第1章 Hive基本概念
1.1 Hive
1.1.1 Hive的产生背景
在那一年的大数据开源社区,我们有了HDFS来存储海量数据、MapReduce来对海量数据进行分布式并行计算、Yarn来实现资源管理和作业调度。但是面对海量数据和负责的业务逻辑,开发人员要编写MR来对数据进行统计分析难度极大、效率较低,并且对开发者的Java功底也有要求。所以Facebook公司在处理自己的海量数据时开发了hive这个数仓工具。Hive可以帮助开发人员来做完成这些苦活,如此开发人员就可以更加专注于业务需求了。
1.1.2 hive简介
Hive:由Facebook开源用于解决海量结构化日志的数据统计工具。
Hive是基于Hadoop的一个数据仓库工具,将结构化的数据文件映射为一张表,并提供类SQL(HQL)查询功能。
1.1.3 Hive本质:将HQL转化成MapReduce程序
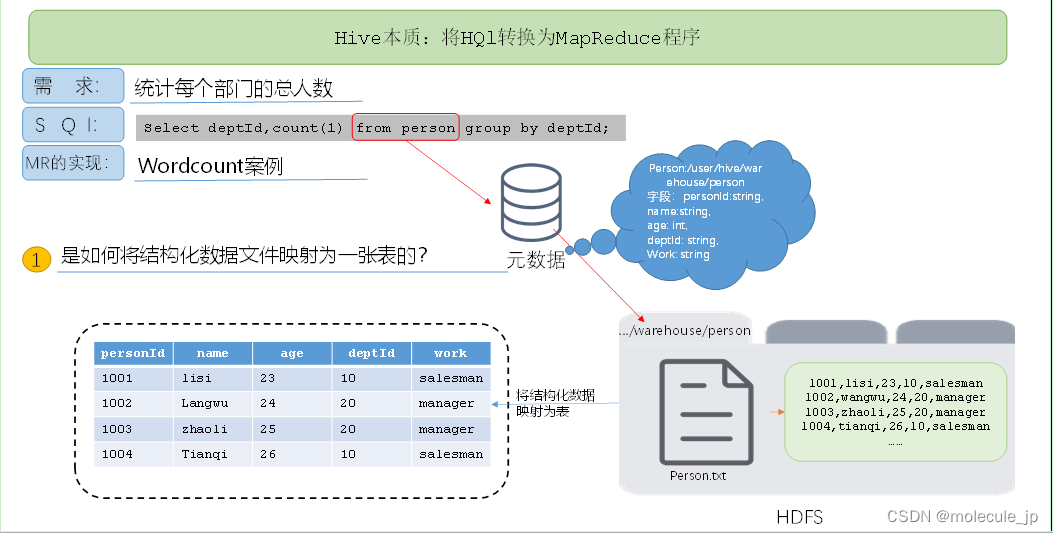
(1)Hive处理的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce
(3)执行程序运行在Yarn上
(4)结构化文件如何映射成一张表的?借助存储在元数据数据库中的元数据来解析结构化文件
1.2 Hive架构原理
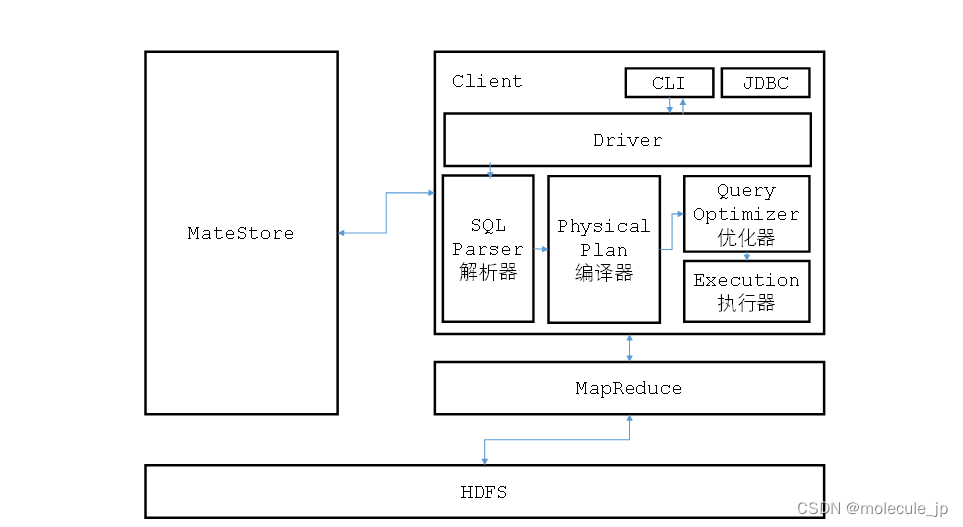
1.2.1 Hive架构介绍
1)用户接口:Client CLI(command-line interface)、
JDBC/ODBC(jdbc访问hive)、
2)元数据:Metastore 元数据包括:
表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3)Hadoop 使用HDFS进行存储,使用MapReduce进行计算。
4)驱动器:Driver ·解析器(SQL Parser): 将SQL字符串转换成抽象语法树AST,
这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
·编译器(Physical Plan): 将AST编译生成逻辑执行计划。
·优化器(Query Optimizer): 对逻辑执行计划进行优化。
·执行器(Execution): 把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
1.2.2 Hive的运行机制
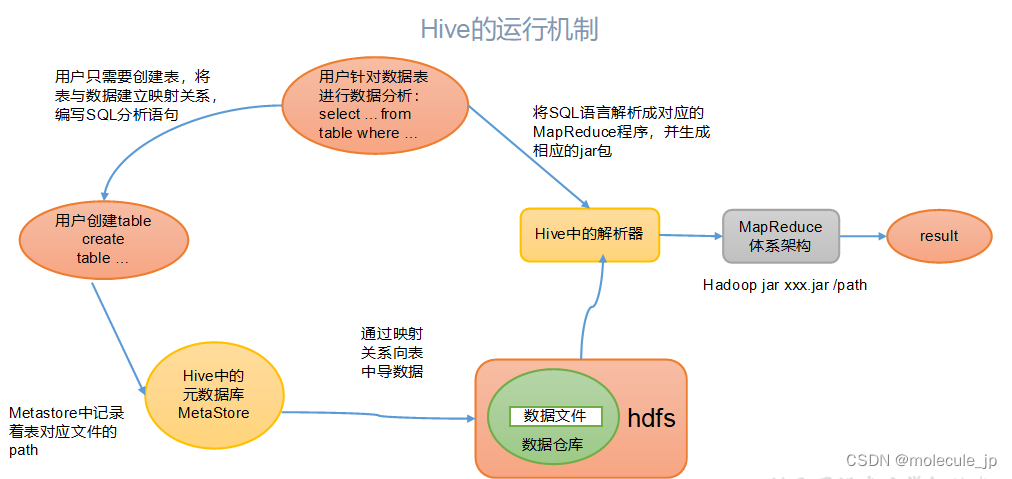
hive通过给用户提供的一系列交互接口,接收到的用户的指令(SQl),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提m交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口中。
1.3 Hive和 数据库比较

综上所述,Hive压根就不是数据库,hive除了语言类似意外,存储和计算都是使用Hadoop来完成的。而Mysql则是使用自己的,拥有自己的体系。
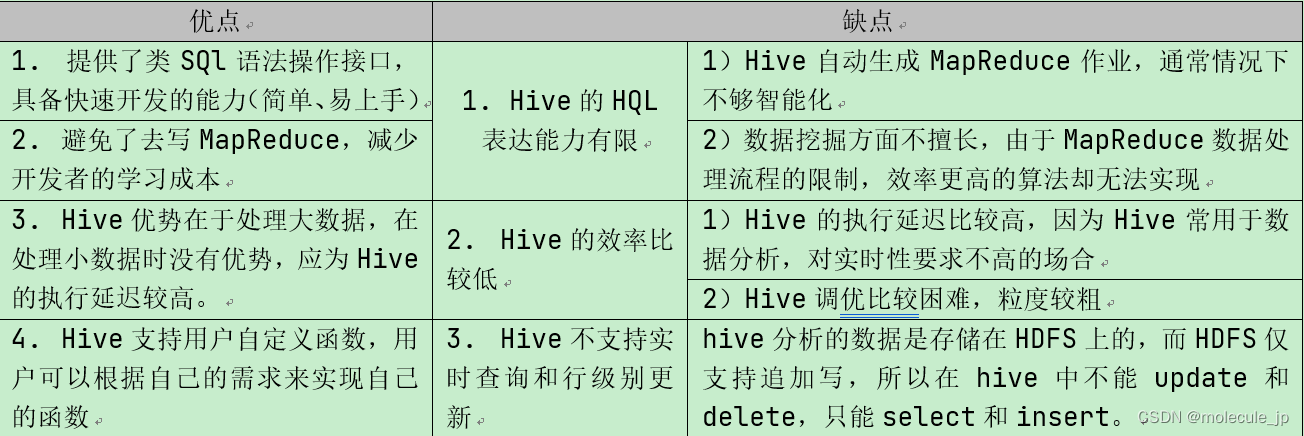
1.4 Hive的优缺点
第2章 Hive安装
2.1 修改hadoop相关参数
1)修改core-site.xml
[aa@hadoop102 hive]$ vim /opt/module/hadoop/etc/hadoop/core-site.xml
<!-- 配置该aa(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!-- 配置该aa(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!-- 配置该aa(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.atguigu.users</name>
<value>*</value>
</property>
2)配置yarn-site.xml
[aa@hadoop102 hive]$ vim /opt/module/hadoop/etc/hadoop/yarn-site.xml
<!-- NodeManager使用内存数,默认8G,修改为4G内存 -->
<property>
<description>Amount of physical memory, in MB, that can be allocated
for containers. If set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true, it is
automatically calculated(in case of Windows and Linux).
In other cases, the default is 8192MB.
</description>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 容器最小内存,默认512M -->
<property>
<description>The minimum allocation for every container request at the RM in MBs.
Memory requests lower than this will be set to the value of this property.
Additionally, a node manager that is configured to have less memory than this value
</description>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 容器最大内存,默认8G,修改为4G -->
<property>
<description>The maximum allocation for every container request at the RM in MBs.
Memory requests higher than this will throw an InvalidResourceRequestException.
</description>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- 虚拟内存检查,默认打开,修改为关闭 -->
<property>
<description>Whether virtual memory limits will be enforced for containers.</description>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
· 注意:修改完配置文件记得分发,然后重启集群。
xynsc /opt/module/hadoop/etc/hadoop/
2.2 Hive解压安装
1)把apache-hive-3.1.2-bin.tar.gz上传到linux的/opt/software目录下
2)将/opt/software/目录下的apache-hive-3.1.2-bin.tar.gz到/opt/module/目录下面
[aa@hadoop102 software]$ tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
3)修改解压后的目录名称为hive
[aa@hadoop102 module]$ mv apache-hive-3.1.2-bin/ /opt/module/hive
4)修改/etc/profile.d/my_env.sh文件,将hive的/bin目录添加到环境变量
[aa@hadoop102 hive]$ sudo vim /etc/profile.d/my_env.sh
……
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=
P
A
T
H
:
PATH:
PATH:HIVE_HOME/bin
[aa@hadoop102 hive]$ source /etc/profile
2.3 Hive元数据的两种选择
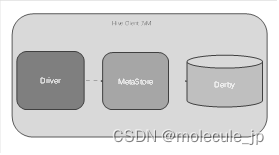
2.3.1 元数据库之Derby
1.derby元数据示意图:
2.Derby数据库:
Derby数据库是Java编写的内存数据库,在内嵌模式中与应用程序共享一个JVM,应用程序负责启动和停止。
3. 初始化Derby数据库
1)在hive根目录下,使用/bin目录中的schematool命令初始化hive自带的Derby元数据库
[aa@hadoop102 hive]$ bin/schematool -dbType derby -initSchema
2)执行上述初始化元数据库时,会发现存在jar包冲突问题,现象如下:
SLF4J: Found binding in [jar:file:/opt/module/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
3)解决jar冲突问题,只需要将hive的/lib目录下的log4j-slf4j-impl-2.10.0.jar重命名即可
[aa@hadoop102 hive]$ mv lib/log4j-slf4j-impl-2.10.0.jar lib/log4j-slf4j-impl-2.10.0.back
4.启动Hive
1)执行/bin目录下的hive命令,就可以启动hive,并通过cli方式连接到hive
[aa@hadoop102 hive]$ bin/hive
2)使用Hive
hive> show databases; // 查看当前所有的数据库
OK
default
Time taken: 0.472 seconds, Fetched: 1 row(s)
hive> show tables; // 查看当前所有的表
OK
Time taken: 0.044 seconds
hive> create table test_derby(id int); // 创建表test_derby,表中只有一个字段,字段类型是int
OK
Time taken: 0.474 seconds
hive> insert into test_derby values(1001); // 向test_derby表中插入数据
Query ID = atguigu_20211018153727_586935da-100d-4d7e-8a94-063d373cc5dd
Total jobs = 3
……
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
……
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 6.19 sec HDFS Read: 12769 HDFS Write: 208 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 190 msec
OK
Time taken: 31.901 second
hive> select * from test_derby; // 查看test_derby表中所有数据
OK
1001
Time taken: 0.085 seconds, Fetched: 1 row(s)
hive> exit;
- 内嵌模式只有一个JVM进程
在内嵌模式下,命令行执行jps –ml命令,只能看到一个CliDriver进程。
[aa@hadoop102 hive]$ jps –ml
7170 sun.tools.jps.Jps -ml
6127 org.apache.hadoop.util.RunJar /opt/module/hive/lib/hive-cli-3.1.2.jar org.apache.hadoop.hive.cli.CliDriver
6.Hive自带的元数据库的问题
演示采用Derby作为元数据库的问题:
开启另一个会话窗口运行Hive,同时监控/tmp/aa目录中的hive.log文件,会观察到如下错误信息。
Caused by: ERROR XSDB6:
> Another instance of Derby may have already booted the database
> /opt/module/hive/metastore_db.
at org.apache.derby.iapi.error.StandardException.newException(Unknown Source)
at org.apache.derby.iapi.error.StandardException.newException(Unknown Source)
at org.apache.derby.impl.store.raw.data.BaseDataFileFactory.privGetJBMSLockOnDB(Unknown Source)
at org.apache.derby.impl.store.raw.data.BaseDataFileFactory.run(Unknown Source)
...
Hive默认使用的元数据库为derby并且部署方式是内嵌式,在开启Hive之后就会独占元数据库,且不与其他客户端共享数据,如果想多窗口操作就会报错,操作比较局限。为此Hive支持采用MySQL作为元数据库,就可以支持多窗口操作。
监控hive.log日志,tail -F hive.log在/temp/atguigu/hive.log
同时打开两个窗口运行hive会报错!