DeiT详解:知识蒸馏的Transformer
- 0. 引言
- 1. ViT
- 2. DeiT
- 2.1 知识蒸馏
- 2.1.1 提出背景
- 2.1.2 理论原理
- 2.2 DeiT模型
- 3. 总结
0. 引言
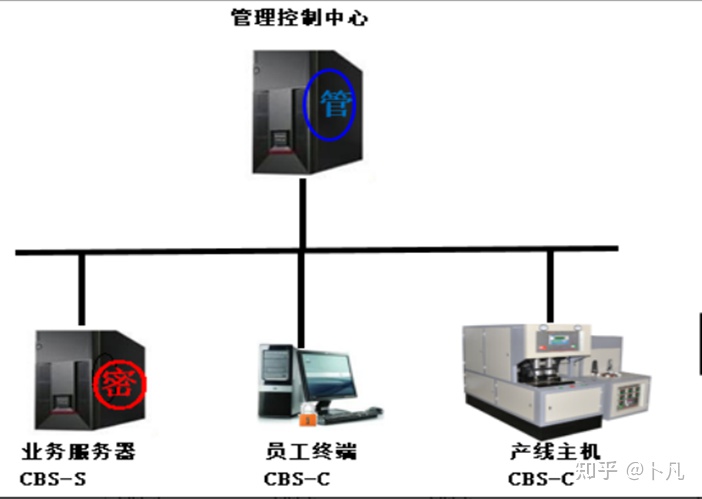
针对 ViT 需求数据量大、运算速度慢的问题,Facebook 与索邦大学 Matthieu Cord 教授合作发表 Training data-efficient image transformers(DeiT) & distillation through attention。DeiT 将知识蒸馏的策略与 ViT 相结合,性能与最先进的卷积神经网络(CNN)可以抗衡。
论文名称:Training data-efficient image transformers & distillation through attention
论文地址:https://arxiv.org/abs/2012.12877
代码地址:https://github.com/facebookresearch/deit
1. ViT
提到 DeiT ,就不提不提及 ViT 。这里对 ViT 进行简要介绍来帮助大家初步了解 ViT。
ViT 模型将 Transformer 模型应用在了 CV 领域,并取得了突出的成果。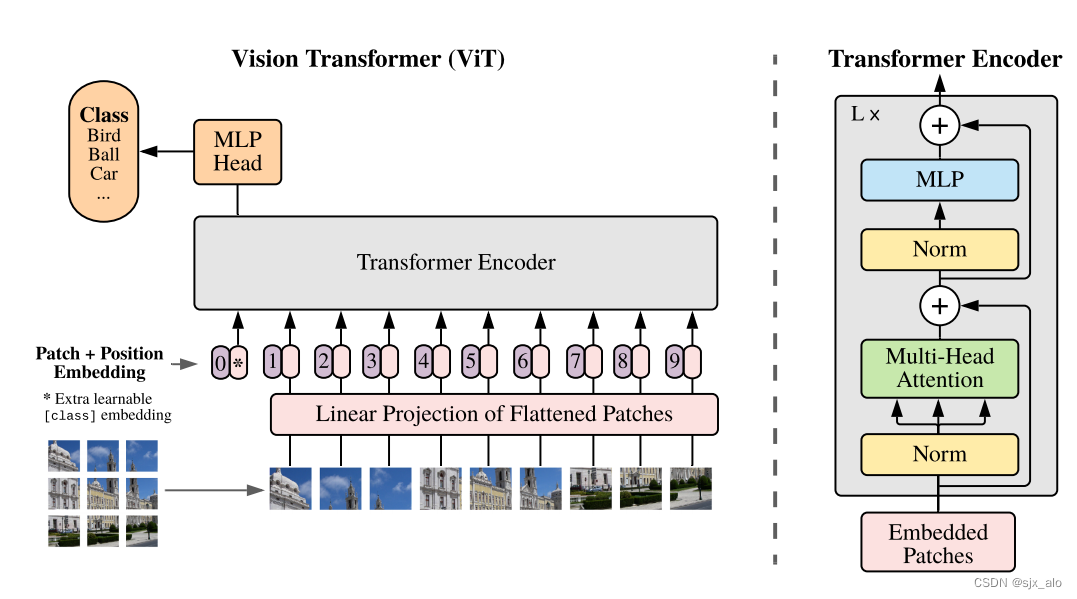
在标准的 Transformer 中,模型仅能处理 1D 数据。为了处理 2D 图像,作者首先将图片数据
X
∈
R
H
×
W
×
C
X\in R^{H\times W \times C}
X∈RH×W×C 按照 patch_size 进行切分并进行一维展平,得到数据
X
∈
R
N
×
(
P
2
×
C
)
X\in R^{N\times (P^2\times C)}
X∈RN×(P2×C) 。其中,
P
P
P 表示 patch_size;
N
N
N 表示图片被切分为多少块,即
N
=
H
×
W
P
2
N=\frac{H\times W}{P^2}
N=P2H×W 。然后,这批数据经过线性变换后与原始图像的位置编码进行合并(并在首部添加类别编码 class embedding)。随后,合并后的数据输入到Transformer Encoder模块。最后经过MLP模型得到输出的类别(MLP模型包含两个具有GELU非线性的层)。总结为公式:
z
0
=
[
x
c
l
a
s
s
;
x
p
1
E
;
x
p
2
E
;
⋅
⋅
⋅
;
x
p
N
E
]
+
E
p
o
s
;
E
∈
R
(
P
2
⋅
C
)
×
D
;
E
p
o
s
∈
R
(
N
+
1
)
×
D
(
1
)
z
ℓ
′
=
M
S
A
(
L
N
(
z
ℓ
−
1
)
)
+
z
ℓ
−
1
;
ℓ
=
1...
L
(
2
)
z
ℓ
=
M
L
P
(
L
N
(
z
ℓ
′
)
)
+
z
ℓ
′
;
ℓ
=
1...
L
(
3
)
y
=
L
N
(
z
L
0
)
(
4
)
z_0 = [x_{class}; x^1_pE; x^2_pE; · · · ; x^N_pE] + E_{pos}; \ \ \ \ \ \ \ \ E\in R^{(P^2·C)×D}; E_pos \in R^{(N+1)×D} (1) \\\ z^′_ℓ = MSA(LN(z_{ℓ−1})) + z_{ℓ−1}; \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ ℓ= 1 ... L (2) \ \ \ \ \ \ \\\ z_ℓ = MLP(LN(z^′_ℓ )) + z^′_ℓ ; \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ ℓ= 1 ... L (3) \\\ \ \ \ \ \ \ \ \ \ \ y = LN(z^0_L) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (4)
z0=[xclass;xp1E;xp2E;⋅⋅⋅;xpNE]+Epos; E∈R(P2⋅C)×D;Epos∈R(N+1)×D(1) zℓ′=MSA(LN(zℓ−1))+zℓ−1; ℓ=1...L(2) zℓ=MLP(LN(zℓ′))+zℓ′; ℓ=1...L(3) y=LN(zL0) (4)
其中,
x
c
l
a
s
s
x_{class}
xclass 就是上文说的class embedding,即
x
c
l
a
s
s
=
z
0
0
x_{class}=z^0_0
xclass=z00 ,其在Transformer编码器输出
(
z
L
0
)
(z^0_L)
(zL0) 的状态作为图像表示
y
y
y;
D
D
D 表示线性映射维度;
L
L
L 表示Transformer输出维度。
注意:这里class embedding的作用是什么呢?
根本原因:Transformer输入为一系列的patch embedding,输出也是同样长的序列patch feature,但是最后要总结为一个类别的判断。而class embedding作为一个Transformer的判断,在训练过程中不断汇总被分割图片的特性,进而得到一个最终分类结果。
具体而言:训练的时候,class token的embedding被随机初始化并与pos embedding相加。在训练过程中,随着网络的训练不断更新,它能够编码整个数据集的统计特性;同时,该token对所有其他token上的信息做汇聚(全局特征聚合),并且由于它本身不基于图像内容,因此可以避免对sequence中某个特定token的偏向性;最后,对该token使用固定的位置编码能够避免输出受到位置编码的干扰。
2. DeiT
为了方便理解 DeiT 模型,首先介绍一下知识蒸馏的概念。
2.1 知识蒸馏
知识蒸馏整体性而言就是当模型训练完成后,可以将教师网络学习到的信息压缩到学生网络中,从而达到降低模型规模的目的。
2.1.1 提出背景
虽然在一般情况下,我们不会去区分训练和部署使用的模型,但是训练和部署之间存在着一定的不一致性。在训练过程中,我们需要使用复杂的模型,大量的计算资源,以便从非常大、高度冗余的数据集中提取出信息。在实验中,效果最好的模型往往规模很大,甚至由多个模型集成得到。而大模型不方便部署到服务中去,常见的瓶颈如下:
- 推理速度和性能慢
- 对部署资源要求高(内存,显存等)
在部署时,对延迟以及计算资源都有着严格的限制。因此,模型压缩(在保证性能的前提下减少模型的参数量)成为了一个重要的问题,而“模型蒸馏”属于模型压缩的一种方法。
2.1.2 理论原理
知识蒸馏使用的是 Teacher—Student 模型,其中 Teacher 是“知识”的输出者,Student 是“知识”的接受者。知识蒸馏的过程分为2个阶段:
- 原始模型训练:训练 “
Teacher模型”,简称为Net-T,它的特点是模型相对复杂,也可以由多个分别训练的模型集成而成。我们对"Teacher模型"不作任何关于模型架构、参数量、是否集成方面的限制,唯一的要求就是,对于输入 X X X, 其都能输出 Y Y Y,其中 Y Y Y经过softmax的映射,输出值对应相应类别的概率值。 - 精简模型训练: 训练"
Student模型",简称为Net-S,它是参数量较小、模型结构相对简单的单模型。同样的,对于输入 X X X,其都能输出 Y Y Y, Y Y Y 经过softmax映射后同样能输出对应相应类别的概率值。
2.2 DeiT模型
在 DeiT 模型中,首先需要一个强力的图像分类模型作为teacher model。然后,引入了一个 Distillation Token,然后在 self-attention layers 中跟 class token,patch token 在 Transformer 结构中不断学习。Class token的目标是跟真实的label一致,而Distillation Token是要跟teacher model预测的label一致。蒸馏过程如下图所示。

在蒸馏过程中,不同的蒸馏方案会得到不同的结果。DeiT 模型主要的蒸馏方案包括以下两种:
- 软蒸馏(Soft distillation):使
教师模型的softmax和学生模型的softmax之间的Kullback-Leibler分歧最小化
L g l o b a l = ( 1 − λ ) L C E ( ψ ( Z s ) , y ) + λ τ 2 K L ( ψ ( Z s / τ ) , ψ ( Z t / τ ) ) L_{global} =(1−λ)L_{CE} (ψ(Z_s ),y)+λτ^2 KL(ψ(Z_s /τ),ψ(Z_t /τ)) Lglobal=(1−λ)LCE(ψ(Zs),y)+λτ2KL(ψ(Zs/τ),ψ(Zt/τ))其中, Z s Z_s Zs 和 Z t Z_t Zt 分别是student model和teacher model的对数, τ τ τ 表示蒸馏温度, λ λ λ 表示 K L KL KL(Kullback-Leibler散度损失)损失和交叉熵( L C E L_{CE} LCE )的系数 , y y y 表示真实值标签, ψ ψ ψ 表示Softmax函数。 - 硬蒸馏(Hard-label distillation):
L g l o b a l h a r d D i s t i l l = 1 2 L C E ( ψ ( Z s ) , y ) + 1 2 L C E ( ψ ( Z s ) , y t ) L_{global}^{hardDistill} = \frac{1}{2} L_{CE}(ψ(Z_s),y)+\frac{1}{2}L_{CE}(ψ(Z_s),y_t) LglobalhardDistill=21LCE(ψ(Zs),y)+21LCE(ψ(Zs),yt)值得注意的是,Hard Label也可以通过标签平滑技术(Label smoothing)转换成Soft Label,其中真值对应的标签被认为具有1- esilon的概率,剩余的esilon由剩余的类别共享。
3. 总结
DeiT 模型(8600万参数)仅用一台 GPU 服务器在 53 hours train,20 hours finetune,仅使用 ImageNet 就达到了 84.2 top-1 准确性,而无需使用任何外部数据进行训练,性能与最先进的卷积神经网络(CNN)可以抗衡。其核心是提出了针对 ViT 的教师-学生蒸馏训练策略,并提出了 token-based distillation 方法,使得 Transformer 在视觉领域训练得又快又好。
如果有什么疑问欢迎在评论区提出,对于共性问题可能会后续添加到文章介绍中。