- tebsorRT是什么
tensorRT是NVIDIA出的一个高性能深度学习推理(inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
- 为什么能加速模型运行速度
TensorRT是英伟达针对自家平台做的加速包,TensorRT主要做了这么两件事情,来提升模型的运行速度。一个是支持INT8和FP16的计算。深度学习网络在训练时,通常使用 32 位或 16 位数据。TensorRT则在网络的推理时选用不这么高的精度,达到加速推断的目的。
第二个是TensorRT对于网络结构进行了重构,把一些能够合并的运算合并在了一起,针对GPU的特性做了优化。现在大多数深度学习框架是没有针对GPU做过性能优化的,而英伟达,GPU的生产者和搬运工,比如一些层在水平方向与深度方向都会做一定的合并,从而加速。
TensorRT具体加速效果决定于显卡和模型,例如在3080ti上resnet50从pytorch转TensorRT可以加速10倍,但是yolov5只能加速一倍多。
另外,TensorRT能做int8和fp16推理要看gpu是否支持,例如新3080ti支持int8和fp16推理,老tesla t4卡就只能做int8推理,更老的卡都不支持了。
TensorRT对网络推理的优化其实远不止CBR(conv、BN、Relu)合并这么简单,还会做Gemm、Winograd、cudnn kernel选择等一系列优化操作,然后遍历选取运行时间最短的cudnn api(打开日志verbose就能看到)。
- 实践中遇到的坑
根据onnx模型生成trt的过程,如果遇到不支持的算子,有的时候报错反卷积和卷积操作不支持,就比较离谱了,这个时候通常是环境问题,以及onnx导出时的torch版本,我用8.4.2.4的tensorRT版本,torch1.9,op12导出onnx模型,可以将模型序列化为trt,但在反序列化推理的时候会报错Error Code 3: API 使用错误:
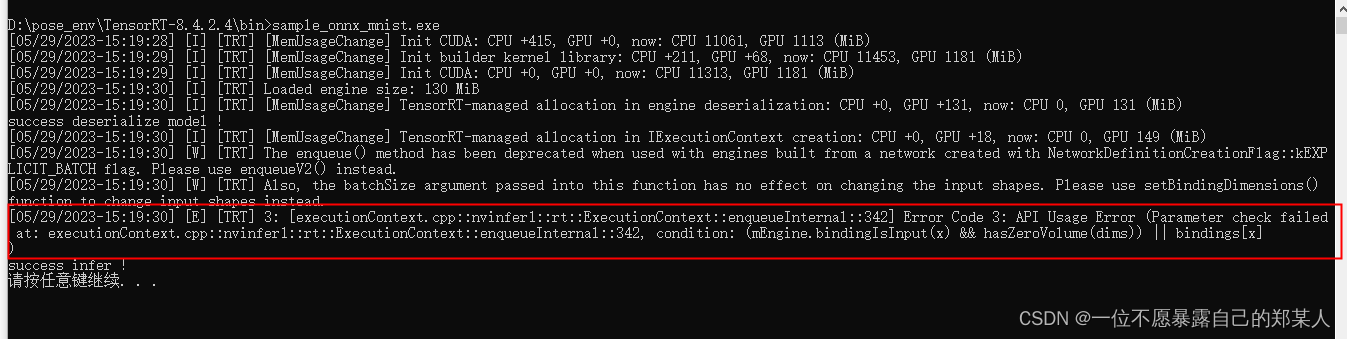
解决方法:
用低版本1.5的torch及op为9的版本,导出onnx模型,推理报错问题解决。
另外,tensorRT是不支持ATen操作的,模型网络结构只是一些矩阵的切片索引乘法,用低版本导出时就会包含ATen这个操作,奇怪,不知道为啥会有这个操作,见如下结构:
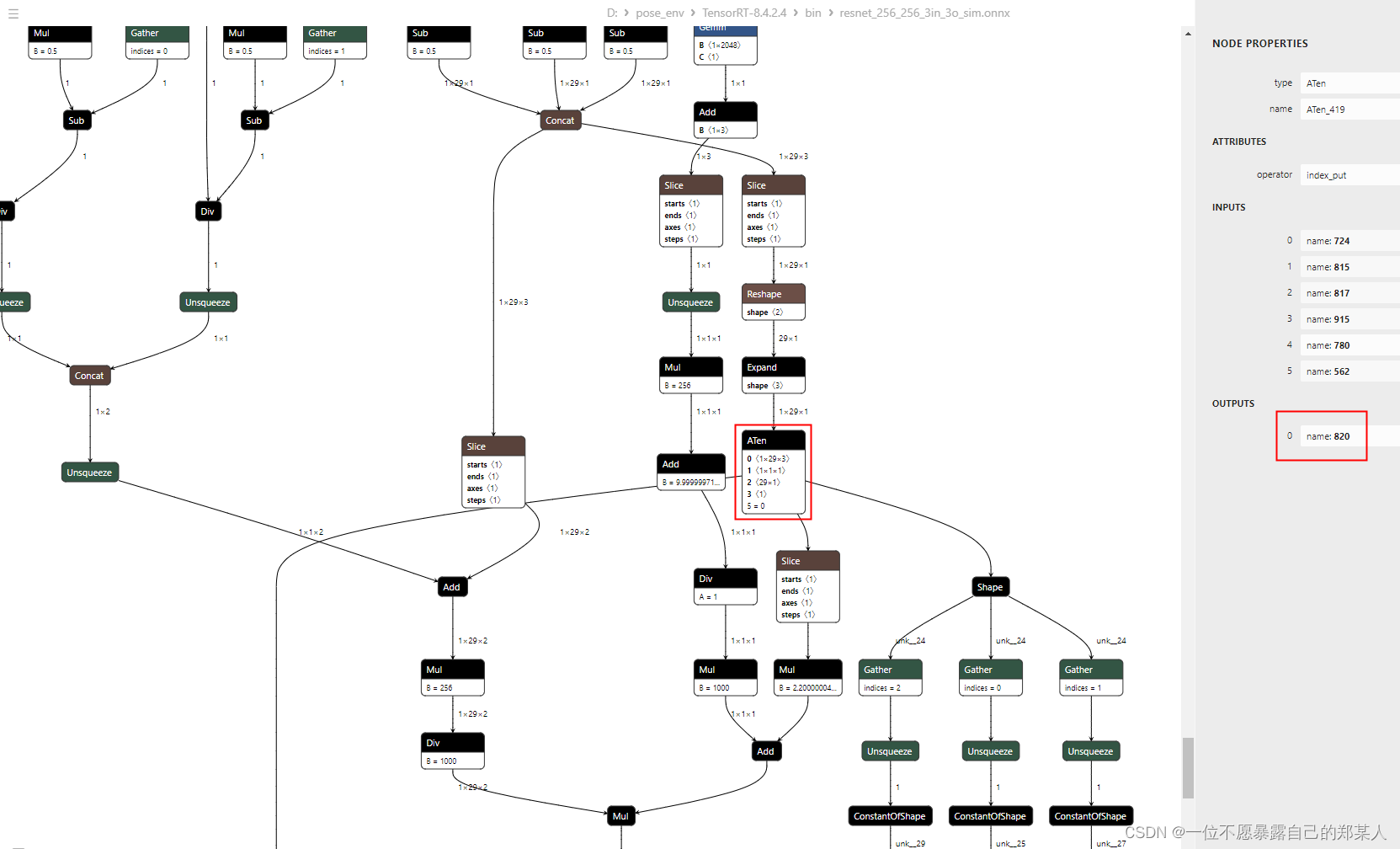
onnx包含ATen算子,tensorRT就会报错如下,然后运行卡住,异常退出:
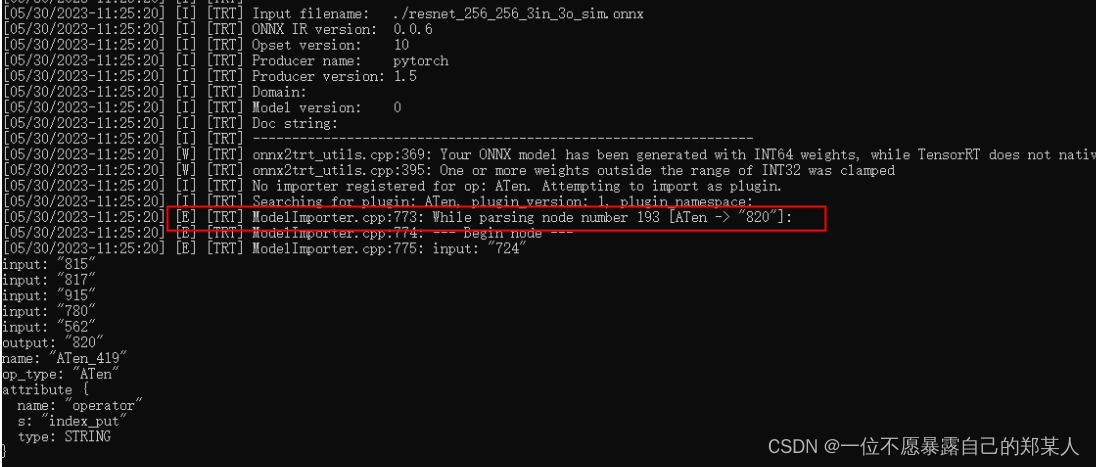
最后将产生ATen这个操作的放在后处理,onnx去掉这部分,导出后,即可成功运行。
注意:代码中声明的变量buffers, buffers的个数是输入加输出的总数,我的模型为1个输入,4个输出,所以声明如下:
void* buffers[5];
另外,模型推理时,如果没做预处理,送进推理的数据类型是U8C3时,推理也会异常退出,不会告诉你是哪里的问题,需要自己一步一步debug, 看各个步骤结果是否符合预期。