一、准备工作
(一)准备文件
1、准备本地系统文件


2、把文件上传到HDFS


(二)启动Spark Shell
1、启动HDFS服务
2、启动Spark服务

3、启动Spark Shell
二、掌握转换算子
(一)映射算子 - map()
映射算子案例

任务1、将rdd1每个元素翻倍得到rdd2
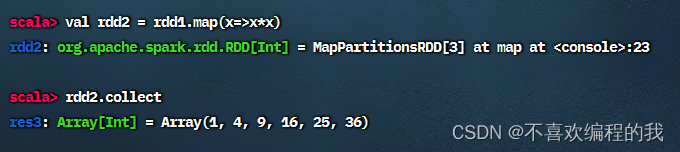
对rdd1应用map()算子,将rdd1中的每个元素平方并返回一个名为rdd2的新RDD

其实,利用神奇占位符_可以写得更简洁

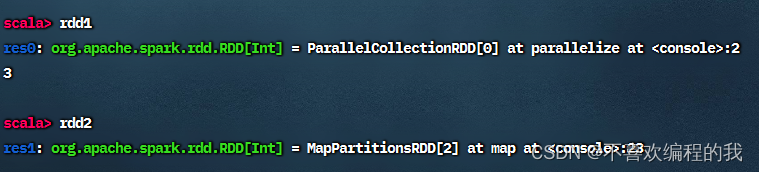
rdd1和rdd2中实际上没有任何数据,因为parallelize()和map()都为转化算子,调用转化算子不会立即计算结果。
执行rdd2.collect进行计算,并将结果以数组的形式收集到当前Driver。因为RDD的元素为分布式的,数据可能分布在不同的节点上。

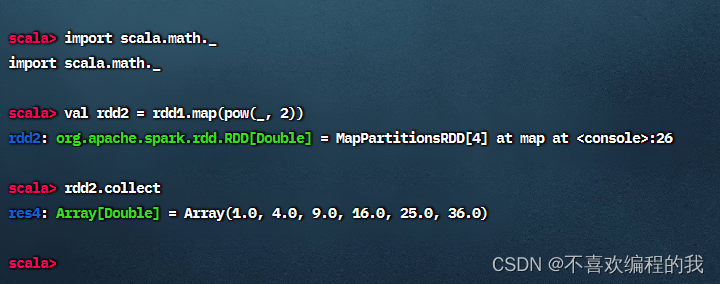
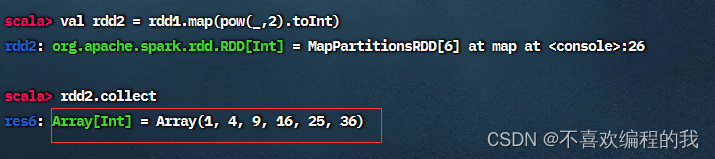
任务2、将rdd1每个元素平方得到rdd2
方法一、采用普通函数作为参数传给map()算子
方法二、采用下划线表达式作为参数传给map()算子

难道就不能用下划线参数了吗?当然可以,但是必须保证下划线表达式里下划线只出现1次。引入数学包scala.math._就可以搞定。
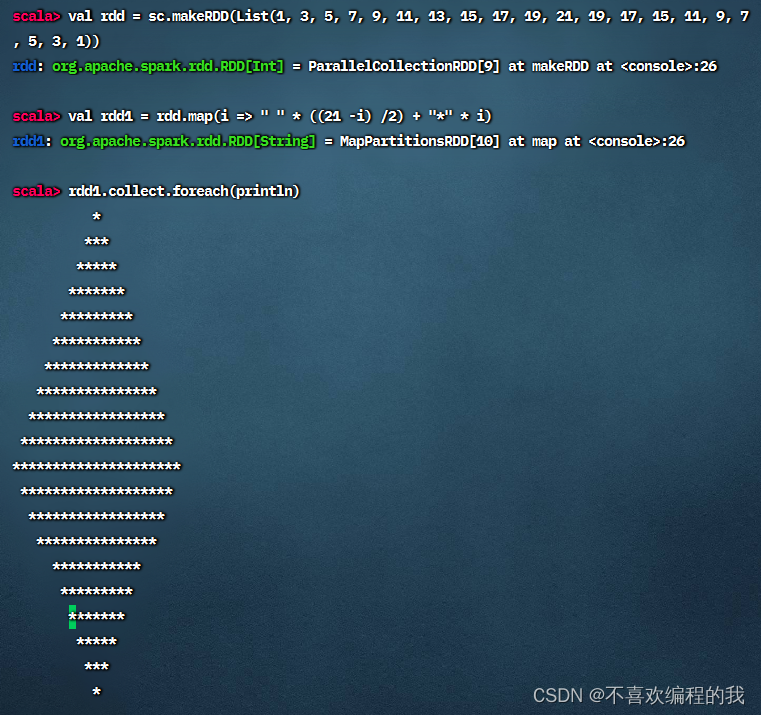
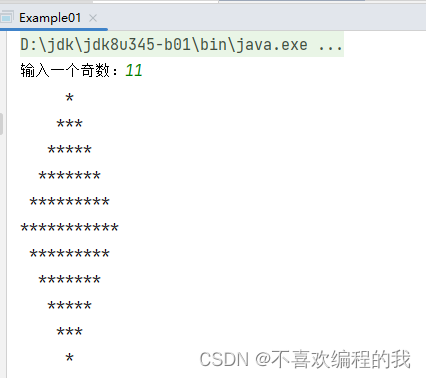
任务3、利用映射算子打印菱形
(1)Spark Shell里实现
菱形正立的等腰三角形和倒立的等腰三角形组合而成

(2)在IDEA里创建项目实现
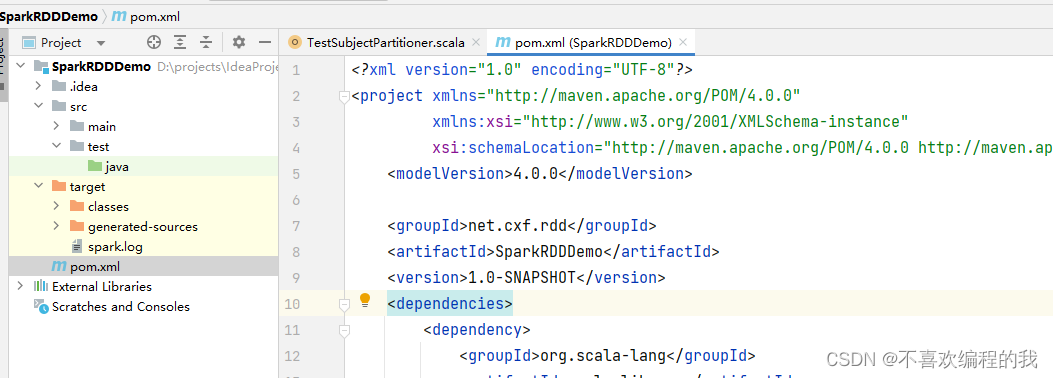
将java目录改成scala目录
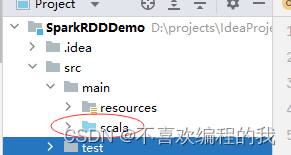
在pom.xml文件里添加相关依赖和设置源程序目录
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.cxf.rdd</groupId>
<artifactId>SparkRDDDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.15</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
</build>
</project>
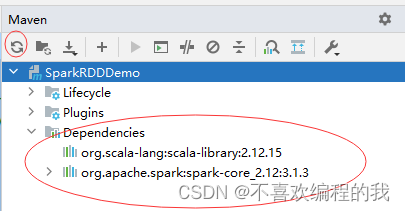
刷新项目依赖
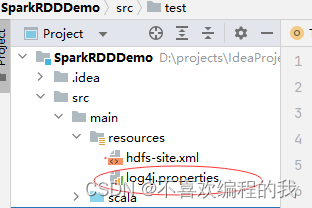
添加日志属性文件
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
创建hdfs-site.xml文件,允许客户端访问集群数据节点
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<description>only config in clients</description>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
</configuration>
创建net.cxf.rdd.day01包
在包里创建Example01单例对象
package net.cxf.rdd.day01
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
import scala.io.StdIn
/**
* 功能:
* 作者:cxf
* 日期:2023年04月19日
*/
object Example01 {
def main(args: Array[String]): Unit = {
//创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") //设置应用名称
.setMaster("local[*]") //设置主节点位置(本地调试)
//基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
//输入一个奇数
print("输入一个奇数:")
val n =StdIn.readInt()
//判断n的奇偶性
if (n % 2 == 0){
println("您输入的不是奇数")
return
}
//创建一个可变列表
val list = new ListBuffer[Int]()
//给列表赋值
(1 to n by 2).foreach(list += _)
(n - 2 to 1 by -2).foreach(list += _)
//基于列表创建rdd
val rdd = sc.makeRDD(list)
//对rdd进行映射操作
val rdd1 = rdd.map(i => " " * ((n - i)/2) +"*" * i)
//输出rdd1结果
rdd1.collect.foreach(println)
}
}
(二)过滤算子 - filter()
过滤算子案例
任务1、过滤出列表中的偶数
整数(Integer):奇数(odd number)+ 偶数(even number)
基于列表创建RDD,然后利用过滤算子得到偶数构成的新RDD
方法一、将匿名函数传给过滤算子
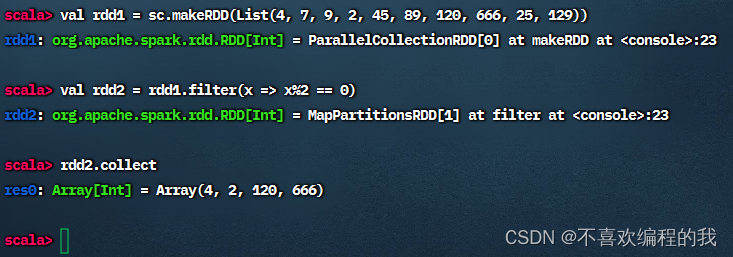
方法二、用神奇占位符改写传入过滤算子的匿名函数
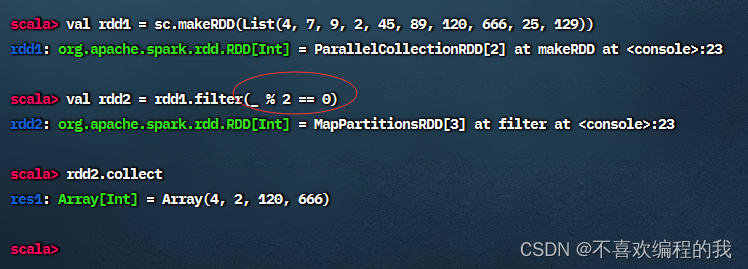
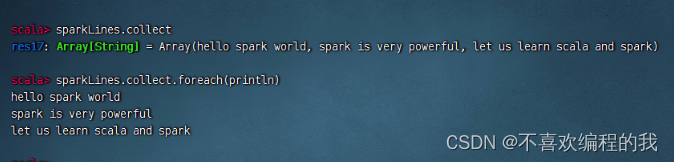
任务2、过滤出文件中包含spark的行
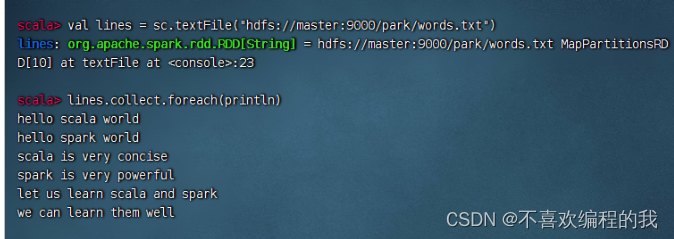
查看源文件/park/words.txt内容



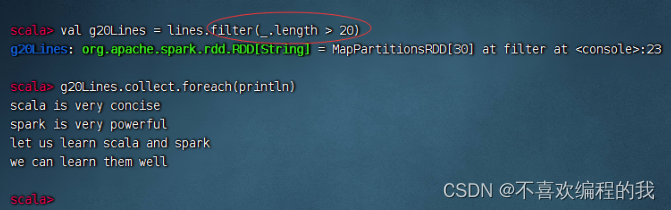
输出长度超过20的行
(三)扁平映射算子 - flatMap()
扁平映射算子案例
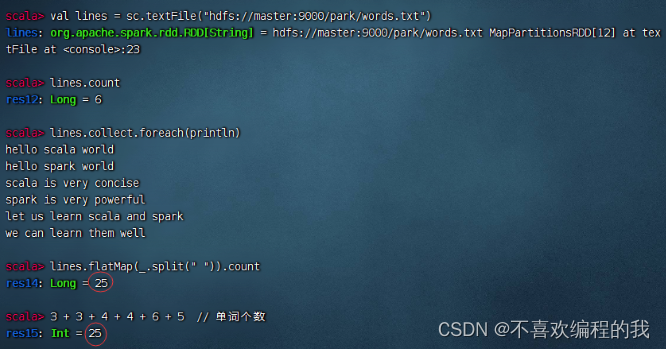
任务1、统计文件中单词个数
读取文件,生成RDD - rdd1,查看其内容和元素个数
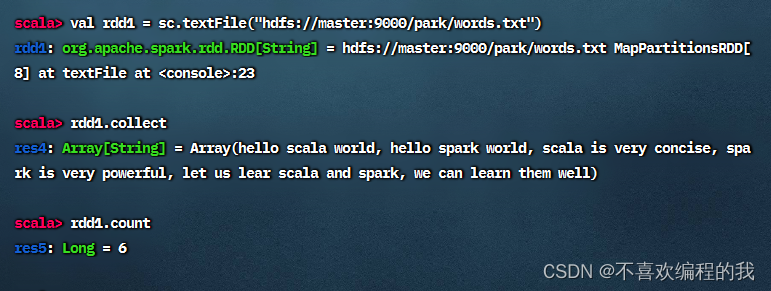
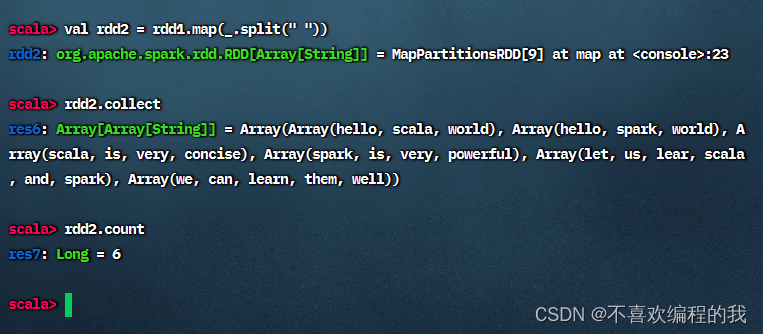
对于rdd1按空格拆分,做映射,生成新RDD - rdd2
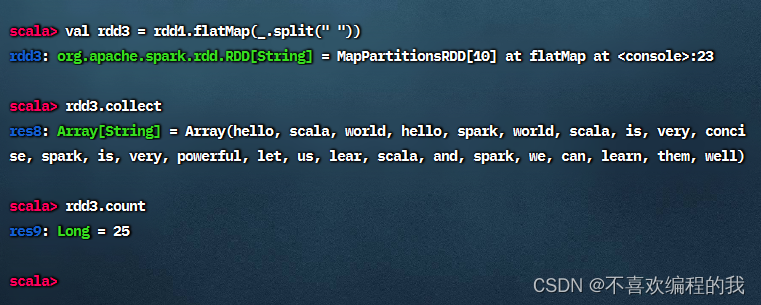
对于rdd1按空格拆分,做扁平映射,生成新RDD - rdd3,有一个降维处理的效果
任务2、统计不规则二维列表元素个数
方法一、利用Scala来实现
package net.cxf.rdd.day01
import org.apache.spark.{SparkConf, SparkContext}
/**
* 功能:利用Scala统计不规则二维列表元素个数
* 作者:cxf
* 日期:2023年04月19日
*/
object Example02 {
def main(args: Array[String]): Unit = {
//创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") //设置应用名称
.setMaster("local[*]") //设置主节点位置(本地调试)//
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
//创建不规则二维列表
val mat = List(
List(7, 8, 1, 5),
List(10, 4, 9),
List(7, 2, 8, 1, 4),
List(21, 4, 7, -4)
)
//输出二维列表
println(mat)
//将二维列表扁平化为一维列表
val arr = mat.flatten
//输出一维列表
println(arr)
//输出元素个数
println("元素个数:" + arr.size)
}
}

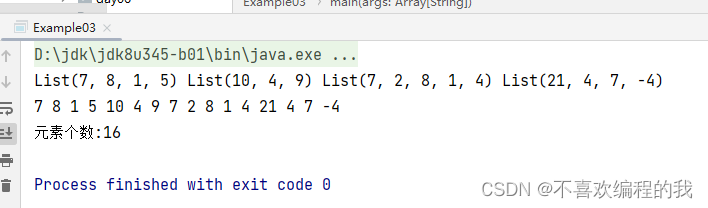
方法二、利用Spark RDD来实现
package net.cxf.rdd.day01
import org.apache.spark.{SparkConf, SparkContext}
import scala.Console.println
/**
* 功能:利用RDD统计不规则二维列表元素个数
* 作者:cxf
* 日期:2023年04月19日
*/
object Example03 {
def main(args: Array[String]): Unit = {
//创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") //设置应用名称
.setMaster("local[*]") //设置主节点位置(本地调试)//
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
//创建不规则二维列表
val mat = List(
List(7, 8, 1, 5),
List(10, 4, 9),
List(7, 2, 8, 1, 4),
List(21, 4, 7, -4)
)
//基于二维列表创建rdd1
val rdd1 = sc.makeRDD(mat)
//输出rdd1
rdd1.collect.foreach(x => print(x + " "))
println()
//进行扁平化映射
val rdd2 = rdd1.flatMap(x => x)
//输出rdd2
(rdd2.collect.foreach(x => print(x +" ")))
println()
//输出元素个数
println("元素个数:" + rdd2.count)
}
}
(四)按键归约算子 - reduceByKey()
按键归约算子案例
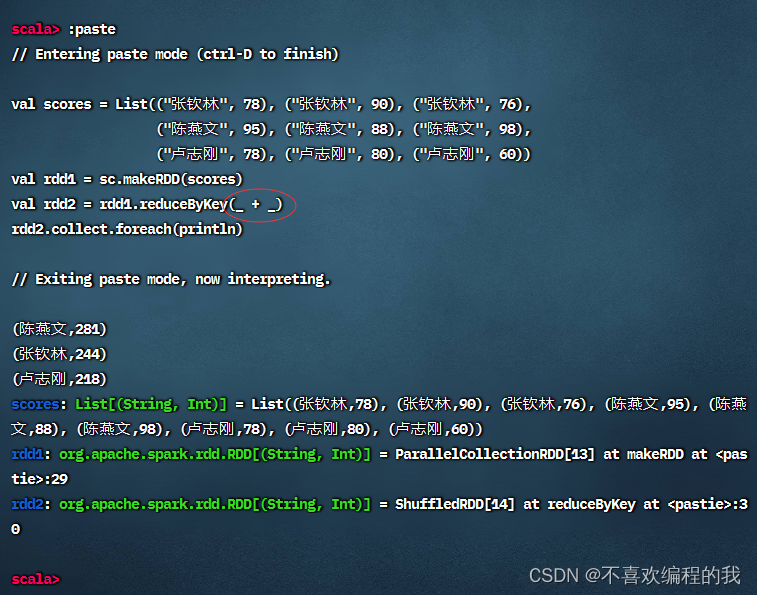
任务1、在Spark Shell里计算学生总分

可以采用神奇的占位符
任务2、在IDEA里计算学生总分
第一种方式:读取二元组成绩列表
在net.cxf.rdd.day02包里创建CalculateScoreSum01单例对象
package net.cxf.rdd.day02
package net.huawei.rdd.day02
import org.apache.spark.{SparkConf, SparkContext}
/**
* 功能:计算总分
* 作者:cxf
* 日期:2023年04月26日
*/
object CalculateScoreSum01 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
val scores = List(
("张钦林", 78), ("张钦林", 90), ("张钦林", 76),
("陈燕文", 95), ("陈燕文", 88), ("陈燕文", 98),
("卢志刚", 78), ("卢志刚", 80), ("卢志刚", 60))
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(scores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey(_ + _)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}
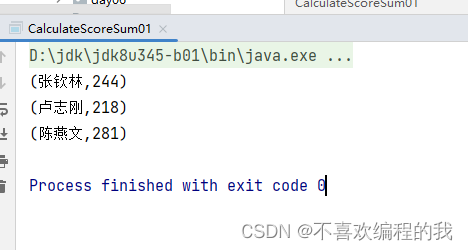
第二种方式:读取四元组成绩列表
package net.cxf.rdd.day02
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
/**
* 功能:计算总分
* 作者:cxf
* 日期:2023年04月26日
*/
object CalculateScoreSum02 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 创建四元组成绩列表
val scores = List(
("张钦林", 78, 90, 76),
("陈燕文", 95, 88, 98),
("卢志刚", 78, 80, 60)
)
// 将四元组成绩列表转化成二元组成绩列表
val newScores = new ListBuffer[(String, Int)]()
// 通过遍历算子遍历四元组成绩列表
scores.foreach(score => {
newScores.append(Tuple2(score._1, score._2))
newScores.append(Tuple2(score._1, score._3))
newScores.append(Tuple2(score._1, score._4))}
)
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(newScores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey(_ + _)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}
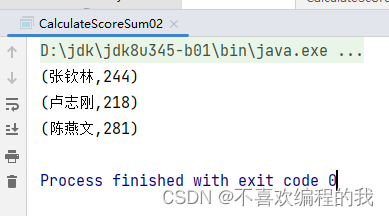
第三种情况:读取HDFS上的成绩文件
在master虚拟机的/home目录里创建成绩文件 - scores.txt

将成绩文件上传到HDFS的/input目录
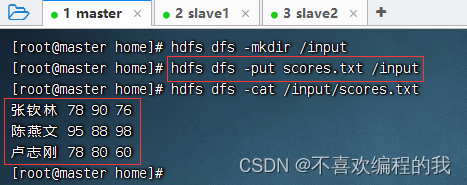
在net.cxf.rdd.day02包里创建CalculateScoreSum03单例对象
package net.cxf.rdd.day02
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
/**
* 功能:计算总分
* 作者:cxf
* 日期:2023年04月26日
*/
object CalculateScoreSum03 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PtintDiamond")
.setMaster("local[*]")
// 基于配置创建Spark上下文
val sc = new SparkContext(conf)
// 读取成绩文件,生成RDD
val lines = sc.textFile("hdfs://master:9000/input/scores.txt")
// 定义二元组成绩列表
val scores = new ListBuffer[(String, Int)]()
// 遍历lines,填充二元组成绩列表
lines.collect.foreach(line => {
val fields = line.split(" ")
scores += Tuple2(fields(0), fields(1).toInt)
scores += Tuple2(fields(0), fields(2).toInt)
scores += Tuple2(fields(0), fields(3).toInt)
})
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(scores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
// 输出归约处理结果
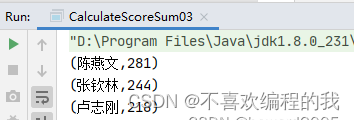
rdd2.collect.foreach(println)
//将计算结果写入HDFS文件
rdd2.saveAsTextFile("hdfs://master:9000/output")
}
}
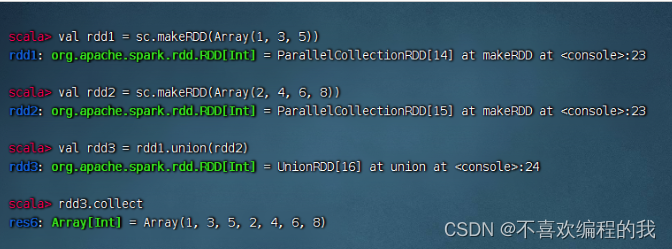
(五)合并算子 - union()
合并算子案例
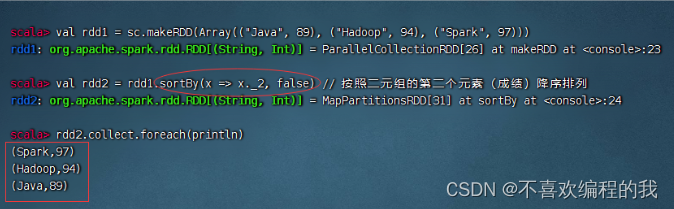
(六)排序算子 - sortBy()
排序算子案例
一个数组中存放了三个元组,将该数组转为RDD集合,然后对该RDD按照每个元素中的第二个值进行降序排列。
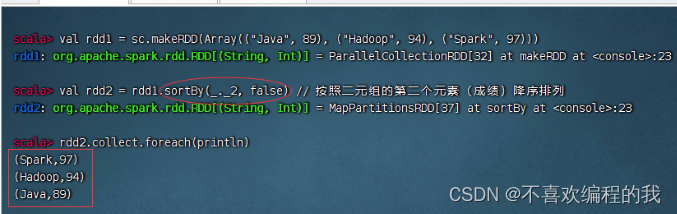
(七)按键排序算子 - sortByKey()
按键排序算子案例
将三个二元组构成的RDD按键先降序排列,然后升序排列
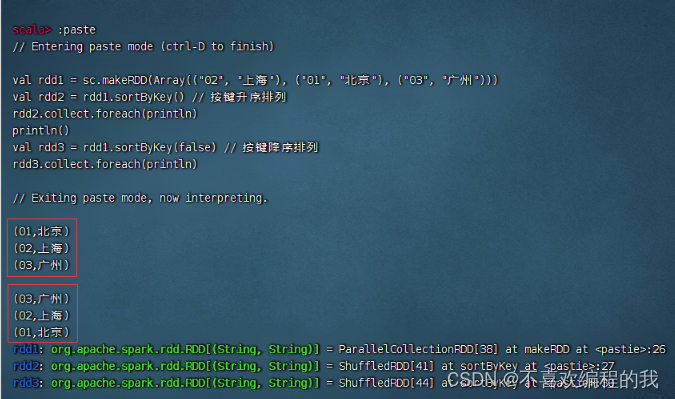
其实,用排序算子也是可以搞定的

(八)连接算子
1、内连接算子 - join()
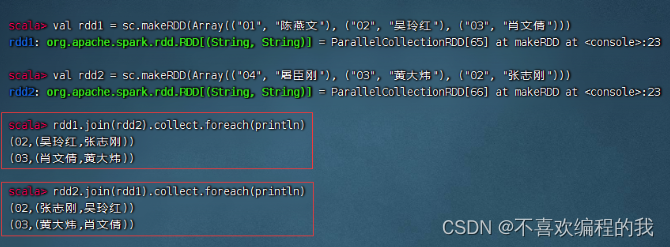
内连接算子案例
将rdd1与rdd2进行内连接
2、左外连接算子 - leftOuterJoin()
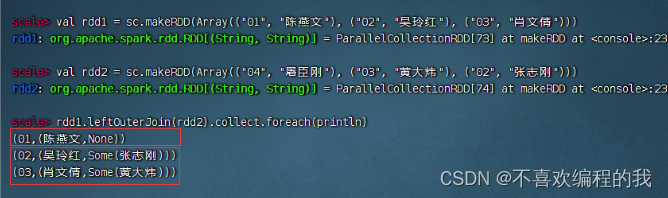
左外连接算子案例
rdd1与rdd2进行左外连接
3、右外连接算子 - rightOuterJoin()
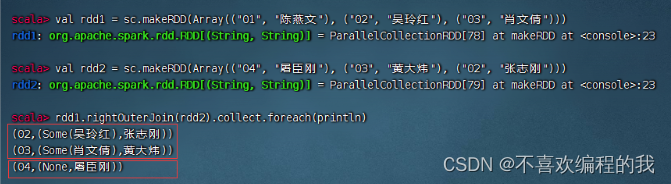
右外连接算子案例
rdd1与rdd2进行右外连接
4、全外连接算子 - fullOuterJoin()
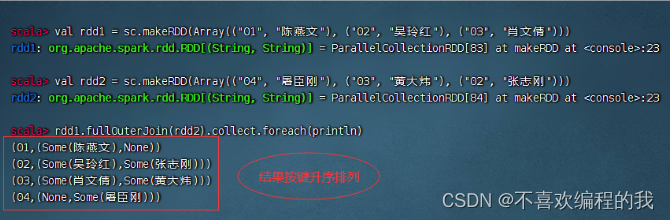
全外连接算子案例
rdd1与rdd2进行全外连接
(九)交集算子 - intersection()
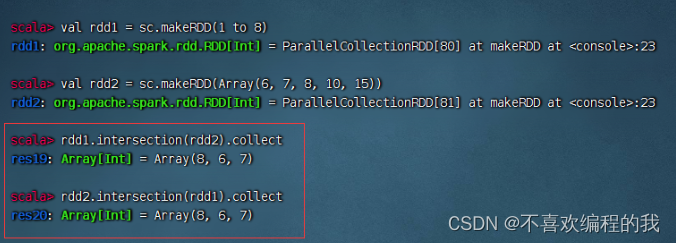
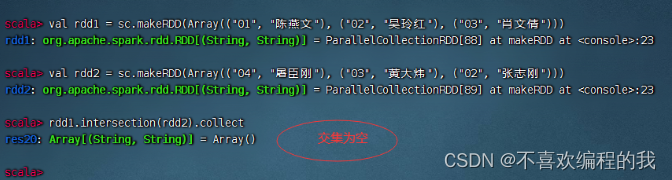
交集算子案例
rdd1与rdd2进行交集操作,满足交换律
A ∩ B ≠ ϕ
(十)去重算子 - distinct()
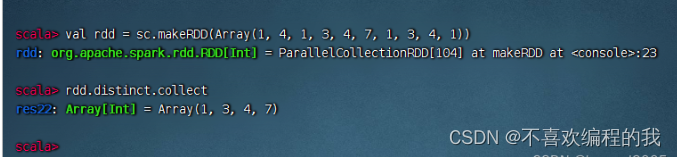
1、去重算子案例
去掉rdd中重复的元素
2、IP地址去重案例
在项目根目录创建ips.txt文件
192.168.234.21
192.168.234.22
192.168.234.21
192.168.234.21
192.168.234.23
192.168.234.21
192.168.234.21
192.168.234.21
192.168.234.25
192.168.234.21
192.168.234.21
192.168.234.26
192.168.234.21
192.168.234.27
192.168.234.21
192.168.234.27
192.168.234.21
192.168.234.29
192.168.234.21
192.168.234.26
192.168.234.21
192.168.234.25
192.168.234.25
192.168.234.21
192.168.234.22
192.168.234.21
在net.cxf.rdd.day03包里创建DistinctIPs单例对象
package net.cxf.rdd.day03
import org.apache.spark.{SparkConf, SparkContext}
/**
* 功能:ip地址去重
* 作者:cxf
* 日期:2023年04月26日
*/
object DistinctlPs {
def main(args: Array[String]): Unit = {
//创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond")// 设置应用名称
.setMaster("local[*]") //设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
//读取IP地址文件,得到RDD
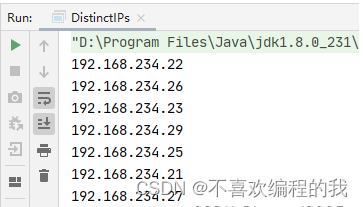
val ips = sc.textFile("file://D:/IdeaProjects/SparkRDDDemo/ips.txt") //
// rdd去重再输出
ips.distinct.collect.foreach(println)
}
}
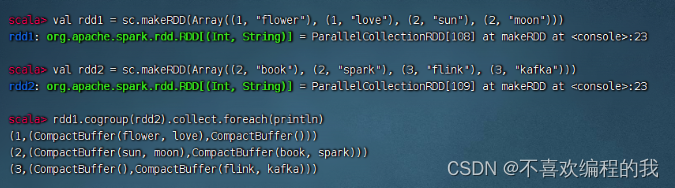
(十一)组合分组算子 - cogroup()
组合分组算子案例
rdd1与rdd2进行组合分组操作
三、掌握行动算子
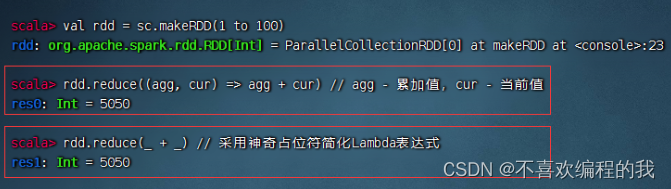
(一)归约算子 - reduce()
归约算子案例
计算1 + 2 + 3 + … … + 100 1 + 2 + 3 + …… + 1001+2+3+……+100的值
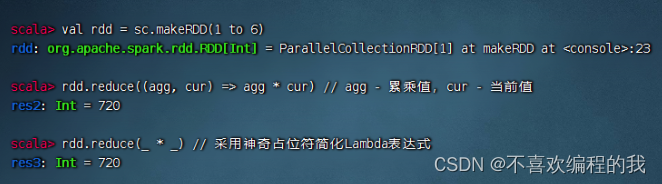
计算1 × 2 × 3 × 4 × 5 × 6 的值(阶乘 - 累乘)
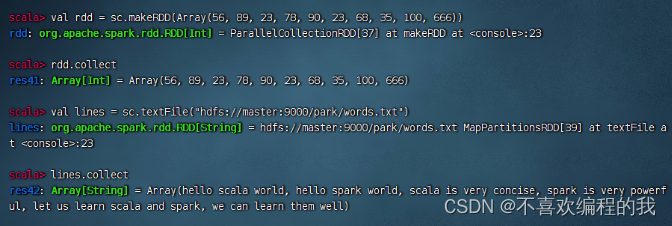
(二)采集算子 - collect()
采集算子案例
显示RDD的全部元素
(三)首元素算子 - first()
首元素算子案例
显示RDD的首元素
(四)计数算子 - count()
计数算子案例
统计RDD的元素个数
如果要统计单词个数,那就要采用扁平映射算子
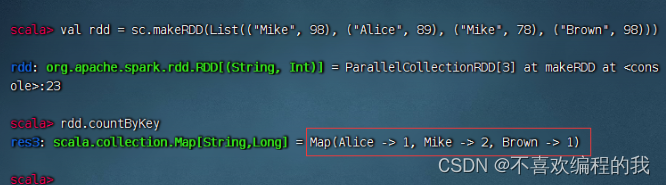
(五)按键计数算子 - countByKey()
按键计数算子案例
List集合中存储的是键值对形式的元组,使用该List集合创建一个RDD,然后对其进行countByKey的计算
注意:元素必须是键值对的二元组,不能是三元组

(六)前截取算子 - take(n)
前截取算子案例
返回集合中前任意多个元素组成的数组
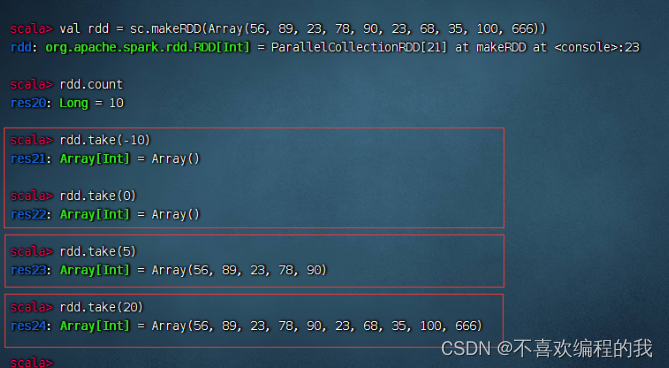
(七)排序前截取算子 - takeOrdered(n)[(ordering)]
排序前截取算子案例
返回RDD前n个元素(升序)
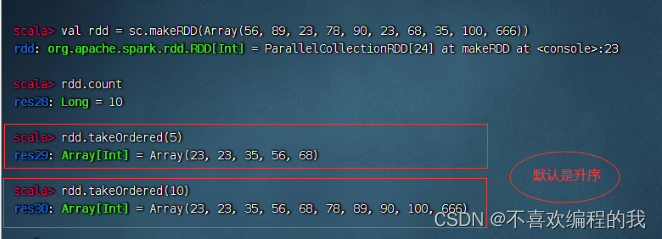
返回前n个元素(降序)
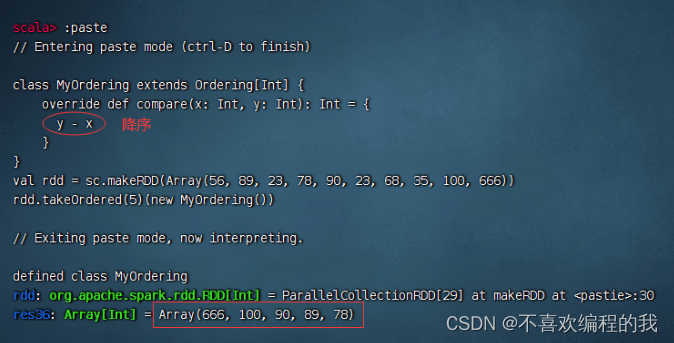
其实,可以top(n)算子来实现同样的效果,更简单

(八)遍历算子 - foreach()
遍历算子案例
将RDD里的每个元素平方后输出(一定要采集,才能遍历)
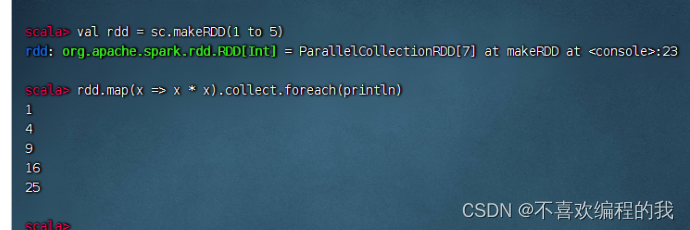
将RDD的内容逐行打印输出
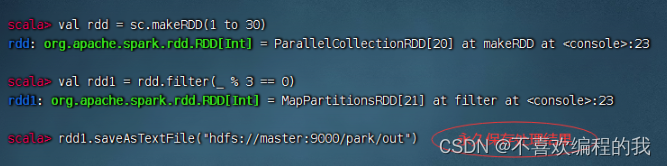
(九)存文件算子 - saveAsFile()
存文件算子案例
将rdd内容保存到HDFS的/park/out目录
查看另存的结果文件