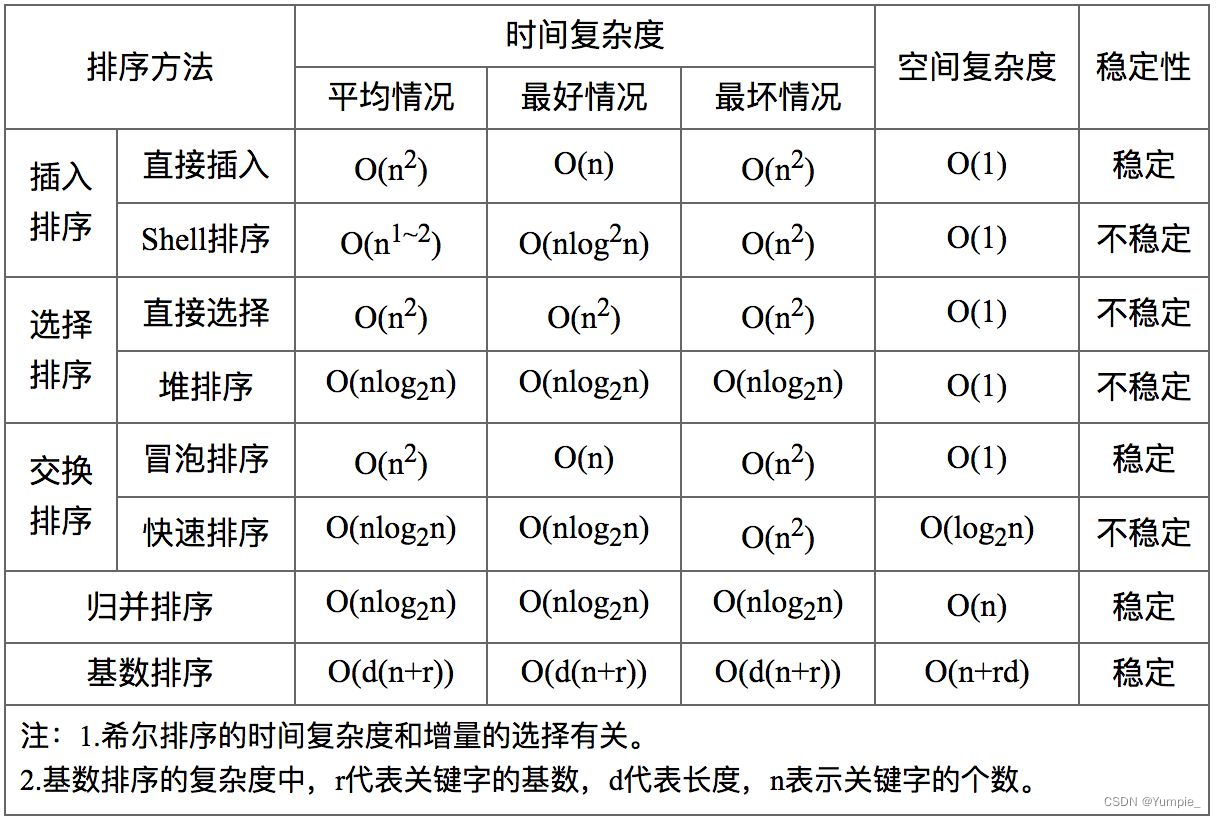
大家好,我是微学AI,今天给大家介绍一下机器学习实战7-基于机器学习算法预测相亲成功率,随着社会的发展,大家都忙于事业,对自己的终身大事就耽搁了,相亲是一种传统的寻找伴侣的方式,随着时代的发展,相亲的方式也在不断地改变。在这个过程中,了解相亲双方的信息以及预测相亲是否成功变得越来越重要。本文将介绍如何使用随机森林算法对相亲成功进行预测,通过分析男女双方的房子、车子、长相、家庭条件、父母情况、生活习惯、学历、性格、兴趣等因素,来预测相亲是否成功。

一、设定条件的合并
相亲过程,如果是设定单个条件的话是比较好找,但是将几个条件综合的话概率就低了。真正符合你设定的所有条件的人其实很少了。之前有过这样的一个统计:
某个城市要找一个170以上,本科学历,月薪5000以上,有房,中等长相,无不良嗜好的男生只剩150了。某城市主城区内常住人口300万,男性占一半的话,剩150万,其中年龄段在25-35之间的占20%, 还剩30万,其中还有排除已经结婚,有女朋友的,剩10万。中国南方男性平均身高168.5,170以上的占40%多,还剩4万,其中有独立房的占10%,剩4000,本科及以上占50%,剩2000,月薪5000及以上占50%,剩1000,中等长相的占50%,剩500,父母有体面工作的,健康,家庭和睦,有退休金占60%,剩300,无不良嗜好,不抽烟,不喝酒,顾家的再占一半,剩150。这样看来就是这样简简单单条件的都这么少了。
二、相亲数据集的描述
1.本文使用的数据集为CSV格式,包含以下字段:
房子(house):是否拥有房子(0:无,1:有)
车子(car):是否拥有车子(0:无,1:有)
长相(appearance):长相评分(1-10)
家庭条件(family_status):家庭经济条件评分(1-10)
父母情况(parents_status):父母健康状况评分(1-10)
生活习惯(lifestyle):生活习惯评分(1-10)
学历(education):学历等级(1:小学,2:初中,3:高中,4:大学,5:硕士,6:博士)
性格(personality):性格评分(1-10)
兴趣(interests):兴趣相似度评分(1-10)
相亲成功(success):是否相亲成功(0:失败,1:成功)
2.数据样例:
数据集为男生条件的数据,在那是有这些条件下的时候相亲成功的情况:
house,car,appearance,family_status,parents_status,lifestyle,education,personality,interests,success
1,0,7,6,8,5,4,7,6,1
0,1,5,4,7,6,3,6,5,0
1,1,8,7,9,7,5,8,7,1
0,0,4,3,6,4,2,5,4,0
1,0,6,5,7,5,4,6,5,1
1,1,6,8,5,8,6,6,5,0
0,1,5,4,7,6,3,6,5,0
1,0,7,6,8,5,4,7,6,1
0,0,4,3,6,4,2,5,4,0
1,1,8,7,9,7,5,8,7,1
0,1,5,4,7,6,3,6,5,0
1,0,7,6,8,5,4,7,6,1
1,1,5,8,9,8,6,9,8,1
0,0,9,3,6,4,2,9,4,1
1,0,6,5,7,5,4,6,5,1
0,1,5,4,7,6,3,6,5,0
1,1,8,7,9,7,5,8,7,1
1,0,7,6,8,5,4,7,6,1
0,0,4,3,6,4,2,5,4,0
1,1,9,8,9,8,6,9,8,1
1,0,6,5,8,5,4,6,5,1
0,1,5,4,3,6,3,6,5,0
1,1,6,7,9,7,7,8,7,1
1,0,7,6,8,5,4,7,6,1
0,0,9,4,6,7,7,9,8,1
1,0,9,8,6,7,6,9,7,1
1,1,6,7,9,4,5,5,4,0
1,1,6,7,8,3,5,4,5,0
0,1,7,5,8,4,5,4,6,0
0,0,7,3,6,4,7,5,4,02.数据预处理
在进行预测之前,需要对数据进行预处理,包括缺失值处理、数据归一化等。
3. 随机森林算法简介
随机森林是一种集成学习算法,它将多个决策树组合在一起进行分类或回归预测。每个决策树都是基于随机的样本和随机的特征选择建立的,这样可以降低模型的方差,提高模型的泛化能力。 在随机森林中,有两种方法可以增加模型的随机性。一种是随机采样,即在训练过程中随机选择一部分样本进行训练,这样可以降低模型的过拟合程度。另一种是随机特征选择,即在每个节点上,随机选择一部分特征进行划分,这样可以避免某些特征对模型的过度依赖。 随机森林的预测结果是基于所有决策树的预测结果的综合得出的,通常是取所有决策树预测结果的平均值(回归问题)或多数投票(分类问题)。随机森林的优点包括易于实现,不需要对数据进行特征缩放,可以处理高维数据和大量样本,同时还可以估计每个特征的重要性。
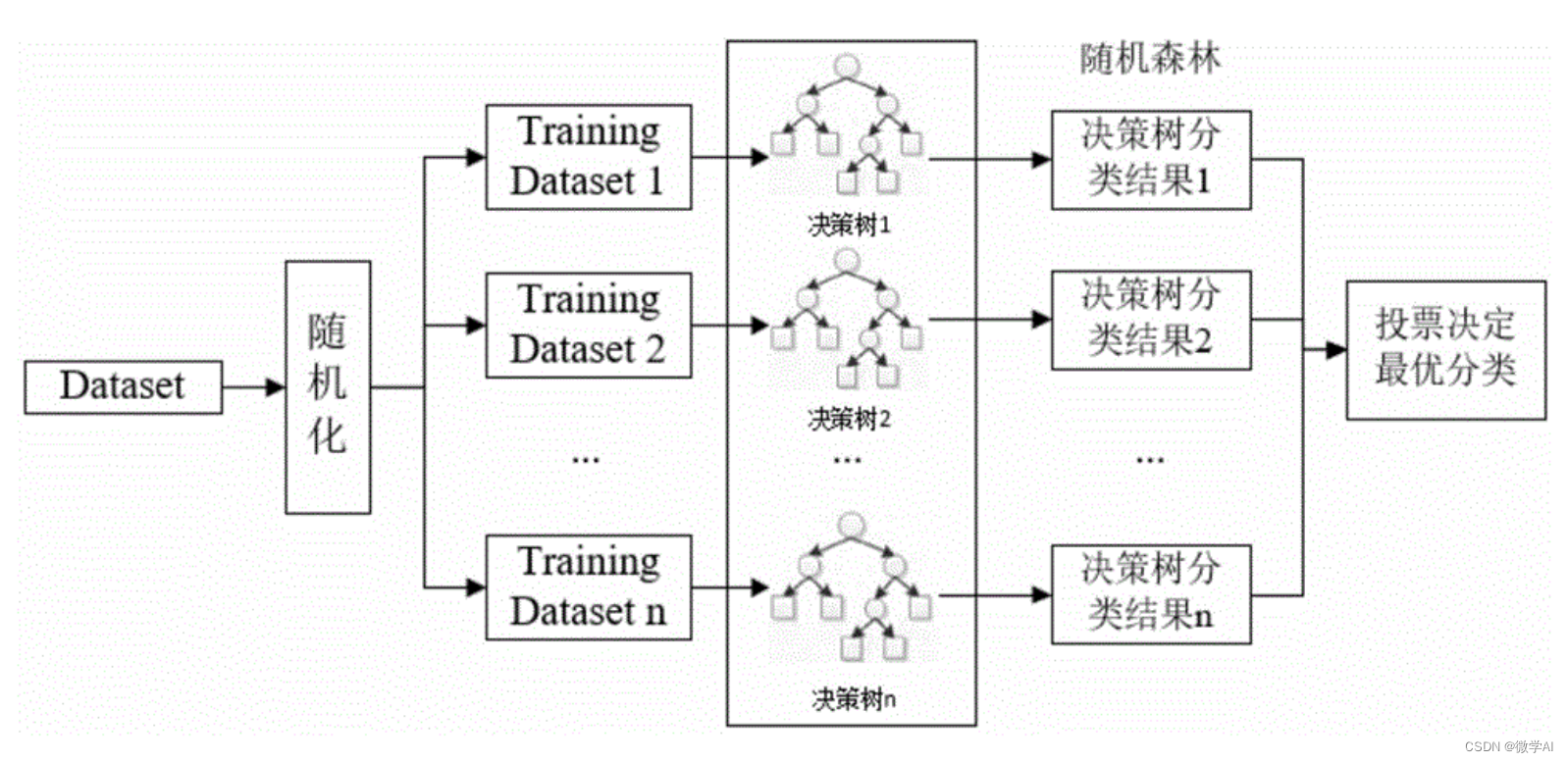
三、代码实现
以下是使用Python和scikit-learn库实现的随机森林算法预测相亲成功的完整代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
# 读取数据
data = pd.read_csv('data.csv')
# 数据预处理
data.fillna(data.mean(), inplace=True)
# 划分训练集和测试集
X = data.drop('success', axis=1)
y = data['success']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练随机森林模型
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
# 预测
y_pred = rf.predict(X_test)
# 评估
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
运行结果:
Accuracy: 1.0
precision recall f1-score support
0 1.00 1.00 1.00 2
1 1.00 1.00 1.00 4
accuracy 1.00 6
macro avg 1.00 1.00 1.00 6
weighted avg 1.00 1.00 1.00 6
Sample prediction: Failure
Process finished with exit code 0
预测数据1:
# 输入样例数据进行预测
sample_data = pd.DataFrame({'house': [0],
'car': [0],
'appearance': [5],
'family_status': [5],
'parents_status': [5],
'lifestyle': [4],
'education': [4],
'personality': [7],
'interests': [4]})
sample_pred = rf.predict(sample_data)
print("Sample prediction:", "Success" if sample_pred[0] == 1 else "Failure")运行结果:
Sample prediction: Failure预测数据2:
# 输入样例数据进行预测
sample_data2= pd.DataFrame({'house': [0],
'car': [0],
'appearance': [9],
'family_status': [5],
'parents_status': [5],
'lifestyle': [9],
'education': [5],
'personality': [8],
'interests': [8]})
sample_pred2 = rf.predict(sample_data2)
print("Sample prediction:", "Success" if sample_pred2[0] == 1 else "Failure")运行结果:
Sample prediction: Failure我们可以看到男生房车,生活习惯,兴趣爱好比较不如意的条件下,就比较难成功。
当男生无房车,但是生活习惯,兴趣爱好与女生很匹配,学历优势,能力优势,也是可以成功的,所以重要的还是看自己的后台能力与性格,能力决定你的幸福。
本文结论仅供参考!