目录
一、实验目的
二、实验内容
三、实验准备
(一)TSS 切换
(二)基于堆栈的进程切换流程
四、实验过程
(一)实现 switch_to()
1、修改 schedule() 中的 switch_to()
2、实现 switch_to() 的汇编代码
(二)修改 PCB
(三)修改 fork() 系统调用
1、如何修改 fork 系统调用
2、修改 copy_process
3、first_return_kernel
(四)编译运行新的 Linux 0.11
(五)分析实验 4 的日志,体会修改前后系统运行的差别
1、运行 process.c
2、分析 log 文件,统计数据
3、TSS 和堆栈切换的差异
一、实验目的
1、深入理解进程和进程切换的概念。
2、综合应用进程、CPU 管理、PCB、LDT、内核栈、内核态等知识解决实际问题。
3、开始建立系统认识。
二、实验内容
现在的 Linux 0.11 采用 TSS 和一条指令就能完成任务切换,虽然看似简单,但指令的执行时间却很长,在实现任务切换时大概需要 200 多个时钟周期。而通过 堆栈 实现任务切换会更快,而且采用堆栈的切换还可以使用指令流水的并行优化技术,同时又使得 CPU 的设计变得简单。所以,无论是 Linux 还是 Windows 系统,进程/线程的切换都没有使用 Intel 提供的这种 TSS 切换手段,而都是通过堆栈实现的。
本次实验的内容就是修改 Linux 0.11 中的进程/线程切换手段,将 0.11 原本采用的 TSS 切换部分去掉,替换为——基于堆栈的切换程序。具体一点,就是将 Linux 0.11 中的 switch_to 实现去掉,并写实现一段基于堆栈切换的代码。
具体内容包括:
(一)编写汇编程序 switch_to ,实现:
-
完成主体框架
-
在主体框架下依次完成 PCB 切换、内核栈切换、LDT 切换等
(二)修改 PCB
-
即 task_struct 结构,增加相应的内容域,同时处理由于修改了 task_struct 所造成的影响
(三)修改 fork() 系统调用
-
由于是基于内核栈的切换,所以进程需要创建出能完成内核栈切换的样子
(四)修改后的 Linux 0.11 仍然可以正常启动、使用
(五)分析实验 4(进程运行轨迹的跟踪与统计)的日志,体会修改前后系统运行的差别
三、实验准备
(一)TSS 切换
Linux 学习笔记(九):基于 TSS 的进程切换_Amentos的博客-CSDN博客
(二)基于堆栈的进程切换流程

1、 PCB 切换
进程切换的第一步是进程控制块 PCB 的切换,PCB 中保存着该进程上一次停止时内核栈栈顶的指针(esp)。先保存好当前进程 PCB 中的内核栈栈顶指针,然后再切换到目标进程的 PCB,之后就可以根据目标进程 PCB 中相关内容切换到目标进程的内核栈。
2、内核栈切换
PCB 中包含指向内核栈栈顶的指针,现在 PCB 已经切换,就可以根据 PCB 中内容切换内核栈。
3、LDT 切换
进程切换还包含 LDT(内存映射表)的切换,这是和线程切换的不同之处。
4、用户栈切换
内核栈中的 SS、SP 指向用户栈,在内核中运行一段代码后,通过 iret 指令退出内核时就能实现用户栈的切换。
四、实验过程
(一)实现 switch_to()
1、修改 schedule() 中的 switch_to()
目前 Linux 0.11 中工作的 schedule() 首先找到目标进程的数组位置 next,这个 next 就是 GDT 中的 n,也就是说 next 是用来找到要切换的目标进程对应 TSS 段的段描述符的。一旦获得这个 next 值,然后直接调用 switch_to(next) 就能完成基于 TSS 的进程切换了。
但现在,我们不用 TSS 进行切换,而是采用切换内核栈的方式来完成进程的切换。所以在新的 switch_to 中将用到当前进程的 PCB、目标进程的 PCB、当前进程的内核栈、目标进程的内核栈、目标进程的 LDT 等信息。所以要修改 switch_to 的参数。
- 进程的内核栈可以通过 PCB 找到(具体怎么找见下文),所以我们只需要传递进程的 PCB 和 LDT 就行
由于指向当前进程 PCB 的 current 指针是一个全局变量,就无需向函数传递了,所以只需要告诉新的 switch_to() 一个指向目标进程 PCB 的指针 pnext ,同时还要将 next 也传递进去。
虽然 TSS(next) 已经不需要了,但是 LDT(next) 还是需要的。也就是说,现在每个进程不必拥有自己的 TSS 了,因为已经不采用 TSS 切换了,但是每个进程还是需要有自己的 LDT,地址分离地址还是必须要有的,因为进程的切换必然要涉及到 LDT 的切换。
【1】修改 switch_to 函数的参数
综上所述,将目前的 schedule() 函数(在 kernal/sched.c 中)稍做修改,将下面的代码:
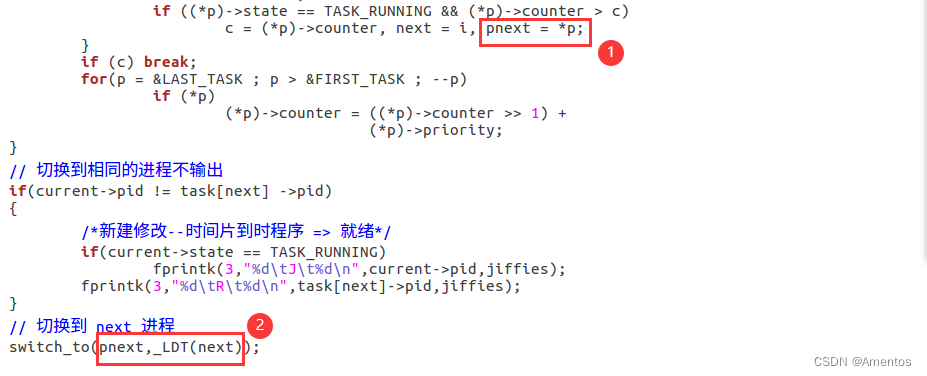
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
//......
switch_to(next);修改为:
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i, pnext = *p;
//.......
switch_to(pnext,_LDT(next));修改后如图所示:
【2】添加 pnext 的变量声明
其中 pnext 指向目标进程的 PCB,_LDT(next) 指向目标进程的 LDT 。
_LDT(n) 在 sched.h 中已经有定义:

但是 pnext 是我们自己定义的指向 PCB 的指针,所以需要在 sched.h 中手动添加声明:
struct tast_struct *pnext = &(init_task.task);- Linux 0.11 中进程的 PCB 就是一个名为 task_struct 的结构体(在 sched.h 中定义)
添加到如下位置即可:

- 这里 pnext 和 current 的初始赋值是一样的
【3】添加 switch_to 函数声明
虽然 switch_to 还没有开始正式编写,但是我们现在已经确定了 switch_to() 的两个参数,所以可以先添加对应的函数声明,不会影响接下来 switch_to 的编写。
在 sched.c 中声明:
extern long switch_to(struct task_struct *p, unsigned long address);添加到如下位置即可:

这样一来,在 schedule() 中经过一番操作后,pnext 就指向了要切换的目标进程的 PCB(具体过程不用管,我们只需要知道结果即可)。当调用 switch_to(pnext, _LDT(next)); 时,会依次将 参数 2 _LDT(next)、 参数1 pnext、返回地址 } 压栈。当执行 switch_to 的返回指令 ret 时,就回弹出 schedule() 函数的 } 并执行这个 schedule() 的返回指令 } 。
2、实现 switch_to() 的汇编代码
实现 switch_to() 是本次实验中最重要也最难的一部分,由于要对内核栈进行精细的操作,所以需要用汇编代码来完成编写,switch_to() 主要依次完成如下功能:
(1)由于是 C 语言调用汇编,所以首先需要在汇编中处理栈帧,即处理 ebp 寄存器。
(2)接下来要取出表示目标进程 PCB 的参数,并和 current(当前进程 PCB)做一个比较:
>> 如果 “等于” current,则什么也不用做。
>> 如果 “不等于” current,则开始进程切换:依次完成 PCB 的切换、TSS 中的内核栈指针的重写、内核栈的切换、LDT 的切换以及 PC 指针(即 CS:EIP)的切换。
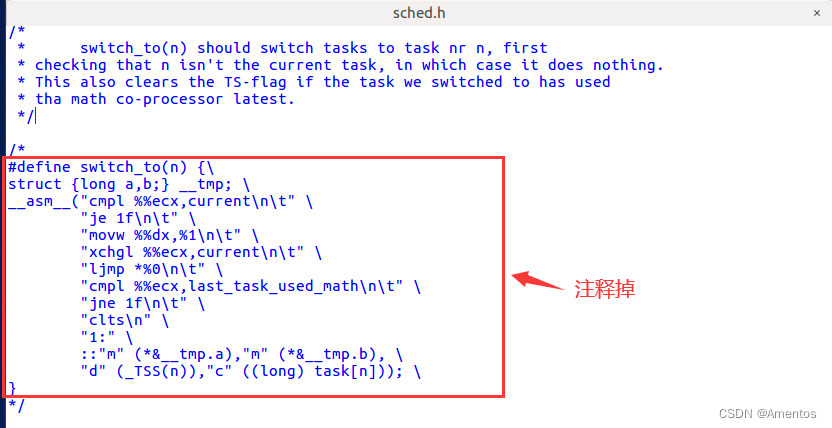
【1】删除原来的 switch_to()
Linux 0.11 原本的 switch_to() 展开就是一段 ljmp 指令,现在要改写成基于堆栈(内核栈)切换的函数,就要删除掉该语句,直接注释掉即可(在 sched.h 中),如下图:
【2】编写基于堆栈的 switch_to 代码
新的 switch_to() 就不在 sched.h 中编写了,我们将它写成一个系统调用函数,所以要在 kernel/system_call.s 中编写。
switch_to 完整代码:
.align 2
switch_to:
//因为该汇编函数要在c语言中调用,所以要先在汇编中处理栈帧
pushl %ebp
movl %esp,%ebp
pushl %ecx
pushl %ebx
pushl %eax
//将ebp+8指向的数据(目标进程的PCB)传递给ebx,然后进行判断:
//如果目标进程的pcb <<等于>> 当前进程的pcb => 不需要进行切换,直接退出函数调用
//如果目标进程的pcb <<不等于>> 当前进程的pcb => 需要进行切换,直接跳到下面去执行
movl 8(%ebp),%ebx
cmpl %ebx,current
je 1f
/** 执行到此处,就要进行真正的基于堆栈的进程切换了 **/
// 切换PCB
movl %ebx,%eax
xchgl %eax,current
// 重写TSS中内核栈的指针
movl tss,%ecx
addl $4096,%ebx
movl %ebx,ESP0(%ecx)
// 切换内核栈
movl %esp,KERNEL_STACK(%eax)
movl 8(%ebp),%ebx
movl KERNEL_STACK(%ebx),%esp
// 切换LDT
movl 12(%ebp),%ecx
lldt %cx
// 切换 LDT 之后
movl $0x17,%ecx
mov %cx,%fs
// 这一段先不用管
cmpl %eax,last_task_used_math
jne 1f
clts
// 现在进入新进程的内核栈工作了,所以接下来做的四次弹栈以及ret处理使用的都是新进程内核栈中的东西
1: popl %eax
popl %ebx
popl %ecx
popl %ebp
ret以上代码添加到 system_call.s 中最后位置即可(即 parallel_interrupt 之后),如下图所示:
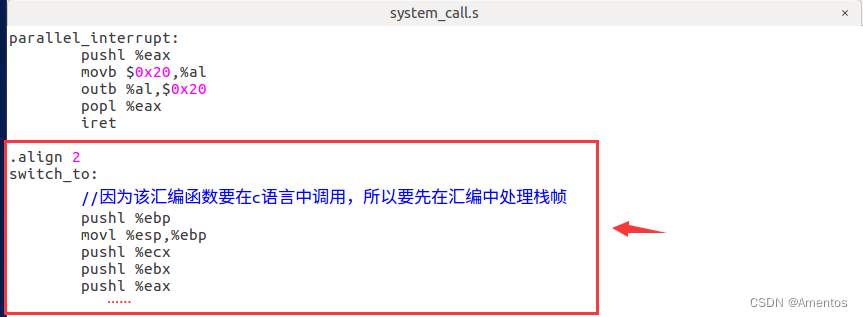
【3】switch_to 代码分析
《操作系统》by李治军 | 实验5.pre - switch_to 汇编代码详解_Amentos的博客-CSDN博客
建议先看看这篇文章再继续。
【4】添加对应变量定义和宏定义
① tss
虽然此时不使用 TSS 进行进程切换了,但是 Intel 的中断处理机制还是要保持的。switch_to 代码中使用了 tss 来作为所有进程的 TSS(这里使用 0 号进程的 TSS),因此需要定义一个全局指针变量 tss 来指向那一段 0 号进程的 TSS 内存(在 sched.c 中定义):
struct tss_struct *tss = &(init_task.task.tss);添加到如下位置即可:

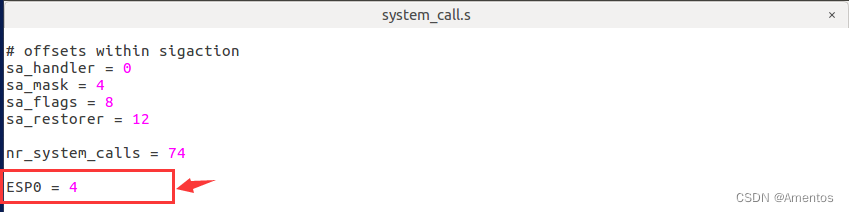
② ESP0
ESP0 定义为 4 ,添加在 system_call.s 中(至于为什么是 4 看看 TSS 的结构体定义就明白了):
(二)修改 PCB
Linux 0.11 中的 PCB 即 task_struct 结构,因为我们添加的堆栈切换使用到了 PCB 中的内容(即内核栈指针域)来进行内核栈的切换,但是在 Linux 0.11 原本的 PCB 中是没有这个域的。所以对应要增加相应的内容域,同时要处理由于修改了 task_struct 所造成的影响。
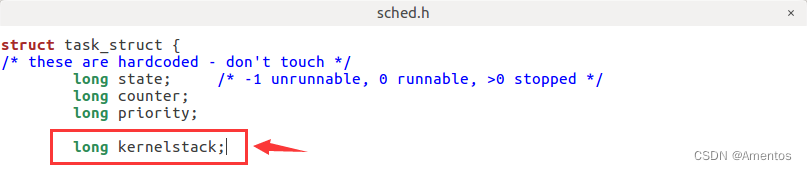
【1】添加内核栈指针域 kernelstack
Linux 0.11 中 PCB 的定义里并没有用于保存内核栈指针的域(kernelstack),但是在 switch_to 中的内核栈切换模块使用到了这个域,所以需要我们自己在 PCB 结构定义中找位置加上这个定义。
Linux 0.11 的 PCB 就是 task_struct 结构(在 include/linux/sched.h 中定义),需要在其中添加一个 kernelstack 作为内核栈指针域。当然将 kernelstack 域加在 task_struct 中的哪个位置都可以,但是在某些汇编文件中(主要是在 kernel/system_call.s 中)有关于操作这个结构的汇编硬编码,所以一旦增加了 kernelstack,这些硬编码也需要跟着修改。
由于第一个位置,即 long state 出现的汇编硬编码很多,所以 kernelstack 千万不要放置在 task_struct 中的第一个位置(不然修改起来非常麻烦)。当放在除第一个位置外的其他位置时,只需要修改 kernel/system_call.s 中对应硬编码就可以了。
long kernelstack;添加到如下位置即可:
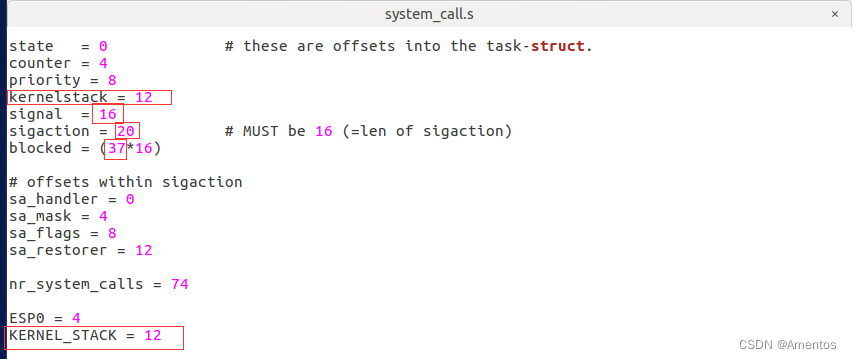
【2】修改硬编码
添加完成后在 system_call.s 中修改汇编硬编码,并添加定义 KERNEL_STACK = 12(为什么是 12 ?因为 kernelstack 添加在第四个位置),修改代码如下:
/* ...... */
state = 0 # these are offsets into the task-struct.
counter = 4
priority = 8
kernelstack = 12
signal = 16
sigaction = 20 # MUST be 16 (=len of sigaction)
blocked = (37*16)
ESP0 = 4
KERNEL_STACK = 12修改情况如下:
【3】添加内核栈指针的初始化
由于我们修改了 PCB 结构体的定义,所以在产生 0 号进程的 PCB 初始化时也要跟着一起变化。需要在 sched.h 中做如下修改,即在 PCB 的第四项(内核栈指针)中增加关于内核栈指针的初始化。
#define INIT_TASK \
/* state etc */ { 0,15,15,PAGE_SIZE+(long)&init_task,\
/* signals */ 0,{{},},0, \
......
}添加情况如下图所示:

(三)修改 fork() 系统调用
-
修改为基于内核栈的切换,所以进程需要创建出能完成内核栈切换的样子
1、如何修改 fork 系统调用
① 修改 fork() 系统调用和书中论述的原理一致,就是要把进程的用户栈、用户程序和其内核栈通过压在内核栈中的 SS:ESP、CS:IP 关联在一起。
② 另外,由于 fork() 这个叉子的含义就是要让父进程和子进程共用同一个代码、数据和堆栈,现在虽然修改成了使用内核栈完成任务切换,但 fork() 的这个基本含义不会发生变化。也就是说基于堆栈的进程切换还是要实现父子进程共用同一个代码、数据和堆栈。
将上面两段描述联立在一起,修改 fork() 的核心工作就是要形成如下图所示的子进程内核栈结构。
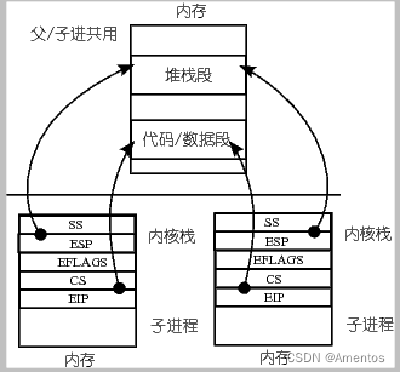
根据上图不难想象,对 fork() 的修改就是对子进程的内核栈的初始化。所以我们要做的就是将新建子进程的内核栈和其父进程的用户栈、用户程序地址关联在一起(因为原来的 TSS 没有做这样的关联,所以要我们自己做),实现父子进程共享同一块内存空间、堆栈和数据代码块。
2、修改 copy_process
fork() 系统调用的代码在 system_call.s 汇编文件中,我们先看看原本的代码:
.align 2
sys_fork:
call find_empty_process
testl %eax,%eax
js 1f
push %gs
pushl %esi
pushl %edi
pushl %ebp
pushl %eax
call copy_process//跳转到copy_process()函数
addl $20,%esp
1: ret可以看出 fork() 函数的核心就是调用 copy_process() ,所以接下来去到 copy_process()(定义在 kernel/fork.c 中),添加代码和注释分析如下:
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,
long ebx,long ecx,long edx,
long fs,long es,long ds,
long eip,long cs,long eflags,long esp,long ss)
{
struct task_struct *p;
int i;
struct file *f;
//用来申请一页内存空间作为子进程的PCB
p = (struct task_struct *) get_free_page();
...
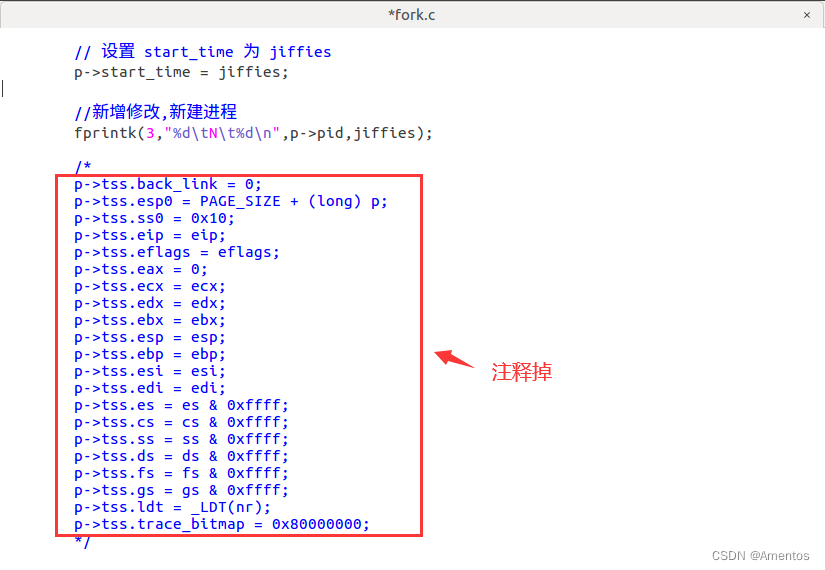
//容易看出下面的部分就是基于tss进程切换机制时的代码,所以要将此片段注释掉
/*
p->tss.back_link = 0;
p->tss.esp0 = PAGE_SIZE + (long) p;
p->tss.ss0 = 0x10;
...
*/
/** 从这里开始添加基于堆栈切换的代码(对fork的修改其实就是对子进程内核栈的初始化 **/
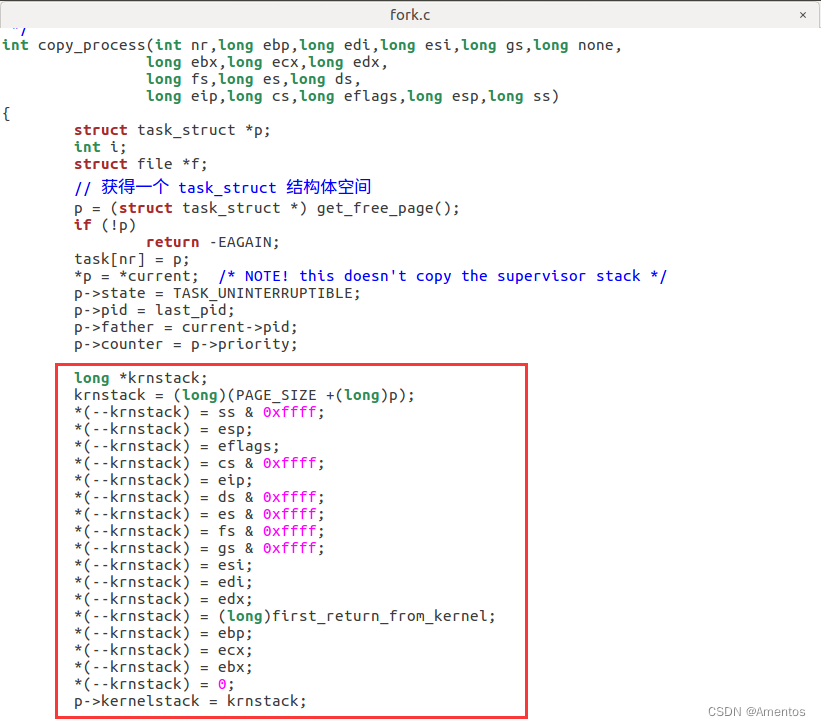
long *krnstack;
//p指针加上页面大小就是子进程的内核栈位置,所以krnstack指向子进程的内核栈
krnstack = (long)(PAGE_SIZE +(long)p);
//现在开始初始化子进程内核栈(krnstack)中的内容:
//下面的五句话可以完成上图所示的关联效果(父子进程共用同一内存、堆栈和数据代码块)
//因为下面的ss,esp,eflags,cs,eip这些参数就是来自调用copy_process()函数的进程的内核栈中
//也就是父进程的内核栈,所以下面5条指令就是将父进程内核栈中的前五个内容拷贝到子进程的内核栈中
*(--krnstack) = ss & 0xffff;
*(--krnstack) = esp;
*(--krnstack) = eflags;
*(--krnstack) = cs & 0xffff;
*(--krnstack) = eip;
*(--krnstack) = ds & 0xffff;
*(--krnstack) = es & 0xffff;
*(--krnstack) = fs & 0xffff;
*(--krnstack) = gs & 0xffff;
*(--krnstack) = esi;
*(--krnstack) = edi;
*(--krnstack) = edx;
//处理switch_to返回的位置,详细解释见下文
*(--krnstack) = (long) first_return_kernel;
//接下来的工作需要和switch_to接在一起考虑
//故事从哪里开始呢?回顾一下前面给出的switch_to,应该从“切换内核栈”完成的那个地方开始
//当时已经切换到子进程的内核栈开始工作,所以switch_to最后的四次弹栈以及ret使用的都是子进程内核栈中的东西
/* switch_to:
...
1: popl %eax
popl %ebx
popl %ecx
popl %ebp
ret
*/
//为了顺利完成上面4条弹栈工作,子进程的内核栈中应该有这些内容
//所以需要对子进程的krnstack进行相应初始化:(下面的ebp,ecx,ebx一样都来自父进程的内核栈)
*(--krnstack) = ebp;
*(--krnstack) = ecx;
*(--krnstack) = ebx;
*(--krnstack) = 0;
//这里为啥是0而不继续继承父进程的eax呢?
//这里的eax就是进程的返回值,也是子进程和父进程的不同之处
//父进程返回子进程的pid,子进程返回0
//最后别忘了,由于我们初始化了子进程的内核栈,栈顶指针也变了
//所以要更新存放在PCB中对应的内核栈指针:
p->kernelstack = krnstack;
...【1】删除 TSS 进程切换片段
【2】添加子进程内核栈初始化代码
添加情况如图所示:
3、first_return_kernel
注意 switch_to 最后还有一条 ret 指令,这条指令就是要从内核栈中弹出一个 32 位数作为 EIP 并跳转去执行。所以需要一个函数地址(仍然是一段汇编程序,所以这个函数地址就是这段汇编程序开始处的标号)并将其初始化到栈中。我们使用一个名为 first_return_kernel 的汇编标号,然后通过 *(--krnstack) = (long) first_return_kernel; 将这个地址初始化到子进程的内核栈中。之后执行 ret 就会跳转到 first_return_kernel 处去执行了。
ps:根据栈先进后出的特点,注意 *(--krnstack) = (long) first_return_kernel; 添加的位置。
现在我们想一想 first_return_kernel 要完成什么工作?PCB、内核栈、LDT 都已经切换完成,所以就剩下 “内核级线程切换五段论” 中的最后一段切换了 —— 用户栈和用户代码的切换,依靠的核心指令就是 iret 。
所以这个 first_return_kernel 就是通过 iret 完成用户栈和用户代码的切换。当然在 iret 切换之前应该恢复一下执行现场,主要就是 eax、ebx、ecx、edx、esi、gs、fs、es、ds 这些寄存器的恢复。
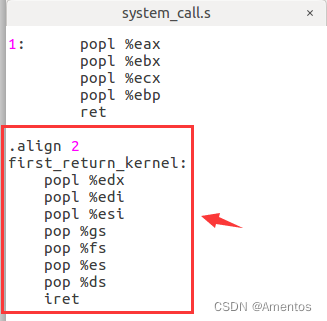
【1】添加 first_return_kernel 函数
将 first_return_kernel 具体的函数实现放在 system_call.s 里面(添加到 switch_to 后即可):
.align 2
first_return_kernel:
popl %edx
popl %edi
popl %esi
pop %gs
pop %fs
pop %es
pop %ds
iret添加情况如下图:
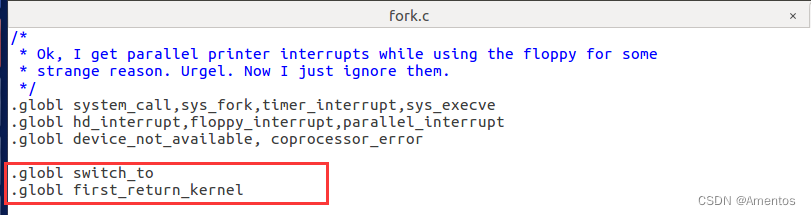
【2】设置 first_return_kernel 全局可见
还需要将 first_return_kernel 在 fork.c 中设置为全局可见(switch_to 也可以设置一下),这样才能在 fork.c 中使用 first_return_kernel。
.globl switch_to
.globl first_return_kernel添加情况如下图:
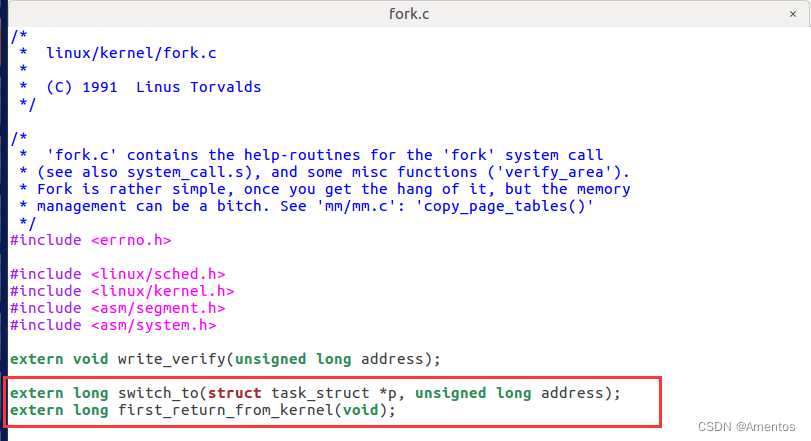
【3】添加函数声明
最后要记得,因为在 fork.c 中使用了 system_call.s 中的 first_return_kernel 和 switch_to 函数,所以要在 fork.c 里添加对应的外部函数声明:
extern long switch_to(struct task_struct *p, unsigned long address);
extern long first_return_from_kernel(void);添加到如下位置即可:
(四)编译运行新的 Linux 0.11
由于我们修改了 Linux 0.11 的内核,所以要重新编译系统。
// linux-0.11 目录下运行
make all进入 Linux 0.11
// oslab 目录下
./run运行结果:
正常运行!
(五)分析实验 4 的日志,体会修改前后系统运行的差别
在新修改的 Linux 0.11 系统中运行实验 4 的样本程序 process.c,统计同样的时间数据,得到新的 process.log ,接着运行统计脚本 stat_log.py 分析新的 log 文件,和 Linux 0.11 原来的 TSS 情况进行对比,体会不同切换手段带来的差异。
1、运行 process.c
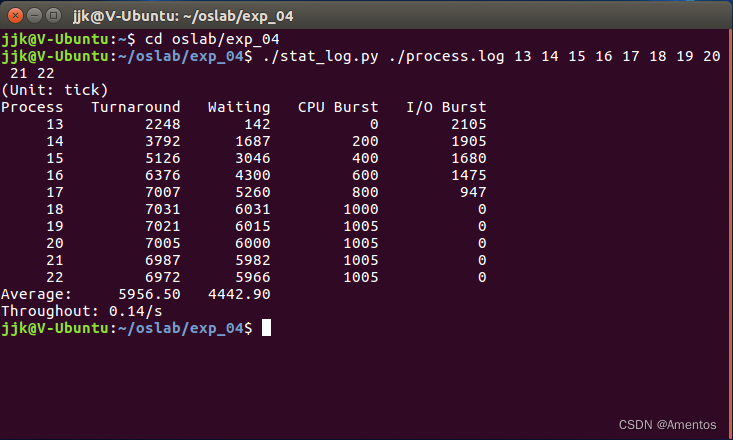
2、分析 log 文件,统计数据
3、TSS 和堆栈切换的差异
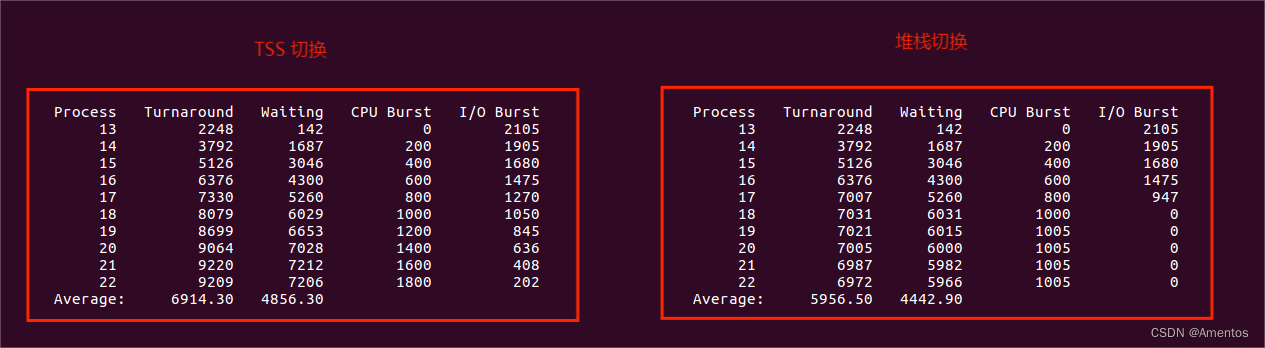
可以看出基于堆栈的进程切换比基于 TSS 的进程切换的平均周转时间和平均等待时间更低。