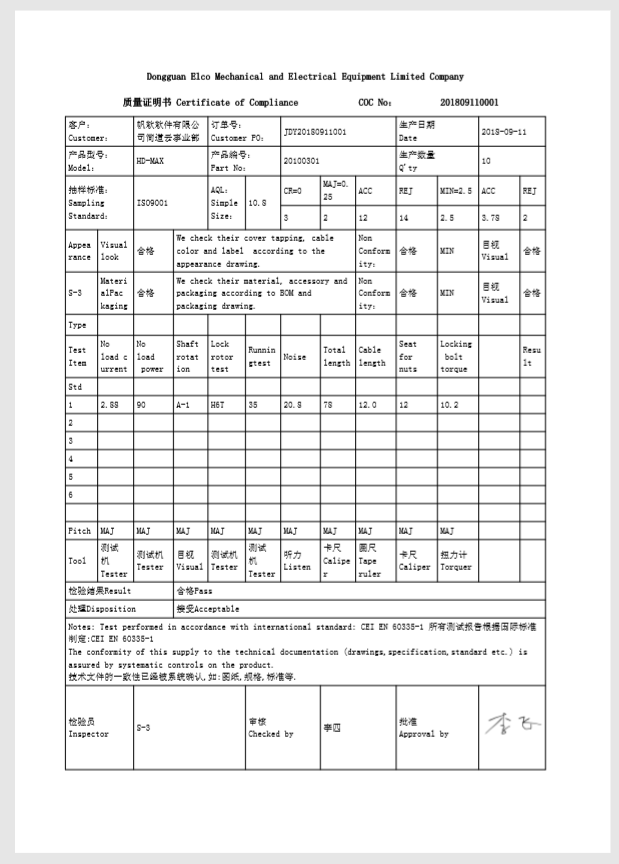
……
书接上文
4.车辆等级维度
探查车龄为5年的车辆,折旧价值与车辆等级的关系。
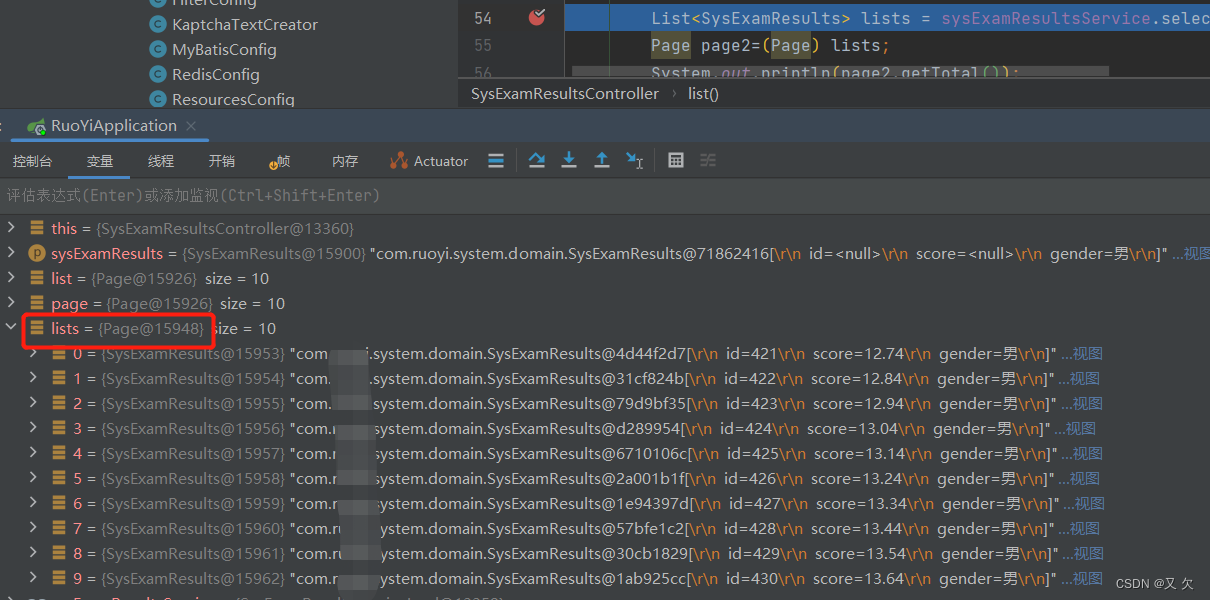
# 筛选出车龄为5的数据创建新表
data_age5 = data[data['age'] == 5]
data_age5
# 分组聚合计算均值
data_car_level = data_age5.groupby('car_level_name')['lowest_price'].mean().reset_index()
data_car_level这里用到了 DataFrame 的 groupby 函数,这个函数对于数据处理的重要程度无需赘言。
groupby 必须配合聚合函数同时使用,否则只能得到一个 DataFrameGroupBy 类型的玩意儿。
这里是可以只传 groupby 参数,不写聚合函数作用的字段的,也就是:
data_age5.groupby('car_level_name').mean()这样的效果和前面提到的 describe 函数相似,会对所有数值字段进行聚合计算。
这里还用到了 reset_index 函数,可以给生成的新表添加一列数字索引。
data_car_level_sort = data_car_level.sort_values('lowest_price',ascending = False)
data_car_level_sort创建新表,使用 sort_values 函数对数据进行排序。第一个参数必穿,是排序的数值列名,第二个参数是调整升序降序,默认升序,给参数 False 可以改为降序。
5.标签维度——可视化
根据标签,对比5年车龄车辆残值价格。
尝试使用另一种分组聚合方式——数据透视表:
data_picture = data_age5.pivot_table(index = 'maker_type', values = ['lowest_price'],aggfunc=np.mean)
bar_data_picture = data_picture.reset_index()
bar_data_picture使用 pivot_table 函数,含义与 group by 相同,索引 index 就是分组的列,值 values 就是需要聚合计算的数值列,聚合函数 aggfunc 使用 numpy 包中的聚合函数,这里依旧取平均值。
# 设置字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置编码,保证图表中中文和符号正常显示
plt.rcParams['axes.unicode_minus'] = False
# 定义x轴和y轴都是哪些数据
sns.barplot(x = bar_data_picture['maker_type'], y = bar_data_picture['lowest_price'], ci=68)
# 设置标题
plt.title('五年车龄二手车价格对比')
plt.show()使用 matplotlib.pyplot 包进行可视化属性参数配置。
更多配置详情请看:
http://t.csdn.cn/Kkx8I![]() http://t.csdn.cn/Kkx8I使用 seaborn 包传输图像必须的横纵坐标数据并展示。
http://t.csdn.cn/Kkx8I使用 seaborn 包传输图像必须的横纵坐标数据并展示。
注:查看matplotlib默认配置参数:print(plt.rcParams)
6.品牌维度——箱线图
data_brand = data_age5.groupby('brand')['lowest_price'].mean().reset_index()
data_brand_sort_desc = data_brand.nlargest(5, 'lowest_price')
data_brand_sort_desc同样分组聚合,查看各个品牌的车辆残值价格平均数,然后取价格最高的前五个品牌。
使用 nlargest 函数可以轻松获得,与之相对的还有取最小值的前n个元素的函数 nsmallest 。
data_brand_sort_desc_plot = data_age5[data_age5['brand'].isin(data_brand_sort_desc.brand)]
data_brand_sort_desc_plot反向取得价格平均数前五的品牌的车辆全部信息。
这里的 data_brand_sort_desc.brand 和 data_brand_sort_desc['brand'] 含义相同,也是提取表的一列。
isin 函数使用方式和SQL类似,利用布尔索引判断目标表的某一列值是否在条件列中。
上述过程相当于SQL的:
select
t1.*
from 总表 t1
where lowest_price in (
select
lowest_price
,brand
from (
select
avg(lowest_price) lowest_price
,brand
from 总表
group by brand
) t2
order by lowest_price desc
limit 5
) 对比SQL的复杂写法和嵌套逻辑,python代码看起来就简单多了(看起来)。
sns.boxplot(x='brand',y='lowest_price',data=data_brand_sort_desc_plot)然后进行可视化,使用 boxplot 函数生成箱线图,传入 x 轴 y 轴以及表名,可以观察到数据的中位数、上下四分位数、异常值分布。
关于箱线图怎么看,以及 boxplot 函数的详细使用,和参数修改,可以参考:http://t.csdn.cn/jNh8X![]() http://t.csdn.cn/jNh8X
http://t.csdn.cn/jNh8X
7.相关性分析——热力图
python有一个探查不同维度之间相关性的常用函数,corr:
correlation = data.corr()
correlation这是在对全体数据进行各维度相关性探查,corr 函数会将 DataFrame 表中所有数值类型的列进行相关性计算,计算结果在 -1 和 1 之间,结果越接近 1 表示两个维度值之间越正相关,越接近 -1 则说明两个维度值之间越呈负相关。
sns.heatmap(correlation, linewidth = 1.0, linecolor = 'white', square = True, annot = True, vmax=1.0)
# annot是否显示值
# vmax热力图取值颜色最大值
# square是否是正方形紧接着用 heatmat 函数生成多热力图查看数据相关度整体情况,通过调整配置参数值,可以轻松看到数据各个维度的相关性。
结论:
二手车价格与新车价格呈很强的正相关;
车龄与二手车残值率呈很强的负相关;
车龄与二手车净残值也呈负相关,但没有残值率体现的明显。
(完)

![深度学习进阶篇[8]:对抗神经网络GAN基本概念简介、纳什均衡、生成器判别器、解码编码器详解以及GAN应用场景](https://img-blog.csdnimg.cn/img_convert/c530a112c911329eaf8cb9cfeaab09fc.png)