回归分析是机器学习中的经典算法之一,用途广泛,在用实际数据进行分析时,可能会遇到以下两种问题
- 过拟合, overfitting
- 欠拟合, underfitting
在机器学习中,首先根据一批数据集来构建一个回归模型,然后在用另外一批数据来检验回归模型的效果。构建回归模型所用的数据集称之为训练数据集,而验证模型的数据集称之为测试数据集。模型来训练集上的误差称之为训练误差,或者经验误差;在测试集上的误差称之为泛化误差。
过拟合指的是模型在训练集中表现良好,而测试集中表现很差,即泛化误差大于了经验误差,说明拟合过度,模型泛化能力降低,只能够适用于训练集,通用性不强 ;欠拟合指的是模型在训练集中的表现就很差,即经验误差很大,图示如下

第一张图代表过拟合,可以看到为了完美匹配每个点,模型非常复杂,这种情况下,经验误差非常小,但是预测值的方差会很大,第二张图代表欠拟合,此时模型过于简单,在训练集上的误差就很大,第三张图则表示一个理想的拟合模型。
欠拟合出现的原因是模型复杂度太低,可能是回归模型自变量较少,模型不合适。针对欠拟合,要做的是增大模型复杂度,可以增加自变量,或者改变模型,比如将自变量由1次方改为2次方。
过拟合出现的原因则是模型复杂度太高或者训练集太少,比如自变量过多等情况。针对过拟合,除了增加训练集数据外,还有多种算法可以处理,正则化就是常用的一种处理方式。
线性回归 损失函数如下:
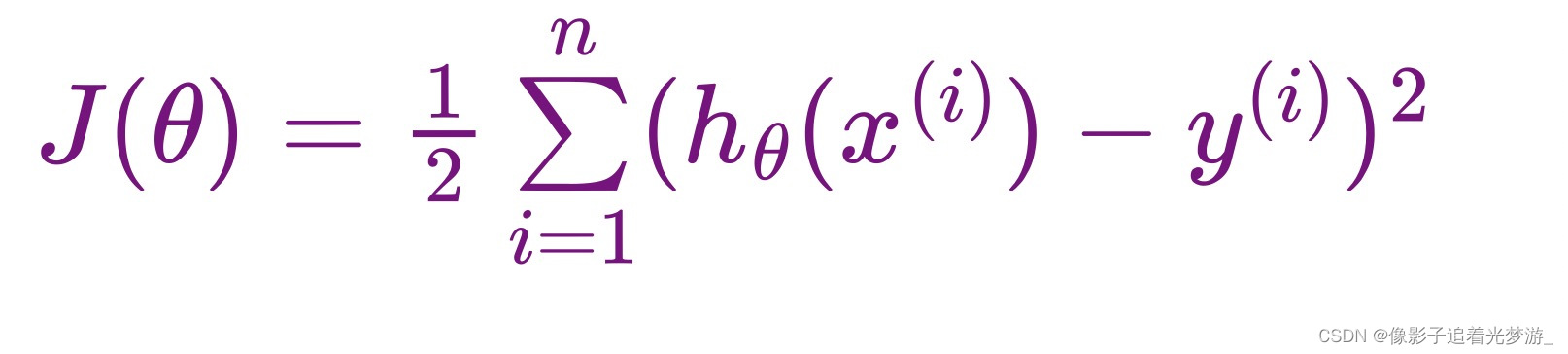
所谓正则化`Regularization`, 指的是在回归模型代价函数后面添加一个约束项, 在线性回归模型中,有两种不同的正则化项
1. 所有参数绝对值之和,即L1范数,对应的回归方法叫做Lasso回归
2. 所有参数的平方和,即L2范数,对应的回归方法叫做Ridge回归,岭回归

岭回归对应的代价函数如下

lasso回归对应的代价函数如下
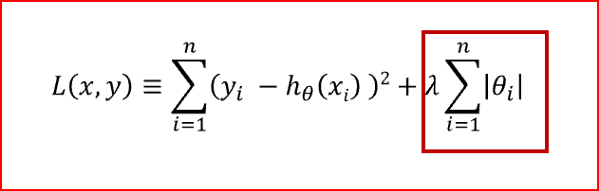
红框标记的就是正则项,需要注意的是,正则项中的回归系数为每个自变量对应的回归系数,不包含回归常数项。
L1和L2各有优劣,L1是基于特征选择的方式,有多种求解方法,更加具有鲁棒性;L2则鲁棒性稍差,只有一种求解方式,而且不是基于特征选择的方式。
在GWAS分析中,当用多个SNP位点作为自变量时,采用基于特征选择的L1范式,不仅可以解决过拟合的问题,还可以筛选重要的SNP位点,所以lasso回归在GWAS中应用的更多一点。
原文:终于搞清楚了Lasso回归和Ridge回归的区别 - 腾讯云开发者社区-腾讯云

![[1173]regexp_replace()和regexp_substr()函数的用法](https://img-blog.csdnimg.cn/img_convert/d5325562013e38b49b681bb78ecd1378.png)


![[附源码]计算机毕业设计JAVA学生宿舍设备报修](https://img-blog.csdnimg.cn/b3be303ed30d4069a8273e4d1ce541a7.png)