【Linux开发—多进程编程】
- 前言
- 1,两种类型的服务端
- 2,并发服务器的实现方法:
- 一,认识及应用
- 1,进程认识
- 2,CPU核的个数与进程数
- 3,进程ID
- 4,进程创建
- 5, 调用fork函数后的程序运行流程:
- 二,僵尸进程
- 1,定义
- 2,产生僵尸进程的原因及解决方式
- 三,信号处理
- 1,定义
- 2,signal函数
- 3,调用方式
- 4,实例:
- 四,基于多任务的并发服务器
- 1,原理
- 2,多任务并发服务器实例
- 五,进程间通信(IPC)
- 1,匿名管道—PIPE
- 2,命名管道—FIFO
- 3,共享内存
- 1,定义
- 2,共享内存的创建,映射,访问和删除
- 3,代码示例:
- 4,信号量
- 1,定义
- 2,工作原理
- 3,Linux的信号量机制
- 1,semget函数
- 2,semop函数
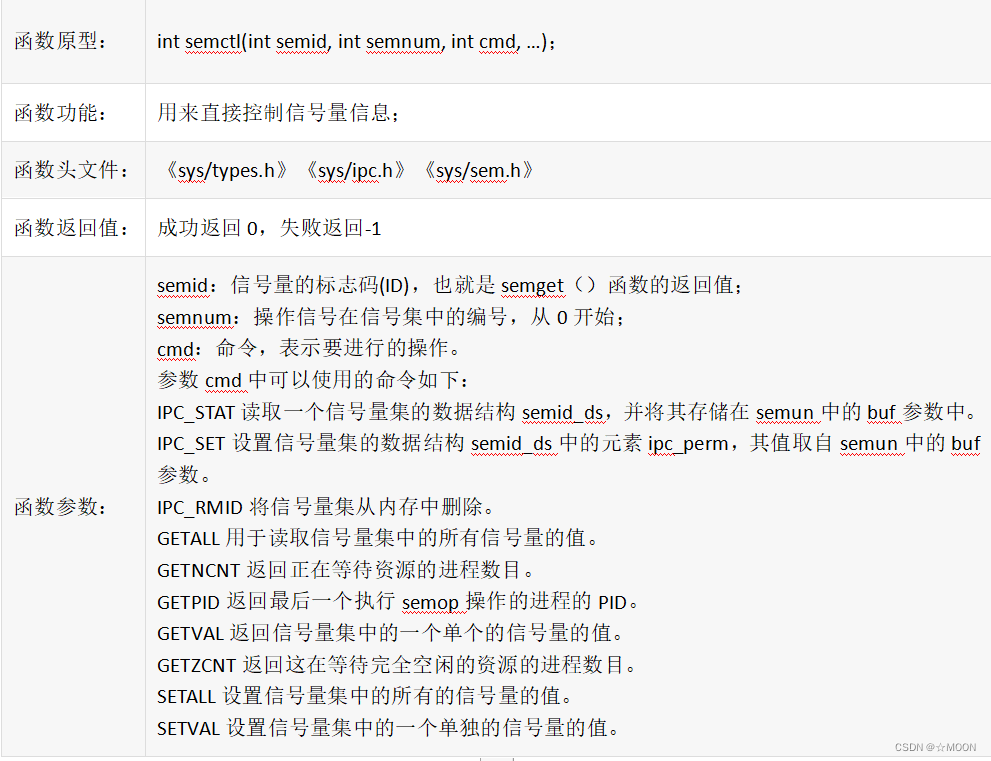
- 3,semctl函数
- 4,代码示例:
- 5,消息队列
- 在之前,我对套接字编程做了一些整理Linux网络编程,但要想实现真正的服务器端,只凭socket还不够。还需要知道,构建实际网络服务所需内容。
前言
我们可以构建按序向第一个客户端到第一百个客户端提供服务的服务器端。当然,第一个客户端不会抱怨服务器端,但如果每个客户端的平均服务时间为0.5秒,则第100个客户端会对服务器端产生相当大的不满。
1,两种类型的服务端
如果真正为客户端着想,应提高客户端满意度平均标准。如果有下面这种类型的服务器端,应该感到满意了吧???
“第一个连接请求的受理时间为0秒,第50个连接请求的受理时间为50秒,第100个连接请求的受理时间为100秒!但只要受理,服务只需1秒钟。”
如果排在前面的请求数能用一只手数清,客户端当然会对服务器端感到满意。但只要超过这个数,客户端就会开始抱怨。还不如用下面这种方式提供服务。
“所有连接请求的受理时间不超过1秒,但平均服务时间为2~3秒。”
2,并发服务器的实现方法:
即使有可能延长服务时间,也有必要改进服务器端,使其同时向所有发起请求的客户端提供服务,以提高平均满意度。
而且,网络程序中数据通信时间比CPU运算时间占比更大,因此,向多个客户端提供服务是一种有效利用CPU的方式。接下来讨论同时向多个客户端提供服务的并发服务器端。下面列出的是具有代表性的并发服务器端实现模型和方法。
- 1 多进程服务器∶通过创建多个进程提供服务。
- 2 多路复用服务器∶通过捆绑并统一管理I/O对象提供服务。
- 3 多线程服务器∶通过生成与客户端等量的线程提供服务。
在这里我们以多进程服务器为主。
一,认识及应用
1,进程认识
- 进程:“占用内存空间的正在运行的程序”,比如植物大战僵尸,如果同时运行多个植物大战僵尸游戏程序,则会生成相应数量的进程,也会占用相应进程数的内存空间。
- 从操作系统的角度看,进程是程序流的基本单位,若创建多个进程,则操作系统将同时运行。有时一个程序运行过程中也会产生多个进程。接下来要创建的多进程服务器就是其中的代表。编写服务器端前,先了解一下通过程序创建进程的方法。
2,CPU核的个数与进程数
- 拥有2个运算设备的CPU称作双核CPU,拥有4个运算器的CPU 称作4核CPU。也就是说,1个CPU中可能包含多个运算设备(核)。核的个数与可同时运行的进程数相同。相反,若进程数超过核数,进程将分时使用CPU 资源。但因为CPU 运转速度极快,我们会感到所有进程同时运行。当然,核数越多,这种感觉越明显。
3,进程ID
- 无论进程是如何创建的,所有进程都会从操作系统分配到ID。此ID称为"进程ID",其值为大于2的整数。1是要分配给操作系统启动后的(用于协助操作系统)首个进程,因此用户进程无法得到ID值1。
通过ps au指令可以查看当前运行的所有进程。特别需要注意的是,该命令同时可以列出PID(进程ID)。通过指定a和u参数可以列出所有进程详细信息。
4,进程创建
- 创建进程的方法很多,这里介绍用于创建多进程服务器端的fork函数。
#include <unistd.h>
//→成功时返回进程 ID,失败时返回-1。
pid_t fork(void);
- fork函数将创建调用的进程副本。也就是说,并非根据完全不同的程序创建进程,而是复制正在运行的、调用fork函数的进程。另外,两个进程都将执行fork函数调用后的语句(准确地说是在fork函数返回后)。但因为通过同一个进程、复制相同的内存空间,之后的程序流要根据fork函数的返回值加以区分。即利用fork函数的如下特点区分程序执行流程。
- 父进程∶fork函数返回子进程ID。
- 子进程∶fork函数返回0。
- 此处"父进程"(Parent Process)指原进程,即调用fork函数的主体,而"子进程"(Child Process)是通过父进程调用fork函数复制出的进程。
5, 调用fork函数后的程序运行流程:

- pid为0,表示开启了子进程,大于0为父进程,小于0为失败
调用fork函数后,父子进程拥有完全独立的内存结构。
二,僵尸进程
1,定义
文件操作中,关闭文件和打开文件同等重要。同样,进程销毁也和进程创建同等重要。如果未认真对待进程销毁,它们将变成僵尸进程困扰大家。
进程的世界同样如此。进程完成工作后(执行完main函数中的程序后)应被销毁,但有时这些进程将变成僵尸进程,占用系统中的重要资源。这种状态下的进程称作"僵尸进程",这也是给系统带来负担的原因之一。
2,产生僵尸进程的原因及解决方式
- 首先利用如下两个示例展示调用fork函数产生子进程的终止方式。
1 传递参数并调用exit函数。
2 main函数中执行retun语句并返回值。
向exit函数传递的参数值和main函数的return语句返回的值都会传递给操作系统。而操作系统不会销毁子进程,直到把这些值传递给产生该子进程的父进程。处在这种状态下的进程就是僵尸进程。也就是说,将子进程变成僵尸进程的正是操作系统。 - 解决方案:只有父进程主动发起请求(函数调用)时,操作系统才会传递该值。换言之,如果父进程未主动要求获得子进程的结束状态值,操作系统将一直保存,并让子进程长时间处于僵尸进程状态。也就是说,父母要负责收回自己生的孩子。
#include <stdio.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
pid_t pid=fork();
if(pid==0) // if Child Process
{
puts("Hi I'am a child process");
}
else
{
printf("Child Process ID: %d \n", pid);
sleep(30); // Sleep 30 sec.
}
if(pid==0)
puts("End child process");
else
puts("End parent process");
return 0;
}
结果显示: Z状态的进程为僵尸进程,S:休眠,R:运行,Z僵尸

三,信号处理
1,定义
-
上面我们了解了,进程的创建和销毁,父进程往往与子进程一样繁忙,不知道什么时候结束子进程, 因此不能只调用waitpid函数无休止的以等待子进程终止,这就需要信号处理来响应关联。
-
子进程终止的识别主体是操作系统,因此,若操作系统能把子进程的信息告诉正忙于工作的父进程,将有助于构建高效的程序。
-
信号处理:特定事件发生时由操作系统向进程发送的消息,另外,为了响应该消息,执行与消息相关的自定义操作的过程。
2,signal函数
- 进程发现自己的子进程结束时,请求操作系统调用特定函数。该请求通过signal函数调用完成(因此称signal为信号注册函数)
//→为了在产生信号时调用,返回之前注册的函数指针。
/*
函数名∶signal
参数∶int signo, void(* func)(int)
返回类型∶参数为int型,返回void型函数指针。
*/
#include<signal.h>
void(*signal(int signo, void(*func)(int))(int);
//等价于下面的内容:
typedef void(*signal_handler)(int);
signal_handler signal(int signo,signal_handler func);
- 调用上述函数时,第一个参数为特殊情况信息,第二个参数为特殊情况下将要调用的函数的地址值(指针)。发生第一个参数代表的情况时,调用第二个参数所指的函数。下面给出可以在signal函数中注册的部分特殊情况和对应的常数。
- SIGALRM∶已到通过调用alarm函数注册的时间。
- SIGINT∶输入CTRL+C。
- SIGCHLD∶子进程终止。(英文为child)
3,调用方式
编写调用signal函数的语句完成如下请求
1、“子进程终止则调用mychild函数。”
代码:signal(SIGCHLD, mychild);
- 此时mychild函数的参数应为int,返回值类型应为void。对应signal函数的第二个参数。另外,常数SIGCHLD表示子进程终止的情况,应成为signal函数的第一个参数。
2、“已到通过alarm函数注册的时间,请调用timeout函数。”
3、“输入CTRL+C时调用keycontrol函数。”
- 代表这2种情况的常数分别为SIGALRM和SIGINT,因此按如下方式调用signal函数。
2、signal(SIGALRM, timeout);
3、signal(SIGINT, keycontrol);
以上就是信号注册过程。注册好信号后,发生注册信号时(注册的情况发生时),操作系统将调用该信号对应的函数。
#include<unistd.h>
//→返回0或以秒为单位的距SIGALRM信号发生所剩时间。
unsigned int alarm(unsigned int seconds);
如果调用该函数的同时向它传递一个正整型参数,相应时间后(以秒为单位)将产生SIGALRM信号。若向该函数传递0,则之前对SIGALRM信号的预约将取消。如果通过该函数预约信号后未指定该信号对应的处理函数,则(通过调用signal函数)终止进程,不做任何处理。
4,实例:
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
// 定义信号处理函数timeout,返回值为void
void timeout(int sig)
{
if(sig==SIGALRM)
puts("Time out!");
//为了每隔2秒重复产生SIGALRM信号,在信号处理器中调用alarm函数
alarm(2);
}
// 定义信号处理函数keycontrol,返回值为void
void keycontrol(int sig)
{
if(sig==SIGINT)
puts("CTRL+C pressed");
}
int main(int argc, char *argv[])
{
int i;
//注册SIGALRM、SIGINT信号及相应处理器
signal(SIGALRM, timeout);
signal(SIGINT, keycontrol);
//预约2秒后发生SIGALRM信号
alarm(2);
for(i=0; i<3; i++)
{
puts("wait...");
sleep(100);
}
return 0;
}
- 上述的for循环:
为了查看信号产生和信号处理器的执行并提供每次100秒、共3次的等待时间,在
循环中调用sleep函数。也就是说,再过300秒、约5分钟后终止程序,这是相当长//的一段时间,但实际执行时只需不到10秒。
这是为什么呢?明明是300秒。。。
- 原因:“发生信号时将唤醒由于调用sleep函数而进入阻塞状态的进程。”
调用函数的主体的确是操作系统,但进程处于睡眠状态时无法调用函数。因此,产生信号时,为了调用信号处理器,将唤醒由于调用sleep函数而进入阻塞状态的进程。而且,进程一旦被唤醒,就不会再进入睡眠状态。即使还未到sleep函数中规定的时间也是如此。所以,程序运行不到10秒就会结束,连续输入CTRL+C则有可能1秒都不到
四,基于多任务的并发服务器
1,原理
(空间与时间的平衡,以时间换取空间,还是以空间换取时间)
每次客户端有访问请求时,服务端在accept阶段,去fork创建子进程处理客户端访问请求,同时父进程回到accept阶段继续等待新的客户端请求。问题点在,若同时在线多个用户的瓶颈,导致内存暴增。
2,多任务并发服务器实例
//-----------------------------------------------------多任务并发服务器(进程)---------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h> //Linux标准数据类型
#include <signal.h>
#include <sys/wait.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#define BUF_SIZE 30
void error_handling(char* message);
//------------------------------------服务端-----------------------
void hand_childProc(int sig)
{
pid_t pid;
int status = 0;
waitpid(-1, &status, WNOHANG);//-1:回收僵尸进程,WNOHANG:非挂起方式,立马返回status状态
printf("%s(%d):%s removed sub proc:%d\r\n", __FILE__, __LINE__, __FUNCTION__, pid);
}
//服务器
void ps_moretask_server()
{
struct sigaction act;
act.sa_flags = 0;
act.sa_handler = hand_childProc;
sigaction(SIGCHLD, &act, 0);//当发现有SIGCHLD信号时进入到子进程函数。处理任务和进程回收(防止僵尸进程)
int serv_sock;
struct sockaddr_in server_adr, client_adr;
memset(&server_adr, 0, sizeof(server_adr));
server_adr.sin_family = AF_INET;
server_adr.sin_addr.s_addr = htonl(INADDR_ANY);
server_adr.sin_port = htons(9527);
serv_sock = socket(AF_INET, SOCK_STREAM, 0);
if (bind(serv_sock, (sockaddr*)&server_adr, sizeof(server_adr)) == -1)
error_handling("ps_moretask server bind error");
if (listen(serv_sock, 5) == -1)
{
error_handling("ps_moretask server listen error");
}
int count = 0;
char buffer[1024];
while (true)
{
socklen_t size = sizeof(client_adr);
int client_sock = accept(serv_sock, (sockaddr*)&client_adr, &size);
if (client_sock < 0) {
error_handling("ps_moretask server accept error");
close(serv_sock);
return;
}
pid_t pid = fork();//会复制客户端和服务端的socket
if (pid == 0)
{
close(serv_sock);//子进程关闭服务端的socket,因为子进程为了处理客户端的任务
ssize_t len = 0;
while ((len = read(client_sock, buffer, sizeof(buffer))) > 0)
{
len = write(client_sock, buffer, strlen(buffer));
if (len != (ssize_t)strlen(buffer)) {
//error_handling("write message failed!");
std::cout << "ps_moretask server write message failed!\n";
close(serv_sock);
return;
}
std::cout << "ps_moretask server read & write success!, buffer:" << buffer << "__len:" << len << std::endl;
memset(buffer, 0, len);//清理
close(client_sock);
return;
}
}
else if (pid < 0)
{
close(client_sock);
error_handling("ps_moretask server accept fork error");
break;
}
close(client_sock);//服务端关闭的时候,客户端会自动关闭
}
close(serv_sock);
}
//------------------------------------客户端-----------------------
void ps_moretask_client()
{
int client = socket(PF_INET, SOCK_STREAM, 0);
struct sockaddr_in servaddr;
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = inet_addr("127.0.0.1");
servaddr.sin_port = htons(9527);
int ret = connect(client, (struct sockaddr*)&servaddr, sizeof(servaddr));
if (ret == -1) {
std::cout << "ps_moretask client connect failed!\n";
close(client);
return;
}
std::cout << "ps_moretask client connect server is success!\n";
char buffer[256] = "hello ps_moretask server, I am client!";
while (1)
{
//fputs("Input message(Q to quit):", stdout);//提示语句,输入Q结束
//fgets(buffer, sizeof(buffer), stdin);//对文件的标准输入流操作 读取buffer的256字节
//if (strcmp(buffer, "q\n") == 0 || (strcmp(buffer, "Q\n") == 0)) {
// break;
//}
size_t len = strlen(buffer);
size_t send_len = 0;
//当数据量很大时,并不能一次把所有数据全部发送完,因此需要分包发送
while (send_len < len)
{
ssize_t ret = write(client, buffer + send_len, len - send_len);//send_len 记录分包的标记
if (ret <= 0) {//连接出了问题
fputs("may be connect newwork failed,make client write failed!\n", stdout);
close(client);
return;
}
send_len += (size_t)ret;
std::cout << "ps_moretask client write success, msg:" << buffer << std::endl;
}
memset(buffer, 0, sizeof(buffer));
//当数据量很大时,并不能一次把所有数据全部读取完,因此需要分包读取
size_t read_len = 0;
while (read_len < len)
{
size_t ret = read(client, buffer + read_len, len - read_len);
if (ret <= 0) {//连接出了问题
fputs("may be connect newwork failed, make client read failed!\n", stdout);
close(client);
return;
}
read_len += (size_t)ret;
}
std::cout << "from server:" << buffer << std::endl;
};
sleep(2);//延时2秒关闭客户端
close(client);
std::cout << "ps_moretask client done!" << std::endl;
}
//------------------------------------调用函数-----------------------
void ps_moretask_func()
{
pid_t pid = fork();
if (pid > 0)
{
printf("%s(%d):%s wait ps_moretask server invoking!\r\n", __FILE__, __LINE__, __FUNCTION__);
sleep(1);
for (int i = 0; i < 5; i++)
{
pid = fork();
if (pid > 0) {
continue;
}
else if (pid == 0)
{
//子进程启动客户端
ps_moretask_client();
break;//到子进程终止,避免指数级创建进程 n的2次方。
}
}
}
else if (pid == 0) {
//启动服务端
ps_moretask_server();
}
}
五,进程间通信(IPC)
-
IPC(Inter Process Communication):进程间通信,通过内核提供的缓冲区进行数据交换的机制。进程间通信意味着两个不同进程间可以交换数据,为了完成这一点,操作系统中应提供两个进程可以同时访问的内存空间。
-
进程A和B之间的如下例子就是一种进程间通信规则。
- "如果我有1个面包,变量bread的值就变为1。如果吃掉这个面包,bread的值又变回0。因此,可以通过变量bread值判断我的状态。"也就是说,进程A通过变量bread将自己的状态通知给了进程B,进程B通过变量bread听到了进程A的话。
-
只要有两个进程可以同时访问的内存空间,就可以通过此空间交换数据。但是进程具有完全独立的内存结构。就连通过fork函数创建的子进程也不会与父进程共享内存空间。因此,进程间通信只能通过其他特殊方法完成。
-
进程中,子进程会复制父进程的内存,而父进程不会复制子进程的内存,因此子进程的一些操作父进程是不知道的。
1,匿名管道—PIPE
(亲族管道,处理两个不相干的进程时会有问题)
- 管道并非属于进程的资源,而是和套接字一样,属于操作系统(也就不是fork函数的复制对象)。所以,两个进程通过操作系统提供的内存空间进行通信。
- 管道其实有很多种:
- 最常用的应该就是shell中的"|"。他其实就是一个管道符,将前面的表达式的输出,引入后面表达式当作输入,比如我们常用的"ps aux|grep ssh"可以查看ssh的相关进程。
- 我们常用在进程间通信管道的有两种,一种是pipe管道,又可以叫做亲族管道,
- 与之对应的则是fifo管道,又可以叫做公共管道。
#include <unistd.h>
//→成功时返回 0,失败时返回-1。
int pipe(int filedes[2]);
/*
Filedes[0] 通过管道接收数据时使用的文件描述符,即管道出口。
Fledes[1] 通过管道传输数据时使用的文件描述符,即管道入口。
*/
- 双向管道:
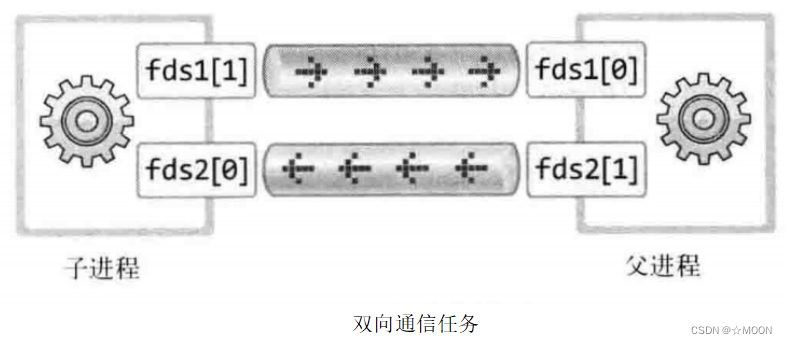
//进程通信——双管道(PIPE)
void ps_pipe_double_func()
{
int fds_server[2] = { -1, -1 };
int fds_client[2] = { -1, -1 };
pipe(fds_server);//父进程创建管道
pipe(fds_client);
pid_t pid = fork();
if (pid == 0)
{
char buffer[64] = "client send by child process!\n";
char readBuf[128] = "";
//子进程数据写入
write(fds_client[1], buffer, sizeof(buffer));
read(fds_server[0], readBuf, sizeof(readBuf));
printf("%s(%d):%s child process read ps_pipe by server :%s\r\n", __FILE__, __LINE__, __FUNCTION__, readBuf);
printf("%s(%d):%s ---pid:%d\r\n", __FILE__, __LINE__, __FUNCTION__, getpid());
}
else
{
char buffer[64] = "server send by father process!\n";
char readBuf[128] = "";
//父进程读取数据
read(fds_client[0], readBuf, sizeof(readBuf));
printf("%s(%d):%s father process read ps_pipe by client :%s\r\n", __FILE__, __LINE__, __FUNCTION__, readBuf);
write(fds_server[1], buffer, sizeof(buffer));
}
printf("%s(%d):%s ---pid:%d\r\n", __FILE__, __LINE__, __FUNCTION__, getpid());
}
2,命名管道—FIFO
FIFO:first in first out,先进先出。(每个进程都要有个命名文件)
-
对比pipe管道,他已经可以完成在两个进程之间通信的任务,不过它似乎完成的不够好,也可以说是不够彻底。它只能在两个有亲戚关系的进程之间进行通信,这就大大限制了pipe管道的应用范围。我们在很多时候往往希望能够在两个独立的进程之间进行通信,这样就无法使用pipe管道,所以一种能够满足独立进程通信的管道应运而生,就是fifo管道。
-
fifo管道的本质是操作系统中的命名文件
-
它在操作系统中以命名文件的形式存在,我们可以在操作系统中看见fifo管道,在你有权限的情况下,甚至可以读写他们。
- 使用命令: mkfifo myfifo
- 使用函数:int mkfifo(const char *pathname, mode_t mode); 成功:0;失败:-1
-
内核会针对fifo文件开辟一个缓冲区,操作FIFO文件,可以操作缓冲区,实现进程通信。一旦使用mkfifo创建了一个FIFO,就可以使用open打开它,常见的文件IO函数都可以用于FIFO。如:close、read、write、unlink等 .
//进程通信-命名管道(FIFO)
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>//创建命名管道头文件
#include <fcntl.h>
#include <string.h>
void ps_fifo_func()
{
mkfifo("./test_fifo.fifo", 0666);//创建FIFO命名管道,并设置mode
pid_t pd = fork();
if (pd == 0)
{
sleep(1);
int fd = open("./test_fifo.fifo", O_RDONLY);//打开创建的fifo文件,并申请读权限
char buffer[64] = "";
ssize_t len = read(fd, buffer, sizeof(buffer));
printf("%s(%d):%s read ps_fifo server :%s len: %d\r\n", __FILE__, __LINE__, __FUNCTION__, buffer, len);
close(fd);
}
else
{
int fd = open("./test_fifo.fifo", O_WRONLY);//打开创建的fifo文件, 并申请读写权限
char buffer[128] = "hello, I am fifo server!";
ssize_t len = write(fd, buffer, sizeof(buffer));
printf("%s(%d):%s ps_fifo server wait success!\r\n", __FILE__, __LINE__, __FUNCTION__);
close(fd);
}
}
3,共享内存
(数据同步时,具有部分时间差,比较耗时)
1,定义
- 在理解共享内存之前,就必须先了解System V IPC通信机制。
System V IPC机制最初是由AT&T System V.2版本的UNIX引入的。这些机制是专门用于IPC(Inter-Process Communication 进程间通信)的,它们在同一个版本中被应用,又有着相似的编程接口,所以它们通常被称为System V IPC通信机制。
共享内存是三个System V IPC机制中的第二个。共享内存允许不同进程之间共享同一段逻辑内存,对于这段内存,它们都能访问,或者修改它,没有任何限制。所以它是进程间传递大量数据的一种非常有效的方式。“共享内存允许不同进程之间共享同一段逻辑内存”,这里是逻辑内存。也就是说共享内存的进程访问的可以不是同一段物理内存,这个没有明确的规定,但是大多数的系统实现都将进程之间的共享内存安排为同一段物理内存。 - 共享内存实际上是由IPC机制分配的一段特殊的物理内存,它可以被映射到该进程的地址空间中,同时也可以被映射到其他拥有权限的进程的地址空间中。就像是使用了malloc分配内存一样,只不过这段内存是可以共享的。
2,共享内存的创建,映射,访问和删除
- IPC提供了一套API来控制共享内存,使用共享内存的步骤通常是:
- 1)创建或获取一段共享内存;
- 2)将上一步创建的共享内存映射到该进程的地址空间;
- 3)访问共享内存;
- 4)将共享内存从当前的进程地址空间分离;
- 5)删除这段共享内存;
- 具体如下:
- 1)使用shmget()函数来创建一段共享内存:
int shmget( key_t key, size_t size, int shmflg );
–key:这段共享内存取的名字,系统利用它来区分共享内存,访问同一段共享内存的不同进程需要传入相同的名字。
–size:共享内存的大小
–shmflg:是共享内存的标志,包含9个比特标志位,其内容与创建文件时的mode相同。有一个特殊的标志IPC_CREAT可以和权限标志以或的形式传入 - 2)使用函数shmat()来映射共享内存:
void* shmat( int shm_id, const void* shm_addr, int shmflg );
–shm_id:是共享内存的ID,shmget()函数的返回值。
–shm_addr:指定共享内存连接到当前进程地址空间的位置,通常传入NULL,表示让系统来进行选择, 防止内存错乱。
–shmflg:一组控制的标志,通常输入0,也有可能输入SHM_RDONLY,表示共享内存段只读。
–函数返回值是共享内存的首地址指针。 - 3)使用函数shmdt()来分离共享内存:
int shmdt( void* shm_p );
–shm_p:就是共享内存的首地址指针,也即是shmat()的返回值。
–成功返回0,失败时返回-1。 - 4)使用shmctl()函数来控制共享内存:
int shmctl( int shm_id, int command, struct shmid_ds* buf );
–shm_id:是共享内存的标示符,也即是shmget()的返回值。
–command:是要采取的动作,它有三个有效值,如下所示:

- 1)使用shmget()函数来创建一段共享内存:
3,代码示例:
#include <sys/ipc.h>
#include <sys/shm.h>//共享内存头文件
//共享的结构体
typedef struct {
int id;
char name[128];
int age;
bool sex;
int signal;
}STUDENT, *P_STUDENT;
void ps_sharememory_func()
{
pid_t pid = fork();
if (pid > 0)
{
//shmget创建共享文件 ftok指定文件或文件夹路径,创建一个安全可靠的key,规避重复
int shm_id = shmget(ftok(".", 1), sizeof(STUDENT), IPC_CREAT | 0666);
if (shm_id == -1) {
printf("%s(%d):%s share memory creat failed!\r\n", __FILE__, __LINE__, __FUNCTION__);
return;
}
P_STUDENT pStu = (P_STUDENT)shmat(shm_id, NULL, 0);
pStu->id = 666666;
strcpy(pStu->name, "welcome moon");
pStu->age = 19;
pStu->sex = true;
pStu->signal = 99;
while (pStu->signal == 99)//同步
{
usleep(100000);
}
shmdt(pStu);
shmctl(shm_id, IPC_RMID, NULL);
}
else {
usleep(500000);//休眠500ms,等待父进程写入数据, 1000单位为1ms,100000为100ms
//shmget创建共享文件 ftok指定文件或文件夹路径,创建一个安全可靠的key,规避重复
int shm_id = shmget(ftok(".", 1), sizeof(STUDENT), IPC_CREAT | 0666);
if (shm_id == -1) {
printf("%s(%d):%s share memory creat failed!\r\n", __FILE__, __LINE__, __FUNCTION__);
return;
}
P_STUDENT pStu = (P_STUDENT)shmat(shm_id, NULL, 0);
while (pStu->signal != 99)//同步
{
usleep(100000);
}
printf("student msg: %d, %s, %d, %s\n", pStu->id, pStu->name, pStu->age, pStu->sex == true ? "male":"famale");
pStu->signal = 0;
shmdt(pStu);
shmctl(shm_id, IPC_RMID, NULL);
}
}
- 共享内存,数据一定要同步案例中两个进程的while循环处理同步,否则并不能访问到数据。弊端:数据同步时,具有部分时间差,比较耗时。
- 运行结果:

4,信号量
1,定义
- 为了防止出现因多个程序同时访问一个共享资源而引发的一系列问题,我们需要一种方法,它可以通过生成并使用令牌来授权,在任一时刻只能有一个执行线程访问代码的临界区域。临界区域是指执行数据更新的代码需要独占式地执行。而信号量就可以提供这样的一种访问机制,让一个临界区同一时间只有一个线程在访问它,也就是说信号量是用来
调协进程对共享资源的访问。 - 信号量是一个特殊的变量,程序对其访问都是原子操作,且
只允许对它进行等待(即P(信号变量))和发送(即V(信号变量))信息操作。最简单的信号量是只能取0和1的变量,这也是信号量最常见的一种形式,叫做二进制信号量。而可以取多个正整数的信号量被称为通用信号量。这里主要探索二进制信号量。
2,工作原理
- 1,由于信号量只能进行两种操作等待和发送信号,即P(sv)和V(sv),他们的行为是这样的: P(sv):如果sv的值大于零,就给它减1;如果它的值为零,就挂起该进程的执行
V(sv):如果有其他进程因等待sv而被挂起,就让它恢复运行,如果没有进程因等待sv而挂起,就给它加1. - 2,举个例子,就是两个进程共享信号量sv,一旦其中一个进程执行了P(sv)操作,它将得到信号量,并可以进入临界区,使sv减1。而第二个进程将被阻止进入临界区,因为当它试图执行P(sv)时,sv为0,它会被挂起以等待第一个进程离开临界区域并执行V(sv)释放信号量,这时第二个进程就可以恢复执行。
3,Linux的信号量机制
1,semget函数

2,semop函数

3,semctl函数