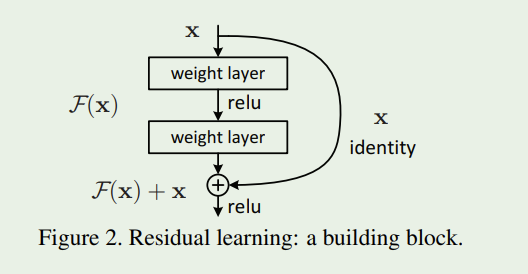
之前的文章介绍过残差网络的基本思想:残差网络的思想就是将网络学习的映射从X到Y转为学习从X到Y-X的差,然后把学习到的残差信息加到原来的输出上即可。即便在某些极端情况下,这个残差为0,那么网络就是一个X到Y的恒等映射。其示意图如下:
后来,就有学者想到,既然输入一个残差块的X和该残差块的输出 可以相加,那么为什么不能一起作为特征继续向后传递呢?所以,就有了DenseNet的基本思想,其示意图如下:
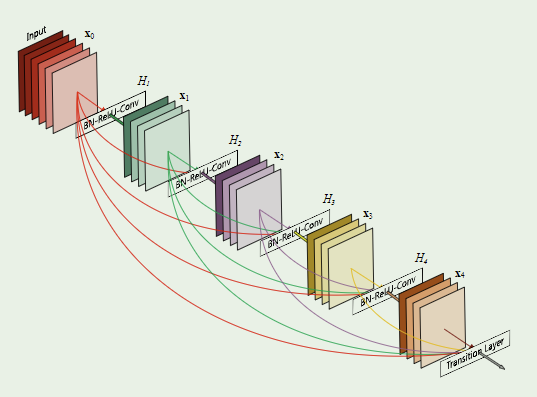
也就是说在网络前向传播的过程中,不仅每一层提取的特征图用做后面一层的输入,其自身也会被当做特征图输入到后面的网络中,比如上图中:
-
经过卷积层后得到了 ,然后 和 都会被当做 的输入*,以此类推,进行前向传播。
这样子做的好处有:
-
缓解了梯度消失问题; -
增强了特征在网络中的传播能力; -
特征重用; -
减少参数的数量。
具体的实现,我们来看下Pytroch的源码:
DenseLayer
class _DenseLayer(nn.Module):
def __init__(
self, num_input_features: int, growth_rate: int, bn_size: int, drop_rate: float, memory_efficient: bool = False
) -> None:
super().__init__()
self.norm1: nn.BatchNorm2d
self.add_module("norm1", nn.BatchNorm2d(num_input_features))
self.relu1: nn.ReLU
self.add_module("relu1", nn.ReLU(inplace=True))
self.conv1: nn.Conv2d
self.add_module(
"conv1", nn.Conv2d(num_input_features, bn_size * growth_rate, kernel_size=1, stride=1, bias=False)
)
self.norm2: nn.BatchNorm2d
self.add_module("norm2", nn.BatchNorm2d(bn_size * growth_rate))
self.relu2: nn.ReLU
self.add_module("relu2", nn.ReLU(inplace=True))
self.conv2: nn.Conv2d
self.add_module(
"conv2", nn.Conv2d(bn_size * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)
)
self.drop_rate = float(drop_rate)
self.memory_efficient = memory_efficient
def bn_function(self, inputs: List[Tensor]) -> Tensor:
concated_features = torch.cat(inputs, 1)
bottleneck_output = self.conv1(self.relu1(self.norm1(concated_features))) # noqa: T484
return bottleneck_output
# todo: rewrite when torchscript supports any
def any_requires_grad(self, input: List[Tensor]) -> bool:
for tensor in input:
if tensor.requires_grad:
return True
return False
@torch.jit.unused # noqa: T484
def call_checkpoint_bottleneck(self, input: List[Tensor]) -> Tensor:
def closure(*inputs):
return self.bn_function(inputs)
return cp.checkpoint(closure, *input)
@torch.jit._overload_method # noqa: F811
def forward(self, input: List[Tensor]) -> Tensor: # noqa: F811
pass
@torch.jit._overload_method # noqa: F811
def forward(self, input: Tensor) -> Tensor: # noqa: F811
pass
# torchscript does not yet support *args, so we overload method
# allowing it to take either a List[Tensor] or single Tensor
def forward(self, input: Tensor) -> Tensor: # noqa: F811
if isinstance(input, Tensor):
prev_features = [input]
else:
prev_features = input
if self.memory_efficient and self.any_requires_grad(prev_features):
if torch.jit.is_scripting():
raise Exception("Memory Efficient not supported in JIT")
bottleneck_output = self.call_checkpoint_bottleneck(prev_features)
else:
bottleneck_output = self.bn_function(prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return new_features
DenseNet的主要构成是DenseBlock,而DenseBlock的基本构成就是DenseLayer(上面的源码),上面的代码中有一些是pytorch的高级用法,暂不展开讲(主要是比较菜),其主要的函数就是其中的bn_function。
DenseBlock
有了DenseLayer,我们看下DenseBlock:
class _DenseBlock(nn.ModuleDict):
_version = 2
def __init__(
self,
num_layers: int,
num_input_features: int,
bn_size: int,
growth_rate: int,
drop_rate: float,
memory_efficient: bool = False,
) -> None:
super().__init__()
for i in range(num_layers):
layer = _DenseLayer(
num_input_features + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.add_module("denselayer%d" % (i + 1), layer)
def forward(self, init_features: Tensor) -> Tensor:
features = [init_features]
for name, layer in self.items():
new_features = layer(features)
features.append(new_features)
return torch.cat(features, 1)
代码其实也比较简单,就是初始化的时候就直接生成相应数量的DenseLayer,然后进行前向传播,整个DenseNet实现的关键点就是这个前向传播函数,注意几点:
-
其features是一个list; -
再通过for循环,不断的对这个list添加元素(append函数); -
最后DenseBlock的返回值是将list中的所有元素在维度1(channel维度)进行拼接。
然后就可以用上面的DenseBlock进行组合,搭积木式的构建自己的DenseNet网络了,比如DenseNet121、DenseNet169等等。
Transition
为了减少参数量,DenseNet中还有Transition这个子模块,其代码如下:
class _Transition(nn.Sequential):
def __init__(self, num_input_features: int, num_output_features: int) -> None:
super().__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_features))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module("conv", nn.Conv2d(num_input_features, num_output_features, kernel_size=1, stride=1, bias=False))
self.add_module("pool", nn.AvgPool2d(kernel_size=2, stride=2))
其作用一般是用来压缩通道数。
总结与思考
-
DenseNet和ResNet的主要区别? -
为什么DenseLayer中的bn_function的构成是norm》relu》conv的顺序?一般不都是conv》norm》relu?(有点迷,下次做实验)
进阶知识点
-
add_module -
torch.jit
参考
【1】HE K, ZHANG X, REN S, et al. Deep Residual Learning for Image Recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).2016:770-778. 10.1109/CVPR.2016.90.
【2】HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2017:4700-4708.
【3】Pytorch官方源码
本文由 mdnice 多平台发布