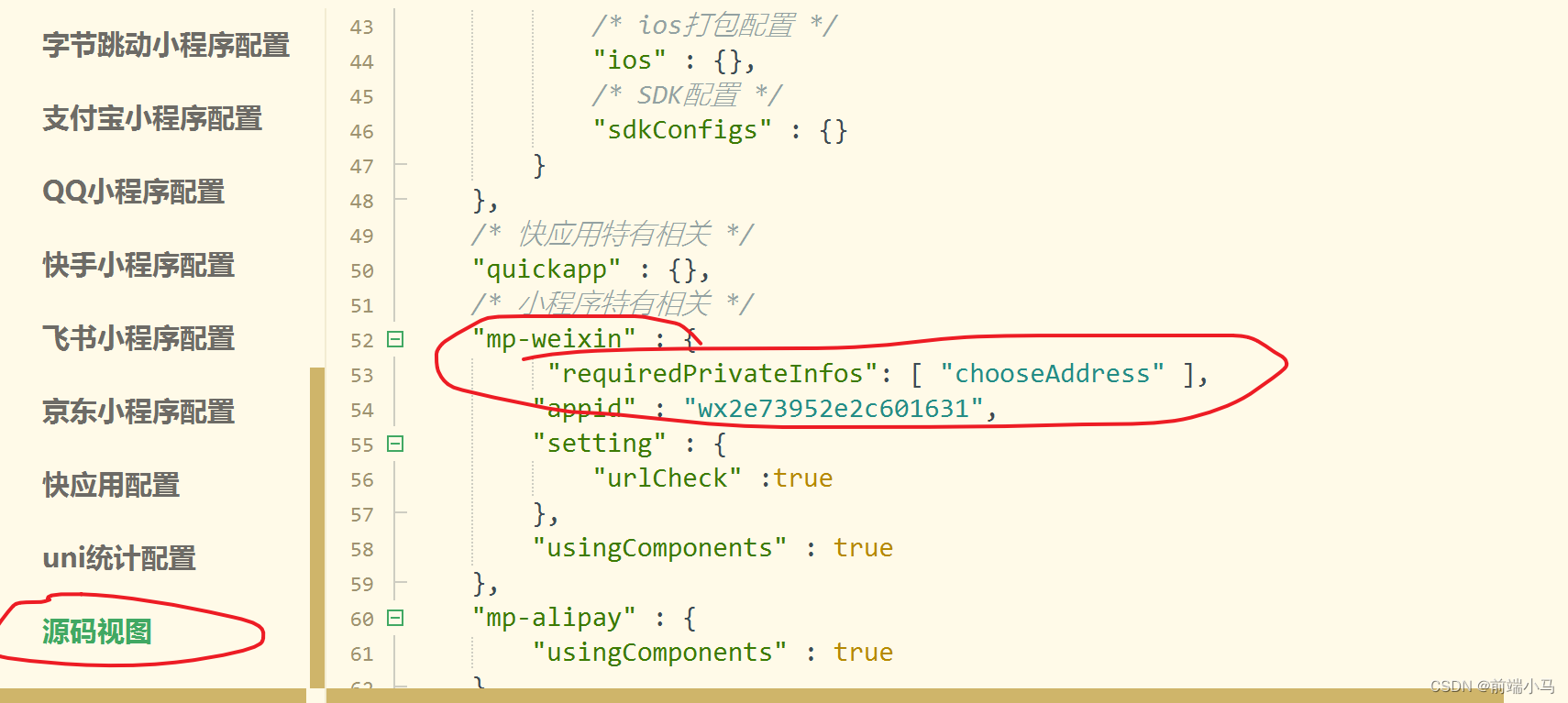
onnx
ONNX 是一种用于机器学习模型的开放式表示格式,它可以让不同的深度学习框架之间共享模型。
import onnxruntime
# 加载模型
session = onnxruntime.InferenceSession('model.onnx')
# 运行模型。第一个参数是输出变量列表,不指定的话返回所有值
output = session.run(None, {'input': input_data})
https://zhuanlan.zhihu.com/p/582974246
ckpt文件
ckpt 文件通常是指 TensorFlow 模型的检查点文件,用于保存模型的权重和其他参数。检查点文件包括两个部分:一个用于存储模型权重,另一个用于存储模型的元数据,例如模型的图结构和训练状态。
通过保存检查点文件,您可以在训练过程中定期保存模型的状态,以便在出现错误或意外终止时能够恢复训练。您还可以使用检查点文件来保存模型的最佳权重,以便在测试或生产环境中使用。
import torch
# MyModel 类需要继承自 PyTorch 中的nn.Module类,并实现forward 方法
model = MyModel()
# 加载权重
state_dict = torch.load('model.ckpt')
model.load_state_dict(state_dict)
# 使用模型进行推理
output = model(input_data)
将ckpt文件转为onnx文件:
import torch
import torch.onnx
# 打开ckpt,跟前面一样的
model = MyModel()
state_dict = torch.load('model.ckpt')
model.load_state_dict(state_dict)
# 将模型转换为 eval 模式
model.eval()
# 创建输入张量.随机的,维度为(1,3,224,224)
input_data = torch.rand(1, 3, 224, 224)
# 导出模型为 ONNX 格式,使onnx运行时版本为11
torch.onnx.export(model, input_data, 'model.onnx', opset_version=11)
Attention机制
即将有限的注意力集中到重点信息上,从而节省资源,快速获得最有效的信息。就是encoder层的输出经过加权平均后再输入到decoder层中,这个加权可以用矩阵表示,即Attention矩阵,它表示对于某个时刻的输出y,它在输入x上各个部分的注意力。
Self-Attention:输出序列即输入序列,自己计算自己的attention得分
Context-Attention:是encoder和decoder之间的attention,是两个不同序列之间的attention。(Transformer模型)
Transformer
Transformer
https://zhuanlan.zhihu.com/p/47812375
Transformer使一种处理序列数据的深度学习模型,在自然语言处理领域应用广泛。其中,编码器是将输入序列转换成一组特征向量,解码器则是特征向量转化成输出序列。
pytorch.nn.TransformerEncoder 中的每个层都包含一个 Multi-Head Attention 模块和一个全连接前馈神经网络模块。(跟前面Encoder模块是一样的,torch中是实现)
在 Multi-Head Attention 模块中,模型会将输入序列分成多个子序列,并在每个子序列上分别计算注意力,然后将注意力结果合并起来。这样的好处是可以让模型同时关注不同位置和不同方面的信息,以提高模型表现。但是头数越多,参数越多,计算量越大,模型的效果越好。需要权衡。
import torch
import torch.nn as nn
# 定义 TransformerEncoder 模型
class TransformerEncoderModel(nn.Module):
def __init__(self, num_layers, input_dim, hidden_dim, num_heads):
super(TransformerEncoderModel, self).__init__()
self.encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(input_dim, num_heads, hidden_dim),
num_layers
)
def forward(self, x):
return self.encoder(x)
# 创建 TransformerEncoder 模型实例
model = TransformerEncoderModel(num_layers=2, input_dim=512, hidden_dim=2048, num_heads=8)
# 准备输入数据
input_data = torch.randn(10, 512)
# 运行模型得到输出
output_data = model(input_data)
# 输出结果
print(output_data.shape)
另一个示例:
import torch.nn as nn
encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8,
dim_feedforward=2048, dropout=0.1, activation='relu')
transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=2)
torch.nn.TransformerEncoderLayer部分参数说明
- d_model 输入向量的维度,默认512
- nhead 注意力头数(指将序列分成多少个子序列),默认8
- dim_feedforward 全连接前馈神经网络模块的隐藏层大小,默认2048
- dropout 在注意力和全连接前馈神经网络模块中使用的dropout概率,默认值0.1,是为了防止过拟合
- activation 全连接前馈神经网络中激活函数类型,默认relu
nn.TransformerEncoder的src_key_padding_mask参数:
用于屏蔽不需要计算注意力的位置的掩码。因为在每个批次计算时,不是所有的序列长度都相同的,因此在进入处理前,我们会对序列进行填充,使长度相同。这些填充的位置显然不用计算注意力,所以要用src_key_padding_mask指明填充位置。
src_key_padding_mask可以设为None,表示所有位置都要计算注意力,如果不是None,就应该是一个二维的布尔型张量,形状为 (batch_size, input_seq_len)。其中,batch_size 表示批次大小,input_seq_len 表示输入序列的长度。
如果 src_key_padding_mask[i, j] 等于 True,则表示第 i 个样本的第 j 个位置是填充位置,不需要计算注意力;否则,表示该位置需要计算注意力。
Normalization
在深度学习中,归一化(Normalization)是一种常用的技术,用于提高模型的稳定性和训练效果。其中,层归一化(Layer Normalization)是一种常用的归一化方式,它可以使得每个样本的特征在神经网络中的传播具有一致性。在 PyTorch 中,nn.LayerNorm 类可以用于实现层归一化。
import torch.nn as nn
# normalized_shape: 归一化的维度。默认值为 -1,表示对输入的所有维度进行归一化
# eps: 一个小的常数,用于避免除以零误差。默认值为 1e-5。
layer_norm = nn.LayerNorm(normalized_shape=512, eps=1e-5)
Embedding
torch.nn.Embedding 是 PyTorch 中的一个类,用于实现嵌入层(embedding layer)。嵌入层通常用于将离散的符号嵌入到低维向量空间中,以便于神经网络对这些符号进行处理。例如,在自然语言处理中,我们通常需要将单词嵌入到低维向量空间中,以便于神经网络对单词进行分类、聚类、生成等任务。
torch.nn.Embedding 的常用参数包括:
num_embeddings:表示嵌入层的符号个数,即嵌入层的输入大小;(例如,在自然语言处理任务中,num_embeddings 可以设置为词表的大小,即词汇表中单词的数量)
embedding_dim:表示嵌入层的嵌入维度,即嵌入层的输出大小,即 Embedding 后的向量的大小。默认值为 128
padding_idx:表示用于填充的符号索引,默认是None,表示不填充
max_norm: 用于指定 Embedding 向量的最大范数。默认值为 None,表示不进行约束
norm_type: 用于指定 Embedding 向量的范数类型。默认值为 2,表示 L2 范数
scale_grad_by_freq: 用于控制梯度的缩放方式。默认值为 False,表示使用固定的梯度缩放因子
sparse: 用于指定是否使用稀疏张量。默认值为 False,表示使用密集张量
import torch.nn as nn
# 将一个大小为 100 的词表映射为一个大小为 128 的向量
# 需要注意的是,输入的整数特征需要在 0 到 num_embeddings-1 的范围内
embedding = nn.Embedding(num_embeddings=100, embedding_dim=128)
DataLoader
torch.utils.data.DataLoader 是 PyTorch 中一个用于加载数据的工具类。它可以帮助我们将数据集转换为 PyTorch 中的 Dataset 对象,并提供了一些方便的功能:
数据批量加载:DataLoader 可以将数据集分成多个批次进行加载,并按照设定的顺序将它们提供给模型进行训练
数据顺序打乱:为了提高模型的训练效果,我们通常需要对数据集进行随机打乱。DataLoader 提供了一个 shuffle 参数,可以轻松地实现随机打乱
数据并行加载:当数据集很大时,我们可能需要使用多个 CPU 或 GPU 并行加载数据。DataLoader 可以通过 num_workers 参数来指定并行加载的进程数
batch_size:指定每个批次的样本数量。默认为 1
collate_fn:指定如何将每个样本的数据进行合并。默认为在每个批次中返回一个元组的列表,即批次中的每个元素包含一个元组,元组中的第 i 个元素是第 i 个样本的数据。可以根据具体的需求自定义合并方法
drop_last:如果设为 True,当数据集中的样本数量不能被 batch_size 整除时,将丢弃最后一个批次中的剩余样本。默认为 False。
PyTorch Lightning 框架
pytorch_lightning.LightningModule 是 PyTorch Lightning 框架中的一个类,它是一个高级别的封装,用于简化深度学习模型的开发和训练过程。它提供了一组标准化的接口和实现,可以帮助我们更方便地定义和训练神经网络模型,同时还可以获得更好的性能和可重用性。只要写好forward,training_step写好了loss,并且return了,就可以自动反向传播。
pytorch_lightning.LightningModule可以帮助我们实现以下功能:
简化模型定义:LightningModule 提供了一组标准化的模型接口,例如 init、forward、training_step、validation_step 和 test_step 等
自动管理训练过程:例如优化器的选择和配置、学习率的调整和策略、梯度的累积和截断等
多样化的训练选项:如分布式训练、自动混合精度和自动批量大小等
高度可重用性
pytorch_lightning.callbacks.ModelCheckpoint 是 PyTorch Lightning 中的一个回调函数类,用于在训练过程中自动保存模型的权重参数。具体来说,它可以帮助我们实现以下功能:
自动保存模型:会根据设定的条件自动保存模型的权重参数。可以根据需要设定保存的频率、保存的文件名等参数
自动加载模型:可以自动加载之前训练好的模型权重参数,从而实现断点训练的功能
自动清理模型:为了避免磁盘空间的浪费,可以根据设定的条件自动清理不需要的模型权重文件
常用参数:
filepath:用于指定保存模型权重参数的文件名。可以使用类似于 {epoch}、{val_loss} 等占位符来动态地生成文件名。
save_top_k:用于指定保存最好的几个模型。例如,save_top_k=1 表示只保存最好的一个模型,save_top_k=3 表示保存最好的三个模型。默认为 1
monitor:用于指定监控的指标。例如,monitor=‘val_loss’ 表示监控验证集上的损失函数值。
mode:用于指定监控指标的模式。例如,mode=‘min’ 表示监控指标越小越好,mode=‘max’ 表示监控指标越大越好,mode=‘auto’ 表示根据指标的类型自动选择模式。默认为 ‘auto’
save_last:用于指定是否保存最后一个模型。默认为 True
save_weights_only:用于指定是否只保存模型的权重参数而不保存整个模型。默认为 False
period:用于指定保存模型的间隔周期。例如,period=10 表示每隔 10 个 epoch 保存一次模型。默认为 None,表示每个 epoch 都保存一次模型

![深度学习进阶篇[8]:对抗神经网络GAN基本概念简介、纳什均衡、生成器判别器、解码编码器详解以及GAN应用场景](https://img-blog.csdnimg.cn/img_convert/c530a112c911329eaf8cb9cfeaab09fc.png)