文章目录
- 基于环形队列的生产消费模型
- 生产者和消费者的关注点
- 申请和释放资源的问题
- 规则
- RingQueue.hpp
- 单生产者单消费者的生产者消费者模型:
- 信号量保护环形队列的原理
- 多生产者多消费者模型+计算任务处理
- RingQueue.hpp
- Task.hpp
- RingQueue.cc
基于环形队列的生产消费模型
环形队列采用数组模拟,用模运算来模拟环状特性, 但是环形结构起始状态和结束状态都是一样的,不好判断为空或者为满, 解决办法:预留一个空的位置
生产者和消费者的关注点
对于生产者和消费者来说,它们关注的资源是不同的
生产者关注的是空间资源,消费者关注的是数据资源
- 生产者关注的是环形队列当中是否有空间(blank),只要有空间生产者就可以进行生产
- 消费者关注的是环形队列当中是否有数据(data),只要有数据消费者就可以进行消费
关于信号量
blank_sem和data_sem的初始值设置
现在我们用信号量来描述环形队列当中的空间资源(blank_sem)和数据资源(data_sem),在我们初始信号量时给它们设置的初始值是不同的:
- blank_sem的初始值我们应该设置为环形队列的容量,因为刚开始时环形队列当中全是空间
- data_sem的初始值我们应该设置为0,因为刚开始时环形队列当中没有数据
申请和释放资源的问题
**对于生产者而言:**生产者申请空间资源,释放数据资源
-
对于生产者来说,生产者每次生产数据前都需要先申请对于的信号量blank_sem
- 如果blank_sem的值不为0,则信号量申请成功,此时生产者可以进行生产操作
- 如果blank_sem的值为0,则信号量申请失败,此时生产者需要在blank_sem的等待队列下进行阻塞等待,直到环形队列当中有新的空间后再被唤醒
-
当生产者生产完数据后,应该释放对于的空间资源->data_sem:
- 虽然生产者在进行生产前是对blank_sem进行的P操作,但是当生产者生产完数据,应该对data_sem进行V操作而不是blank_sem
- 生产者在生产数据前申请到的是
blank位置,当生产者生产完数据后,该位置当中存储的是生产者生产的数据,在该数据被消费者消费之前,该位置不再是blank位置,而应该是data位置 - 所以当生产者生产完数据后,意味着环形队列当中多了一个
data位置,因此我们应该对data_sem进行V操作
**对于消费者而言:**消费者申请数据资源,释放空间资源
对于消费者来说,消费者每次消费数据前都需要先申请data_sem:
- 如果data_sem的值不为0,则信号量申请成功,此时消费者可以进行消费操作
- 如果data_sem的值为0,则信号量申请失败,此时消费者需要在data_sem的等待队列下进行阻塞等待,直到环形队列当中有新的数据后再被唤醒
当消费者消费完数据后,应该释放blank_sem:
- 虽然消费者在进行消费前是对data_sem进行的P操作,但是当消费者消费完数据,应该对blank_sem进行V操作而不是data_sem
- 消费者在消费数据前申请到的是
data位置,当消费者消费完数据后,该位置当中的数据已经被消费过了,再次被消费就没有意义了,为了让生产者后续可以在该位置生产新的数据,我们应该将该位置算作blank位置,而不是data位置 - 当消费者消费完数据后,意味着环形队列当中多了一个
blank位置,因此我们应该对blank_sem进行V操作
规则
生产者和消费者必须遵守如下两个规则 规则1)生产者和消费者不能对同一个位置进行访问
生产者和消费者在访问环形队列时:
- 如果生产者和消费者访问的是环形队列当中的同一个位置,那么此时生产者和消费者就相当于同时对这一块临界资源进行了访问,这当然是不允许的
- 如果生产者和消费者访问的是环形队列当中的不同位置,那么此时生产者和消费者是可以同时进行生产和消费的,此时不会出现数据不一致等问题
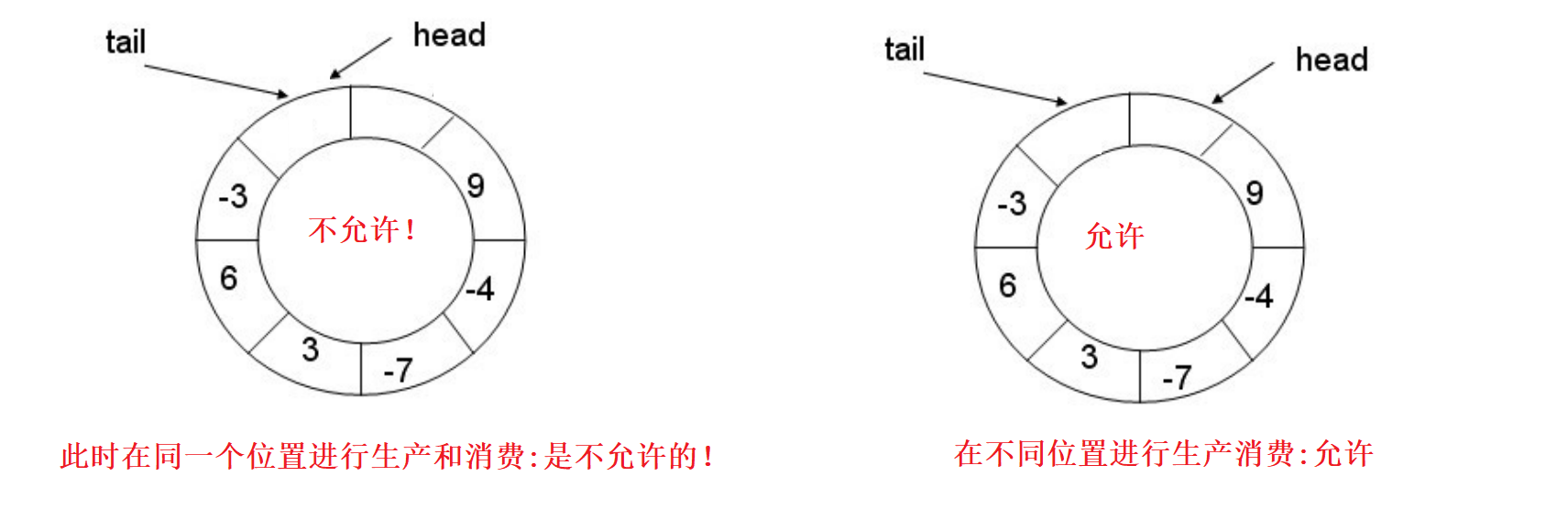
规则2)无论是生产者还是消费者,都不应该将对方套一个圈以上
- 生产者从消费者的位置开始一直按顺时针方向进行生产,如果生产者生产的速度比消费者消费的速度快,那么当生产者绕着消费者生产了一圈数据后再次遇到消费者,此时生产者就不应该再继续生产了,因为再生产就会覆盖还未被消费者消费的数据
- 同理,消费者从生产者的位置开始一直按顺时针方向进行消费,如果消费者消费的速度比生产者生产的速度快,那么当消费者绕着生产者消费了一圈数据后再次遇到生产者,此时消费者就不应该再继续消费了,因为再消费就会消费到缓冲区中保存的废弃数据
RingQueue.hpp
我们用数组实现环形队列RingQueue,其中这个环形队列就是生产者消费者模型当中的交易场所
注意事项:
- 当不设置环形队列的大小时,我们默认将环形队列的容量上限设置为10
- 代码中的RingQueue是用vector实现的,生产者每次生产的数据放到vector下标为p_pos的位置,消费者每次消费的数据来源于vector下标为c_pos的位置
- 生产者每次生产数据后p_pos都会进行++,标记下一次生产数据的存放位置,++后的下标会与环形队列的容量进行取模运算,实现“环形”的效果
- 消费者每次消费数据后c_pos都会进行++,标记下一次消费数据的来源位置,++后的下标会与环形队列的容量进行取模运算,实现“环形”的效果
- p_pos只会由生产者线程进行更新,c_pos只会由消费者线程进行更新,对这两个变量访问时不需要进行保护,因此代码中将p_pos和c_pos的更新放到了V操作之后,就是为了尽量减少临界区的代码
#pragma once
#include <iostream>
#include <vector>
#include <semaphore.h>
namespace Mango
{
const int cap_default = 10;
template<class T>
class RingQueue
{
public:
RingQueue(int cap = cap_default)
:_cap(cap),c_step(0),p_step(0)
{
_ringqueue.resize(cap);
//初始化信号量,第三个参数:信号量的初始值
sem_init(&blank_sem, 0, cap);//最初有cap个空格子资源,所以blank_sem初始值设置为环形队列的容量
sem_init(&data_sem, 0, 0);//最初没有数据,数据资源为0
}
~RingQueue()
{
sem_destroy(&blank_sem);
sem_destroy(&data_sem);
}
//向环形队列插入数据->生产者使用
void Push(const T& in)
{
//step1:申请信号量
sem_wait(&blank_sem);//生产者要申请空位置的资源,P操作(空位置)
//step2:在当前p_step位置生产(放数据)
_ringqueue[p_step] = in;
//step3:多了一个数据->数据资源增加(V操作(数据资源))
sem_post(&data_sem);
//step4:处理p_step的位置,防止越界
p_step++;
p_step %=_cap;
}
//从环形队列获取数据->消费者使用
void Pop(T* out)//输出型参数
{
//step1:申请信号量
sem_wait(&data_sem); //消费者要申请数据资源,P操作(数据资源)
//step2:取出在c_step位置的数据(拿数据)
*out = _ringqueue[c_step];
//step3:少了一个数据->空间资源增加(V操作(空间资源))
sem_post(&blank_sem);
//step4:处理c_step的位置,防止越界
c_step++;
c_step %= _cap;
}
private:
std::vector<T> _ringqueue;//数组模拟实现环形队列
int _cap;//记录容量
sem_t blank_sem;//描述空间资源->生产者关心空位置资源
sem_t data_sem;//描述数据资源->消费者关心数据资源
int c_step;//消费者当前所在的位置
int p_step;//生产者当前所在的位置
};
}
单生产者单消费者的生产者消费者模型:
主函数我们就只需要创建一个生产者线程和一个消费者线程,生产者线程不断生产数据放入环形队列,消费者线程不断从环形队列里取出数据进行消费
注意事项:
- 环形队列要让生产者线程向队列中Push数据,让消费者线程从队列中Pop数据,因此这个环形队列必须要让这两个线程同时看到,所以我们在创建生产者线程和消费者线程时,需要将环形队列作为线程执行例程的参数进行传入
- 代码中生产者生产数据就是将获取到的随机数Push到环形队列,而消费者就是从环形队列Pop数据,为了便于观察,我们可以将生产者生产的数据和消费者消费的数据进行打印输出
#include "RingQueue.hpp"
#include <pthread.h>
#include <time.h>
#include <unistd.h>
using namespace Mango;
void* consumer(void* args)
{
RingQueue<int>* rq = ( RingQueue<int>*)args;
while(1)
{
sleep(1);
int data = 0;
rq->Pop(&data);//输出型参数
std::cout << "消费数据是: " << data << std::endl;
}
}
void* producter(void* args)
{
RingQueue<int>* rq = ( RingQueue<int>*)args;
while(1)
{
sleep(1);
int data = rand()%20 +1;//1~20的数据
std::cout << "生产数据是: " << data << std::endl;
rq->Push(data);
}
}
int main()
{
//单生产单消费模型
srand((long long)time(0));
RingQueue<int>* rq = new RingQueue<int>();
pthread_t c,p;
//把环形队列以参数的形式传给两个线程,相当于两个线程有了进行通信的数据区域
pthread_create(&c, nullptr, consumer, (void*)rq);
pthread_create(&p, nullptr, producter, (void*)rq);
pthread_join(c, nullptr);
pthread_join(p, nullptr);
return 0;
}
生产者和消费者生产速度一致时: 此时生产者和消费者的执行步调是一致的
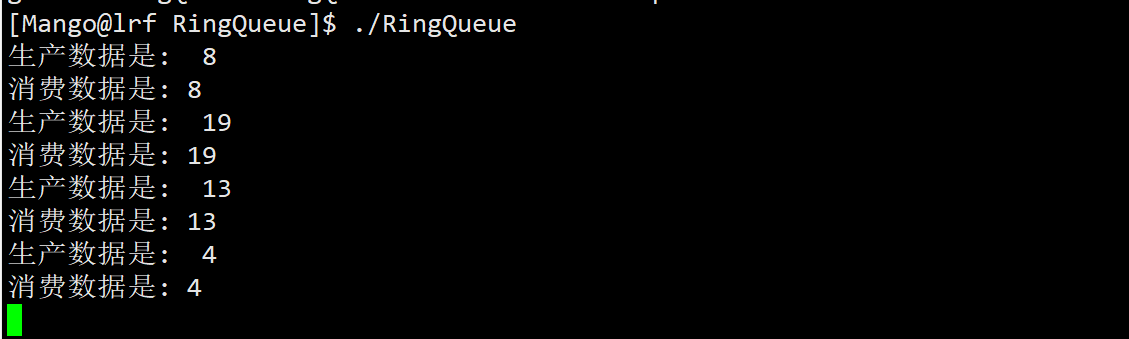
生产者生产的快,消费者消费的慢的情况: 让生产者不停的进行生产,而消费者每隔一秒进行消费,
此时可以看到:由于生产者生产的很快,运行代码后一瞬间生产者就将环形队列打满了,此时生产者想要再进行生产,但空间资源已经为0了,于是生产者只能在blank_sem的等待队列下进行阻塞等待,直到由消费者消费完一个数据后对blank_sem进行了V操作,生产者才会被唤醒进而继续进行生产
但由于生产者的生产速度很快,生产者生产完一个数据后又会进行等待,因此后续生产者和消费者的步调又变成一致的了
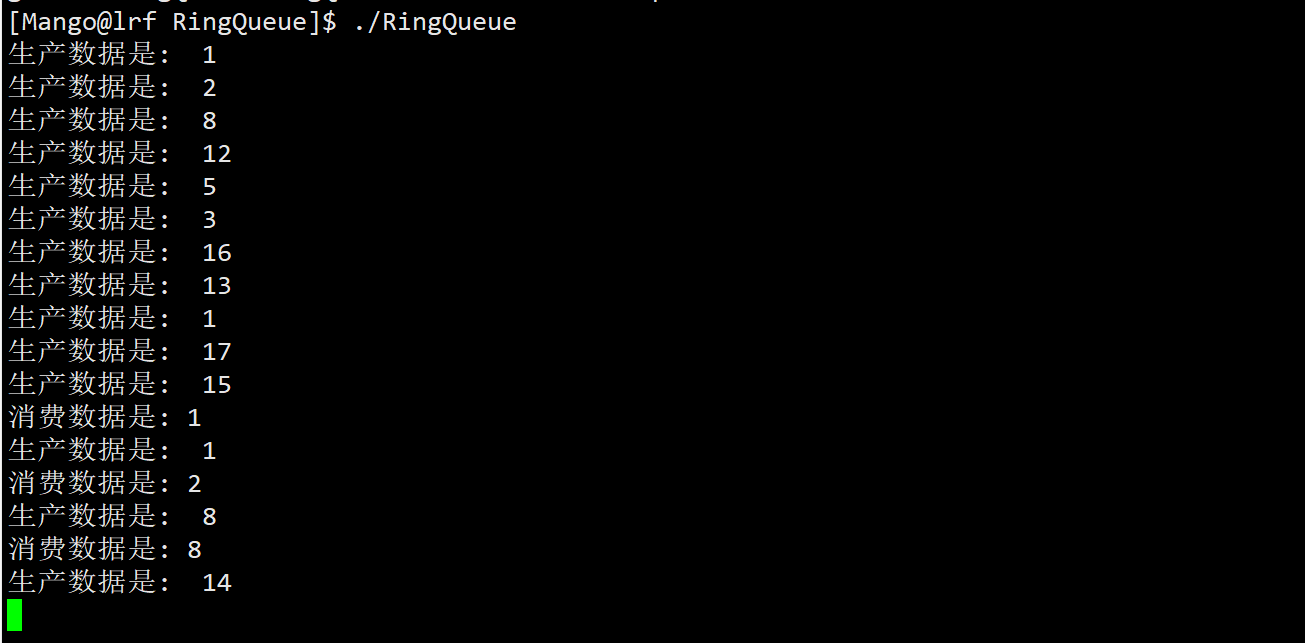
生产者生产的慢,消费者消费的快 : 让生产者每隔一秒进行生产,而消费者不停的进行消费
虽然消费者消费的很快,但一开始环形队列当中的数据资源为0,因此消费者只能在data_sem的等待队列下进行阻塞等待,直到生产者生产完一个数据后对data_sem进行了V操作,消费者才会被唤醒进而进行消费.
但由于消费者的消费速度很快,消费者消费完一个数据后又会进行等待,因此后续生产者和消费者的步调又变成一致的了
信号量保护环形队列的原理
在blank_sem和data_sem两个信号量的保护后,该环形队列中不可能会出现数据不一致的问题.
因为只有当生产者和消费者指向同一个位置并访问时,才会导致数据不一致的问题,而此时生产者和消费者在对环形队列进行写入或读取数据时,只有两种情况会指向同一个位置:
- 环形队列为空时
- 环形队列为满时
但是在这两种情况下,生产者和消费者不会同时对环形队列进行访问:
- 当环形队列为空的时,消费者一定不能进行消费,因为此时数据资源为0
- 当环形队列为满的时,生产者一定不能进行生产,因为此时空间资源为0
也就是说,当环形队列为空和满时,我们已经通过信号量保证了生产者和消费者的串行化过程
而除了这两种情况之外,生产者和消费者指向的都不是同一个位置,因此该环形队列当中不可能会出现数据不一致的问题
并且大部分情况下生产者和消费者指向并不是同一个位置,因此大部分情况下该环形队列可以让生产者和消费者并发的执行
多生产者多消费者模型+计算任务处理
RingQueue.hpp
由于现在是多执行流,所以c_step和p_step可能会被多个执行流访问,是临界资源,我们还要维护生产者和生产者的互斥,消费者和消费者的互斥.所以我们需要定义两把互斥锁分别进行保护!
要访问临界资源之前,先加锁
问:加锁应该在申请信号量之前还是在申请信号量之后?
信号量的P操作本身就是原子的,如果放在前面,那么就只有申请锁成功的人才能申请信号量,即使信号量设置的非常高,但实际上申请的时候还是要一个一个的申请, 不是我们想要的效果,放在前面和单生产者单消费者没有本质差别
所以推荐放在后面,放在后面有一个好处:可以保证进入生产区域+更新下标的时候是只有一个执行流进入的,此时有资格竞争锁的前提,必须得先申请信号量,如果有多个生产者,相当于就可以预先把信号量分配给多个对于的生产者 ,当锁一旦释放了,其它人立马申请锁,
即:在你申请锁成功访问临界资源的时候,别人就可以并行的把信号量先准备好
多生产和多消费的优势不在于拿数据和放数据,而在于并发的获取和处理任务
#pragma once
#include <iostream>
#include <vector>
#include<pthread.h>
#include <semaphore.h>
namespace Mango
{
const int cap_default = 10;
template<class T>
class RingQueue
{
public:
RingQueue(int cap = cap_default)
:_cap(cap),c_step(0),p_step(0)
{
_ringqueue.resize(cap);
//初始化信号量,第三个参数:信号量的初始值
sem_init(&blank_sem, 0, cap);//最初有cap个空格子资源
sem_init(&data_sem, 0, 0);//最初没有数据,数据资源为0
//初始化互斥锁
pthread_mutex_init(&c_mtx_, nullptr);
pthread_mutex_init(&p_mtx_, nullptr);
}
~RingQueue()
{
sem_destroy(&blank_sem);
sem_destroy(&data_sem);
//释放互斥锁
pthread_mutex_destroy(&c_mtx_);
pthread_mutex_destroy(&p_mtx_);
}
//插入数据->生产者使用
void Push(const T& in)
{
//step1:申请信号量
sem_wait(&blank_sem);//生产者要申请空位置的资源,P操作(空位置)
//访问临界资源前先加锁:
pthread_mutex_lock(&p_mtx_);
//step2:在当前p_step位置生产(放数据)
_ringqueue[p_step] = in;
//step3:多了一个数据->数据资源增加(V操作(数据资源))
sem_post(&data_sem);
//step4:处理p_step的位置,防止越界
p_step++;
p_step %=_cap;
pthread_mutex_unlock(&p_mtx_);//解锁
}
//弹出数据->消费者使用
void Pop(T* out)//输出型参数
{
//step1:申请信号量
sem_wait(&data_sem); //消费者要申请数据资源,P操作(数据资源)
//访问临界资源前先加锁:
pthread_mutex_lock(&c_mtx_);
//step2:取出在c_step位置的数据(拿数据)
*out = _ringqueue[c_step];
//step3:少了一个数据->空间资源增加(V操作(空间资源))
sem_post(&blank_sem);
//step4:处理c_step的位置,防止越界
c_step++;
c_step %= _cap;
pthread_mutex_unlock(&c_mtx_);
}
private:
std::vector<T> _ringqueue;//数组模拟实现环形队列
int _cap;//记录容量
sem_t blank_sem;//描述空间资源->生产者关心空位置资源
sem_t data_sem;//描述数据资源->消费者关心数据资源
int c_step;//消费者当前所在的位置
int p_step;//生产者当前所在的位置
//新增:两把锁,保护临界资源
pthread_mutex_t c_mtx_;
pthread_mutex_t p_mtx_;
};
}
上述代码,我们分开的使用两把锁,就维护了生产者和生产者的互斥关系,消费者和消费者的互斥关系,他们两套互斥互不影响,任意时刻最多只允许有一个生产者执行流进入生产,最多只允许有一个消费者执行流进入消费,每一个能进去的人,前提是申请信号量成功,他们进入临界资源的生产和消费的同步和互斥由信号量保证
实际使用生产者消费者模型时可不是简单的让生产者生产一个数字让消费者进行打印而已,我们这样做只是为了测试代码的正确性,由于我们将RingQueue当中存储的数据进行了模板化,此时就可以让RingQueue当中存储其他类型的数据
Task.hpp
例如:
实现一个基于计算任务的生产者消费者模型,此时我们只需要定义一个Task类,这个类当中需要包含一个Run成员函数,该函数代表着我们想让消费者如何处理拿到的数据
#pragma once
#include <iostream>
#include <pthread.h>
namespace Mango
{
class Task
{
private:
int x_;
int y_;
char op_; //+/*/%
public:
// void (*callback)();
Task() {}
Task(int x, int y, char op) : x_(x), y_(y), op_(op)
{
}
std::string Show()
{
std::string message = std::to_string(x_);
message += op_;
message += std::to_string(y_);
message += "=?";
return message;
}
int Run()
{
int res = 0;
switch (op_)
{
case '+':
res = x_ + y_;
break;
case '-':
res = x_ - y_;
break;
case '*':
res = x_ * y_;
break;
case '/':
res = x_ / y_;
break;
case '%':
res = x_ % y_;
break;
default:
std::cout << "bug??" << std::endl;
break;
}
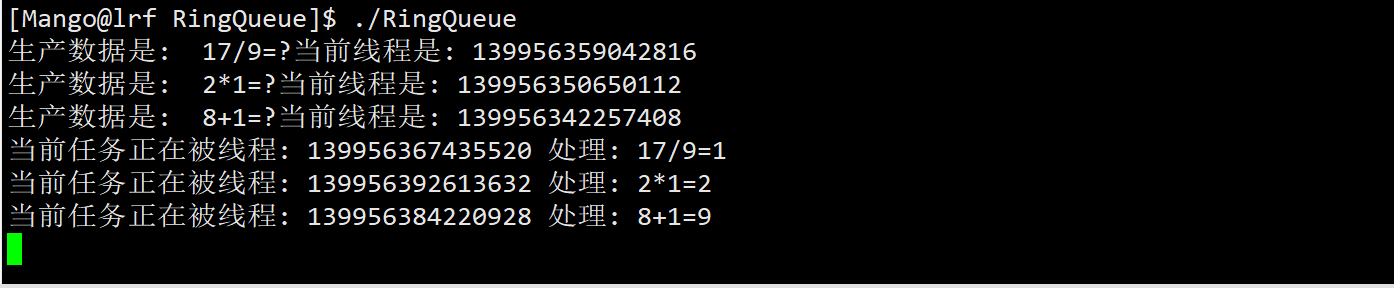
std::cout << "当前任务正在被线程: " << pthread_self() << " 处理: " \
<< x_ << op_ << y_ << "=" << res << std::endl;
return res;
}
int operator()() //仿函数
{
return Run();
}
~Task() {}
};
}
这里我们重载了operator , 定义一个对象Task t; t()本质相当于:t.operator() ->调用Run函数, 这种做法和t.Run()没有本质区别
此时生产者放入环形队列的数据就是一个Task对象,而消费者从环形队列拿到Task对象后,就可以用该对象调用Run成员函数进行数据处理
RingQueue.cc
我们让生产者慢一点,观察现象
#include "RingQueue.hpp"
#include"Task.hpp"
#include <pthread.h>
#include <time.h>
#include <unistd.h>
using namespace Mango;
void* consumer(void* args)
{
RingQueue<Task>* rq = (RingQueue<Task>*)args;
while(true)
{
Task t;
rq->Pop(&t);
t(); //相当于t.operator() ->t.Run()
sleep(1);
}
}
void* producter(void* args)
{
RingQueue<Task>* rq = (RingQueue<Task>*)args;
const std::string ops = "+-*/%";
while(true)
{
sleep(1);
int x = rand()%20 + 1;
int y = rand()%10 + 1;
char op = ops[rand()%ops.size()];
Task t(x, y, op);
std::cout << "生产数据是: " << t.Show() << "当前线程是: " << pthread_self()<< std::endl;
rq->Push(t);
}
}
int main()
{
//改成多生产者多消费者模型
srand((long long)time(nullptr));
RingQueue<Task>* rq = new RingQueue<Task>();
pthread_t c0,c1,c2,c3,p0,p1,p2;
pthread_create(&c0, nullptr, consumer, (void*)rq);
pthread_create(&c1, nullptr, consumer, (void*)rq);
pthread_create(&c2, nullptr, consumer, (void*)rq);
pthread_create(&c3, nullptr, consumer, (void*)rq);
pthread_create(&p0, nullptr, producter, (void*)rq);
pthread_create(&p1, nullptr, producter, (void*)rq);
pthread_create(&p2, nullptr, producter, (void*)rq);
pthread_join(c0, nullptr);
pthread_join(c1, nullptr);
pthread_join(c2, nullptr);
pthread_join(c3, nullptr);
pthread_join(p0, nullptr);
pthread_join(p1, nullptr);
pthread_join(p2, nullptr);
return 0;
}