Buffer Pool
在MySQL服务器启动的时候就向操作系统申请了⼀⽚连续的内存,他们给这⽚内存起了个名,叫做Buffer Pool(中⽂名
是缓冲池)。
默认情况下Buffer Pool只有128M⼤⼩,最⼩值为5M,通过修改配置文件设置其大小(256M):
[server]
innodb_buffer_pool_size = 268435456
Buffer Pool内部组成
Buffer Pool中默认的缓存⻚⼤⼩和在磁盘上默认的⻚⼤⼩是⼀样的,都是16KB。为了更好的管理这些在Buffer Pool中的缓存⻚,设计InnoDB的为每⼀个缓存⻚都创建了⼀些所谓的控制信息,这些控制信息包括该⻚所属的表空间编号、⻚号、缓存⻚在Buffer Pool中的地址、链表节点信息、⼀些锁信息以及LSN信息。
每个缓存⻚对应的控制信息占⽤的内存⼤⼩是相同的,每个⻚对应的控制信息占⽤的⼀块内存称为⼀个控制块吧,控制块和缓存⻚是⼀⼀对应的,它们都被存放到 Buffer Pool 中,其中控制块被存放到 Buffer Pool 的前边,缓存⻚被存放到 Buffer Pool 后边,所以整个Buffer Pool对应的内存空间。
每⼀个控制块都对应⼀个缓存⻚,那在分配⾜够多的控制块和缓存⻚后,可能剩余的那点⼉空间不够⼀对控制块和缓存⻚的⼤⼩,这个⽤不到的那点⼉内存空间就被称为碎⽚了

free链表的管理
把所有空闲的缓存⻚对应的控制块作为⼀个节点放到⼀个链表中,这个链表也可以被称作free链表,如下:

每当需要从磁盘中加载⼀个⻚到Buffer Pool中时,就从free链表中取⼀个空闲的缓存⻚,并且把该缓存⻚对应的控制块的信息填上(就是该⻚所在的表空间、⻚号之类的信息),然后把该缓存⻚对应的free链表节点从链表中移除,表示该缓存⻚已经被使⽤了。
缓存页的哈希处理
当我们需要访问某个⻚中的数据时,就会把该⻚从磁盘加载到Buffer Pool中,⽤表空间号 + ⻚号作为key,缓存⻚作为value创建⼀个哈希表,在需要访问某个⻚的数据时,先从哈希表中根据表空间号 + ⻚号看看有没有对应的缓存⻚,如果有,直接使⽤该缓存⻚就好,如果没有,那就从free链表中选⼀个空闲的缓存⻚,然后把磁盘中对应的⻚加载到该缓存⻚的位置。
flush链表的管理
如果我们修改了Buffer Pool中某个缓存⻚的数据,那它就和磁盘上的⻚不⼀致了,这样的缓存⻚也被称为脏页(英⽂名:dirty page)。
凡是修改过的缓存⻚对应的控制块都会作为⼀个节点加⼊到⼀个链表中,因为这个链表节点对应的缓存⻚都是需要被刷新到磁盘上的,所以也叫flush链表。链表的构造和free链表差不多,假设某个时间点Buffer Pool中的脏⻚数量为n。
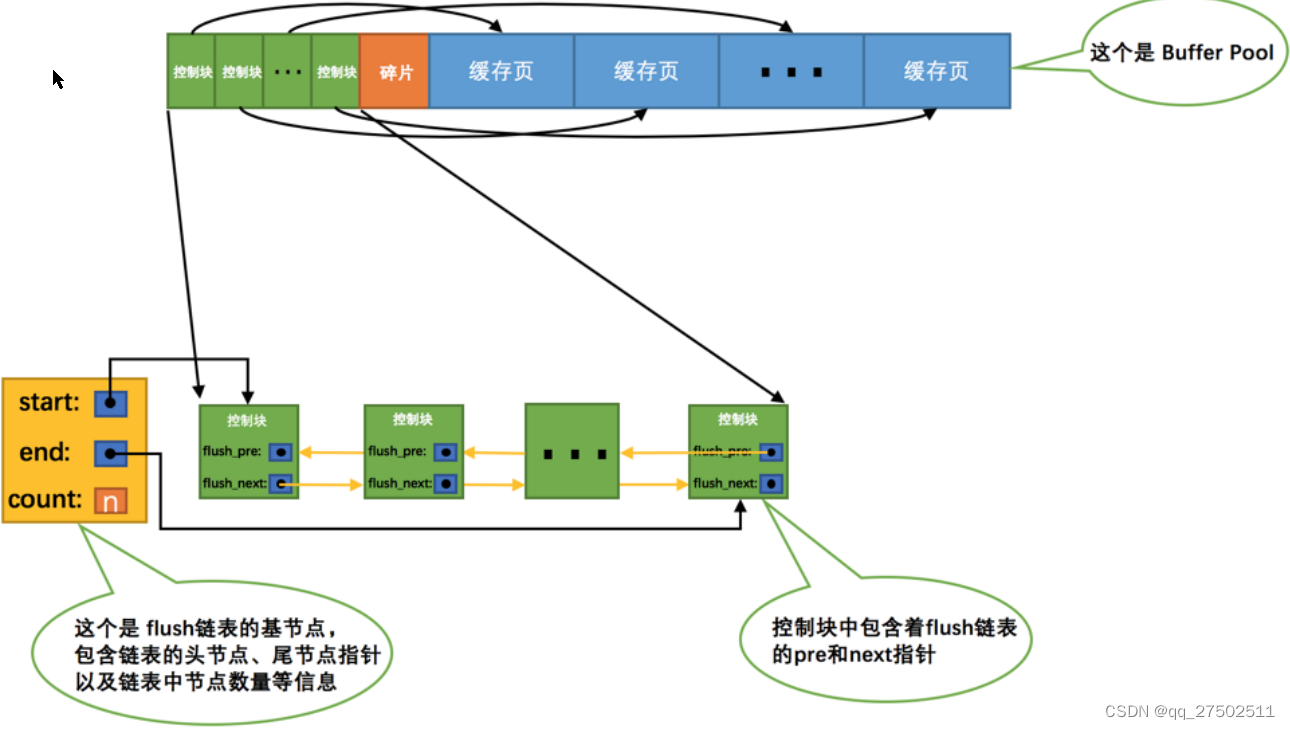
LRU链表的管理
当Buffer Pool中不再有空闲的缓存⻚时,就需要淘汰掉部分最近很少使⽤的缓存⻚。
简单的LRU链表
只要我们使⽤到某个缓存⻚,就把该缓存⻚调整到LRU链表的头部,这样LRU链表尾部就是最近最少使⽤的缓存⻚。
划分区域的LRU链表
⼀部分存储使⽤频率⾮常⾼的缓存⻚,所以这⼀部分链表也叫做热数据,或者称young区域。
另⼀部分存储使⽤频率不是很⾼的缓存⻚,所以这⼀部分链表也叫做冷数据,或者称old区域。
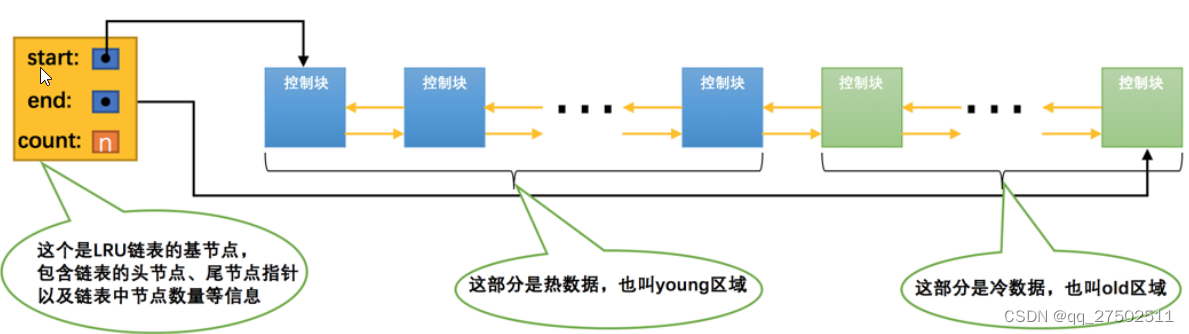
young和old可以修改“innodb_old_blocks_pct”进行调整连个区的比例。
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_pct';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_old_blocks_pct | 37 |
+-----------------------+-------+
1 row inset (0.01 sec)
这样修改配置⽂件:
[server]
innodb_old_blocks_pct = 40
为了避免只读取一次的数据,占领了young的数据,所以设计一下模式:
在对某个处在old区域的缓存⻚进⾏第⼀次访问时就在它对应的控制块中记录下来这个访问时间,如果后续的访问时间与第⼀次访问的时间在某个时间间隔内,那么该⻚⾯就不会被从old区域移动到young区域的头部,否则将它移动到young区域的头部。上述的这个间隔时间是由系统变量innodb_old_blocks_time控制的。
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_time';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_old_blocks_time | 1000 |
+------------------------+-------+
1 row inset (0.01 sec)
更进⼀步优化LRU链表
对于young区域的缓存⻚来说,我们每次访问⼀个缓存⻚就要把它移动到LRU链表的头部,这样开销有点大了,毕竟在young区域的缓存⻚都是热点数据,也就是可能被经常访问的,这样频繁的对LRU链表进⾏节点移动操作是不是不太好啊?是的,为了解决这个问题其实我们还可以提出⼀些优化策略,⽐如只有被访问的缓存⻚位于young区域的1/4的后边,才会被移动到LRU链表头部,这样就可以降低调整LRU链表的频率,从⽽提升性能(也就是说如果某个缓存⻚对应的节点在young区域的1/4中,再次访问该缓存⻚时也不会将其移动到LRU链表头部)
刷新脏页到磁盘
从LRU链表的冷数据中刷新⼀部分⻚⾯到磁盘。
后台线程会定时从LRU链表尾部开始扫描⼀些⻚⾯,扫描的⻚⾯数量可以通过系统变量innodb_lru_scan_depth来指定,如果从⾥边⼉发现脏⻚,会把它们刷
新到磁盘。这种刷新⻚⾯的⽅式被称之为BUF_FLUSH_LRU。
从flush链表中刷新⼀部分⻚⾯到磁盘。
后台线程也会定时从flush链表中刷新⼀部分⻚⾯到磁盘,刷新的速率取决于当时系统是不是很繁忙。这种刷新⻚⾯的⽅式被称之为BUF_FLUSH_LIST。
多个Buffer Pool实例
在多线程环境下,访问Buffer Pool中的各种链表都需要加锁处理啥的,在Buffer Pool特别⼤⽽且多线程并发访问特别⾼的情况下,单⼀的Buffer Pool可能会影响请求的处理速度。所以在Buffer Pool特别⼤的时候,我们可以把它们拆分成若⼲个⼩的Buffer Pool,每个Buffer Pool都称为⼀个实例,它们都是独⽴的,独⽴的去申请内存空间,独⽴的管理各种链表,所以在多线程并发访问时并不会相互影响,从⽽提⾼并发处理能⼒。以在服务器启动的时候通过设置innodb_buffer_pool_instances的值来修改Buffer Pool实例的个数,⽐⽅说这样:
[server]
innodb_buffer_pool_instances = 2
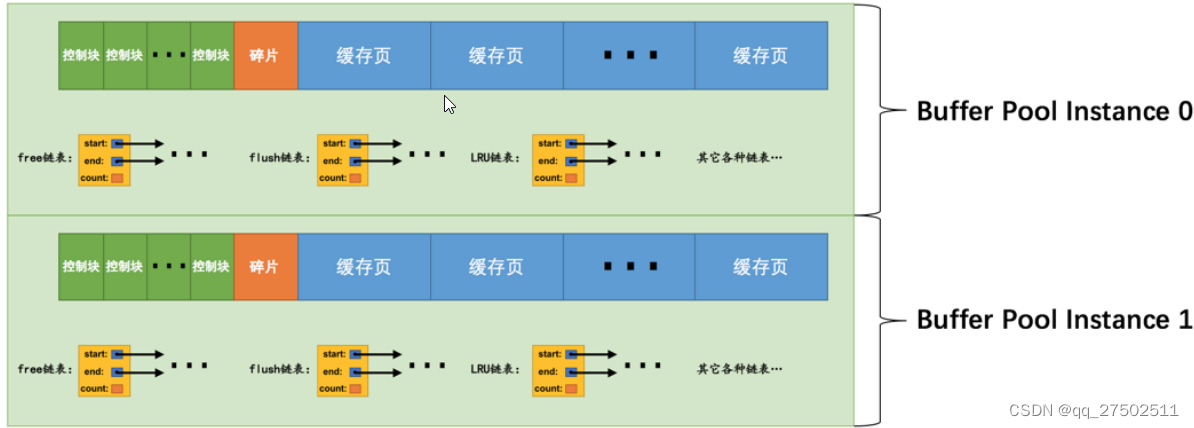
配置Buffer Pool时的注意事项
- innodb_buffer_pool_size必须是innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的倍数(这主要是想保证每⼀个Buffer Pool实例
中包含的chunk数量相同)。
假设我们指定的innodb_buffer_pool_chunk_size的值是128M,innodb_buffer_pool_instances的值是16,那么这两个值的乘积就是2G,也就是说
innodb_buffer_pool_size的值必须是2G或者2G的整数倍。⽐⽅说我们在启动MySQL服务器是这样指定启动参数的:
mysqld --innodb-buffer-pool-size=8G --innodb-buffer-pool-instances=16
默认的innodb_buffer_pool_chunk_size值是128M,指定的innodb_buffer_pool_instances的值是16,所以innodb_buffer_pool_size的值必须是2G或者
2G的整数倍,上边例⼦中指定的innodb_buffer_pool_size的值是8G,符合规定,所以在服务器启动完成之后我们查看⼀下该变量的值就是我们指定的
8G(8589934592字节):
如果我们指定的innodb_buffer_pool_size⼤于2G并且不是2G的整数倍,那么服务器会⾃动的把innodb_buffer_pool_size的值调整为2G的整数倍,⽐⽅说mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+------------+ | Variable_name | Value | +-------------------------+------------+ | innodb_buffer_pool_size | 8589934592 | +-------------------------+------------+ 1 row inset (0.00 sec)
我们在启动服务器时指定的innodb_buffer_pool_size的值是9G:
mysqld --innodb-buffer-pool-size=9G --innodb-buffer-pool-instances=16
那么服务器会⾃动把innodb_buffer_pool_size的值调整为10G(10737418240字节),不信你看:mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+-------------+ | Variable_name | Value | +-------------------------+-------------+ | innodb_buffer_pool_size | 10737418240 | +-------------------------+-------------+ 1 row inset (0.01 sec) - 如果在服务器启动时,innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的值已经⼤于innodb_buffer_pool_size的值,那么
innodb_buffer_pool_chunk_size的值会被服务器⾃动设置为innodb_buffer_pool_size/innodb_buffer_pool_instances的值。
⽐⽅说我们在启动服务器时指定的innodb_buffer_pool_size的值为2G,innodb_buffer_pool_instances的值为16,innodb_buffer_pool_chunk_size的值
为256M:
mysqld --innodb-buffer-pool-size=2G --innodb-buffer-pool-instances=16 --innodb-buffer-pool-chunk-size=256M
由于256M × 16 = 4G,⽽4G > 2G,所以innodb_buffer_pool_chunk_size值会被服务器改写为
innodb_buffer_pool_size/innodb_buffer_pool_instances的值,也就是:2G/16 = 128M(134217728字节),不信你看:
mysql> show variables like 'innodb_buffer_pool_size';
+-------------------------+------------+
| Variable_name | Value |
+-------------------------+------------+
| innodb_buffer_pool_size | 2147483648 |
+-------------------------+------------+
1 row inset (0.01 sec)
mysql> show variables like 'innodb_buffer_pool_chunk_size';
+-------------------------------+-----------+
| Variable_name | Value |
+-------------------------------+-----------+
| innodb_buffer_pool_chunk_size | 134217728 |
+-------------------------------+-----------+
1 row inset (0.00 sec)