文章目录
- REGEXP_REPLACE的使用方法
- 命令格式:regexp_replace(source, pattern, replace_string, occurrence)
- 参数说明
- 返回值
- 常用案例
- 其他案例
- 正则符号释义
- regexp_substr()函数的用法
REGEXP_REPLACE的使用方法
命令格式:regexp_replace(source, pattern, replace_string, occurrence)
参数说明
- source: string类型,要替换的原始字符串。
- pattern: string类型常量,要匹配的正则模式,pattern为空串时抛异常。
- replace_string:string,将匹配的pattern替换成的字符串。
- occurrence: bigint类型常量,必须大于等于0。
- 大于0:表示将第几次匹配替换成replace_string。
- 等于0:表示替换掉所有的匹配子串。
- 其它类型或小于0抛异常。
返回值
将source字符串中匹配pattern的子串替换成指定字符串后返回,当输入source, pattern, occurrence参数为NULL时返回NULL,若replace_string为NULL且pattern有匹配,返回NULL,replace_string为NULL但pattern不匹配,则返回原串。
常用案例
1、用#替换字符串中的所有数字
SELECT regexp_replace('01234abcde56789','[0-9]','#');
结果:#####abcde#####
用#替换字符串中的数字0、9
SELECT regexp_replace('01234abcde56789','[09]','#');
结果:#1234abcde5678#
2、遇到非小写字母或者数字跳过,从匹配到的第4个值开始替换,替换为''
SELECT regexp_replace('abcdefg123456ABC','[a-z0-9]','',4)
结果:abcefg123456ABC
SELECT regexp_replace('abcDEfg123456ABC','[a-z0-9]','',4)
结果:abcDEg123456ABC
SELECT regexp_replace('abcDEfg123456ABC','[a-z0-9]','',7);
结果:abcDEfg13456ABC
遇到非小写字母或者非数字跳过,将所有匹配到的值替换为''
SELECT regexp_replace('abcDefg123456ABC','[a-z0-9]','',0);
结果:DABC
3、格式化手机号,将+86 13811112222转换为(+86) 138-1111-2222,+在正则表达式中有定义,需要转义。\\1表示引用的第一个组
SELECT regexp_replace('+86 13811112222','(\\+[0-9]{2})( )([0-9]{3})([0-9]{4})([0-9]{4})','(\\1)\\3-\\4-\\5',0);
结果:(+86)138-1111-2222
SELECT regexp_replace("123.456.7890","([[:digit:]]{3})\\.([[:digit:]]{3})\\.([[:digit:]]{4})","(\\1)\\2-\\3",0) ;
SELECT regexp_replace("123.456.7890","([0-9]{3})\\.([0-9]{3})\\.([0-9]{4})","(\\1)\\2-\\3",0) ;
结果:(123)456-7890
4、将字符用空格分隔开,0表示替换掉所有的匹配子串。
SELECT regexp_replace('abcdefg123456ABC','(.)','\\1 ',0) AS new_str FROM dual;
结果:a b c d e f g 1 2 3 4 5 6 A B C
SELECT regexp_replace('abcdefg123456ABC','(.)','\\1 ',2) AS new_str FROM dual;
结果:ab cdefg123456ABC
5、
SELECT regexp_replace("abcd","(.*)(.)$","\\1",0) ;
结果:abc
SELECT regexp_replace("abcd","(.*)(.)$","\\2",0) ;
结果:d
SELECT regexp_replace("abcd","(.*)(.)$","\\1-\\2",0) ;
结果:abc-d
其他案例
SELECT regexp_replace("abcd","(.)","\\2",1) 结果为`"abcd"`,因为pattern中只定义了一个组,引用的第二个组不存在。
SELECT regexp_replace("abcd","(.*)(.)$","\\2",0) 结果为"d"
SELECT regexp_replace("abcd","(.*)(.)$","\\1",0) 结果为"abc"
SELECT regexp_replace("abcd","(.*)(.)$","\\1-\\2",0) 结果为"abc-d"
SELECT regexp_replace("abcd","a","\\1",0),结果为” \1bcd”,因为在pattern中没有组的定义,所以\1直接输出为字符。
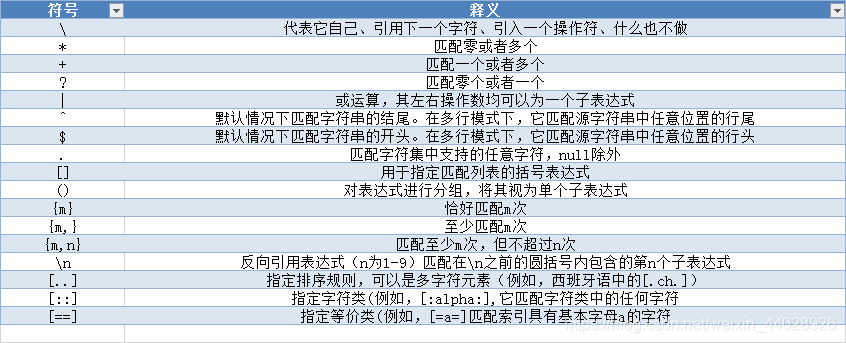
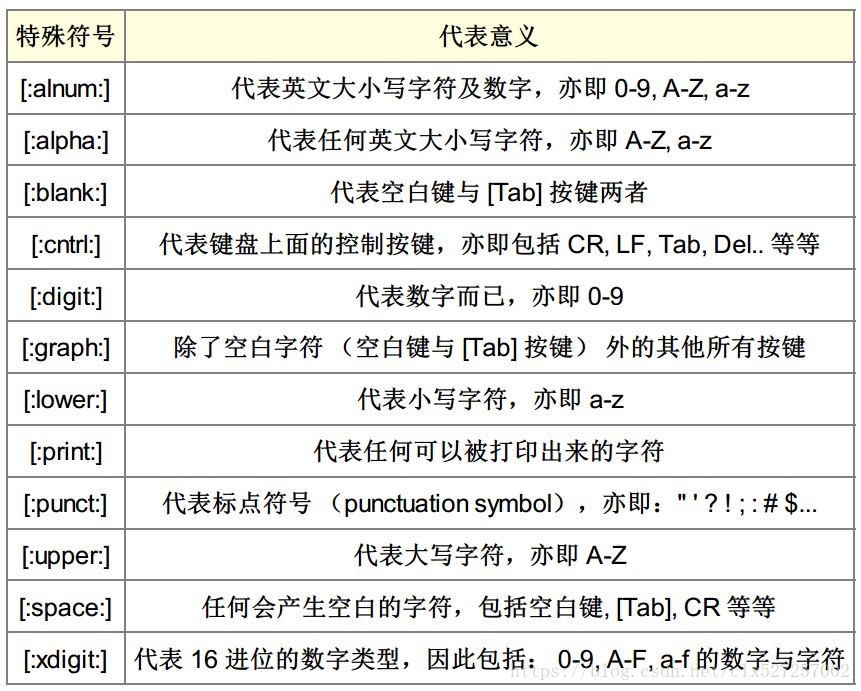
正则符号释义
regexp_substr()函数的用法
在SQL中尝试使用正则,可以试下regexp_substr()来进行分割
1.首先创建一个实验视图:
SQL>
create or replace view test_ip as select '192.168.1.1' as ip from dual
union all
select '192.168.1.2' as ip from dual
union all
select '192.168.1.3' as ip from dual
union all
select '192.168.1.4' as ip from dual;
2.查看下视图的整体结构
SQL> select * from test_ip;
IP
-----------
192.168.1.1
192.168.1.2
192.168.1.3
192.168.1.4
3.实例
(1)现在有一个需求,需要将这些ip以“.”为分隔符,分段显示ip
最终效果如下:
IP1 IP2 IP3 IP4
---------------------- ---------------------- ---------------------- -----
192 168 1 1
192 168 1 2
192 168 1 3
192 168 1 4
执行的SQL如下:
select regexp_substr(a.ip, '[^.]+', 1, 1) ip1,
regexp_substr(a.ip, '[^.]+', 1, 2) ip2,
regexp_substr(a.ip, '[^.]+', 1, 3) ip3,
regexp_substr(a.ip, '[^.]+', 1, 4) ip4 from test_ip a;
分析:
regexp_substr()括号中的
[^.] -->代表除了“.”以外的全部字段
+ -->表示匹配1次以上
1 -->表示从第一个“.”开始
2 -->表示匹配到的第二个字段
这样就能达到这个效果
参考:https://blog.csdn.net/JohnnyChu/article/details/111184962
https://blog.csdn.net/boos_zhao/article/details/121470300


![[附源码]计算机毕业设计JAVA学生宿舍设备报修](https://img-blog.csdnimg.cn/b3be303ed30d4069a8273e4d1ce541a7.png)









![[附源码]Python计算机毕业设计Django健身生活系统论文](https://img-blog.csdnimg.cn/e6f30804310542dd9666ad055f8023e3.png)