介绍
kafka在过去几年获得了巨大的普及。在微服务架构中,它起着举足轻重的作用。它使数据能够从一项服务转移到另一项服务。我开始这个系列是为了帮助初学者深入了解 Kafka。但是,在我们深入之前,了解一些基础知识很重要。因此,在这篇文章中,我们将学习基础知识,并最终深入探讨。
基本
“Kafka 是一个高度可扩展、持久、容错的分布式流媒体平台。” 这是我们从Kafka官网看到的定义。这些行话可能会吓到新人。让我们先了解一下这些的含义。
高度可扩展:如果 Kafka 的传入消息不断增加,您可以通过向集群添加更多代理来扩展系统。您可以通过添加更多机器或通过添加更多磁盘空间来垂直扩展它。
耐用:耐用性是持续时间更长的能力。发送到 Kafka 主题的消息会保存在磁盘中。除非您将它们配置为删除,否则它们不会被删除。
容错:首先,容错是指系统在一个或多个节点发生故障时仍能运行的能力。在 Kafka 集群中,即使一个 broker 挂了,系统仍然可以运行,因为有复制。我们将在以后的帖子中了解这一点。
分布式流媒体平台:流是连续的流。在 Kafka 中,生产者生产消息,消费者消费。此流从未停止。这就是为什么我们称 Kafka 为流媒体平台。
简而言之,Kafka 在传统的客户端-服务器架构上工作。服务器是Kafka,生产者(发送数据的)和消费者(接收数据的)是客户端。客户端和服务器之间的通信通过Kafka 团队实现的定制高性能 TCP 协议进行。大多数编程语言都有许多可用的客户端库。
事件
事件描述发生的事情。例如,在电子商务系统中,事件的例子可以是“订单已创建”、“商品已添加到购物车”、“订单已送达”。在 Kafka 中,我们以事件的形式读取或写入数据。事件数据的示例ORDER_CREATED如下所示。我们可以用 XML、JSON 或 Avro 发送这些数据。
{
"order_id": "abcd-1234",
"order_amount": "50.00",
"created_by": "lokesh",
"created_on": "2022-02-09T22:02:00Z"
}
基本架构
生产者是将数据“发送”到 Kafka 的实体。消费者是“消费”来自 Kafka 的数据的实体。在 Kafka 中,这两个实体都是松散耦合的。这意味着,生产者只生产而不管消费者的存在。同样,消费者的责任是在不依赖生产者的情况下消费来自 Kafka 的数据。

主题和分区
事件按主题分类。主题包含相关信息。在设计数据管道时,主题是基于语义创建的。每个主题都有其意义和目的。例如,“支付”是接收支付相关事件的主题。每个主题分为多个分区。主题是 Kafka 中的逻辑实体,这意味着它在物理上不存在,而分区存在。当您创建一个包含“n”个分区的主题时,下面是幕后发生的事情。
- Kafka 创建了 ‘n’ 个名称为
topic-1,topic-2…的文件夹topic-n。 - 在每个文件夹中,都会有存储事件的文件。
我们将在接下来的帖子中进入内部。现在,谈到分区,它是最小的存储单元和仅附加数据结构,其中事件附加到末尾。分区允许用户获得并行性。分区数越多,并行度越高。
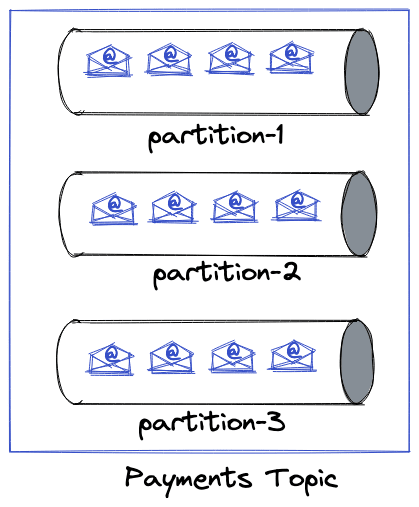
分区键
当生产者向 Kafka broker 发送消息时,他们会去哪个分区?好吧,如果没有发送分区键,它们将转到一个随机分区。什么是分区键?它是发送时的可选参数,Kafka 确保具有相同分区键的消息写入同一个分区。让我们用下图来说明它。带有分区键“lokesh、john & kate”的消息被发送到partition 1。与其他键相同。在幕后,Kafka 计算分区键的哈希值,并对总分区应用模运算以获得分区。分区键解决了一些需要根据分区键聚合消息的用例。

消费者如何工作?
当您启动消费者时,会发生以下情况。
- 我们向消费者指定 Kafka 引导程序 URL(或 zookeeper URL,当提供 Kafka 代理时将自动发现)。
- 消费者打开与代理的 TCP 连接并注册自己。
- 消费者询问经纪人它在哪里,经纪人返回偏移量。Kafka 代理在一个名为
__consumer_offsets. - 消费者不断轮询并从偏移量开始消费消息。
- 消费者完成工作并将偏移量提交回代理。
- 消费者移动到下一条消息并且该过程继续。
如果您的消费者需要更多时间来处理每条消息,那么您可以将配置max.poll.interval.ms更改为更高的值。默认情况下,它设置为 5 分钟。您还可以调整max.poll.records,它指定消费者可以在单个轮询调用中获取的最大记录数。
抵消
在计算机科学中,维基百科对偏移量的定义如下。在 Kafka 的上下文中也是如此。它告诉消息位置。
偏移量是一个整数,指示对象的开始与给定元素或点之间的距离(位移),大概在同一对象内。
消费者群体
顾名思义,消费组就是一群消费者。每个消费者组都有一个名称。您可以拥有任意数量的消费者群体。当您启动一个消费者组时,它将向 Kafka 代理注册,这意味着该组中的所有消费者也将被注册。
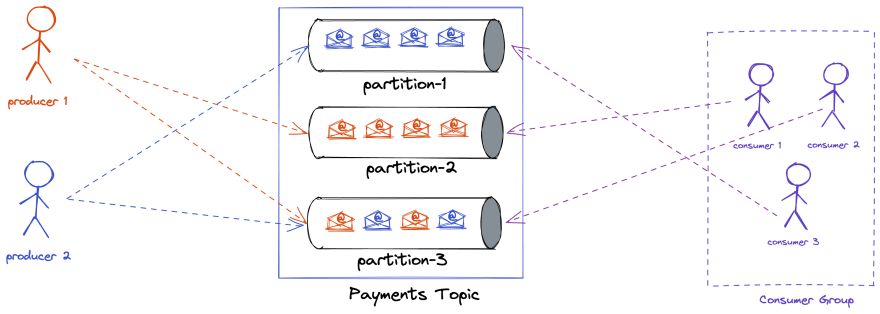
与传统的发布-订阅系统的比较。
此外,如果您熟悉像 rabbitmq 这样的传统 pub-sub 消息传递系统,您可能会发现一些不同之处。
- 消息一旦被消费,就会从 rabbitmq 中删除。但是,在 Kafka 中,它们不会被删除。它们保存在磁盘中。这个特性使 Kafka 可以充当流媒体平台。
- 在 pub-sub 系统中,您不能让多个服务消费相同的数据,因为消息在被一个消费者消费后就会被删除。而在 Kafka 中,您可以使用多个服务。这为许多机会打开了大门,例如Kafka 流、Kafka 连接。


![[QT_055]设置QT源码调试(qtc+vs/mingw+msvc)](https://img-blog.csdnimg.cn/b3aeb7e64d864400a8262f4ec00db104.png)