1.摘要
在低光条件下拍摄的照片会因曝光不足而产生一系列的视觉问题,如亮度低、信息丢失、噪声和颜色失真等。为了解决上述问题,提出一个结合注意力的双分支残差低光照图像增强网络。首先,采用改进InceptionV2提取浅层特征;其次,使用残差特征提取块(RFB)和稠密残差特征提取块(DRFB)提取深层特征;然后,融合浅层和深层特征,并将融合结果输入亮度调整块(BAM)调整亮度,最终得到增强图像,该模型整体命名为双分支残差网络(Dual-branch Residual Network for lowlight image enhancement, DR-Net)。实验结果表明,在LOL(LOw-Light)数据集上,所实现的网络模型能够在提高低光照图像亮度的同时降低噪声,减少了颜色失真和伪影,得到的增强图像更加清晰自然。
2.数据集介绍
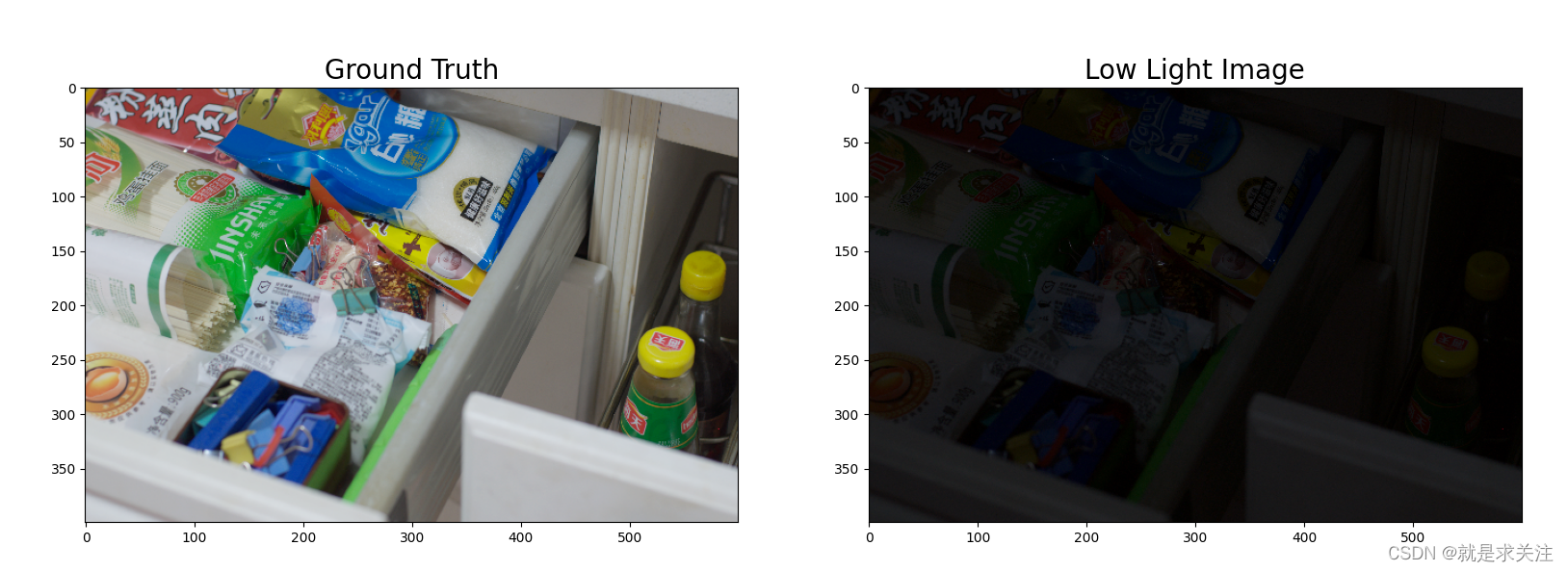
LOL数据集是用于低光照图像增强的一个常用数据集。它是由Yue et al.在2015年发布的,用于评估低光照图像增强算法的性能。LOL数据集包含485对低光照图像和对应的正常光图像。每对图像都是在相同的场景下采集的,其中一张图像是低光照条件下的原始图像,另一张是由人工调整亮度和对比度后的正常光图像。LOL数据集的图像覆盖了各种场景和对象,包括室内和室外环境、自然风景、人物肖像等。这使得LOL数据集成为评估低光照图像增强算法的重要基准。数据展示如下:
3.模型设计与实现
设计了用于低光照图像增强的双分支残差网络(Dual-branch Residual Network for lowlight image enhancement, DR-Net)。 该 网 络 采 用 改 进InceptionV2提取浅层特征,使用残差特征提取块(Residual Feature extraction Block, RFB)和 残 差 稠 密 特 征 提 取 块(Dense RFB,DRFB)两个分支进一步提取深层特征,然后将得到的特征信息融合,解决了图像细节丢失和偏色的问题。再 将 融 合 结 果 送 入 亮 度 调 整 块(Brightness AdjustmentModule, BAM)进行增亮调节,最终得到正常光图像。DRA-Net的结构如图所示,主要由浅层特征提取、深层特征提取、特征融合和亮度调整这 4个部分组成。

实现的代码如下:
# 定义DR-Net网络结构
inputs = keras.Input(shape=(None, None, 3), name='img')
# 浅层特征提取,使用改进InceptionV2
x = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(inputs)
x = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(x)
# 残差特征提取块(RFB)
rfb = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(x)
rfb = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(rfb)
rfb = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(rfb)
# 残差稠密特征提取块(DRFB)
drfb = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(x)
drfb = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(drfb)
drfb = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(drfb)
drfb = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(drfb)
# 特征融合块(FFM)
ffm = layers.Concatenate()([rfb, drfb])
ffm = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(ffm)
ffm = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(ffm)
# BAM块
bam = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(ffm)
bam = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(bam)
bam = layers.Conv2D(3, (3, 3), strides=(1, 1), padding='same', activation='relu')(bam)
outputs = layers.Add()([inputs, bam])
# 创建DR-Net模型
model = keras.Model(inputs, outputs)下面是代码的详细解释:
-
定义输入层:使用
keras.Input创建一个输入层,输入的形状为(None, None, 3),表示任意大小的RGB图像。 -
浅层特征提取(Improved InceptionV2):通过三个卷积层,分别使用64个3x3的卷积核和ReLU激活函数,对输入进行特征提取。这一部分用于提取图像的浅层特征。
-
残差特征提取块(RFB):这是一个残差结构,通过三个卷积层,每个卷积层使用64个3x3的卷积核和ReLU激活函数,对浅层特征进行进一步的特征提取。
-
残差稠密特征提取块(DRFB):类似于RFB块,这也是一个残差结构,通过四个卷积层,每个卷积层使用64个3x3的卷积核和ReLU激活函数,对浅层特征进行更深层次的特征提取。
-
特征融合块(FFM):使用Concatenate层将RFB块和DRFB块的特征进行融合,然后通过两个卷积层,每个卷积层使用64个3x3的卷积核和ReLU激活函数,进一步提取融合后的特征。
-
BAM块(Brightness Adjustment Module):通过三个卷积层,分别使用64个3x3的卷积核和ReLU激活函数,对特征进行亮度调整。
-
输出层:使用Add层将输入层和BAM块的输出相加,得到最终的增强图像。
-
创建模型:使用
keras.Model创建DR-Net模型,指定输入层和输出层。
在LOL数据集上的实验过程如下:
Epoch 1/20
24/24 [==============================] - 1s 21ms/step - loss: 0.1123
Epoch 2/20
24/24 [==============================] - 1s 21ms/step - loss: 0.0591
Epoch 3/20
24/24 [==============================] - 0s 21ms/step - loss: 0.0442
Epoch 4/20
24/24 [==============================] - 1s 21ms/step - loss: 0.0570
Epoch 5/20
24/24 [==============================] - 1s 21ms/step - loss: 0.0540
Epoch 6/20
24/24 [==============================] - 0s 21ms/step - loss: 0.0467
Epoch 7/20
24/24 [==============================] - 1s 22ms/step - loss: 0.1179
Epoch 8/20
24/24 [==============================] - 1s 22ms/step - loss: 0.0477
Epoch 9/20
24/24 [==============================] - 0s 21ms/step - loss: 0.0414
Epoch 10/20
24/24 [==============================] - 1s 21ms/step - loss: 0.0227
Epoch 11/20
24/24 [==============================] - 1s 21ms/step - loss: 0.0387
Epoch 12/20
24/24 [==============================] - 0s 21ms/step - loss: 0.0550
Epoch 13/20
24/24 [==============================] - 1s 22ms/step - loss: 0.0324
Epoch 14/20
24/24 [==============================] - 1s 21ms/step - loss: 0.0386
Epoch 15/20
24/24 [==============================] - 1s 21ms/step - loss: 0.0215
Epoch 16/20
24/24 [==============================] - 1s 21ms/step - loss: 0.0166
Epoch 17/20
24/24 [==============================] - 1s 21ms/step - loss: 0.0187
Epoch 18/20
24/24 [==============================] - 0s 21ms/step - loss: 0.0223
Epoch 19/20
24/24 [==============================] - 1s 21ms/step - loss: 0.0285
Epoch 20/20
24/24 [==============================] - 1s 21ms/step - loss: 0.02274.应用展示
实现了一个基于GUI的图像增强应用程序。使用load_model函数加载预先训练好的模型文件('model.h5'),该模型用于图像增强。通过模型对图像进行预测,并根据预测结果和输入图像进行像素级别的操作,以实现增强效果。
完成的用户展示界面实现了一个用户友好的图像增强应用程序,用户可以通过界面上传图像文件并进行低光照图像增强操作。应用程序使用预训练的模型进行图像增强,并提供保存增强后图像和重新选择图像的功能。整个应用程序的逻辑由GUI界面和代码实现之间的交互完成。
其界面如下:
上传一个低光照的图像:
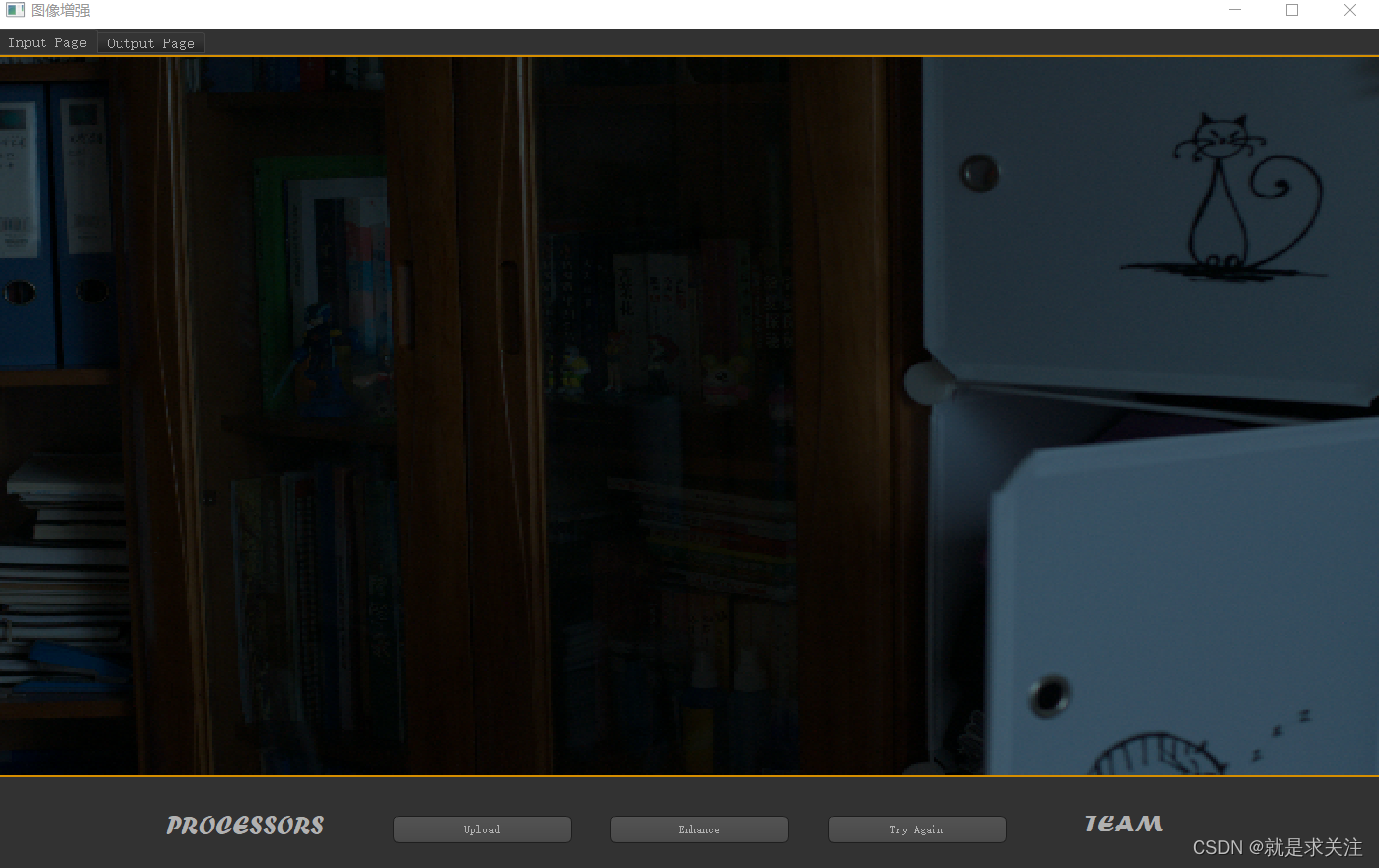
开始进行图像亮度增强,输出结果为:

5.总结
该内容介绍了图像增强算法——双分支残差网络(DR-Net),用于解决低光照图像的亮度低、颜色失真和信息丢失等问题。以下是论文的主要贡献和实验结果:
-
算法结构:DR-Net采用了改进的InceptionV2与双分支残差来提取特征信息。浅层特征提取使用改进的InceptionV2,深层特征提取使用残差特征提取块(RFB)和残差稠密特征提取块(DRFB)。特征融合块(FFM)用于捕获和融合重要特征。亮度调整块(BAM)用于调整图像亮度。
-
实验结果:作者在真实低光照和合成低光照图像上进行了对比实验。实验结果表明,DR-Net算法在增加图像亮度、还原图像颜色和减少噪声方面都优于其他对比算法。无论是在主观视觉效果还是客观评价指标上,DR-Net都表现出较好的性能。
-
应用实现:使用
load_model函数加载预先训练好的模型文件('model.h5'),完成的用户展示界面实现了一个用户友好的图像增强应用程序,用户可以通过界面上传图像文件并进行低光照图像增强操作。 -
未来展望:作者提出了进一步优化网络结构和扩充数据集的研究方向,以进一步提高低光照图像增强算法的性能。
总的来说,该内容提出的DR-Net算法通过结合改进的InceptionV2、双分支残差、特征融合和亮度调整等模块,有效解决了低光照图像的亮度、颜色和噪声等问题,并在实验中展现了良好的性能。未来的研究方向包括网络结构优化和数据集扩充,以进一步提升算法的性能。
完整代码链接:
https://download.csdn.net/download/weixin_40651515/87850091

![[Java Web]Cookie,Session,Filter,Listener,Thymeleaf模板](https://img-blog.csdnimg.cn/img_convert/c27acf2ff074f54e616d939116e4af8b.png)



![[bugfix]解决visual studio installer双击后进度条一闪而过之后无反应的问题](https://img-blog.csdnimg.cn/0b55ed9a1190425c943883b51da270bd.png)