PyCharm是一种Python IDE,其带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具。此外,该IDE提供了一些高级功能,以用于Django框架下的专业Web开发。
PyCharm 最新下载
本文将展示如何使用免费的 PyCharm Community Edition 开发简单的 CLI 应用程序来自动执行日常任务。 虽然在本教程结束时您将获得一个可用的密码短语生成器,但请仅将其视为一个学习项目。 切勿使用此生成器生成的密码短语保护任何真实数据。
关于密码短语
什么是密码短语?
我们每天都会使用很多密码。 注册使用服务或网站时,您都需要创建一个长而独一无二的密码,包含数字、特殊字符、大写字母等。
这些要求都是为了使密码能够抵抗暴力攻击。 暴力攻击基本上是多次尝试猜测密码,直到最终猜对为止。 需要多少尝试和多长时间取决于密码的长度和复杂度。
密码短语是由多个随机单词组成的密码。 它不需要有意义,也不需要符合语法规则。 密码短语通常包含 4 到 5 个单词,越多越好。 例如,PhysicianBuiltHotPotatoRegularly 就是一个密码短语。
为什么密码短语更好?
A^1rL#2k2oPiA9H 是一个安全系数高的好密码。 它包含大小写字母、数字、特殊符号,长度为 15 个字符。 但是您更愿意记住哪个,A^1rL#2k2oPiA9H 还是 PhysicianBuiltHotPotatoRegularly? 顺便说一下,后者有 32 个字符。
除了记住密码的难易程度之外,我们还应该注意破解密码的难易程度。 来看下表:
| A^1rL#2k2oPiA9H | PhysicianBuiltHotPotatoRegularly | |
| 符号集大小 | 95 | 52 |
| 密码长度 | 15 | 32 |
| 破解所需的尝试次数 | 2 98 | 2 182 |
两者都很强,但密码短语安全系数更高且更好记。 另外,如果在密码短语中添加一些数字和特殊字符,这将使所需的平均猜测次数增加到 2210 次 – 几乎不可能破解!
综上:
- 由随机单词组成的密码短语比由随机字符组成的密码更好记。
- 密码短语通常比密码更长,因此更能抵抗暴力攻击,更安全。
- 密码短语可以根据复杂度要求进行修改。 例如,您可以将单词大写来包含大写字母,或者在单词之间添加特殊字符和数字作为分隔符。
什么是密码短语生成器
通常,密码短语生成器是一种将随机单词组合成伪句来生成密码的程序。 在本教程中,我们将使用 PyCharm 和 Typer 开发一个命令行工具,它将执行以下操作:
- 生成由 4-5 个随机单词组成的密码短语。
- 按照选项将密码短语中的单词大写。 单词默认不大写。
- 使用任意符号作为单词的分隔符。 默认不含分隔符。
- 添加第五个单词,创建更长的密码短语。 默认长度为四个单词。
工具不会存储您的密码短语。
先决条件
- 具备 Python 经验。
- PyCharm Community Edition 2023.1 或更高版本。
- Python(可以在创建项目时下载)。
第一步
使用 Typer 编写“Hello World”
首次启动 PyCharm 时,您会看到欢迎屏幕。 点击 New Project:
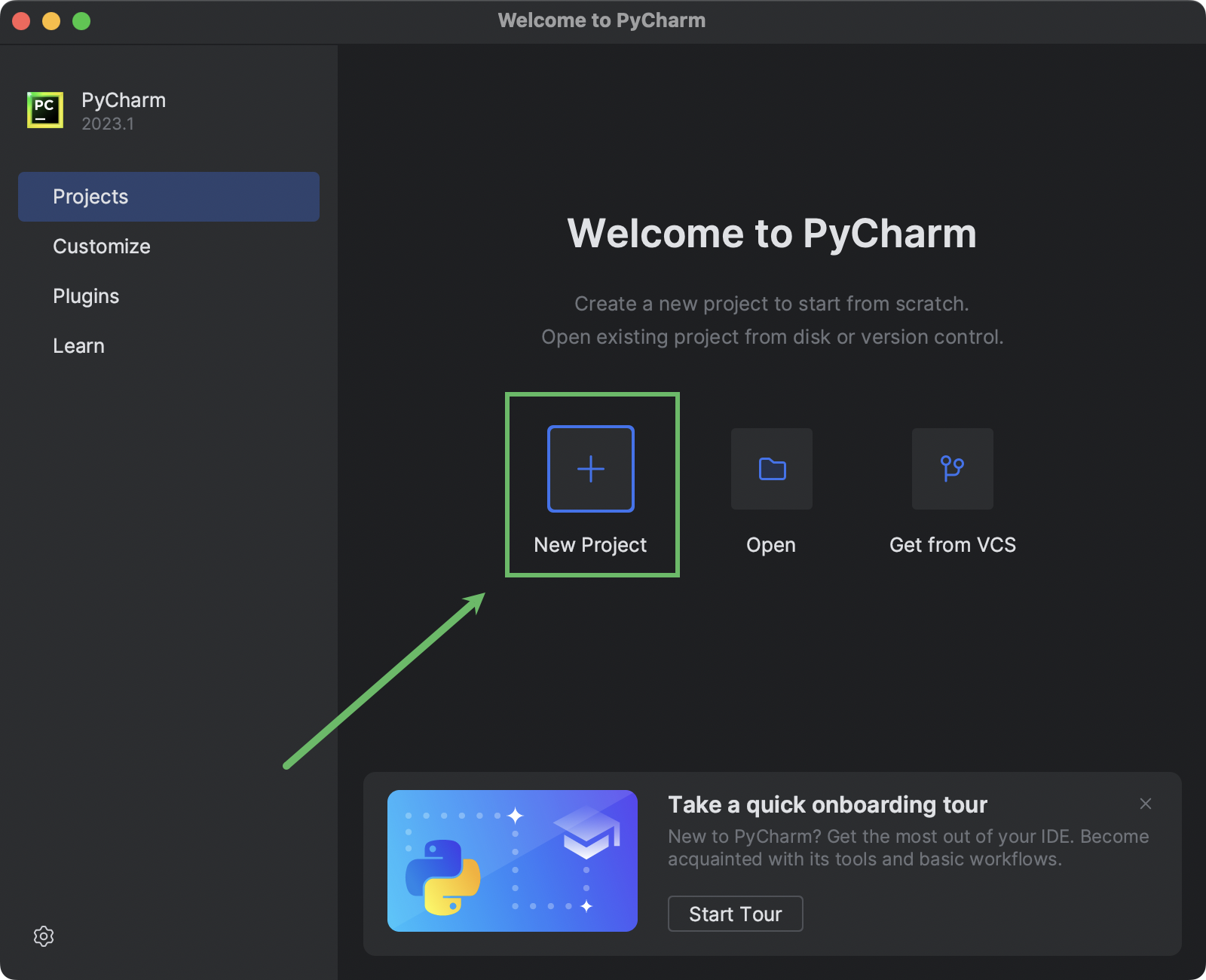
如果 PyCharm 已经在运行,可以从主菜单中选择 File | New Project。
在 “New Project”窗口打开后,找到顶部的 Location字段,使用它指定项目的目录。 这也将用作项目名称。
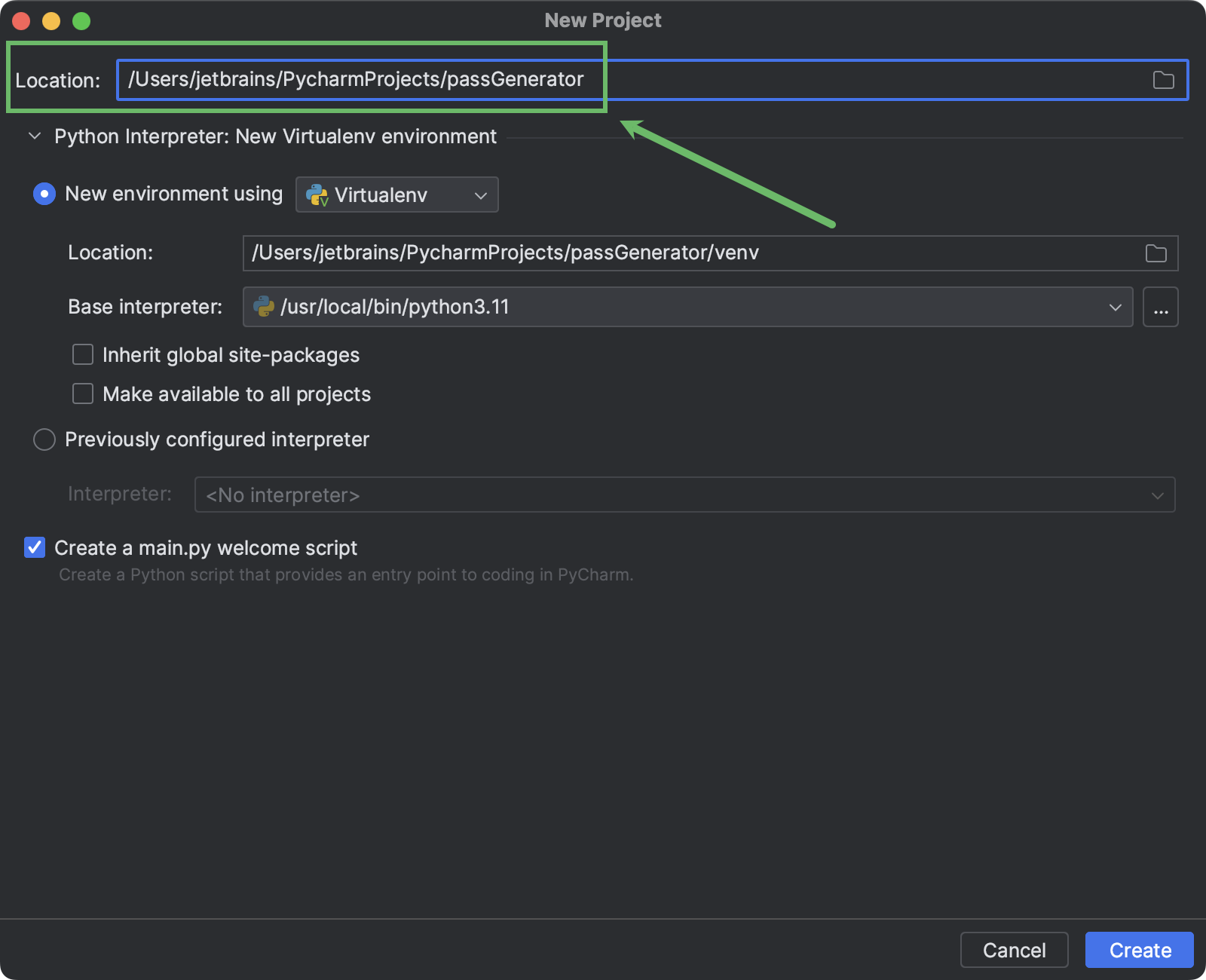
您可以选择 PyCharm 将在其中安装项目依赖项的虚拟环境的类型。 您还可以选择创建环境的位置,以及基础 Python 解释器。
选择首选环境类型并指定选项(或保留默认值),然后点击 Create(创建)。
PyCharm 将创建包含虚拟环境的项目目录(在我们的示例中为 venv)。 如果您在上一步中没有清除 Create a main.py welcome script 复选框,它也会创建 main.py 并在编辑器中将其打开:
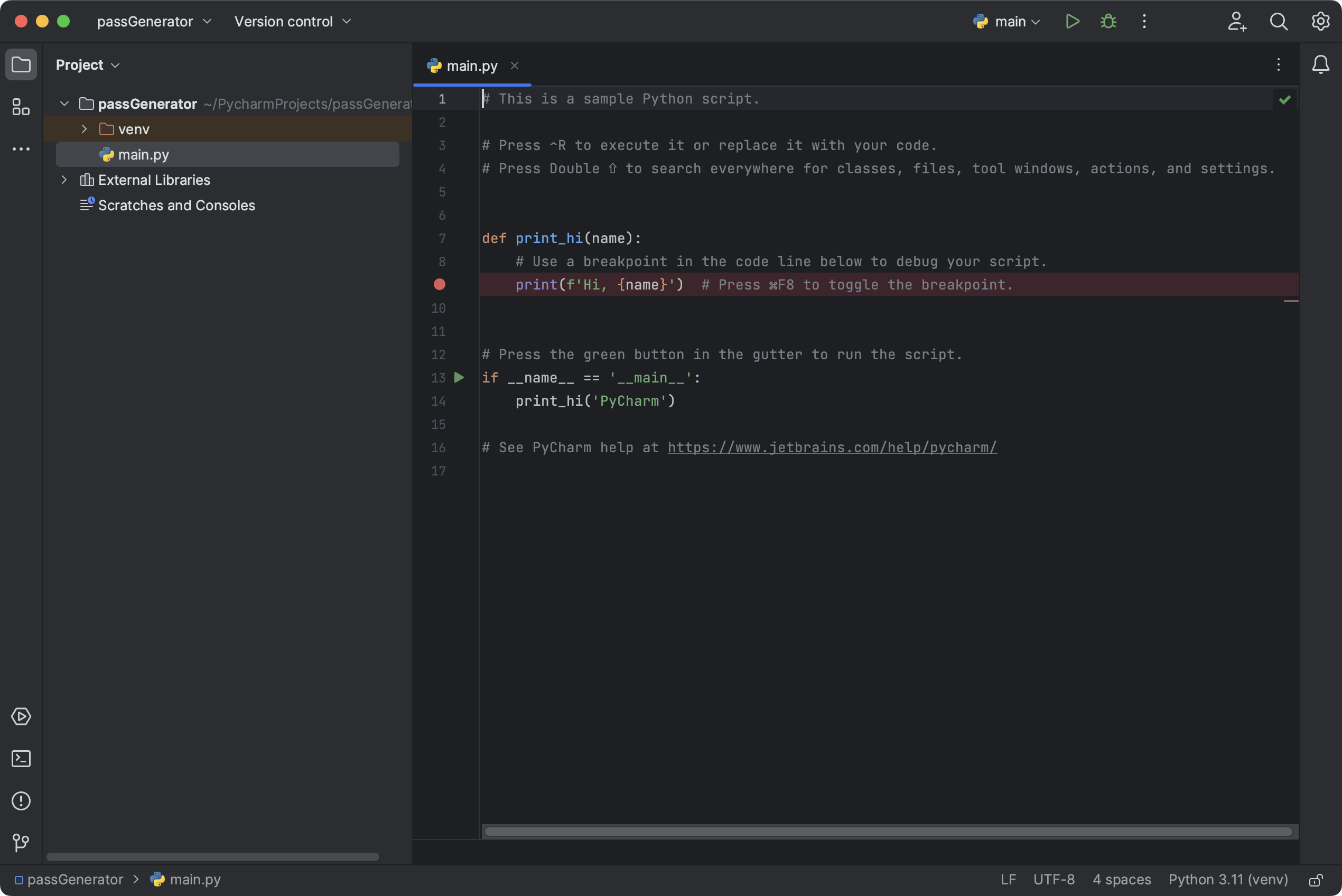
文件包含带有一些基本指令的“Hello World”脚本。 将以下代码复制到剪贴板:
def main():
print("Hello World")
if __name__ == "__main__":
typer.run(main)转到 PyCharm,按 ⌘A / Ctrl+A,然后按 ⌘V / Ctrl+V 替换 main.py 的内容。 您将得到:
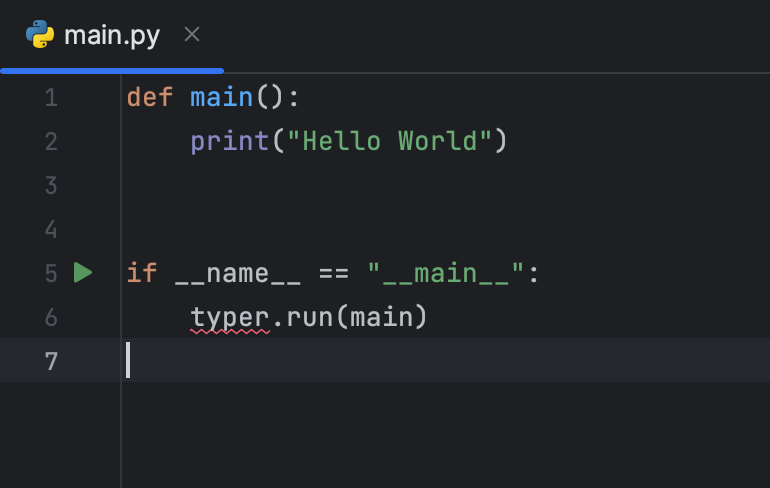
您可以看到 ”typer“按钮下方有一条红色波浪线。 这表示 Python 解释器无法识别 Type。 我们需要安装此软件包并将其导入 main.py 才能启动脚本。
将鼠标指针悬停在高亮显示的符号上,然后在弹出窗口中选择 Install and import package ‘typer’(安装并导入软件包 ‘typer’):
PyCharm 会将 Typer 软件包安装到项目环境中,并将其导入 main.py。
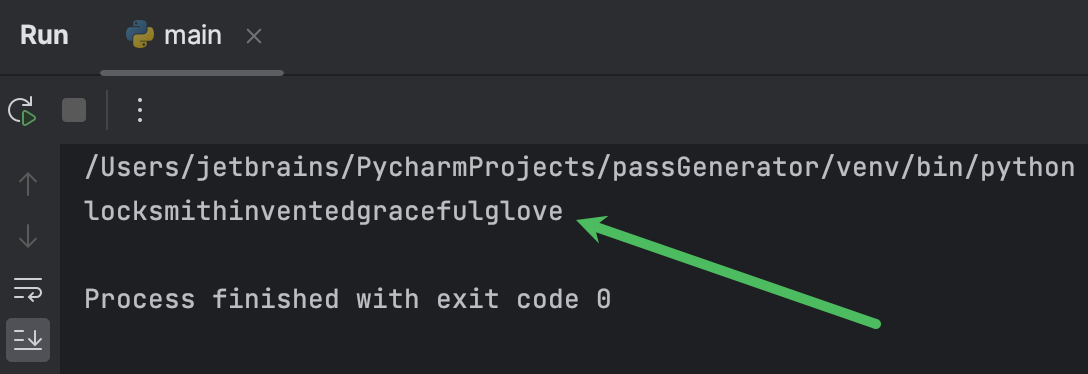
现在,我们可以运行脚本了。 点击装订区域中的运行图标,选择 Run ‘main’:
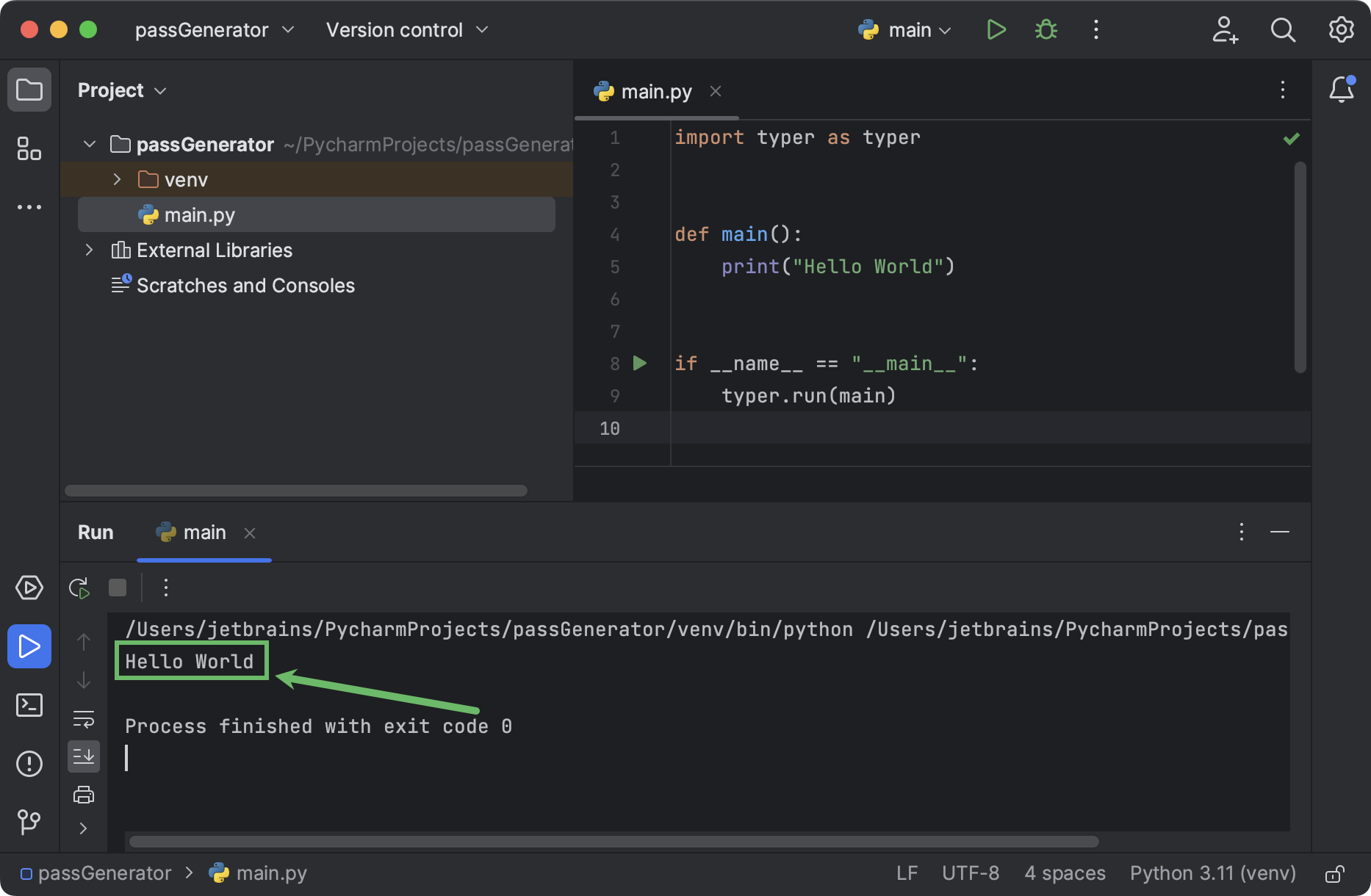
带有“Hello World”的 运行工具窗口将在底部打开:
生成第一个密码短语
修改代码,让它打印密码短语而不是“Hello World”。 这里的想法是随机挑选单词并组成短语。 因此,我们需要一个或多个可供选择的单词列表。 您可以手动准备这样的列表,也可以使用大型语言模型生成。
创建单词列表时,请确保它们的安全性。 如果恶意行为者访问了单词列表,他们将能够在几秒钟内破解您的密码。
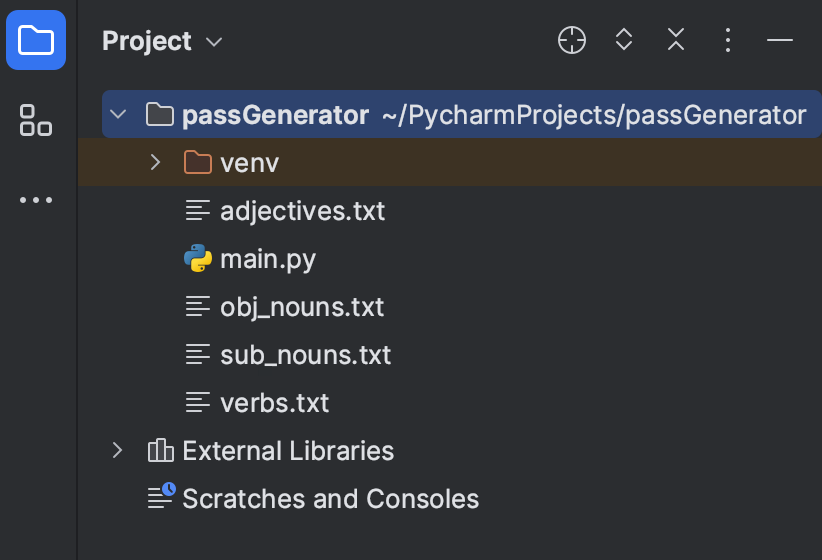
在这一步中,您需要包含 4 个单词的列表:
- obj_nouns.txt,包含将在我们生成的伪句中充当宾语的名词。
- sub_nouns.txt,包含将充当主语的名词。
- verbs.txt,包含动词。
- adjectives.txt,包含形容词。
每个列表中的单词越多,脚本能够生成的组合就越多。 每个单词都应另起一行。
将生成或下载的单词列表复制到项目目录。 如果您想手动创建单词列表,可以在 PyCharm 中进行:
- 在 Project工具窗口中点击项目目录,然后按 ⌘N / Ctrl+N。
- 选择 File,指定文件名,例如 obj_nouns.txt。
- PyCharm 将创建文件并在编辑器中将其打开。
项目结构应该如下所示:
首先,需要从文本文件读取单词。 将 print("Hello World") 替换为以下代码:
sub_nouns = read_words('sub_nouns.txt')同样,read_words 下方有一条红色波浪线。 我们需要创建这个函数。 将鼠标悬停在 read_words 上,然后在弹出窗口中点击 Create function ‘read_words’(创建函数 ‘read_words’):
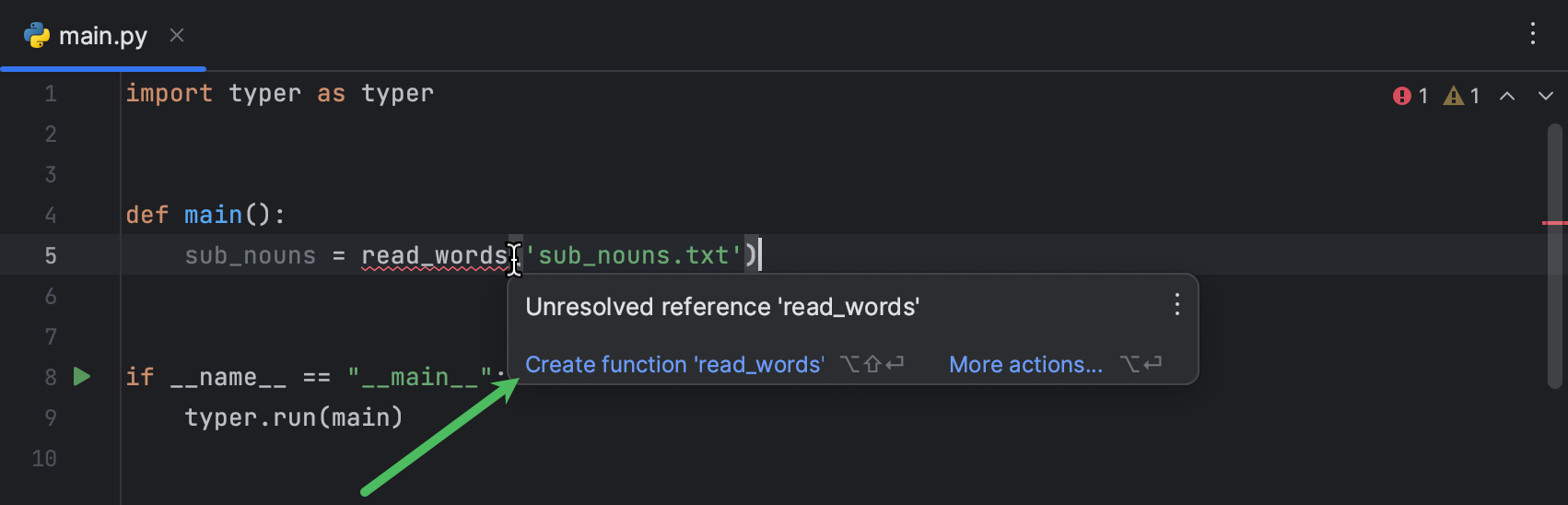
PyCharm 将创建一个函数存根。 指定 file_name 为函数形参,然后按 Tab 键开始编写函数代码:
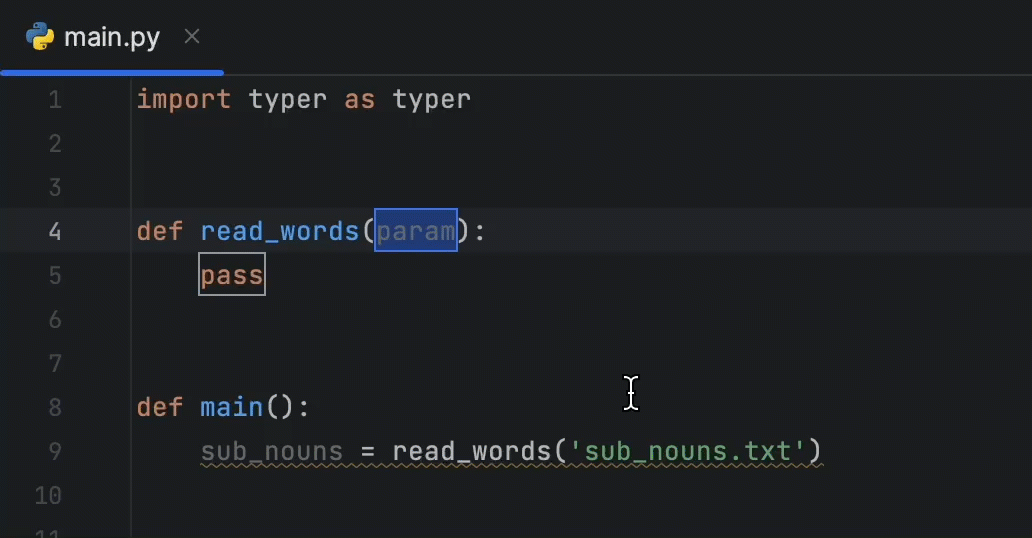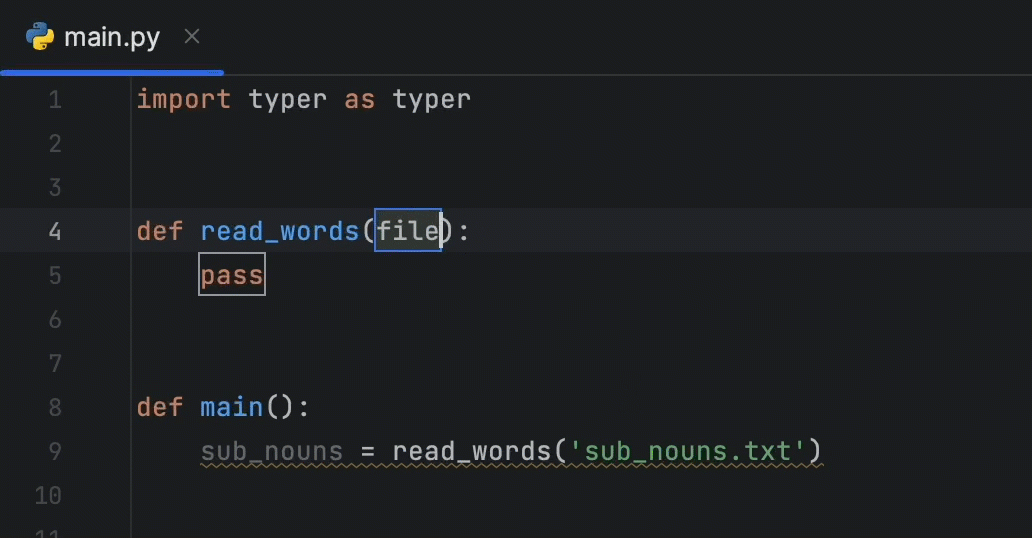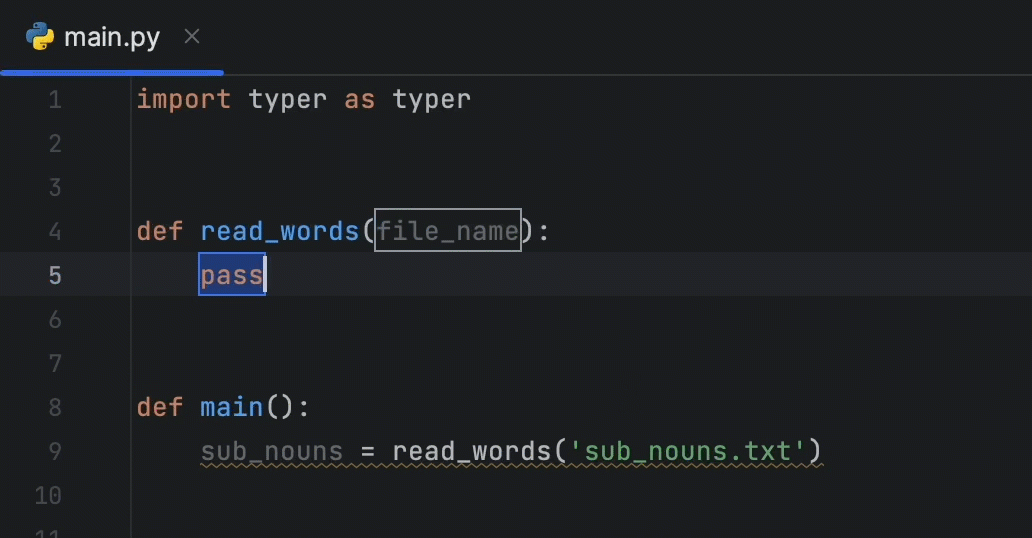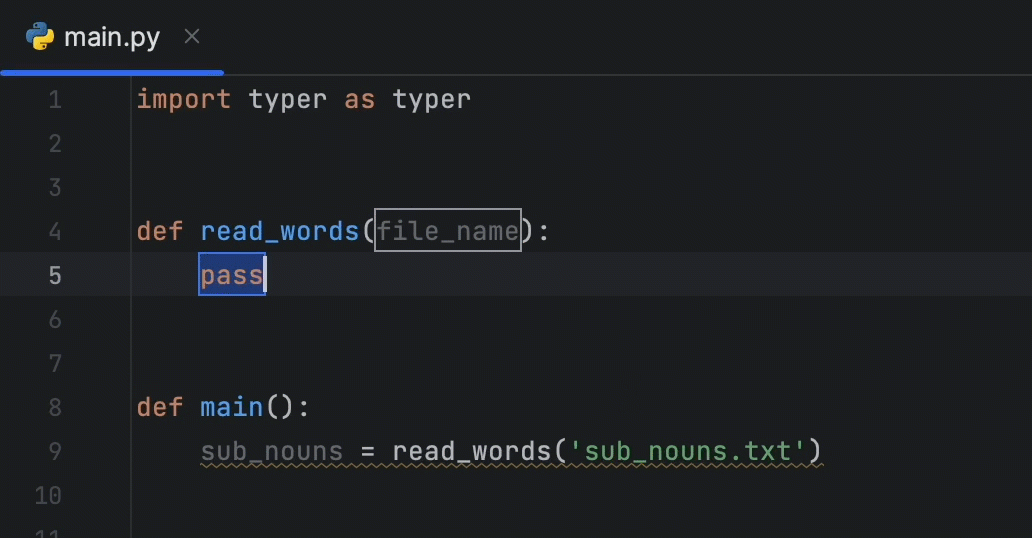
您可以将高亮显示的代码复制到函数体中:
def read_words(file_name):
with open(file_name, 'r') as f:
words = f.readlines()
return words该函数将打开名称在第一个形参中提供的文件。 然后,它会应用 readlines() 方法,这将返回包含文件行作为其元素的 Python 列表。 列表被保存到 words 变量中并由函数返回。
我们回到 main() 函数,使用新创建的 read_words 函数读取另外 3 个单词列表:
def main():
sub_nouns = read_words('sub_nouns.txt')
verbs = read_words('verbs.txt')
adjectives = read_words('adjectives.txt')
obj_nouns = read_words('obj_nouns.txt')接下来,创建一个单词列表的列表,将其命名为 word_bank。 稍后,我们将在为密码短语选择随机单词时迭代它:
word_bank = [sub_nouns, verbs, adjectives, obj_nouns]选择的随机单词将被保存到另一个列表中。 把它命名为 phrase_words 并进行初始化:
phrase_words = []在接下来的 for 循环中,我们迭代 word_bank 的条目。 word_bank 中的每个条目都是一个包含单词的列表。 我们从内置 random 模块中调用 SystemRandom() 类的 choice() 方法,从列表中选择一个随机单词。 然后,将所选单词追加到 phrase_words:
for word_list in word_bank:
random_word = random.SystemRandom().choice(word_list)
phrase_words.append(random_word)虽然 random 是内置模块,但我们还是需要导入它。 像之前一样,您可以通过编辑器中的红色波浪线来判断。 将鼠标悬停在它上面,选择 Import this name(导入此名称)。
最后,使用 join 将包含随机选择单词的列表转换成短语并打印结果:
passphrase = ''.join(phrase_words)
print(passphrase)main() 在这个阶段应该是这样的:
def main():
sub_nouns = read_words('sub_nouns.txt')
verbs = read_words('verbs.txt')
adjectives = read_words('adjectives.txt')
obj_nouns = read_words('obj_nouns.txt')
word_bank = [sub_nouns, verbs, adjectives, obj_nouns]
phrase_words = []
for word_list in word_bank:
random_word = random.SystemRandom().choice(word_list)
phrase_words.append(random_word)
passphrase = ''.join(phrase_words)
print(passphrase)现在,运行脚本来检查它是否正常运作。 点击装订区域中的 Run图标,并选择 Run ‘main’(运行 ‘main’),您应该得到:
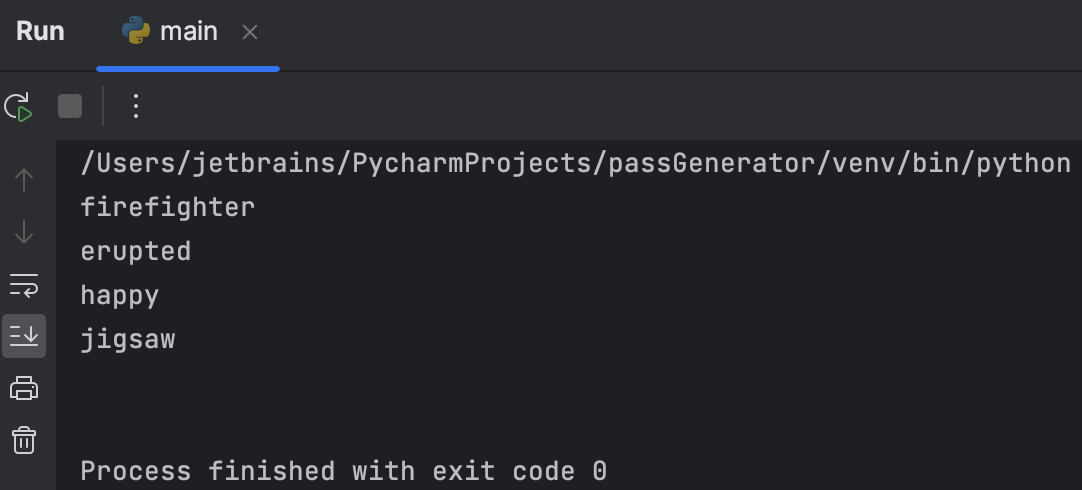
现在已经有了 4 个单词,但它绝对不是短语。 当代码正常工作但产生意外结果时,就需要进行调试。
从当前输出可以看到,脚本成功从单词列表选择了随机单词。 它没有做到的是将单词组合成短语。 main() 的倒数第二行似乎是问题根源:
def main():
...
passphrase = ''.join(phrase_words)
print(passphrase)为了查看特定代码行生成的结果,我们应该在该行上放置一个断点。 然后,调试器将在执行带有断点的行之前停止。 要设置断点,请点击要检查的行旁边的装订区域:
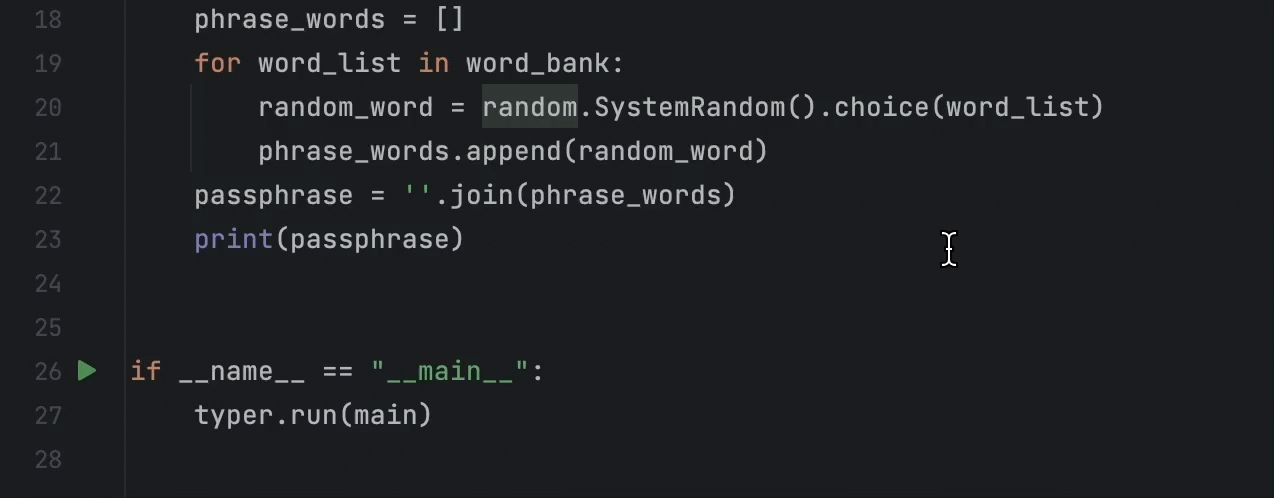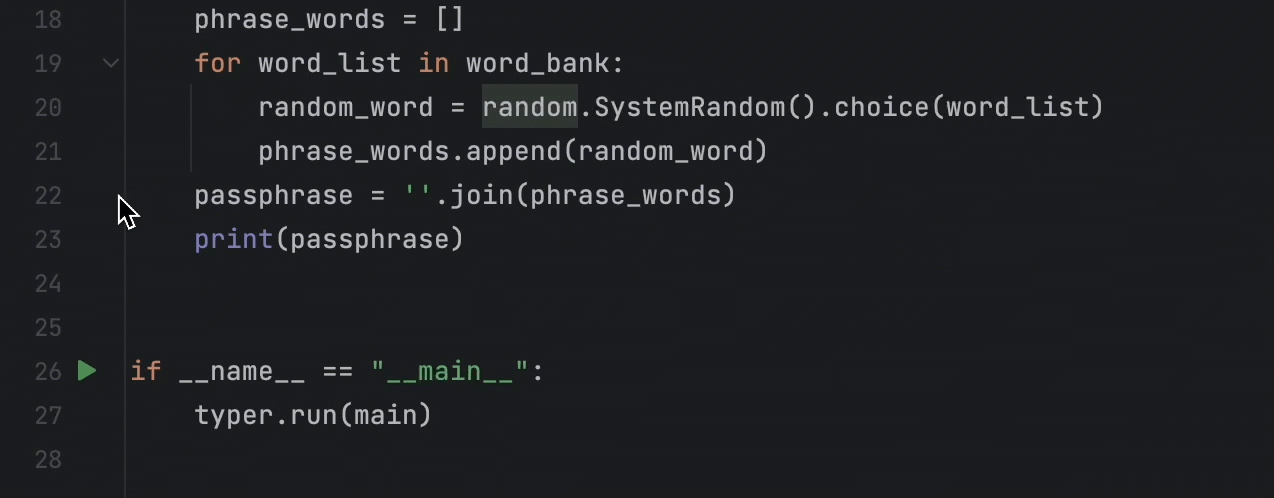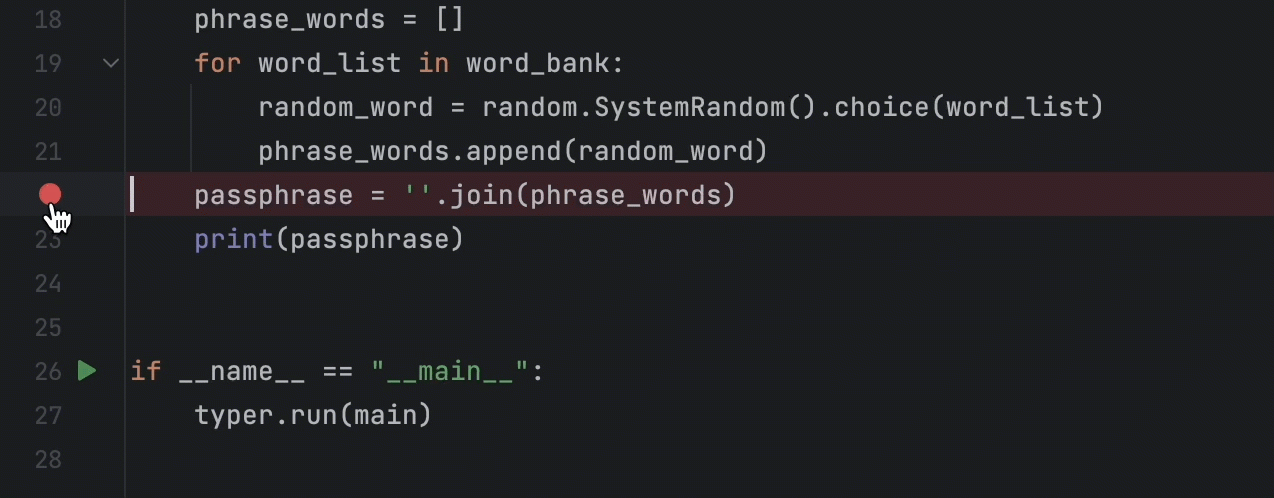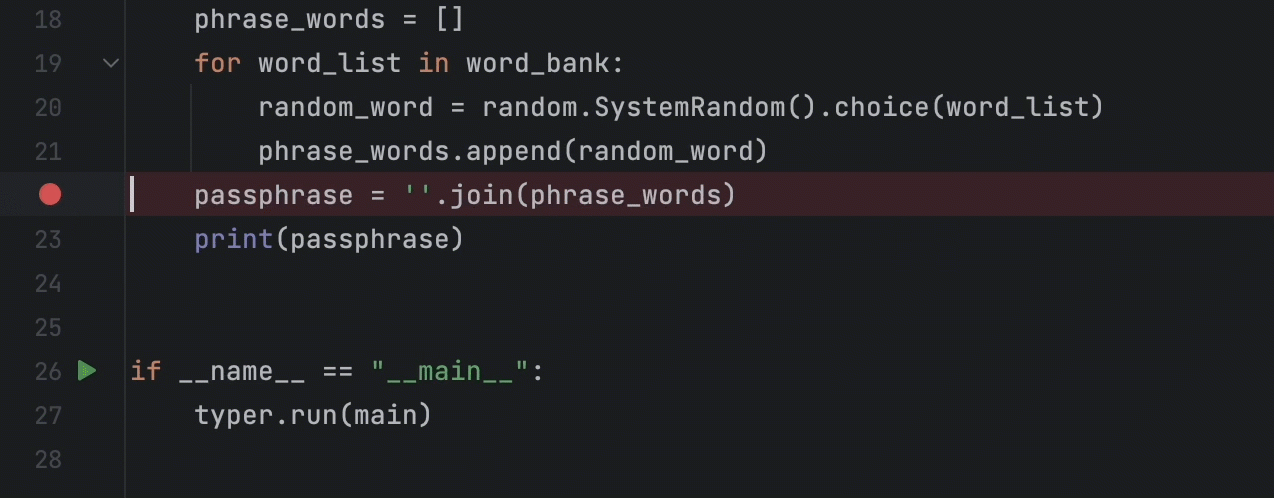
要开始调试过程,像之前一样点击装订区域中的 Run图标,但这次,在弹出窗口中选择 Debug ‘main’(调试 ‘main’)。 调试器将在断点处启动并停止执行,在底部打开 Debug(调试)工具窗口:
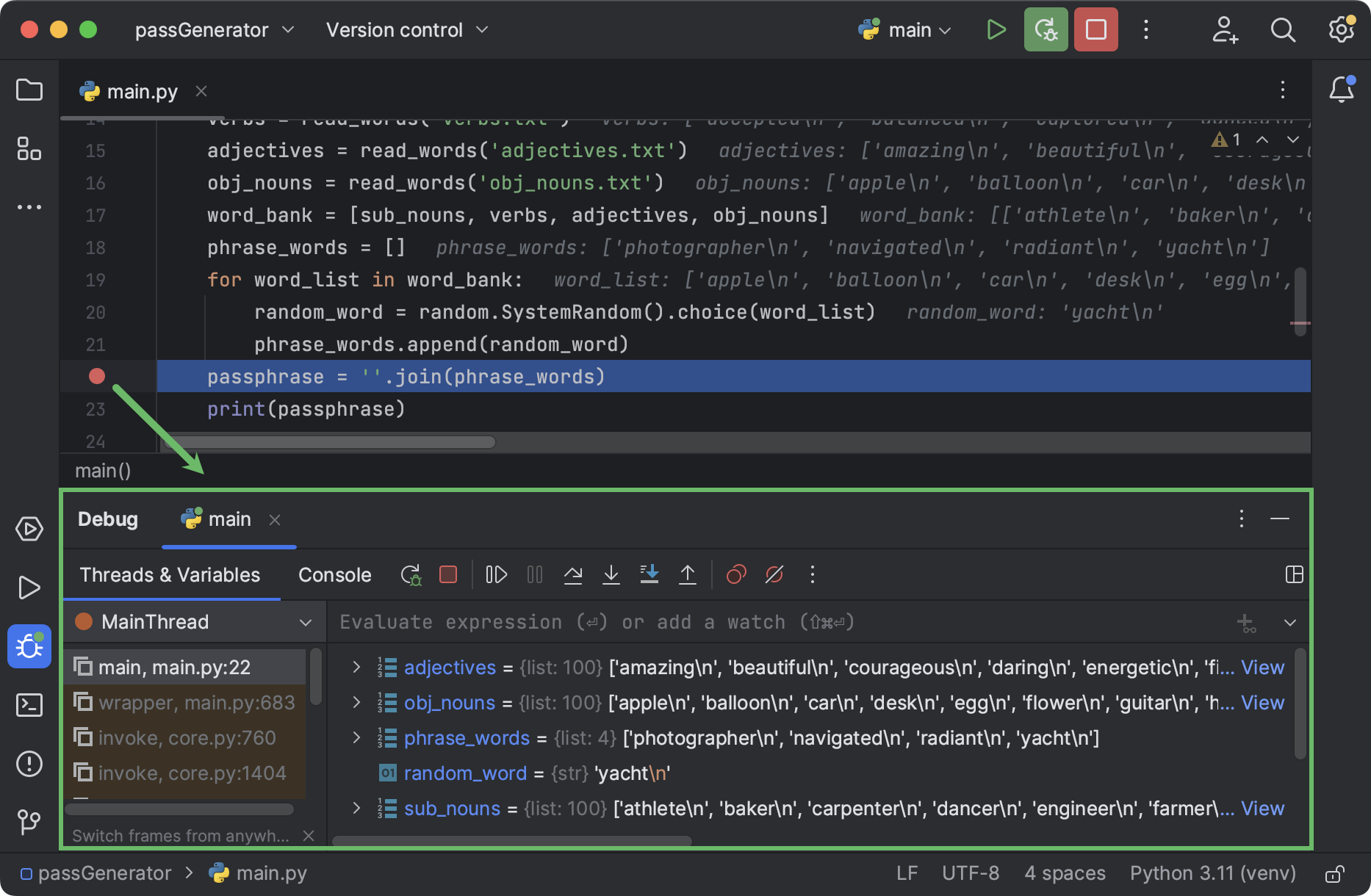
在 Debug(调试)工具窗口的右侧窗格中,您可以看到目前为止已赋值的变量。 展开 phrase_words 来查看其中的内容:
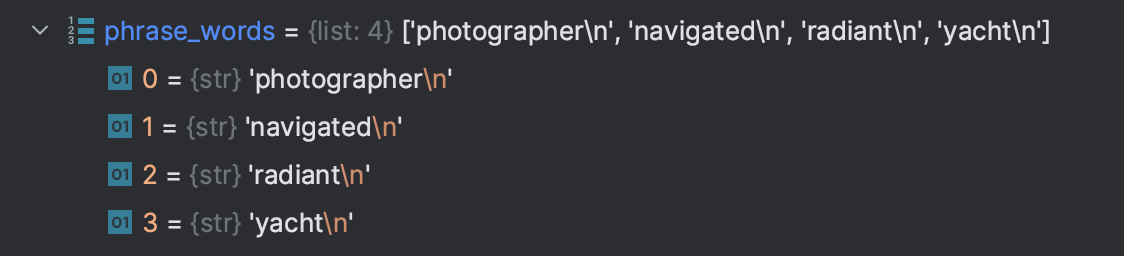
列表中有 4 个类型为 str 的条目。 每个字符串都以新行('\n') 结尾。 因此,后续将这些字符串连接在一起打印时,每个单词都打印在单独的行中。
如果查看其他列表,例如 adjectives,可以发现其中的所有条目也都以 ‘n’ 结尾。 我们从 read_words 函数获取这些列表。 这意味着我们需要修正它,让它返回没有尾随 ‘n’ 的单词列表。
让我们使用 strip() 和列表推导式,在返回之前去除每个列表条目中的 ‘n’:
def read_words(file_name):
with open(file_name, 'r') as f:
words = f.readlines()
words = [word.strip() for word in words]
return words重新运行 main(),获得结果: