文章目录
- 一、TSNE是什么?
- 二、使用步骤
- 1.引入库 from sklearn.manifold import TSNE
- 2.参数详细说明
一、TSNE是什么?
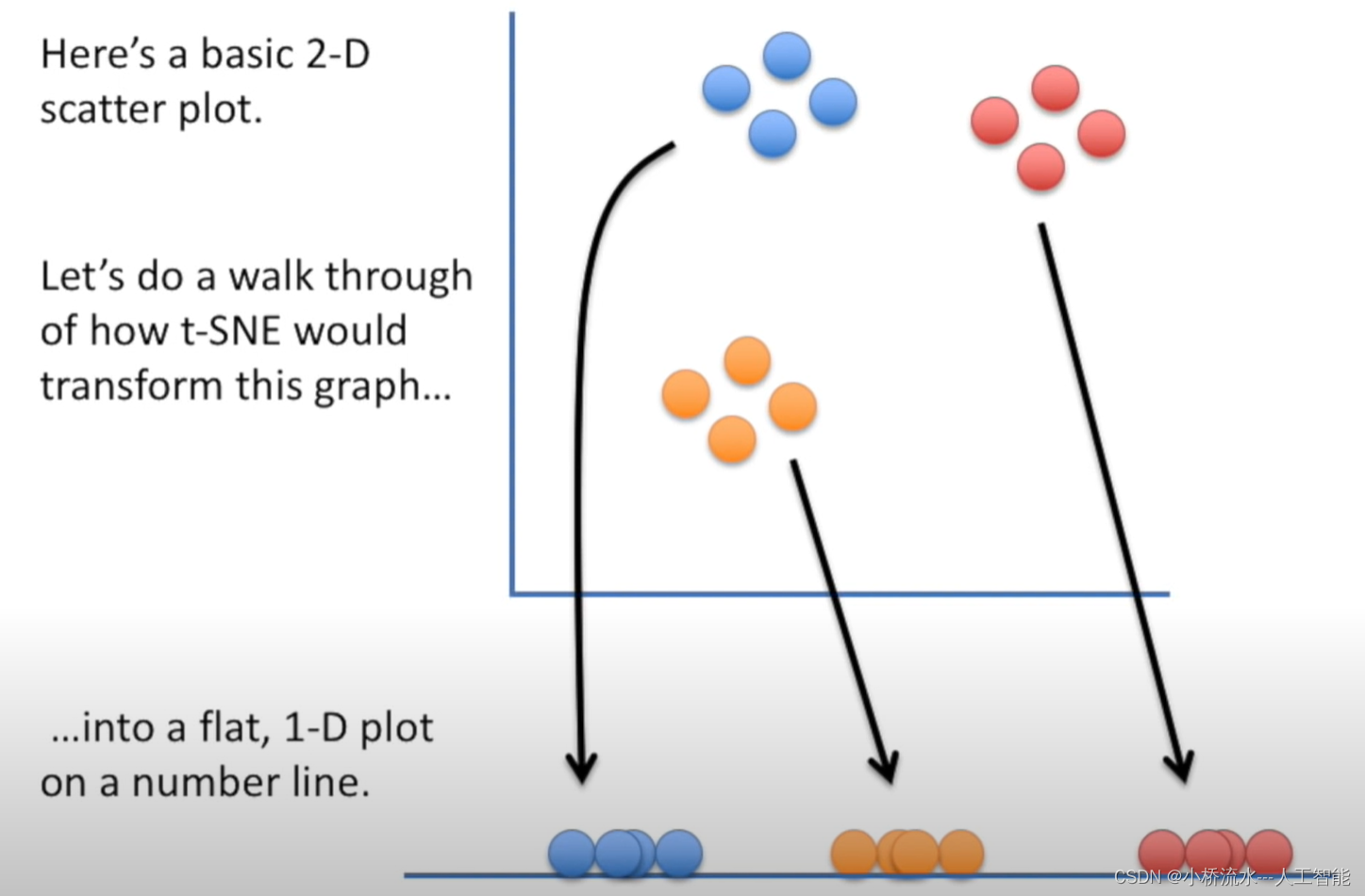
TSNE(t-Distributed Stochastic Neighbor Embedding)是一种非线性降维技术,主要用于高维数据的可视化。它是一种基于概率的技术,可以对数据进行降维,并将数据的高维结构映射到低维空间中,保留数据之间的相似性关系。TSNE 根据高维数据点之间的相似度计算它们之间的距离并生成一组新的坐标,使得每个数据点在新的低维空间中都能够更清晰地显示其在原始高维空间中的关系。通过使用TSNE,可以更好地理解数据之间的关系,并发现其中的模式和结构。
二、使用步骤
1.引入库 from sklearn.manifold import TSNE
from sklearn.manifold import TSNE 是一个 Python 中的 Scikit-learn 函数库,用于执行 TSNE 算法,即使用 t-Distributed Stochastic Neighbor Embedding 进行数据降维。Scikit-learn 是一个流行的、免费的 Python 函数库,它包含了许多用于机器学习、数据分析和数据可视化的函数。manifold 模块包括了一系列可用于数据降维的算法,包括 PCA、MDS、TSNE 等。其中的 TSNE 具有许多可调节的参数,包括 perplexity、learning rate、n_iter 和 random state 等,这些参数都可以使得 TSNE 的输出更加适合使用者的需求。
from sklearn.manifold import TSNE
2.参数详细说明
- n_components: 降维后的特征空间维度,通常为2维或3维。取值范围为1-100之间的整数。
- perplexity: 是t-SNE中一个重要的参数,表示t-SNE算法考虑邻近点的多少。在大多数情况下,此参数的推荐值为5到50之间。如果数据集较大,通常使用较大的值。如果这个值太小,可能会导致过度拟合,而太大则可能导致缺少局部结构。
- learning_rate: 学习率决定在t-SNE算法优化过程中更新样本间距离的速度。默认值为200,通常在50到1000之间选择。学习率对降维结果具有较大影响,如果学习率过小,则算法每次更新时会有过度存在的飞跃现象;如果学习率过大,则很容易导致数据处于不稳定状态。
- random_state: 设为固定值可以保证多次执行tsne时结果一致。取值范围是正整数或者None,如果是None则保证每次随机。







![[Java Web]Cookie,Session,Filter,Listener,Thymeleaf模板](https://img-blog.csdnimg.cn/img_convert/c27acf2ff074f54e616d939116e4af8b.png)