原理
在现代的容器化环境中,节点资源的管理是一个重要的任务。特别是对于内存资源的管理,它直接影响着容器应用的性能和可用性。在 Kubernetes 中,我们可以利用自动调度和控制的机制来实现对节点内存的有效管理。本文将介绍一种基于 Bash 脚本的节点内存管理方案,并探讨其原理、优势、缺点以及部署和应用趋势。
背景
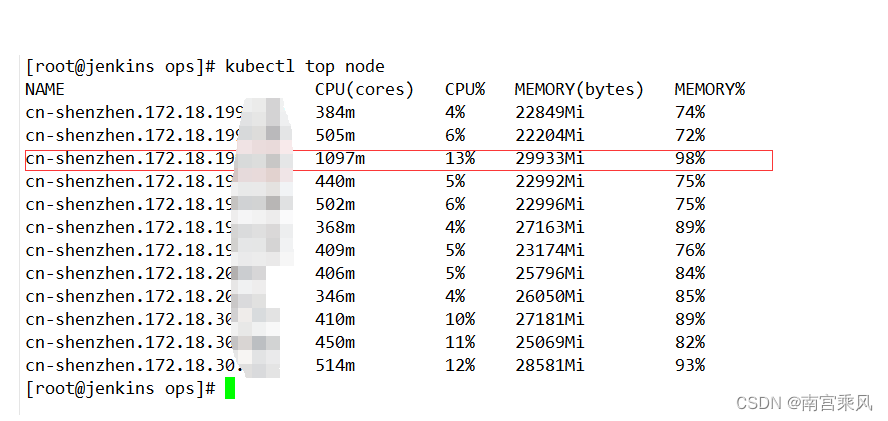
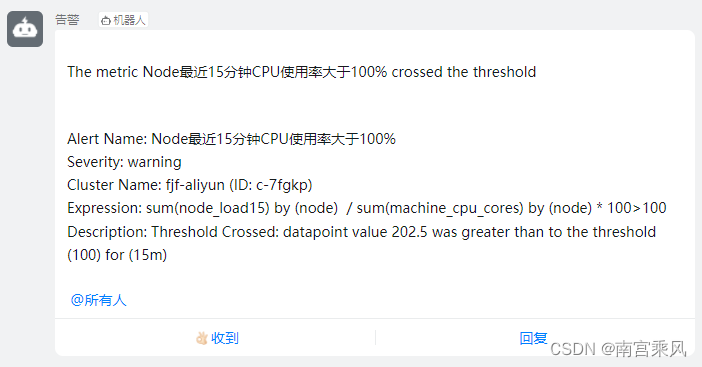
注意到一个节点的内存使用率非常高,一些 Pods 在这个节点上无法正常运行并不断重启。经过仔细研究,发现是因为这个节点的内存资源不足,导致一些高内存需求的 Pods 无法正常运行。您决定实施一种解决方案,以确保这些高内存需求的 Pods 不会被调度到这个节点上,直到您能够通过扩容或升级硬件等方式来解决这个问题。
方案
为了实现这个解决方案,您决定使用 Kubernetes 中的污点(Taint)和容忍度(Toleration)机制。您将首先添加一个污点到这个节点,以标识它当前无法容纳高内存需求的 Pods。然后,您将在这些 Pods 的 YAML 文件中添加容忍度字段,以允许它们在具有更充足内存资源的其他节点上运行。最后,您将设置 SchedulingDisabled 标志,以确保后续的 Pods 不会被调度到这个节点上,直到您解决了该节点的内存问题。
脚本
#!/bin/bash
# 功能:控制节点内存
# 如果节点内存占用率超过 90%,则禁止在该节点上调度 Pod
# 如果节点内存占用率低于平均值且平均值小于 90%,则允许在该节点上调度 Pod
# 使用 kubectl top 命令获取节点的内存占用率,并忽略掉一些特定的节点
data=$(kubectl top node | grep -v "MEMORY" | grep -v "cn-shenzhen" | sed "s/%//g")
# 计算所有节点的内存占用率的平均值
avg=$(echo "$data" | awk '{ sum += $NF } END { print sum / NR }' | awk -F. '{ print $1 }')
# 逐行读取每个节点的信息(节点名称和内存占用率)
echo "$data" | awk '{ print $1, $NF }' | while read line
do
# 获取节点名称和内存占用率
n=$(echo $line | awk '{ print $1 }')
m=$(echo $line | awk '{ print $2 }')
# 如果内存占用率超过 90%,并且该节点没有被设置为不可调度状态,则禁止在该节点上调度 Pod
if [ "$m" -ge "90" ];then
if kubectl get node | grep $n | grep -q "SchedulingDisabled";then
continue
else
kubectl cordon $n
fi
# 如果内存占用率低于平均值且平均值小于 90%,并且该节点已被设置为不可调度状态,则允许在该节点上调度 Pod
elif [ "$m" -lt "$avg" ] && [ "$avg" -lt "90" ];then
if kubectl get node | grep $n | grep -q "SchedulingDisabled";then
kubectl uncordon $n
fi
fi
done

原理
该脚本的原理是通过获取节点的内存占用率,并根据预设的阈值进行判断和操作。具体流程如下:
- 使用 kubectl top 命令获取节点的内存占用率,并忽略掉特定的节点。
- 计算所有节点的内存占用率的平均值。
- 逐行读取每个节点的信息,包括节点名称和内存占用率。
- 如果节点内存占用率超过设定的阈值(例如 90%),并且该节点没有被设置为不可调度状态,则禁止在该节点上调度 Pod。
- 如果节点内存占用率低于平均值且平均值小于阈值,并且该节点已被设置为不可调度状态,则允许在该节点上调度 Pod。
通过这样的原理,我们可以在集群中实现对节点内存的动态管理,确保节点资源的合理利用和容器应用的稳定运行。
优势
自动化管理: 该脚本实现了自动化的节点内存管理,无需手动干预,减轻了运维人员的负担。
实时监测:通过定期执行脚本,可以实时监测节点的内存占用情况,及时做出调整,提高了容器应用的性能和可用性。
智能决策:根据设定的阈值和平均值,脚本能够智能地决策是否禁止或允许在节点上调度 Pod,确保资源的合理分配。
缺点
依赖性: 该脚本依赖于 Kubernetes 命令行工具 kubectl 和集群的配置,因此需要保证环境的正确配置和可用性。
单一维度: 该脚本仅基于节点的内存占用率进行管理,没有考虑其他资源(如 CPU、存储)的情况,因此在综合资源管理方面还有待完善。