文章目录
- 前言
- 一、自定义一个简单的mybatis分页插件?
- 1.判断当前传参是不是一个Page,如果是page就进行转换。
- 2.分页查询总条数
- 3.修改原有sql
- 4.执行原有方法
- 5.存在问题:
- 二、PageHelper分析
- 1.PageHelper简介
- 2.PageHelper源码分析
- 三:fetchsize游标的使用
- 1.什么是fetchsize
- 2.使用场景
前言
Mybatis作为一个应用广泛的优秀的ORM开源框架,这个框架具有强大的灵活性,在四大组件(Executor、StatementHandler、ParameterHandler、ResultSetHandler)处提供了简单易用的插 件扩展机制。Mybatis对持久层的操作就是借助于四大核心对象。MyBatis支持用插件对四大核心对象进行拦截,对mybatis来说插件就是拦截器,用来增强核心对象的功能,增强功能本质上是借助于底层的动态代理实现的,换句话说,MyBatis中的四大对象都是代理对象
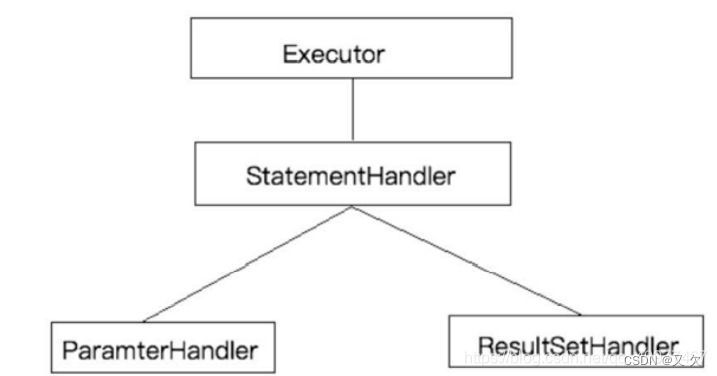
1.Executor:用于拦截MyBatis的Executor对象,可以在执行SQL语句前后进行一些操作,如记录SQL日志、实现分页功能等。
2.ParameterHandler:用于拦截MyBatis的ParameterHandler对象,可以在设置SQL参数前后进行一些操作,如加密解密、参数校验等。
3.ResultSetHandler:用于拦截MyBatis的ResultSetHandler对象,可以在处理查询结果前后进行一些操作,如缓存查询结果、处理枚举类型等。
4.StatementHandler:用于拦截MyBatis的StatementHandler对象,可以在创建SQL语句前后进行一些操作,如动态修改SQL语句、实现分表功能等。
通过拦截这些对象,MyBatis插件可以实现很多功能,如分页、缓存、加密解密、动态修改SQL语句等。同时,MyBatis插件也可以扩展MyBatis的功能,提高开发效率和代码质量。
一、自定义一个简单的mybatis分页插件?
Page 类,负责传递参数等信息
public class Page {
// 总行数
public int total;
// 每页大小
public int size ;
// 页码
public int index;
}
PagePlugin 类,对StatementHandler的prepare方法进行拦截。
@Intercepts({@Signature(type= StatementHandler.class,method="prepare",args={Connection.class,Integer.class})})
public class PagePlugin implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
// 1.判断当前SQL是否需要进行分页
// 2.分页查询总条数
// 3.修改原有SQL,拼接limit进行分页设置
// 4.执行原有方法,查询数据库
return invocation.proceed();
}
@Override
public Object plugin(Object target) {
return Interceptor.super.plugin(target);
}
@Override
public void setProperties(Properties properties) {
Interceptor.super.setProperties(properties);
}
}
在PagePlugin 类中,他对StatementHandler的prepare方法进行拦截,并获取了两个参数Connection和一个Integer。而在intercept方法中,我们则需要完成以下4步来完成我们的分页操作。
1.判断当前传参是不是一个Page,如果是page就进行转换。
StatementHandler target =(StatementHandler) invocation.getTarget();
BoundSql boundSql = target.getBoundSql();
// 拿到参数
Object parameterObject = boundSql.getParameterObject();
Page page=null;
// 1.判断当前传参是不是一个Page,如果是page就进行转换。
if (parameterObject instanceof Page){
page = (Page) parameterObject;
// 2.如果是多个参数,就遍历map,查看有没有page对象
} else if(parameterObject instanceof Map){
page = (Page) ((Map<?, ?>) parameterObject).values().stream().filter(v -> v instanceof Page).findFirst().orElse(null);
// 如果都不是表示不需要分页,执行原有方法
}else if (page == null ){
return invocation.proceed();
}
2.分页查询总条数
// 从参数列表中,获取一个Connection
Connection connection = (Connection)invocation.getArgs()[0];
String sql = boundSql.getSql();
int count=0;
if (page!=null){
// 完成SQL拼接,查询总条数的SQL
String countSQL = String.format("select count(*) from (%s) as _page", sql);
// 进行参数值,SQL的设置
PreparedStatement preparedStatement = connection.prepareStatement(countSQL);
target.getParameterHandler().setParameters(preparedStatement);
// 查询数据库,获取结果
ResultSet resultSet = preparedStatement.executeQuery();
if (resultSet.next()){
// 获取总条数
count= resultSet.getInt(1);
}
// 关闭资源,连接
resultSet.close();
preparedStatement.close();;
}
// 设置总条数
page.setTotal(count);
3.修改原有sql
// 对原有SQL进行修改,拼接limit
String newSQL = String.format("%s limit %s offset %s", sql, page.getSize(), page.getOffset());
// 通过反射修改boundSql的sql语句
SystemMetaObject.forObject(boundSql).setValue("sql",newSQL);
4.执行原有方法
// 执行原有方法
return invocation.proceed();
5.存在问题:
问题一:在我们执行以上代码时,如果一级缓存命中的话,是不是就不会执行prepare方法。因为我们在执行方法时,先会去查我们的二级缓存,在查一级缓存。如果都没有才会去查询数据库。而我们这个方法是在查询数据库之前才会去执行的。
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
Page page=new Page();
page.setSize(2);
page.setIndex(1);
List<User> users = mapper.selectPage("admin",page);
page.setSize(3);
// 走了一级缓存
List<User> admin = mapper.selectPage("admin", page);
解决方案:
通过反射获取MappedStatement ,如果需要进行分页就禁用一级缓存。
// 在这里我们可以通过反射获取MappedStatement
MetaObject metaObject = SystemMetaObject.forObject(target);
MappedStatement mappedStatement = (MappedStatement) metaObject.getValue("delegate.mappedStatement");
// 禁用一级缓存
mappedStatement.getConfiguration().setLocalCacheScope(LocalCacheScope.STATEMENT);
问题二:也就是我们的二级缓存问题,如果在多个SqlSession当中,我们二级缓存命中了。那么我们返回总条数的对象会是一样的吗?
其实这个我目前也没有好的解决方案,因为在平时开发中我也是不建议使用二级缓存的。暴力点,直接不开启二级缓存。
当然还有很多其他的问题,接下来我们可以通过分析PageHelper的源码去一 一破解,看看PageHelper是怎么去做的。
二、PageHelper分析
1.PageHelper简介
PageHelper是一个开源的MyBatis分页插件,它可以帮助我们快速实现分页功能,支持MySQL、Oracle、SQL Server等多种数据库。使用PageHelper可以大大简化分页代码的编写,提高开发效率。以下是PageHelper的一些特点:
支持多种数据库,包括MySQL、Oracle、SQL Server等;
支持多种分页方式,包括普通分页、滚动分页、嵌套分页等;
支持多种排序方式,包括单字段排序、多字段排序等;
支持多种参数传递方式,包括Page对象、RowBounds对象、Mapper接口参数等;
支持自定义分页插件,可以根据自己的需求扩展分页功能。
使用PageHelper非常简单,只需要在MyBatis的配置文件中配置PageHelper插件,然后在Mapper接口中使用Page对象作为分页参数即可。
在MyBatis的配置文件中配置PageHelper插件:
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<property name="dialect" value="mysql"/>
</plugin>
</plugins>
在Mapper接口中使用Page对象作为分页参数:
public interface UserMapper {
List<User> selectAll(@Param("page") Page page);
}
在Service层中调用Mapper接口方法,并传入Page对象作为分页参数:
public class UserServiceImpl implements UserService {
@Autowired
private UserMapper userMapper;
@Override
public PageInfo<User> selectAll(String name, int pageNum, int pageSize) {
PageHelper.startPage(pageNum, pageSize);
List<User> userList = userMapper.selectAll(new Page(name));
return new PageInfo<>(userList);
}
}
2.PageHelper源码分析
这段代码做的是什么功能,就是把我们当前设置的分页参数存储在ThreadLocal当中,后续在执行查询时,就会获取当前分页参数。这样就可以达到,当我们执行一次分页时。不需要改动我们的原有对象,也不需要在原有对象中去设置分页参数等等。
什么是ThreadLocal,请自行百度,先简单理解的话就是一个当前线程内存放数据的变量。而且这里边存放的东西是线程隔离的,其他线程拿不到,而当前线程是可以随时拿到里面的数据。
PageHelper.startPage(pageNum, pageSize);
其实整体逻辑和上面我们自定义一个分页插件是差不多的,只不过是PageHelper比我们更完善,考虑方面也会更多。下面就带着几个问题去看看我们的源码。
问题一:就是查询总数的问题,其实大家可以发现,如果我们同样的SQL同样的条件,只是分页的数值不一样。那么他查询的总数肯定是一样的对把,就没必要去进行两次的查询。那么我们看看PageHelper是怎么做的。
首先PageHelper是对Executor的query方法进行了拦截,那么也就是它把拦截提前了,在二级缓存之前。
@Intercepts({@Signature(
type = Executor.class,
method = "query",
args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}
), @Signature(
type = Executor.class,
method = "query",
args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class, CacheKey.class, BoundSql.class}
)})
public class PageInterceptor implements Interceptor {
}
其实对执行器进行拦截,就可以达到我们上面的效果。因为拦截之后我们是要去走缓存的。如果第一次查询总数的时候,我们在拦截器里面先去调用执行器的query方法,并把数据和结果存入我们的一级、二级缓存中。那么我们第二次查询总数时,是否就可以直接命中缓存。
问题二:那么是不是只要我设置了ThreadLocal,每次查询它都会进行分页
在处理完所有方法后,会调用finally里面的方法。
try {
} finally {
if (this.dialect != null) {
this.dialect.afterAll();
}
}
查询完就把线程内(前面提到的) ThreadLocal LOCAL_PAGE 存储的数据移除了。后面在查询中,如果在ThreadLocal中获取不到相应数据,那么也就没必要进行分页。直接走原有查询方法即可。
public void afterAll() {
AbstractHelperDialect delegate = this.autoDialect.getDelegate();
if (delegate != null) {
delegate.afterAll();
this.autoDialect.clearDelegate();
}
clearPage();
}
public static void clearPage() {
LOCAL_PAGE.remove();
}
问题三:当我设置了两次分页,第二次分页值不一样。会命中缓存吗
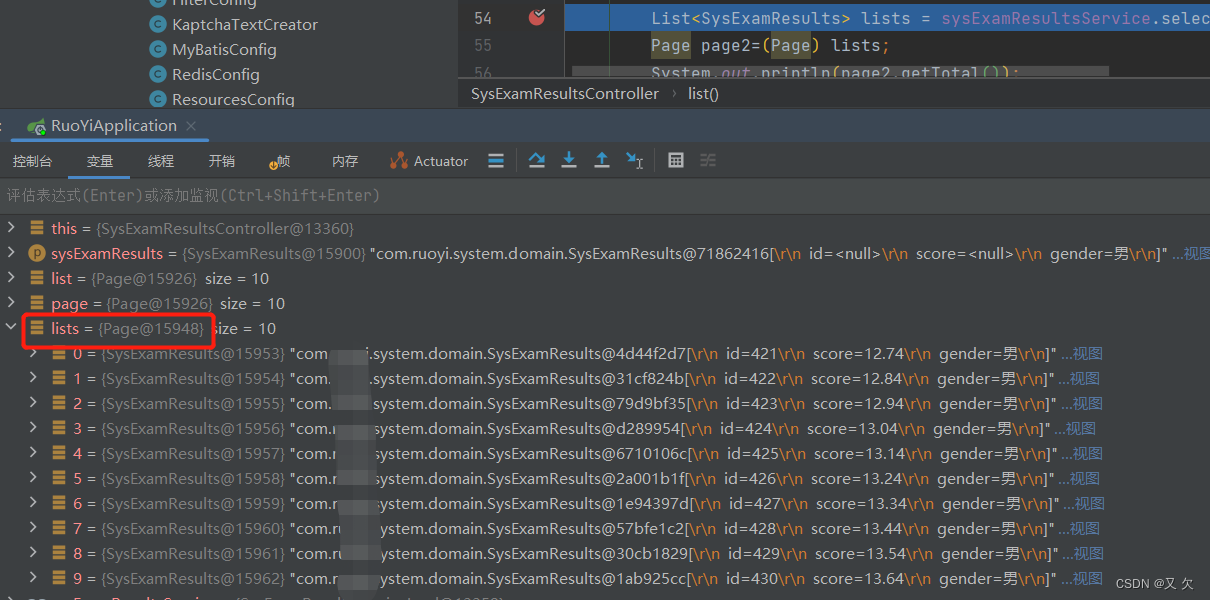
public TableDataInfo list(SysExamResults sysExamResults)
{
startPage();
List<SysExamResults> list = sysExamResultsService.selectSysExamResultsList(sysExamResults);
startPages();
List<SysExamResults> lists = sysExamResultsService.selectSysExamResultsList(sysExamResults);
return getDataTable(list);
}
在我自定义的分页插件当中,当我设置分页参数不一样时,还是会命中缓存的。而PageHelper却不会。在同一个SqlSession中,我们能否命中一级缓存,主要还是看我们的cacheKey。如果cacheKey一样那么就可以命中我们的缓存。而在PageHelper中,它通过反射改动了我们原有cacheKey,把我们的分页参数加入到了cacheKey当中。二级缓存其实也是同理,也是改动了cacheKey
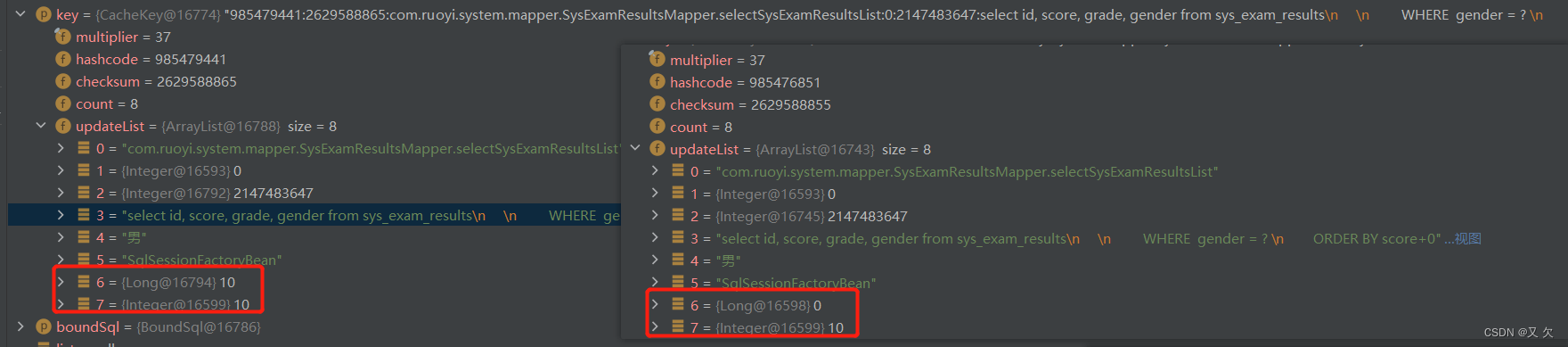
问题四:我查询了总条数之后,PageHelper把它放在哪里。我怎么去获取
在page的PageMethod当中,是有一个ThreadLocal的。当存储的就是当前线程的page。这里是不是和前面存储我们的分页参数一样。
protected static final ThreadLocal<Page> LOCAL_PAGE = new ThreadLocal();
/**
* 在查询总数之后执行的方法,用于设置总条数和分页信息。
* @param count 总条数
* @param parameterObject 查询参数
* @param rowBounds 分页参数
* @return 是否继续执行分页查询
*/
public boolean afterCount(long count, Object parameterObject, RowBounds rowBounds) {
// 获取当前线程的Page对象
Page page = this.getLocalPage();
// 设置总条数
page.setTotal(count);
// 如果分页参数是PageRowBounds类型,则设置总条数
if (rowBounds instanceof PageRowBounds) {
((PageRowBounds)rowBounds).setTotal(count);
}
// 如果pageSizeZero不为空,则判断pageSize是否合法
if (page.getPageSizeZero() != null) {
if (!page.getPageSizeZero() && page.getPageSize() <= 0) {
return false;
}
if (page.getPageSizeZero() && page.getPageSize() < 0) {
return false;
}
}
// 判断是否需要继续执行分页查询
return page.getPageNum() > 0 && count > page.getStartRow();
}
这段代码是PageHelper中的一个方法,用于在查询总数之后执行,设置总条数和分页信息。具体来说,它会先获取当前线程的Page对象,然后将总条数设置到Page对象中。如果分页参数是PageRowBounds类型,则也会将总条数设置到分页参数中。接着,如果pageSizeZero不为空,则会判断pageSize是否合法。最后,根据总条数和分页信息,判断是否需要继续执行分页查询。
这个是查询结果后会执行一次afterPage,这个afterPage就是把我们查询分页后的结果封装到page当中。所以我们当前的这个page,既有我们查询的总条数,也有我们执行的结果集合。
public Object afterPage(List pageList, Object parameterObject, RowBounds rowBounds) {
Page page = this.getLocalPage();
if (page == null) {
return pageList;
} else {
page.addAll(pageList);
if (!page.isCount()) {
page.setTotal(-1L);
} else if (page.getPageSizeZero() != null && page.getPageSizeZero() && page.getPageSize() == 0) {
page.setTotal((long)pageList.size());
} else if (page.isOrderByOnly()) {
page.setTotal((long)pageList.size());
}
return page;
}
}
把查询结果直接转换为page,通过 page.getTotal()获取总条数
Page page=(Page) lists;
page.getTotal()
查询的结果lists是一个page类型的集合。
三:fetchsize游标的使用
1.什么是fetchsize
fetchSize是JDBC中的一个参数,用于设置每次从数据库中获取的记录数。在执行查询操作时,JDBC会将查询结果分批返回,每次返回的记录数就是fetchSize参数设置的值。fetchSize的默认值是0,表示不限制每次返回的记录数,这样会导致JDBC一次性将所有记录都返回,占用大量内存和网络带宽,影响查询性能。因此,为了提高查询性能,我们通常需要设置fetchSize参数,限制每次返回的记录数,减少内存和网络带宽的占用。
2.使用场景
假如我们要导出100w条数据,如果我们一次性把这100万条数据全部查出来,放入到我们的对象中,这个时候可能就会出现OOM内存溢出的情况。
既然一次读不了这么多,那么我每次就读1w条,通过limit去进行分页。但是大家也知道,在我们使用limit进行深度分页时,越后面的数据我们分页就会越慢,这样就会影响我们的业务体验。
在MySQL中,使用setFetchSize(Integer.MIN_VALUE)开启游标模式后,每次从数据库中获取的记录数是由MySQL JDBC驱动程序自动决定的,具体取决于MySQL服务器的配置和查询语句的复杂度。一般来说,MySQL JDBC驱动程序会根据查询语句的复杂度和MySQL服务器的配置,自动调整每次获取的记录数,以达到最优的查询性能。
以下是一个深度分页的测试用例,数据库100w条数据耗时: 327613 大约5分27秒
public void Test() throws Exception{
Connection connection =null;
PreparedStatement statement =null;
ResultSet resultSet =null;
try {
SqlSessionFactoryBuilder sqlSessionFactoryBuilder=new SqlSessionFactoryBuilder();
org.springframework.core.io.ClassPathResource classPathResource=new ClassPathResource("org/apache/ibatis/user/mybatis.xml");
InputStream inputStream = classPathResource.getInputStream();
SqlSessionFactory sqlSessionFactory= sqlSessionFactoryBuilder.build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
connection = sqlSession.getConnection();
statement = connection.prepareStatement("select * from t2 limit ?,?");
long l = System.currentTimeMillis();
long begin=0L;
Long offset=10000L;;
while (true){
statement.setLong(1,begin);
statement.setLong(2,offset);
begin+=offset;
resultSet=statement.executeQuery();
boolean flag=resultSet.next();
if (!flag) break;
while (flag){
System.out.println("id:"+resultSet.getString("id"));
flag=resultSet.next();
}
}
System.out.println("耗时:"+ (System.currentTimeMillis()-l));
}catch (Exception e){
e.printStackTrace();
}finally {
statement.close();
connection.close();
resultSet.close();
}
}
以下是一个fetchsize测试用例,数据库100w条数据耗时: 157613 大约2分37秒
public void TestfetchSize() throws Exception{
Connection connection =null;
PreparedStatement statement =null;
ResultSet resultSet =null;
try {
SqlSessionFactoryBuilder sqlSessionFactoryBuilder=new SqlSessionFactoryBuilder();
org.springframework.core.io.ClassPathResource classPathResource=new ClassPathResource("org/apache/ibatis/user/mybatis.xml");
InputStream inputStream = classPathResource.getInputStream();
SqlSessionFactory sqlSessionFactory= sqlSessionFactoryBuilder.build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
connection = sqlSession.getConnection();
statement = connection.prepareStatement("select * from t2 ");
statement.setFetchSize(Integer.MIN_VALUE);
statement.setFetchDirection(ResultSet.FETCH_FORWARD);
long l = System.currentTimeMillis();
resultSet = statement.executeQuery();
while (resultSet.next()){
System.out.println("id:"+resultSet.getString("id"));
}
System.out.println("耗时:"+ (System.currentTimeMillis()-l));
}catch (Exception e){
e.printStackTrace();
}finally {
statement.close();
connection.close();
resultSet.close();
}
当然差距还是有的,可能我电脑配置不行。 我使用的是MySQL数据库,如果你使用的是其他数据库可能执行效率会更快。fetchSize和分页都是获取数据的方式,但是适用场景不同。如果查询结果集较大,可以考虑使用fetchSize来减少JDBC与数据库之间的通信次数,提高查询性能;如果需要分批次获取数据,可以考虑使用分页来实现。需要根据具体的查询场景和性能需求,选择合适的获取数据方式。
到了这里本文章也就结束了,希望本文章可以给你带来帮助。