引言
书接上篇 微服务绕不过的坎-服务雪崩 ,玩微服务不可避免的问题:服务雪崩,那为了应付服务雪崩问题,需要做啥预防性操作呢?答案是:做好容错保护
容错方案
前面说了,要防止雪崩的扩散,我们就要做好服务的容错,容错说白了就是保护自己不被猪队友拖垮的一些措施, 下面介绍常见的服务容错思路和组件。
常见的容错思路有隔离、超时、限流、熔断、降级这几种,下面分别介绍一下。
隔离
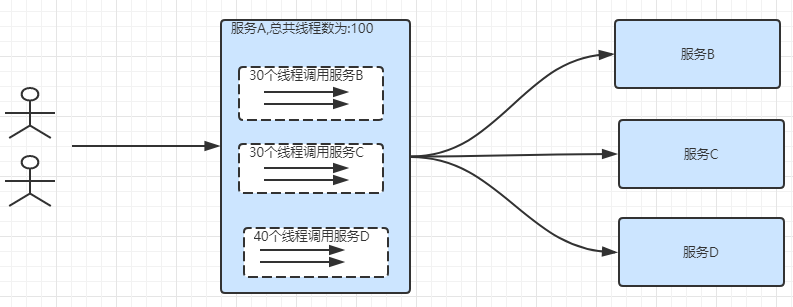
隔离机制: 比如服务A内限制有100个线程, 现在服务A可能会调用服务B,服务C,服务D.我们在服务A进行远程调用的时候,给不同的服务分配固定的线程,不会把所有线程都分配给某个微服务. 比如调用服务B分配30个线程,调用服务C分配30个线程,调用服务D分配40个线程. 这样进行资源的隔离,保证即使下游某个服务挂了,也不至于把服务A的线程消耗完。比如服务B挂了,这时候最多只会占用服务A的30个线程,服务A还有70个线程可以调用服务C和服务D.
超时机制
超时机制: 在上游服务调用下游服务的时候,设置一个最大响应时间,如果超过这个时间,下游未作出反应,就断开请求,释放掉线程。

限流机制
限流机制: 限流就是限制系统的输入和输出流量已达到保护系统的目的。为了保证系统的稳固运行,一旦达到的需要限制的阈值,就需要限制流量并采取少量措施以完成限制流量的目的。

熔断机制
熔断机制: 在互联网系统中,当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫做熔断。

服务熔断一般有三种状态:
-
熔断关闭状态(Closed)
服务没有故障时,熔断器所处的状态,对调用方的调用不做任何限制
-
熔断开启状态(Open)
后续对该服务接口的调用不再经过网络,直接执行本地的fallback方法
-
半熔断状态(Half-Open)
尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率。如果成功率达到预期,则说明服务已恢复,进入熔断关闭状态;如果成功率仍旧很低,则重新进入熔断开启状态。
降级机制
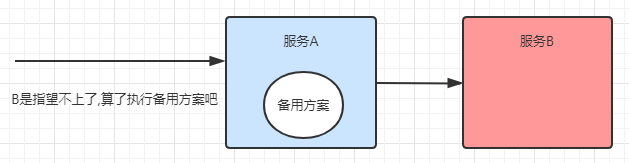
降级机制: 降级其实就是为服务提供一个兜底方案,一旦服务无法正常调用,就使用兜底方案。
常见的容错组件
-
Hystrix
Hystrix是由Netflflix开源的一个延迟和容错库,用于隔离访问远程系统、服务或者第三方库,防止
级联失败,从而提升系统的可用性与容错性。
-
Resilience4J
Resilicence4J一款非常轻量、简单,并且文档非常清晰、丰富的熔断工具,这也是Hystrix官方推
荐的替代产品。不仅如此,Resilicence4j还原生支持Spring Boot 1.x/2.x,而且监控也支持和
prometheus等多款主流产品进行整合。
-
Sentinel
Sentinel 是阿里巴巴开源的一款断路器实现,本身在阿里内部已经被大规模采用,非常稳定。
![[附源码]计算机毕业设计springboot疫情期间小学生作业线上管理系统](https://img-blog.csdnimg.cn/a7af71894ebc40feacf894bdc72c49bd.png)







![[附源码]计算机毕业设计springboot疫苗药品批量扫码识别追溯系统](https://img-blog.csdnimg.cn/ca21ba193bbb4b88ada80dfbf702c746.png)