A2A 协议的高级应用与优化
学习目标
-
掌握 A2A 高级功能
- 理解多用户支持机制
- 掌握长期任务管理方法
- 学习服务性能优化技巧
-
理解与 MCP 的差异
- 分析多智能体场景下的优势
- 掌握不同场景的选择策略
第一部分:多用户支持机制
1. 用户隔离架构
2. 资源管理实现
class UserResourceManager:
def __init__(self):
self.quotas = {}
self.usage = {}
def allocate_resources(self, user_id: str, request: dict) -> bool:
"""分配用户资源"""
quota = self.quotas.get(user_id, {})
current_usage = self.usage.get(user_id, {})
# 检查资源配额
if not self._check_quota(quota, current_usage, request):
return False
# 更新资源使用
self._update_usage(user_id, request)
return True
def _check_quota(self, quota: dict, usage: dict, request: dict) -> bool:
"""检查资源配额"""
for resource, amount in request.items():
if usage.get(resource, 0) + amount > quota.get(resource, 0):
return False
return True
第二部分:长期任务管理
1. 任务生命周期
2. 进度跟踪实现
class LongRunningTaskManager:
def __init__(self):
self.tasks = {}
self.checkpoints = {}
async def track_progress(self, task_id: str):
"""跟踪任务进度"""
task = self.tasks[task_id]
while not task.is_completed:
progress = await self._get_task_progress(task_id)
self._update_progress(task_id, progress)
if self._should_checkpoint(progress):
await self._save_checkpoint(task_id)
await asyncio.sleep(self.check_interval)
async def resume_task(self, task_id: str):
"""恢复任务执行"""
checkpoint = self.checkpoints.get(task_id)
if checkpoint:
return await self._restore_from_checkpoint(task_id, checkpoint)
return await self._start_new_task(task_id)
第三部分:服务优化
1. 数据传输优化
class OptimizedDataTransfer:
def __init__(self):
self.compression = True
self.batch_size = 1000
self.cache = LRUCache(maxsize=1000)
async def send_data(self, data: Any, recipient: str):
"""优化数据传输"""
# 1. 检查缓存
if cached := self.cache.get(self._get_cache_key(data)):
return await self._send_cached_data(cached, recipient)
# 2. 数据压缩
if self.compression:
data = self._compress_data(data)
# 3. 批量发送
if self._should_batch(data):
return await self._batch_send(data, recipient)
# 4. 直接发送
return await self._direct_send(data, recipient)
2. 任务调度优化
class OptimizedTaskScheduler:
def __init__(self):
self.task_queue = PriorityQueue()
self.agent_pool = AgentPool()
self.performance_metrics = {}
async def schedule_task(self, task: Task):
"""优化任务调度"""
# 1. 任务优先级评估
priority = self._evaluate_priority(task)
# 2. 负载均衡
available_agents = self._get_available_agents()
best_agent = self._select_optimal_agent(available_agents, task)
# 3. 资源预留
if not await self._reserve_resources(best_agent, task):
return await self._handle_resource_conflict(task)
# 4. 任务分配
return await self._assign_task(best_agent, task)
def _select_optimal_agent(self, agents: List[Agent], task: Task) -> Agent:
"""选择最优执行智能体"""
scores = {}
for agent in agents:
# 计算得分
performance_score = self._get_performance_score(agent)
capability_score = self._get_capability_match_score(agent, task)
load_score = self._get_load_score(agent)
# 综合评分
scores[agent.id] = (
performance_score * 0.4 +
capability_score * 0.4 +
load_score * 0.2
)
return max(agents, key=lambda a: scores[a.id])
第四部分:MCP 与 A2A 对比
1. 场景差异分析
| 特性 | MCP | A2A |
|---|---|---|
| 上下文管理 | 丰富的单智能体上下文 | 分布式多智能体上下文 |
| 扩展性 | 单智能体能力扩展 | 多智能体动态协作 |
| 资源利用 | 集中式资源分配 | 分布式资源调度 |
| 任务处理 | 同步处理为主 | 支持异步和长期任务 |
| 适用场景 | 复杂单任务处理 | 分布式协作任务 |
2. 选择策略
class ArchitectureSelector:
def select_architecture(self, requirements: dict) -> str:
"""选择合适的架构"""
scores = {
'mcp': 0,
'a2a': 0
}
# 评估关键因素
if requirements.get('multi_agent_collaboration'):
scores['a2a'] += 3
if requirements.get('rich_context_needed'):
scores['mcp'] += 3
if requirements.get('scalability_needed'):
scores['a2a'] += 2
if requirements.get('async_processing'):
scores['a2a'] += 2
return 'a2a' if scores['a2a'] > scores['mcp'] else 'mcp'
第五部分:最佳实践
1. 性能优化建议
-
数据传输优化
- 使用数据压缩
- 实现批量处理
- 采用缓存机制
- 优化序列化方式
-
资源管理优化
- 实现动态资源分配
- 使用资源预留机制
- 优化负载均衡策略
- 实现自动扩缩容
-
任务调度优化
- 优化任务优先级
- 实现智能负载均衡
- 支持任务预热
- 优化任务队列管理
2. 监控指标
class PerformanceMonitor:
def __init__(self):
self.metrics = {
# 系统指标
'system': {
'cpu_usage': Gauge('cpu_usage', 'CPU usage percentage'),
'memory_usage': Gauge('memory_usage', 'Memory usage percentage'),
'network_io': Counter('network_io', 'Network I/O bytes')
},
# 任务指标
'task': {
'processing_time': Histogram('task_processing_time', 'Task processing time'),
'queue_length': Gauge('task_queue_length', 'Task queue length'),
'success_rate': Counter('task_success_rate', 'Task success rate')
},
# 智能体指标
'agent': {
'response_time': Histogram('agent_response_time', 'Agent response time'),
'error_rate': Counter('agent_error_rate', 'Agent error rate'),
'availability': Gauge('agent_availability', 'Agent availability')
}
}
学习资源
1. 技术文档
- A2A 协议规范
- 性能优化指南
- 最佳实践手册
2. 示例代码
- GitHub 示例项目
- 性能测试用例
- 优化实践示例
3. 社区资源
- 技术博客
- 开发者论坛
- 问答平台
第六部分:高级流程详解
1. 多用户任务处理流程
2. 长期任务状态转换
3. 优化后的数据流转过程
4. 智能负载均衡策略
5. 故障恢复流程
流程说明
-
多用户任务处理流程
- 用户请求通过负载均衡器进入系统
- 命名空间管理器确保用户隔离
- 资源管理器进行配额控制
- 任务管理器负责全生命周期管理
-
长期任务状态转换
- 完整展示了任务从创建到完成的所有可能状态
- 包含了执行过程中的检查点机制
- 支持任务暂停和恢复
- 实现了失败重试机制
-
优化后的数据流转过程
- 数据预处理和压缩优化
- 批处理和缓存机制
- 并行处理架构
- 结果聚合和存储
-
智能负载均衡策略
- 实时性能指标收集
- 动态权重调整
- 多维度负载评估
- 自适应任务分发
-
故障恢复流程
- 定期健康检查
- 检查点恢复机制
- 资源动态调整
- 任务状态恢复
实现建议
-
性能优化
class PerformanceOptimizer: def optimize_data_flow(self, data_stream): # 1. 数据压缩 compressed_data = self._compress(data_stream) # 2. 批量处理 batches = self._create_batches(compressed_data) # 3. 缓存处理 cached_results = self._process_with_cache(batches) # 4. 并行处理 final_results = self._parallel_process(cached_results) return final_results -
故障恢复
class FaultTolerance: def handle_failure(self, agent_id: str): # 1. 保存检查点 checkpoint = self._save_checkpoint(agent_id) # 2. 分配新资源 new_agent = self._allocate_new_agent() # 3. 恢复状态 self._restore_state(new_agent, checkpoint) # 4. 恢复执行 self._resume_execution(new_agent)
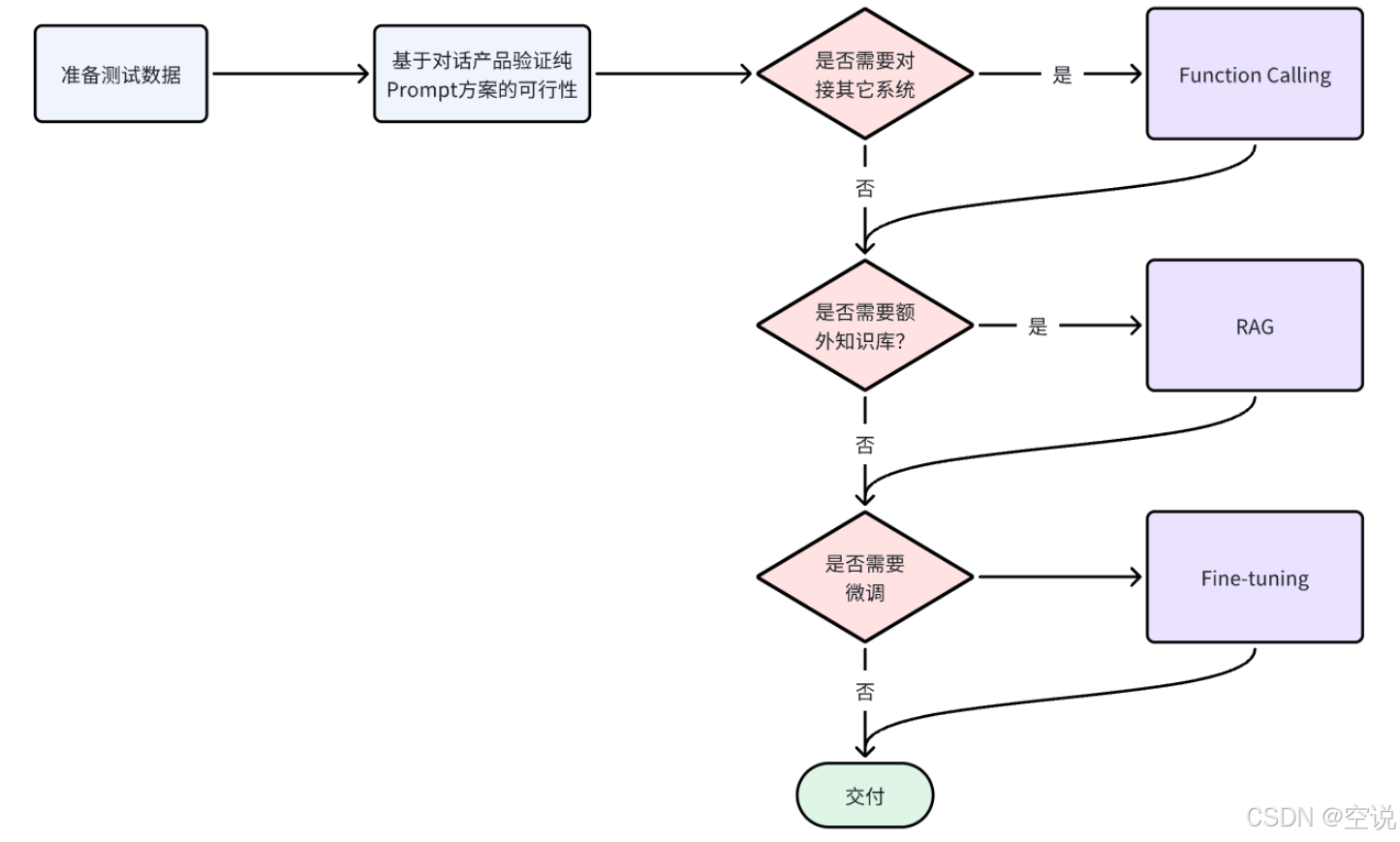
这些流程图和实现建议提供了更详细的系统运行机制说明,有助于理解A2A协议的高级特性和优化方案。每个流程都配有详细的说明和相应的实现建议,便于实际开发参考。




![STM32单片机入门学习——第40节: [11-5] 硬件SPI读写W25Q64](https://i-blog.csdnimg.cn/direct/a8d908602f5a417ba564991076396886.png)