course(name) values ('数学');
drop table if exists exam_score;
create table exam_score(
id int primary key auto_increment,
score decimal(4,1),
student_id int,
course_id int,
foreign key (student_id) references student(id),
foreign key (course_id) references course(id)
);
insert into exam_score(student_id, course_id, score) values (1, 1, 101);
insert into exam_score(student_id, course_id, score) values (1, 2, 120);
insert into exam_score(student_id, course_id, score) values (2, 1, 78);
insert into exam_score(student_id, course_id, score) values (2, 2, 99.5);
insert into exam_score(student_id, course_id, score) values (3, 1, 115.5);
insert into exam_score(student_id, course_id, score) values (3, 2, 104);
增删改查进阶

使用场景:
1.复制表
⒉提前准备一些统计的数据(统计的sql一般关联很多表,条件可能也很复杂,执行效率可能不高)
很多系统就提前在凌晨系统不忙的时候,定时运行任务,将这些统计的数据,准备在单独的一张表中
drop table if exists score_total;
create table score_total(
id int primary key auto_increment,
score decimal(4, 1),
student_id int,
student_name varchar(20),
course_id int,
course_name varchar(20)
);
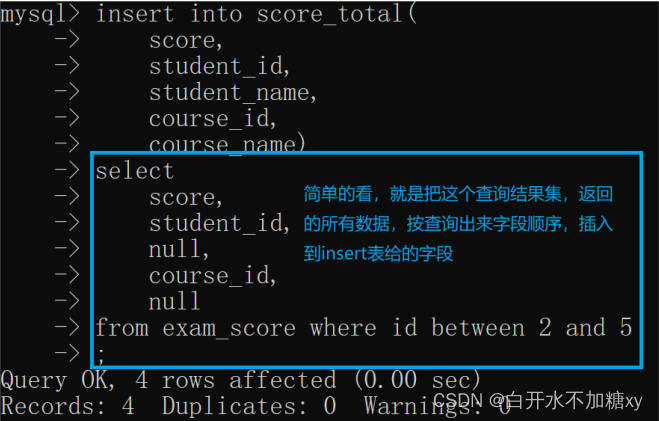
insert into score_total(
score,
student_id,
student_name,
course_id,
course_name)
select
score,
student_id,
null,
course_id,
null
from exam_score where id between 2 and 5;
聚合函数
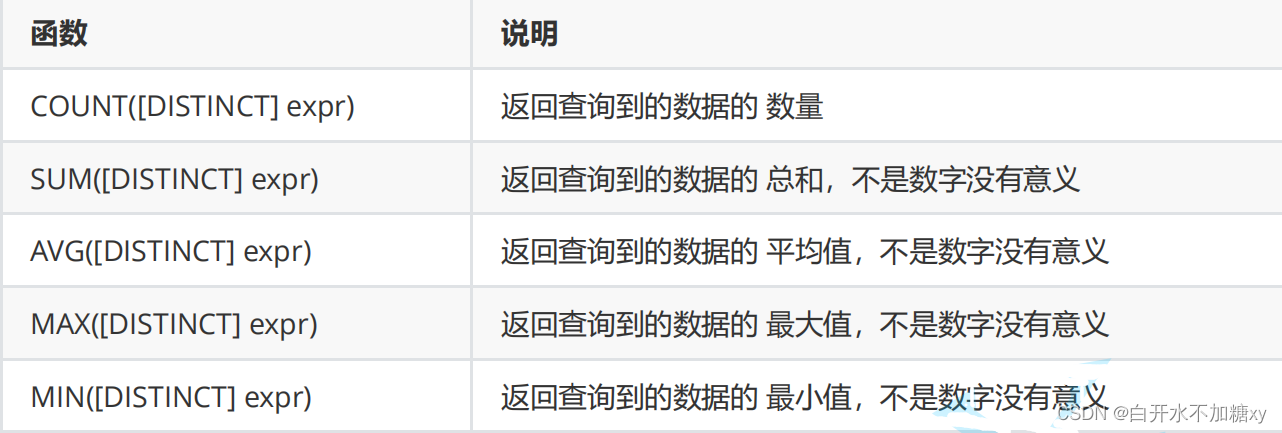
count(某个字段)= count(*) = count(常量值)
Group by分组
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:
使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中
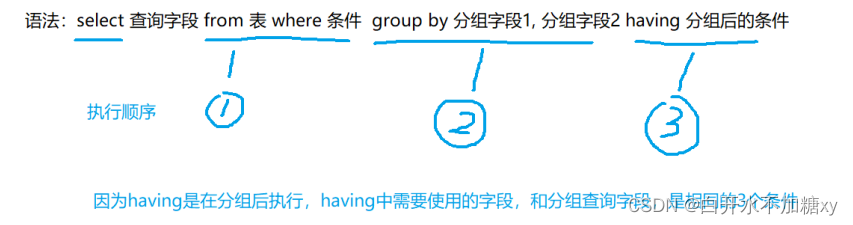
语法:
select column1, sum(column2), .. from table group by column1;
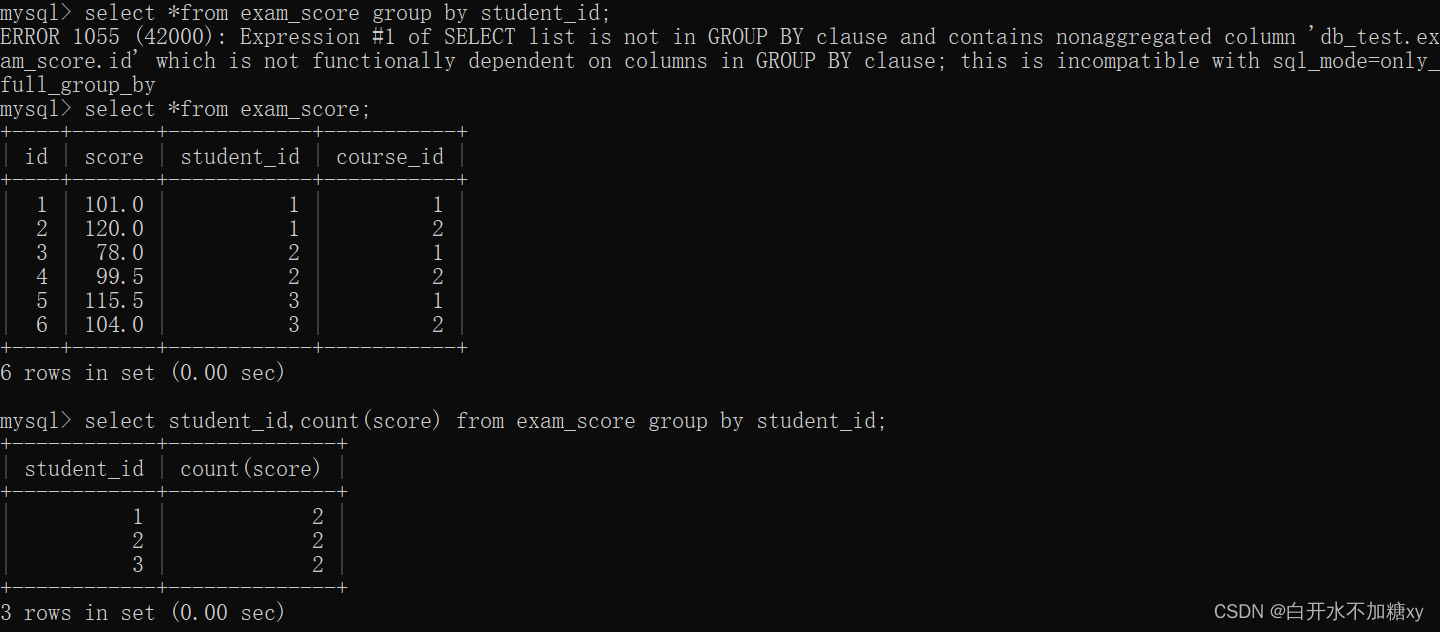
分组查询操作:查询字段必须是
(1)分组字段
(2)如果分组会造成聚合,非分组字段必须写在聚合函数中
(3) 分组不会造成聚合,非分组字段就可以直接写
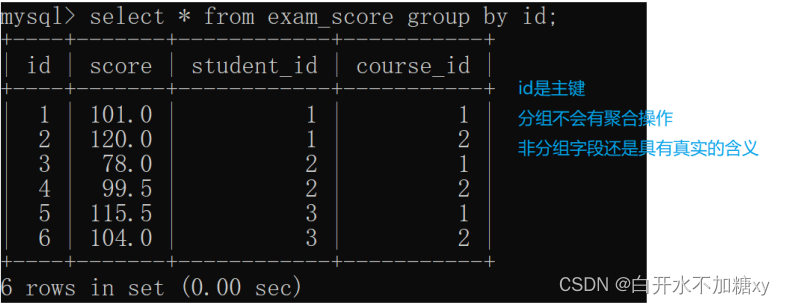
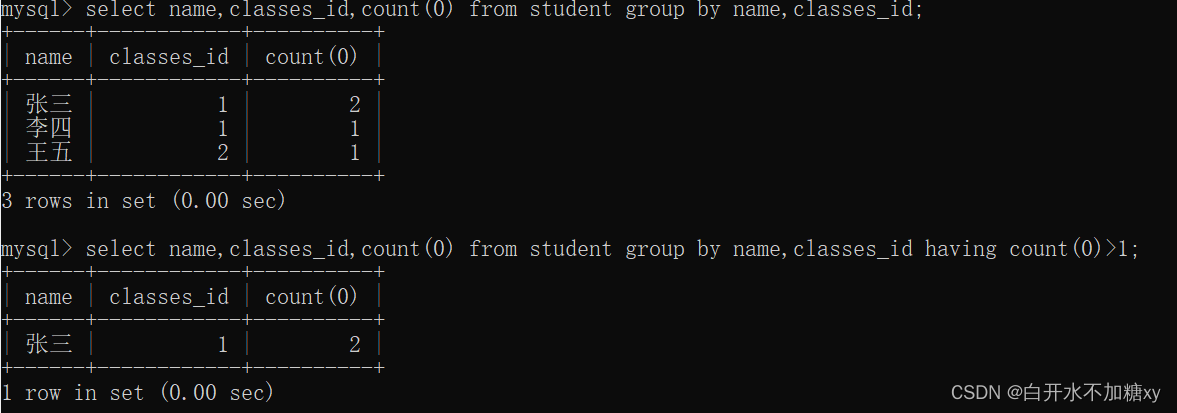
having:分组后的条件过滤
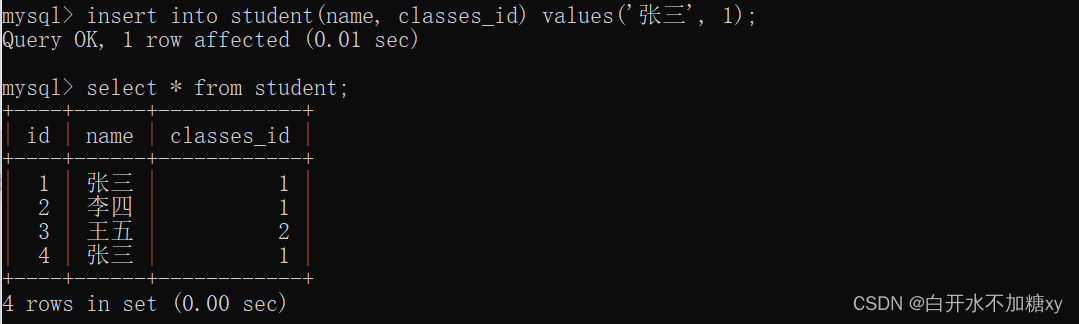
-- group by + having 查询重复的数据
-- 先准备重复数据:学生表学生姓名+班级id表示是否重复
insert into student(name, classes_id) values('张三', 1);
select name, classes_id, count(0) from student group by name, classes_id having count(0)>1;
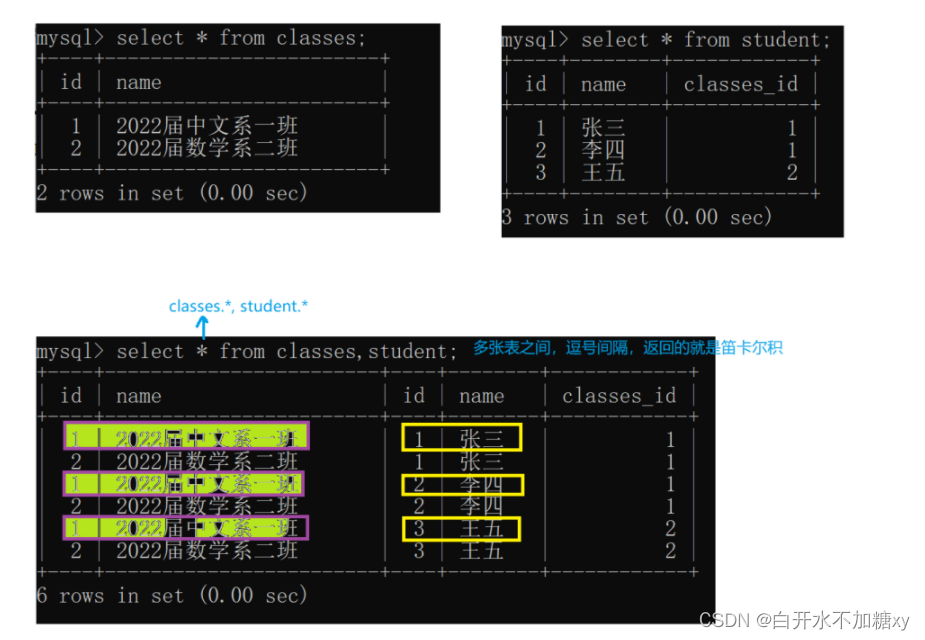
联合查询
多表查询是对多张表的数据取笛卡尔积
简单来说,就是:
1.遍历第一张表的数据
⒉每条数据,和第二张表的所有数据,相关联
3.遍历第二张表的数据
笛卡尔积的结果: 就是两张表的每条数据相连接,产生的一个结果集(虚拟表)
结果集行数=第一张表行数*第二张表的行数
两张表取笛卡尔积:部分数据实际上没有意义
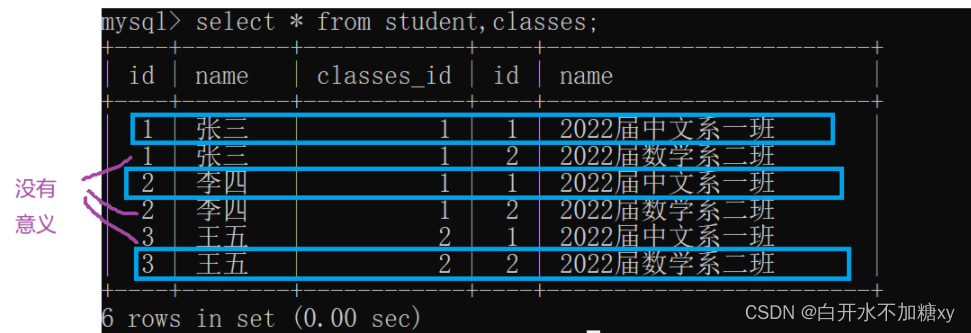
联合查询:单纯笛卡尔积返回的结果集,进行过滤(把不符合真实业务的数据过滤掉),剩下的就是有意义
多表联合查询操作,使用字段的时候,必须使用表名.字段名这样的方式,否则就会报错
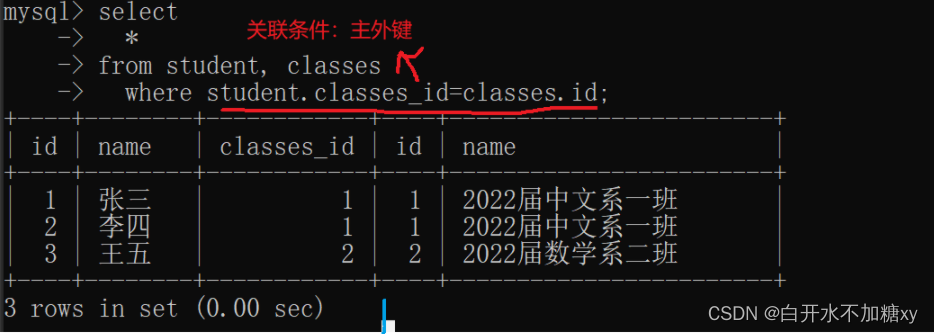
每个字段,都要加表名,写起来不方便可以加上表的别名
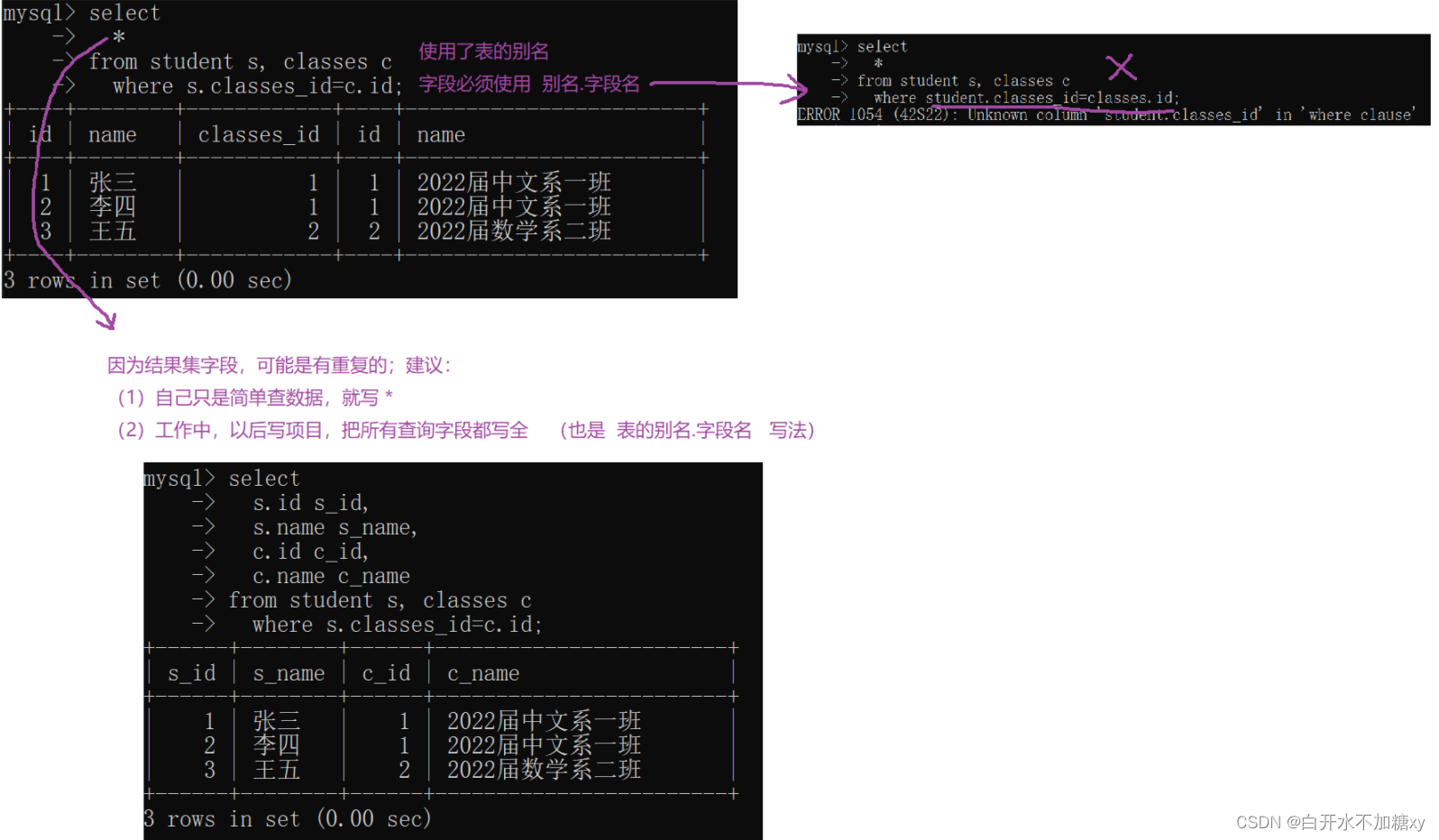
内连接
select 查询字段 from 表1,表2 where 连接条件 and 其他条件
select 查询字段 from 表1 [inner] join 表2 on 连接条件 and 其他条件
如:查询所有班级,在id=1的课程,平均分
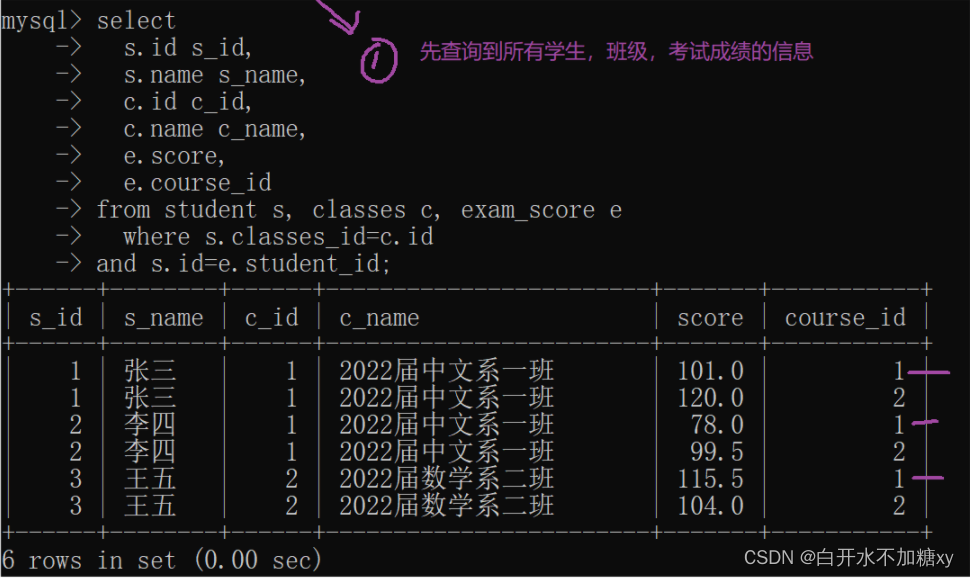
2.where查询条件:课程id=1
3.对班级id字段进行分组,取score的聚合avg
-- 扩展:可以关联2张以上的表
select
s.id s_id,
s.name s_name,
c.id c_id,
c.name c_name,
e.score,
e.course_id
from student s, classes c, exam_score e
where s.classes_id=c.id
and s.id=e.student_id;
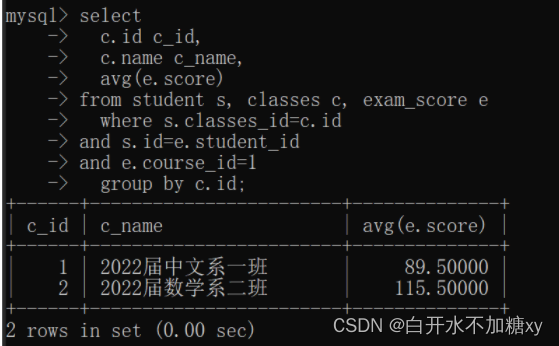
-- 查询课程id=1的所有班级的平均分
select
c.id c_id,
c.name c_name,
avg(e.score)
from student s, classes c, exam_score e
where s.classes_id=c.id
and s.id=e.student_id
and e.course_id=1
group by c.id;
外连接
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
语法:
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件
-- 观察外连接和内连接查询结果的区别
-- 新插入班级表一条数据
insert into classes(name) values('2022届计算机系一班');
-- 内连接:关联学生和班级表:班级中没有学生的就无法显示
select s.id s_id,s.name s_name,c.id c_id,c.name c_name from student s,classes c where s.classes_id=c.id;
-- 使用外连接,班级表作为外表,即使班级没有学生,也可以显示
select s.id s_id, s.name s_name, c.id c_id, s.classes_id, c.name c_name from student s right join classes c on s.classes_id=c.id;
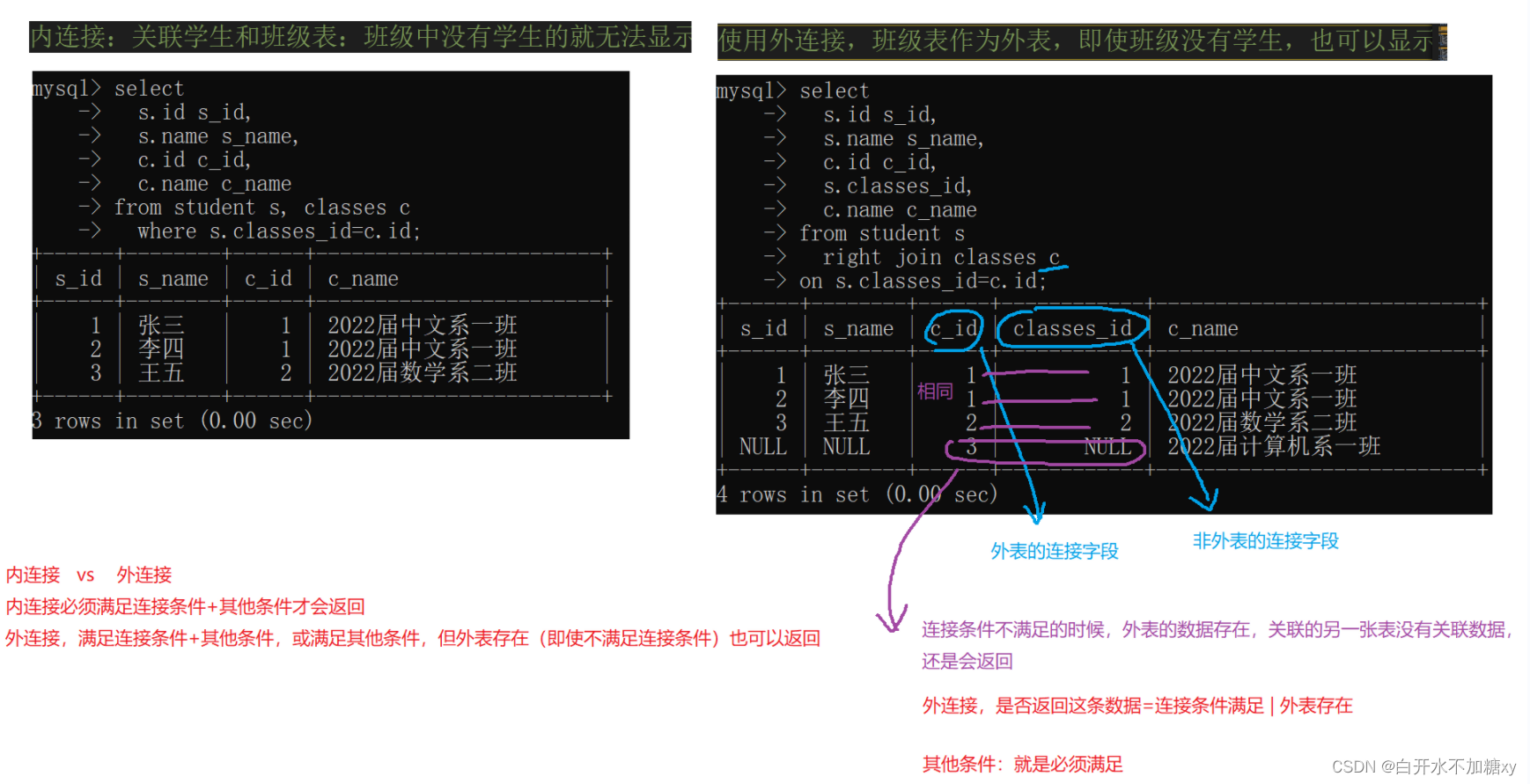
select 查询字段from 左表 left join 右表 on 连接条件 where 其他条件
select 查询字段from 左表 right join 右表 on 连接条件 where 其他条件
注:其他条件必须满足

自连接
自连接是指在同一张表连接自身进行查询。
示例:查语文成绩比数学成绩高的记录

先取笛卡尔积观察结果
select *from exam_score e1,exam_score e2;
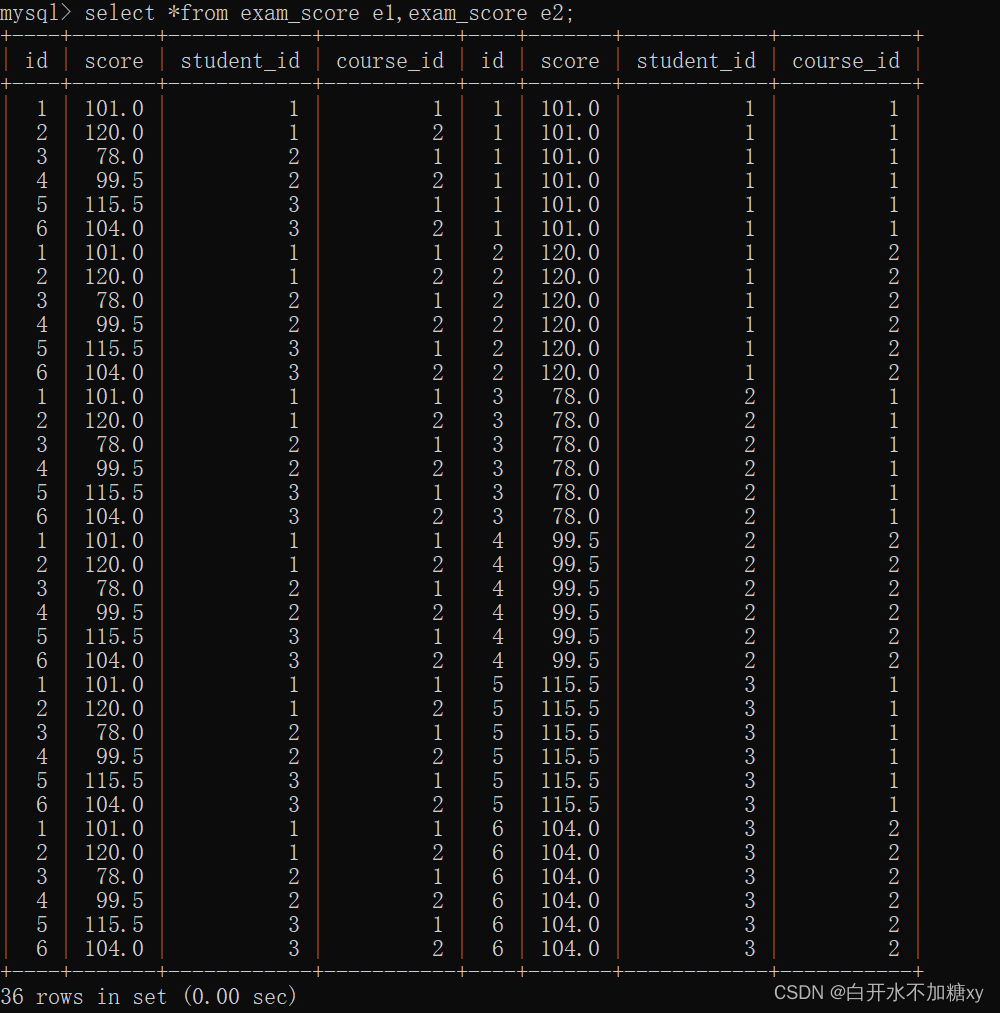
我们是取同一个学生,语文成绩比数学成绩高:按学生id作为连接条件
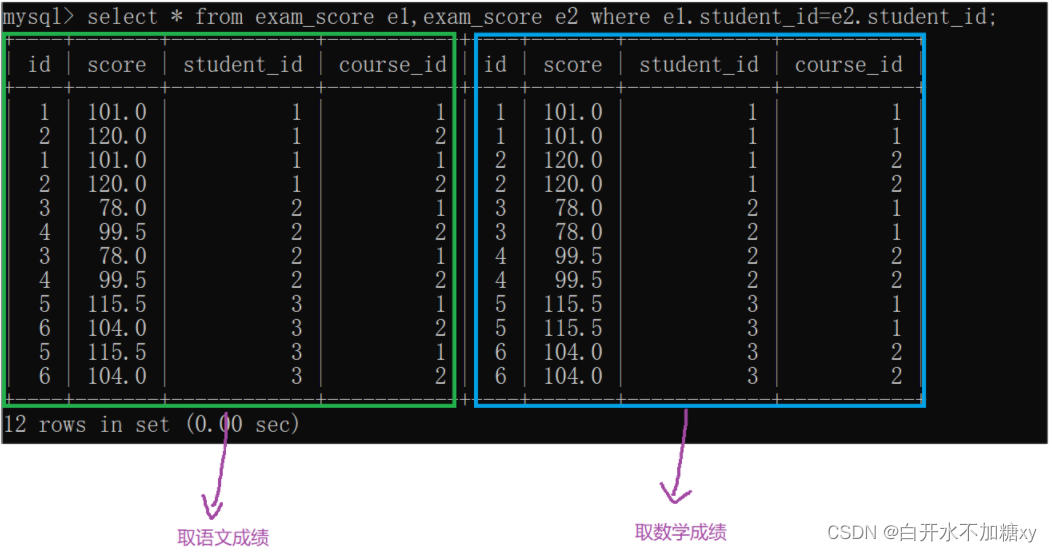
取表e1 的语文成绩,取表e2的数学成绩:

第一个score>第二个score,就是符合条件的

如果是查询语文成绩比数学成绩高,就不能使用id来过滤

子查询(嵌套查询)
select语句,用()包起来,用在其他的地方:如常量,表,in
(1)子查询返回一行一列的时候,可以当作常量
张三的同班同学
select *from student where classes_id=(select classes_id from student where name='张三');

(2) in()

1.子查询:返回多行一列
查询张三和李四成绩
-- 子查询:返回多行1列
-- 查询“张三”和“李四”的成绩
-- 先查询学生id
select id from student where name='张三' or name='李四';
-- 再查询成绩表中,学生id再以上结果集的学生id
select
*
from exam_score
where student_id in(
select id from student where name='张三' or name='李四'
);
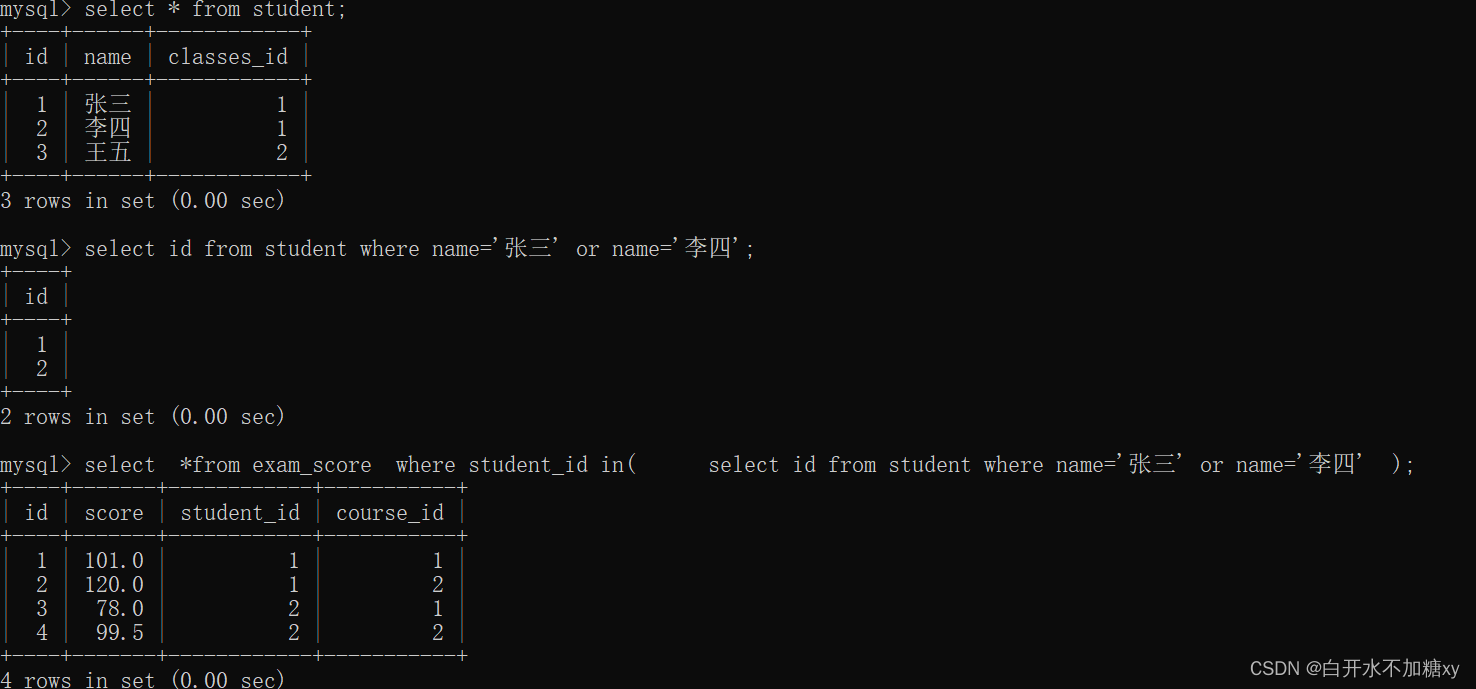
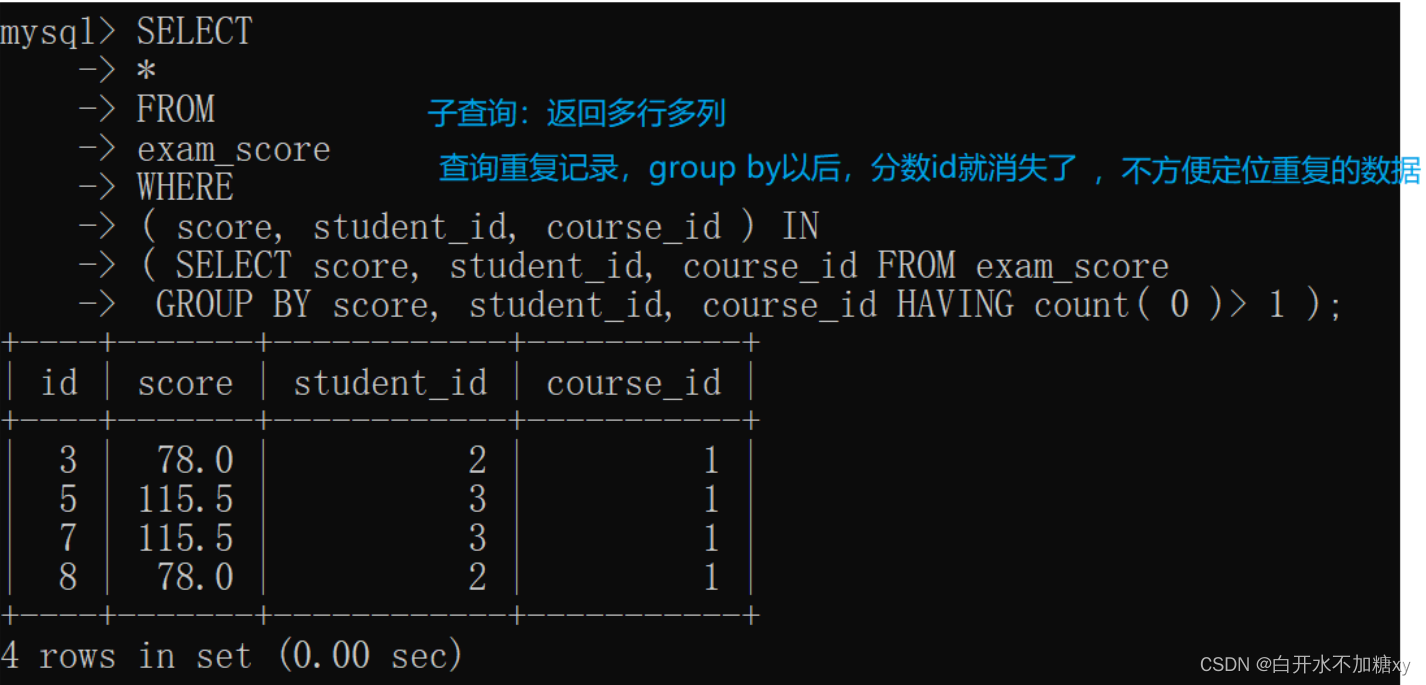
2.子查询:返回多行多列
-- 查询分数表中重复的记录:分数+学生id+课程id都一样,就表示重复
insert into exam_score(score, student_id, course_id)
values
( 115.5, 3, 1 ),
( 78, 2, 1 );
-- 查询重复的分数: 这样分数id再聚合后就消失了
select score, student_id, course_id from exam_score group by score, student_id, course_id having count(0)>1;
SELECT
*
FROM
exam_score
WHERE
( score, student_id, course_id ) IN
( SELECT score, student_id, course_id FROM exam_score
GROUP BY score, student_id, course_id HAVING count( 0 )> 1 );
查询重复记录,group by以后,分数id就消失了,不方便定位重复的数据
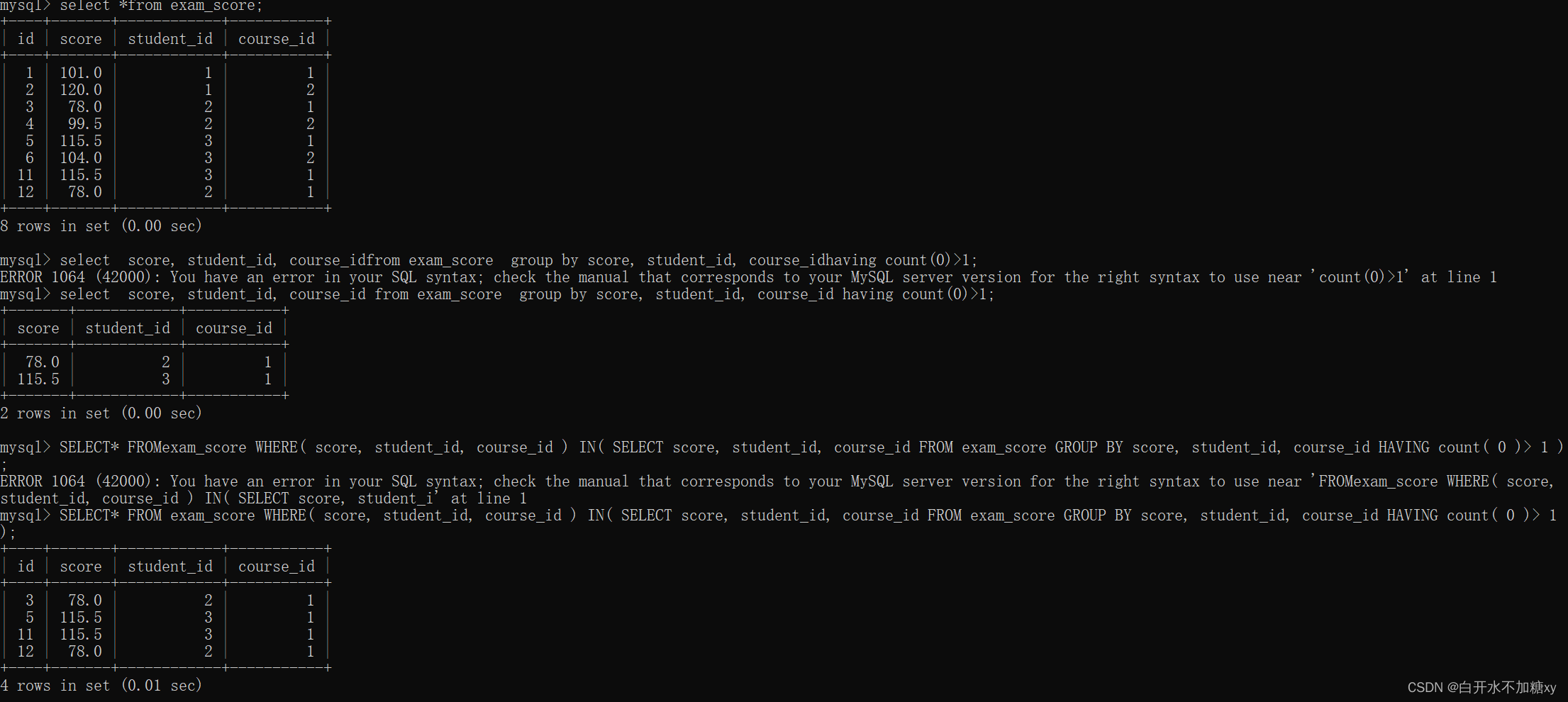
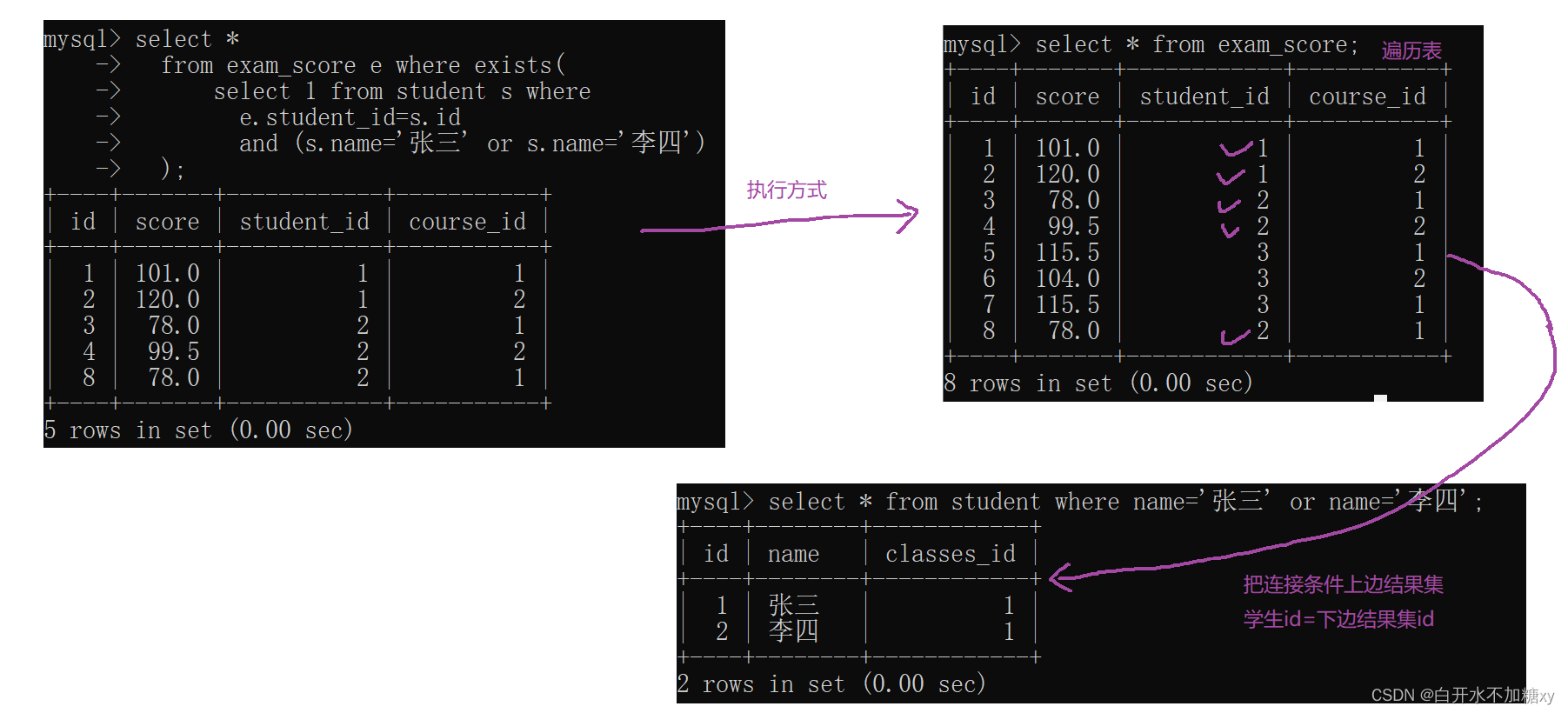
(3) [not] exists:
-- [not] in 可以改为 [not] exists 的写法
-- 再查询成绩表中,学生id再以上结果集的学生id(以上in的写法)
select
*
from exam_score
where student_id in(
select id from student where name='张三' or name='李四'
);
-- 改为exists
select *
from exam_score e where exists(
select 1 from student s where
e.student_id=s.id
and (s.name='张三' or s.name='李四')
);
执行过程:
(4)子查询作为临时表
查询成绩表中,分数比“2022届中文系一班”平均分高的
-- 子查询:作为临时表,可以关联其他表
-- 查询成绩表中,分数比“2022届中文系一班”平均分高的
-- 查平均分
select avg(e.score) from exam_score e, student s, classes c
where e.student_id=s.id and s.classes_id=c.id
and c.name='2022届中文系一班';
select es.*
from exam_score es,
(
select avg(e.score) avg_score from exam_score e, student s, classes c
where e.student_id=s.id and s.classes_id=c.id and c.name='2022届中文系一班')tmp
where es.score>tmp.avg_score;
合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致。
注:两个结果集的查询字段,顺序和数量要一致
UNION ALL
取得两个结果集的并集

UNION
取两个结果集的并集,并去重((按结果集所有查询字段去重)
单表的结果集取并集其实是可以使用or实现的,但union是使用两个结果集(不一定是一张表)







![[附源码]Python计算机毕业设计Django青栞系统](https://img-blog.csdnimg.cn/767ba2b81b35430a8b12681c5db5d7ae.png)