在今天这个时代,人们的工作和生活已经离不开数据访问,而几乎所有平台背后的数据存储和查询都离不开数据库。SQL作为一种数据库的查询和处理语言历史悠久,最早由IBM于上世纪70年代初研究关系数据模型时提出,后续发展为一种广泛使用的数据库标准访问接口。今天大语言模型的发展给了我们一个契机,重新审视这层标准,如何让人们以更加自然的方式访问数据库,数据以更直接、更灵活的方式返回给客户。由于历史发展的原因,从数据库分析出一个结论,需要“分析人员+报表前端+数据后端+SQL+数据存储”的全路径,这一使用范式在未来将受到挑战。除了自然语言本身的优势外,语境的上下文学习能力、迁移学习和文字总结能力也有很大的发挥空间,带着这些思考,我们有必要了解一下大语言模型背后的发展及其技术原理。
一、大语言模型的发展
大语言模型作为一个被验证可行的方向,其“大”体现在训练数据集广,模型参数和层数大,计算量大,其价值体现在通用性上,并且有更好的泛化能力。相较于传统特定领域训练出来的语言模型,有更广泛的应用场景。这篇文章参考Google和OpenAI相关论文及部分作者的补充,结合我的理解尝试用大家普遍看得明白的语言,对其技术发展和主要实现进行解析。
1.1 Transformer模型的提出
在Transformer提出之前,自然语言处理领域的主流模型是循环神经网络(RNN,recurrent neural network),使用递归和卷积神经网络进行语言序列转换。2017年,谷歌大脑团队在人工智能领域的顶会NeurIPS发表了一篇名为“Attention is all you need”的论文,首次提出了一种新的简单网络架构,即 Transformer,它完全基于注意力机制(attention),完全摒弃了循环递归和卷积。
递归模型通常沿输入和输出序列的符号位置进行计算,来预测后面的值。但这种固有的顺序性质阻碍了训练样例内的并行化,因为内存约束限制了样例之间的批处理。而注意力机制允许对依赖项进行建模,而无需考虑它们在输入或输出序列中的距离。
Transformer避开了递归网络的模型体系结构,并且完全依赖于注意力机制来绘制输入和输出之间的全局依存关系。 在八个P100 GPU上进行了仅仅12个小时的训练之后,Transformer就可以在翻译质量方面达到新的最先进水平,体现了很好的并行能力。成为当时最先进的大型语言模型(Large Language Model, LLM)。
总结两个核心突破:
-
突破了远距离文本依赖的学习限制,避开了递归网络的模型体系结构,并且完全依赖于注意力机制来绘制输入和输出之间的全局依赖关系。关联来自两个任意输入或输出位置的信号所需的操作数随着距离增加,原来需要线性增长或对数增长,现在被收敛成一个常量,并通过多注意头机制保障了准确性。
-
可高度并行进行训练,这对发挥硬件红利以及快速迭代模型非常重要。
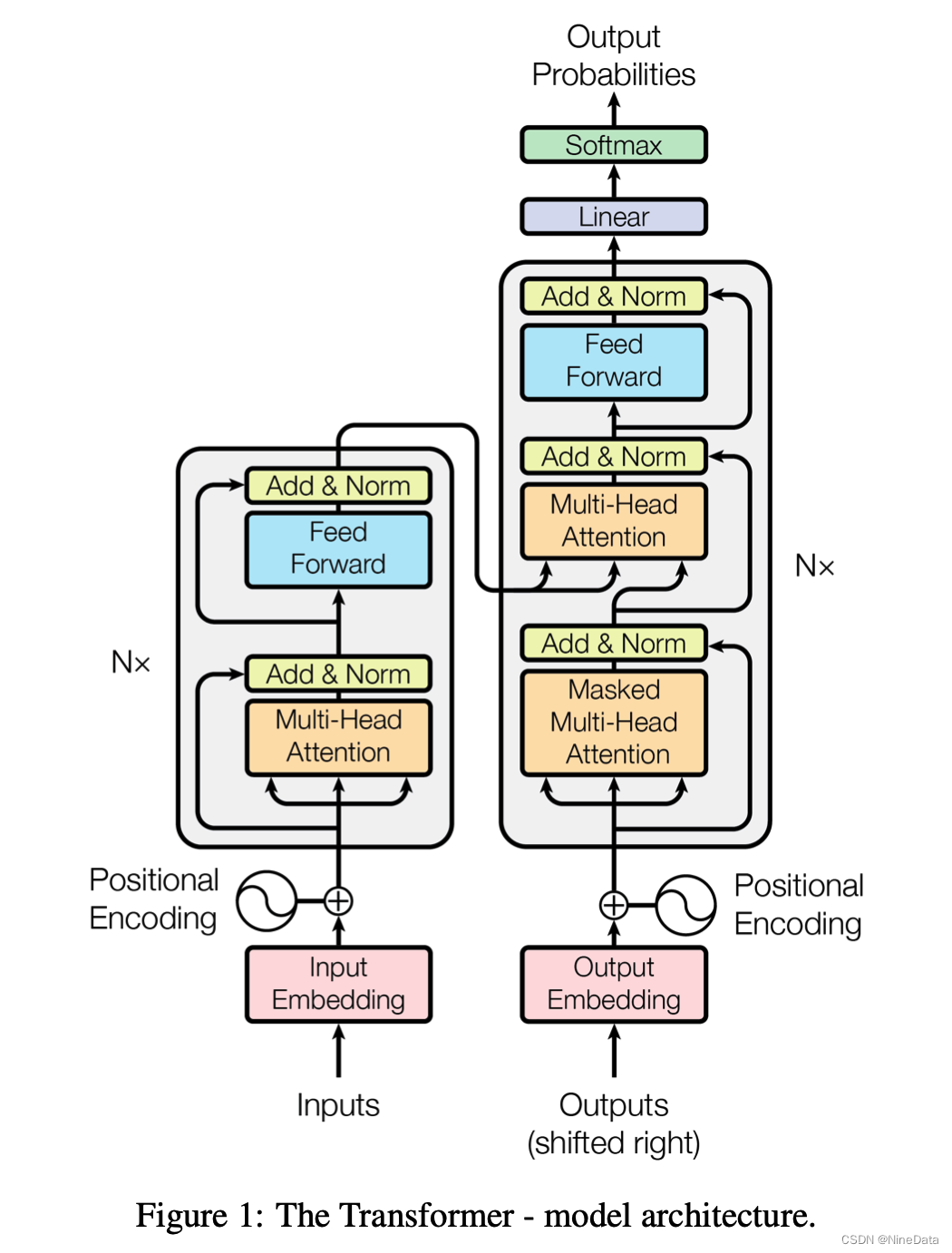
下图是论文提到的Transformer模型,对编码器和解码器使用堆叠式的自注意力和逐点式、全连接层,分别如图1的左半部分(编码器)和右半部分(解码器)所示,相关技术细节后面会重点讲到。
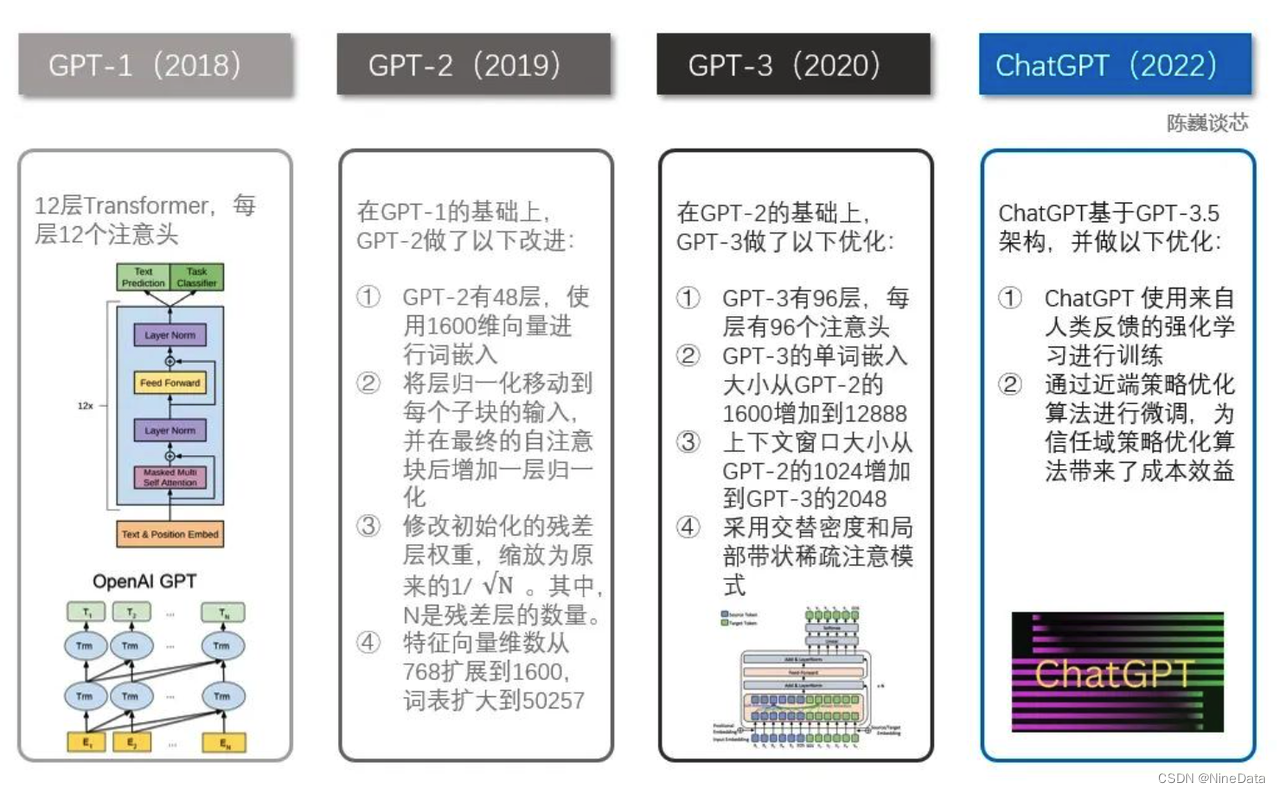
OpenAI基于该工作基础上发展了GPT(Generative Pre-training)生成式预训练模型,这里借用网上一张图简单改过,相关细节将在后面展开。
1.2 生成式预训练初现潜力:GPT-1
2018年,OpenAI公司发表了论文“Improving Language Understanding by Generative Pre-training”,
使用的模型有两个阶段,第一阶段是无监督预训练,基于海量的文本集通过Transformer学习一个大容量的语言模型,第二阶段基于标注数据进行参数微调。得到的一般任务不可知模型(或称为通用模型)优于经过判别训练的模型,在论文选定的12种数据集中有9个取得更好效果。 在 GPT-1 中,采用了 12 层Transformer 的结构作为解码器,每个 Transformer 层是一个多头的自注意力机制,然后通过全连接得到输出的概率分布。
这次实践对OpenAI来讲,我觉得是奠定了他们往这个路线发展的核心因素,主要有几个重点突破:
1、证明了通用模型训练具有很大的价值潜力。之前用于学习特定任务的标注数据难以获得,导致模型效果不能持续提升,而通过Transformer无监督训练+少量标注数据的Finetune就取得了更优的效果。
2、论文尝试增加Transformer中间层, 在从2层到12层的数量增加中,平均每增加1层能够提升9%的准确性。加上Transformer本身具备并行能力,这在GPU上无疑潜力巨大。
3、论文发现在第二步的Finetune中添加语言建模作为辅助学习目标,能够提高监督模型的泛化能力,并加速收敛。说明在更海量的数据集时,模型会更收益于辅助学习目标。
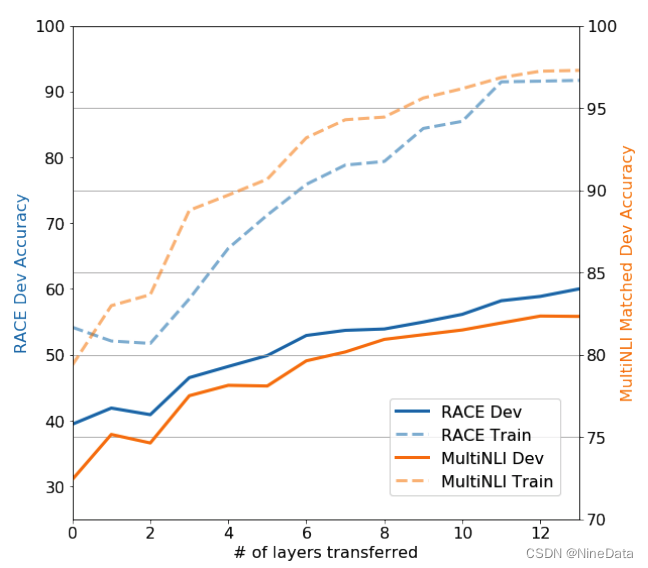
虽然论文摘要重点强调了该模型在缺少标注数据情况下对特定任务的优势,但其实以上三点发现对OpenAI后续技术路线影响重大。但GPT-1在生成长文本时,仍然会出现信息遗忘和重复等问题,和特定领域的模型对比还有很多不足。
1.3 泛化能力突破:GPT-2
2019年,OpenAI发表了最新进展,一篇“Language Models are Unsupervised Multitask Learners”的论文。重点实践了更大的模型更广的数据集具有更好的泛化能力。GPT-1是12层的transformer,BERT最深是24层的transformer,GPT-2则是48层,共有15亿个参数的transformer,训练集叫WebText,是从4500万个链接提取文本去重后,得到800万文档共40GB文本。
论文认为现有系统用单个任务来训练的单个领域数据集,是缺乏模型泛化能力的主要原因,因此在更广的数据集上,GPT-2采用了多任务(multitask)的方式,每一个任务都要保证其损失函数能收敛,不同的任务共享主体transformer参数。
最终训练出来的模型在不需要任何参数和模型改动下,在zero-shot(零样本)任务中,在8个数据集中有7个表现为业界最优,这个泛化能力可以说已经很强大了,并且在机器翻译场景取得亮眼结果,GPT也是在2.0出来后,开始备受关注。
1.4 更大参数更大数据集:GPT3
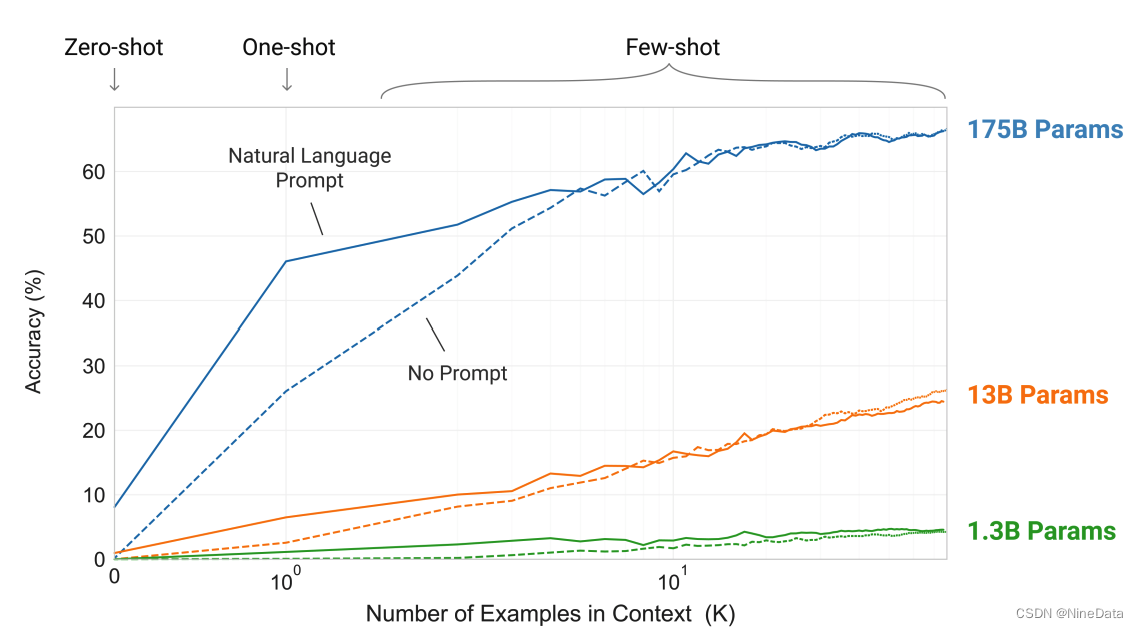
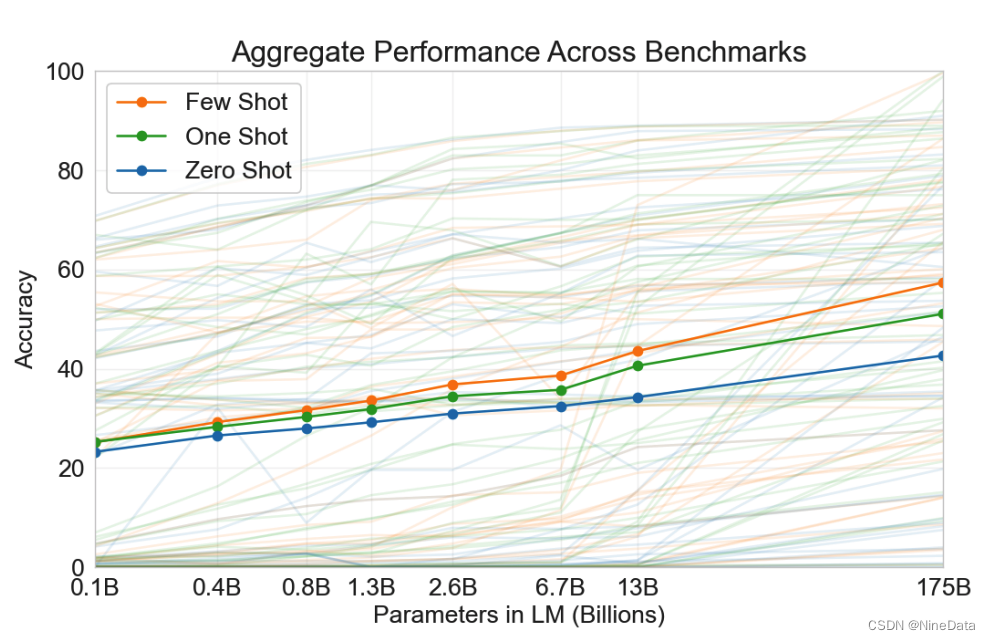
之前的模型要在特定领域有更好表现,依然需要上千条标注样本数据来进行finetune,很大程度影响了模型的通用性,而人类能够根据前面一句话知道语境(in-context),从而正确回答问题。GPT3就通过调大参数(1750亿)来测试in-context 学习能力,并在没有finetune情况下得到以下数据。在参数不断增加的同时,分为三种场景看回答准确率表现:Zero-shot(0样本),One-shot(只给一个标准样本),Few-shot(少量标准样本,1000条左右)。下图可以看到模型参数和样本集对正确性的影响,随着参数增多,Few-shot相比Zero-shot的提升效果在拉大,说明越大的参数对样本具有更强的泛化能力。
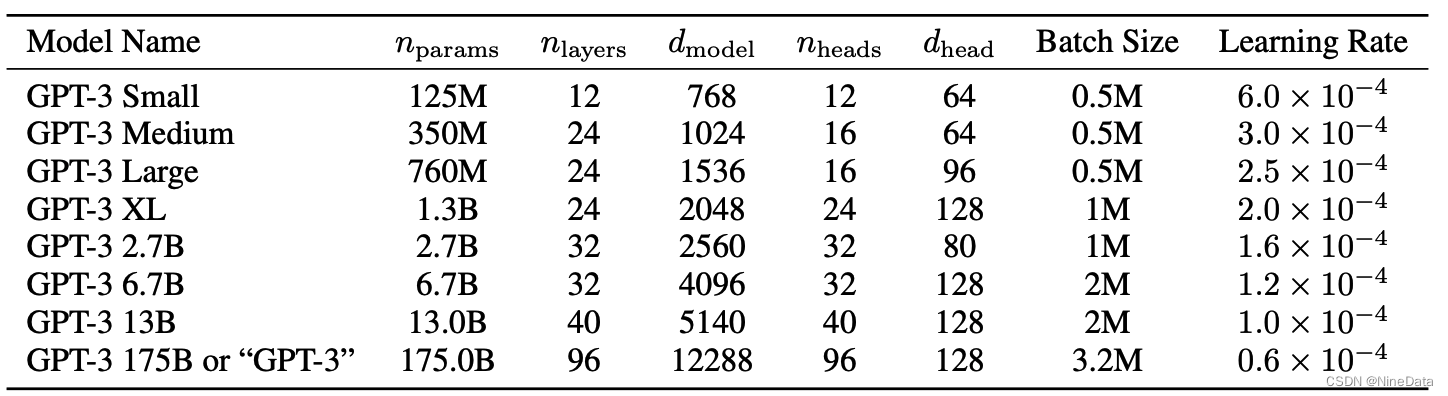
论文做了不同参数的验证工作,n(params)是参数梳理,n(layers)是模型层数,d(model)是FFN层数的1/4,d(head)是多注意头的维数,所有测试使用的上下文token数是2048。
GPT-3 在 GPT-2 追求无监督和零次学习的特征基础上进行了改进,转而追求无监督模式下的 few-shot(少量学习)。GPT-3采用了 96 层的多头 Transformer,上下文窗口大小提升至 2048 个 token ,基于更大的数据集 45TB 的文本数据训练,在多个 NLP 数据集上实现了出色的性能。GPT-3更多的工作在工程问题上,比如数据污染处理,GPU并行时减少节点间网络交互和负载均衡等。
论文测试了超过24中场景,GPT-3在许多NLP数据集上实现了强大的性能,包括翻译、问题回答和完形填空任务,以及一些需要实时推理或领域适应的任务,如解读单词、在句子中使用新单词或执行3位数字算术。论文还表明,在few-shot设置下,GPT-3可以生成人类评估者难以区分的新闻文章。
1.5 火爆的ChatGPT:GPT 3.5
2022年3月,OpenAI再次发表论文“Training language models to follow instructions with human feedback”,通过人工反馈和微调,使语言模型与用户对各种任务的意图保持一致。并推出了InstructGPT模型,InstructGPT 是基于 GPT-3 的一轮增强优化,所以也被称为 GPT-3.5。尽管GPT3.5还会犯一些简单的错误,但论文工作表明利用人类反馈进行微调是一个很有前景的方向。
论文提供了一种方法,能通过对人类反馈进行微调,使语言模型在广泛的任务应用中更好地遵从使用者意图。从一组人工编写的prompts和通过OpenAI API提交的prompts开始,论文收集了所需模型行为的标记样本数据集,并使用监督学习对GPT-3进行微调。然后,论文对模型输出进行人工排名,使用来自人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)进一步微调这个监督模型。InstructGPT模型的参数为1.3B,而GPT-3模型的参数为175B,约为InstructGPT模型的130倍,但InstructGPT模型的输出却优于GPT-3模型的输出。
训练过程首先聘请了40个承包商来标注数据,收集提交给OpenAI的prompts的人工答案样本集,以及一些人工写的prompts作为训练监督学习的基线。然后,在更大的prompts集上对比OpenAI的输出,并人工标记差距,据此训练出一个奖励模型(Reward Model)来预测人类喜好的输出。最后用PPO来最大化这个奖励模型和fine-tune对监督模型的效果。这部分具体技术细节将在后面展开。论文认为模型如果有价值观的话,体现更多的是标注者的价值观念而不是更广泛人的价值观。
对人类任务意图的识别,是一个非常重要的能力。ChatGPT 采用 InstructGPT 相同结构的模型,针对 Chat 进行了专门的优化, 同时开放到公众测试训练,以便产生更多有效标注数据。基于人类反馈的强化学习(RLHF)是 ChatGPT 区别于其他生成类模型的最主要特点,该法帮助模型尽量减少有害的、不真实的及有偏见的输出,提升自然沟通效果。 同时,为了更好地支持多轮对话,ChatGPT 引入了一种基于堆栈的上下文管理的机制,帮助 ChatGPT 跟踪和管理多轮对话中的上下文信息,从而在多轮对话中生成连贯自然的回复。
1.6 当前的技术局限性
-
专业的领域,缺乏语料训练的情况下,GPT无法生成合适的回答。
-
可信度问题,缺乏答案的具体来源。
-
时效性问题,大模型底层训练数据是过往数据,再一次训练的成本很高。
-
数理问题会一本正经地胡说八道,Stephen Wolfram创造了计算知识搜索引擎和计算语言wolfram,有机会将自然语言转为计算符号再进行计算,解决这一问题。
-
模型的训练方法有个致命的问题,训练好的模型在回答问题时,在各个答案里选一个最优答案,但答案依然可能是错的,模型本质是黑盒的,目前还未能对内部逻辑进行分解,无法保证不产生有害或伤害客户的描述。如果调教训练模型更加谨慎,可能会拒绝回答(以避免提示的误报)。有时模型最终对一个短语没有反应,但对问题/短语稍作调整,它最终会正确回答。
二、主要技术细节
Google的论文比较简短,看到刘岩推荐的Jay Alammer对Transformer的讲解,这里也做了部分引用,这里希望用大家看得懂的话,抽取主要技术细节讲清楚。
从数学或机器学习的角度来看,语言模型都是对词语序列的概率相关性分布的建模,即利用已经说过的语句(语句可以作为数学中的向量)作为输入条件,预测下一个时刻不同语句甚至语言集合出现的概率分布。 GPT生成式预训练模型也是根据语料概率来自动生成回答的每一个字,ChatGPT在此基础上通过使用基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来干预增强学习以取得更好效果。
2.1 什么是Transformer?
本文重点介绍Transformer核心结构和技术点,略过训练优化部分。
编解码组件结构
Transformer 本质上是一个 Encoder-Decoder 架构,包括编码组件和解码组件。比如在机器翻译任务中,将一种语言的一个句子作为输入,然后将其翻译成另一种语言的一个句子作为输出。编码组件和解码组件可以有很多层,比如Google刚提出时的论文用的是6层,后面GPT-1是12层,然后到GPT-3是96层。
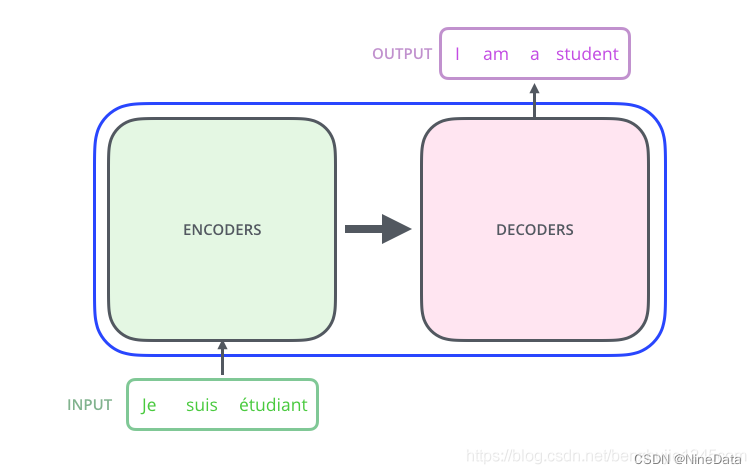
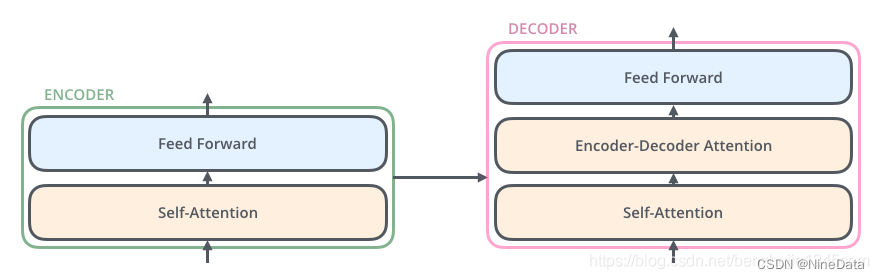
每个编码器由两个子层组成:Self-Attention 层(自注意力层)和 Position-wise Feed Forward Network(前馈网络,缩写为 FFN),每个编码器的结构都是相同的,但是它们使用不同的权重参数。编码器的输入会先流入 Self-Attention 层。它可以让编码器在对特定词进行编码时使用输入句子中的其他词的信息(可以理解为:当我们翻译一个词时,不仅只关注当前的词,而且还会上下文关注其他词的信息)。
解码器也有编码器中这两层,但是它们之间还有一个编解码注意力层(即 Encoder-Decoder Attention),其用来帮助解码器关注输入句子中需要关注的相关部分。
-
编码器对文本的处理
对文本处理和通常的 NLP 任务一样,首先使用词嵌入算法(Embedding)将每个词转换为一个词向量(vector)。在 Transformer 论文摘要提到词嵌入向量的维度是 512,所有编码器都会接收到包含多个大小为 512 的向量列表(List of vectors)。嵌入仅发生在最底层的编码器中,其他编码器接收的是上一个编码器的输出。这个列表大小是我们可以设置的参数——基本上这个参数就是训练数据集中最长句子的长度。对输入序列完成嵌入操作后,每个词都会流经编码器内的两层,然后逐个编码器向上传递。
Self-Attention 原理
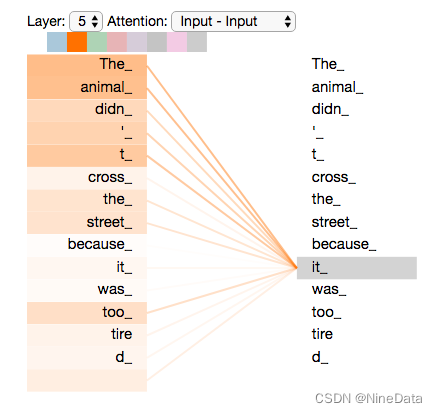
之前说Transformer的自注意机制突破了文本关注距离的限制,因此非常关键。先看这样一个句子:
The animal didn't cross the street because it was too tired
这个句子中的"it"代表什么意思,是animal,还是street还是其他?这个对人来说很容易,但对模型来说不简单。self-Attention就是用来解决这个问题,让it指向animal。通过加权之后可以得到类似图8的加权情况,The animal获得最大关注。
在self-attention中,每个单词有3个不同的向量,它们分别是Query向量( Q ),Key向量( K )和Value向量( V ),长度均是64。它们是通过3个不同的权值矩阵由嵌入向量 X 乘以三个不同的权值矩阵 W^Q , W^K ,W^V 得到,其中三个矩阵的尺寸也是相同的。均是 512×64 。
Query,Key,Value的概念取自于信息检索系统,举个简单的搜索的例子来说。当你在某电商平台搜索某件商品(年轻女士冬季穿的红色薄款羽绒服)时,你在搜索引擎上输入的内容便是Query,然后搜索引擎根据Query为你匹配Key(例如商品的种类,颜色,描述等),然后根据Query和Key的相似度得到匹配的内容(Value)。
self-attention中的Q,K,V也是起着类似的作用,在矩阵计算中,点积是计算两个矩阵相似度的方法之一,因此式1中使用了QK^T进行相似度的计算。接着便是根据相似度进行输出的匹配,这里使用了加权匹配的方式,而权值就是query与key的相似度。
多注意头机制
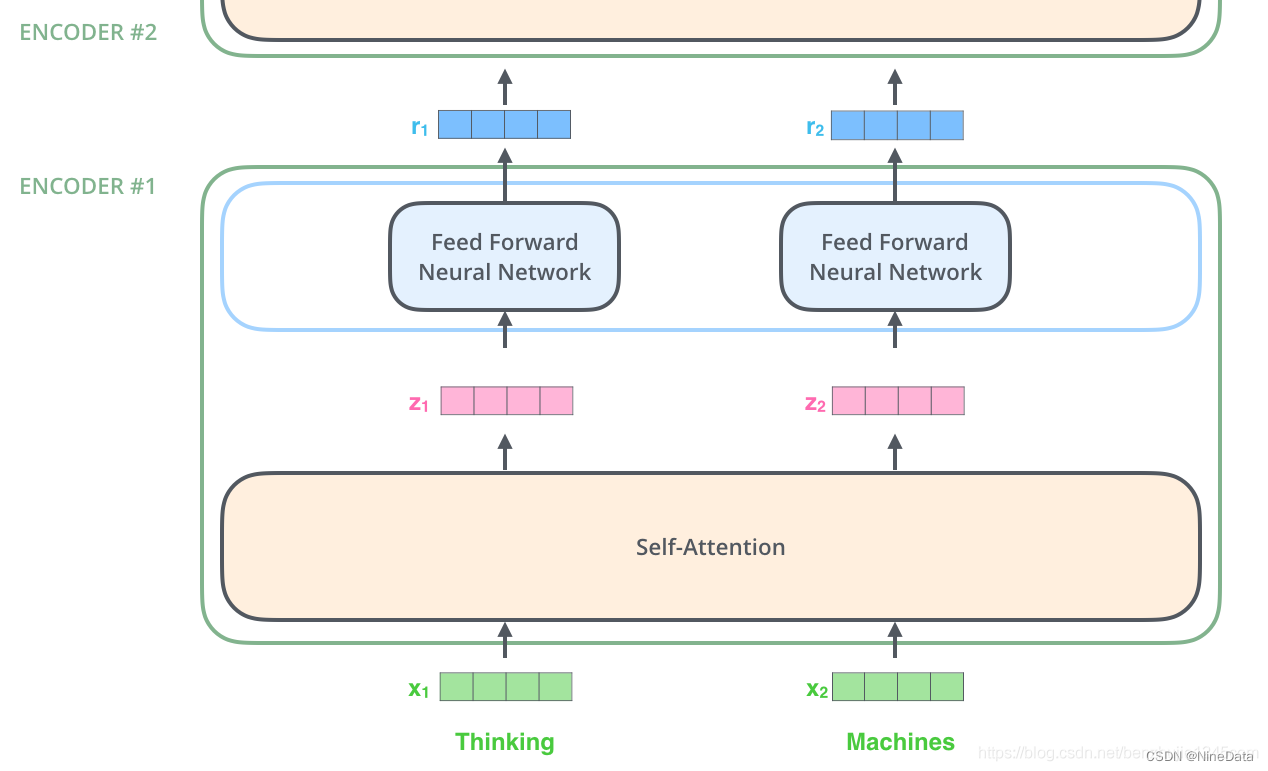
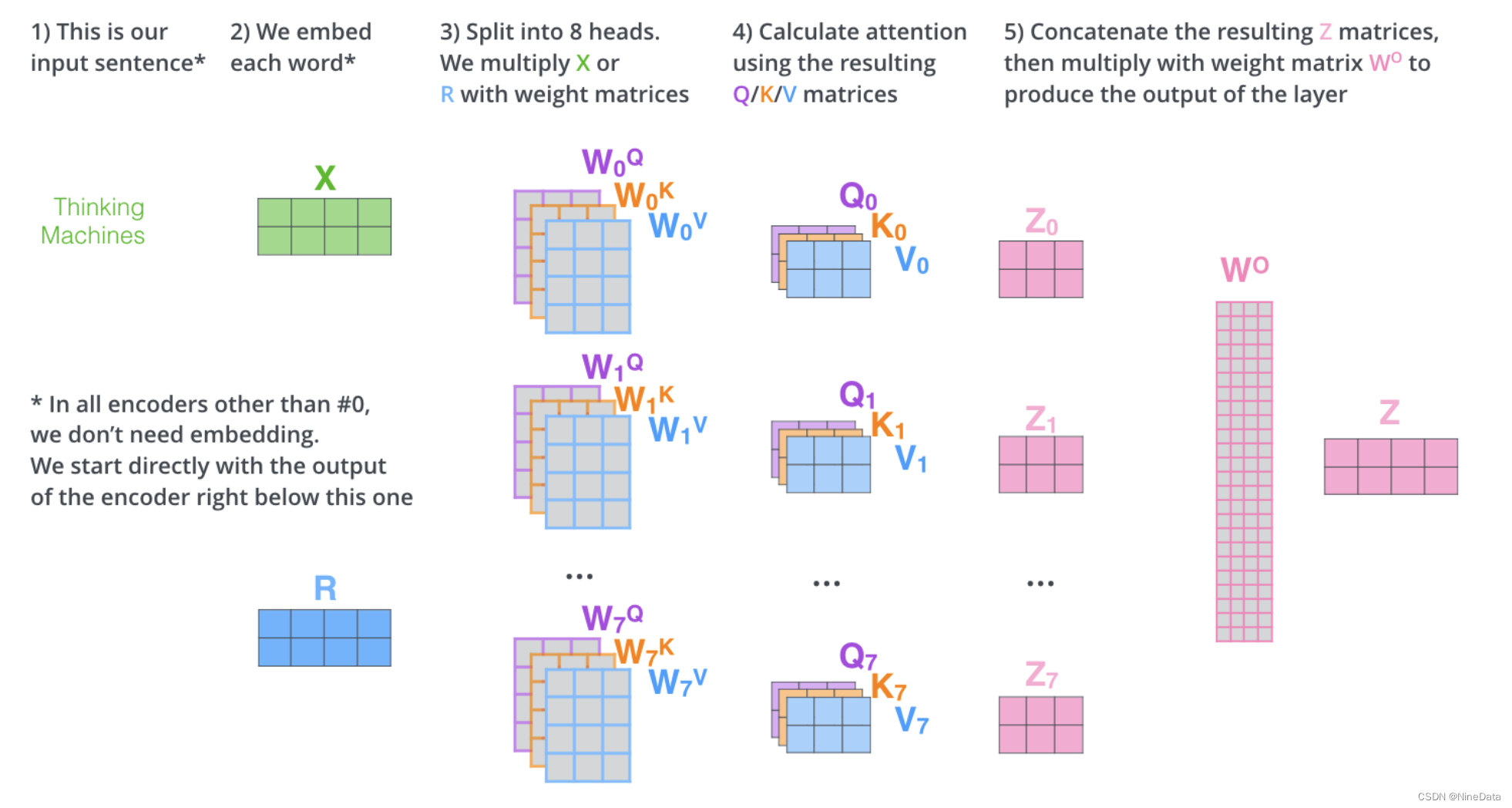
Multi-headed attention增强了自注意能力,其一是扩展了关注的位置,使之同时关注多个不同位置,其二是它为注意力层提供了多个“表示子空间”,如论文用了8个注意头,那就有8组不同的Q/K/V矩阵,每个输入的词向量都被投影到8个表示子空间中进行计算。
具体流程如下图,“Thinking Machines"的词向量经过最下面那层编码器后,使用不同的权重矩阵进行 8 次自注意力计算,就可以得到 8 个不同的 Z矩阵(0-7)。然后将8个Z矩阵拼接起来,和权重矩阵W0相乘,就得到最终的矩阵 Z,这个矩阵包含了所有注意力头的信息。这个矩阵会输入到 FFN 层。
现在重新看之前的例子,在多注意头机制下,"it" 关注的词有哪些,顶部的8种颜色代表8个注意头,可以看到有个注意头最关注"the animal",另一个注意头关注"tired",从某种意义上说,模型对“it”这个词的表示融入了“animal”和“tired”的表示。
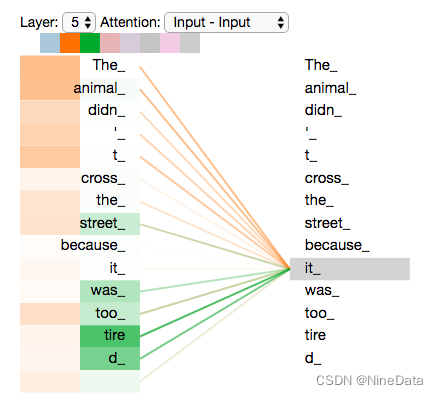
因此多注意头本质上是用更多个角度进行注意力计算再统一起来,能够增强对句子上下文的完整理解。
解码器的联动
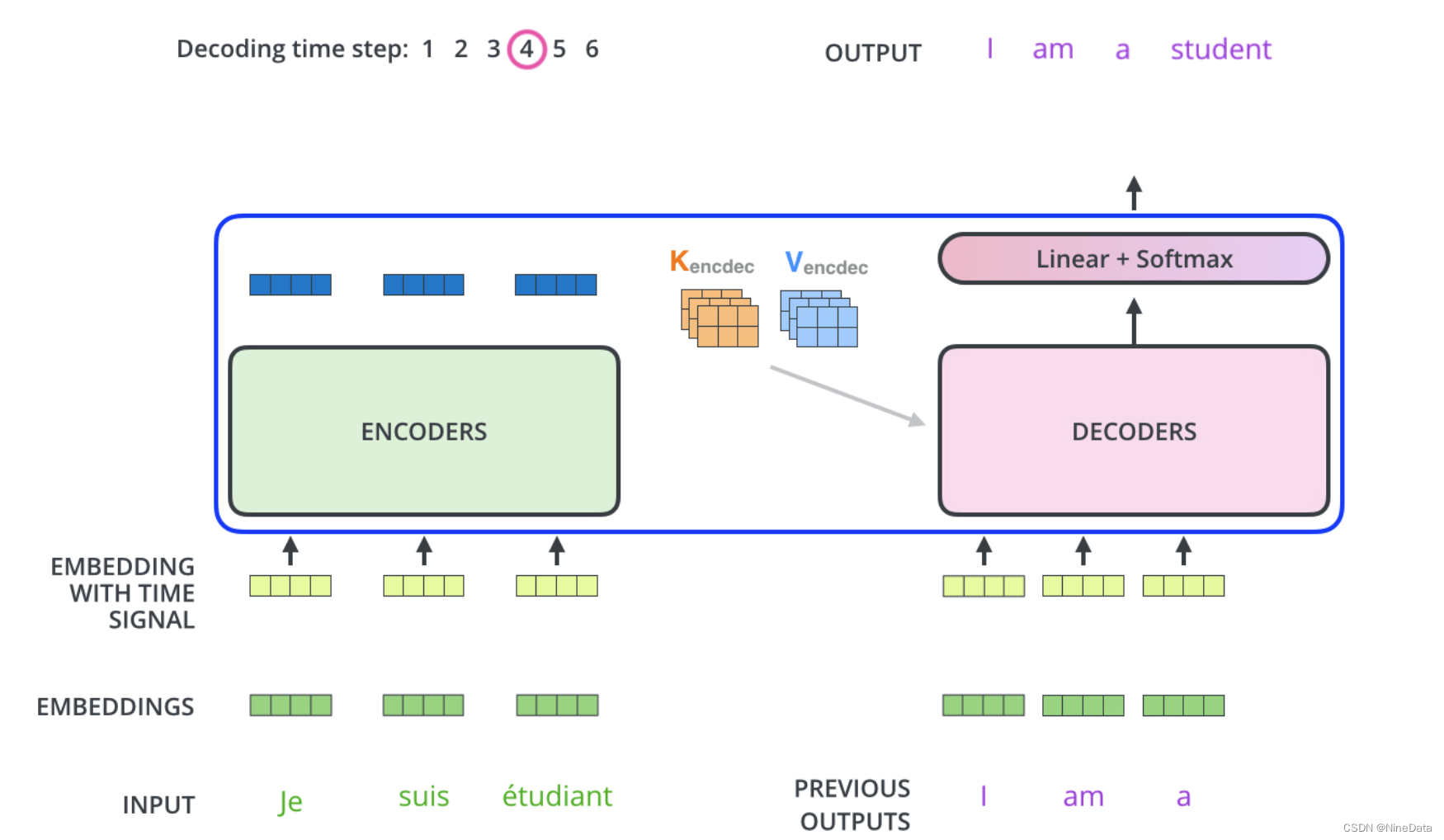
在解码器中,Transformer block比编码器中多了个encoder-cecoder attention。在encoder-decoder attention中,Q来自于解码器的上一个输出, K 和 V 则来自于编码器的输出。这些向量将在每个解码器的 Encoder-Decoder Attention 层被使用,帮助解码器把注意力关注到输入序列的合适位置。
下图显示在翻译I am a student过程中,每一轮解码器都生成一个词,如图示生成到"a"时,"a"会加入作为下一轮的输入Q,然后解码器结合输入和编码器的K、V,生成"student"。
2.2 ChatGPT是如何提升训练效果的?
ChatGPT的背后是大型语言模型 (Large Language Model,LLM) 生成领域的新训练范式:RLHF (Reinforcement Learning from Human Feedback) ,即基于来自人类反馈的强化学习来优化语言模型。关于RLHF训练有个TAMER框架(Training an Agent Manually via Evaluative Reinforcement)值得参考。
RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,这里我们按三个步骤分解:
-
预训练一个语言模型 (LM) ;
-
聚合问答数据并训练一个奖励模型 (Reward Model,RM) ;
-
用强化学习 (RL) 方式微调 LM。
GPT3训练后的大语言模型是根据概率分布,计算出下一个最大可能的词,他不管事实逻辑上的准确性,也没有所谓的意识,所以有时会一本正经地胡说八道。RLHF是用生成文本的人工反馈作为性能衡量标准,或更进一步用该反馈作为奖励来优化模型,使得在一般文本数据语料库上训练的语言模型能和复杂的人类价值观对齐。具体步骤如下:
首先,我们使用经典的预训练目标训练一个语言模型。对这一步的模型,OpenAI 在其第一个流行的 RLHF 模型 InstructGPT 中使用了较小版本的 GPT-3。然后进行以下步骤:
-
训练监督策略语言模型
GPT-3本身无法识别人类指令蕴含的不同意图,也很难判断生成内容是否高质量。为了解决这一问题,训练过程是从数据集中随机抽取问题,由标注人员给出高质量答案,相当于提供了一系列人工编写的prompts和对应的答案数据集。然后用这些人工标注好的数据集微调GPT3.5模型,获得SFT模型(Supervised Fine-Tune)。
-
训练奖励模型
训练方法:根据第一阶段的模型,随机抽取问题,给出多个不同的回答,人工选出最优答案进行标注,有点类似教学辅导。将高质量答案的奖励值进入下一轮强化学习RL,训练一个奖励模型来预测人类偏好的输出。
RM 的训练是 RLHF 区别于旧范式的开端。这一模型接收一系列文本并返回一个标量奖励,数值上对应人的偏好。我们可以用端到端的方式用 LM 建模,或者用模块化的系统建模 (比如对输出进行排名,再将排名转换为奖励) 。这一奖励数值将对后续无缝接入现有的强化学习 RL 算法至关重要。
关于模型选择方面,RM 可以是另一个经过微调的 LM,也可以是根据偏好数据从头开始训练的 LM。例如 Anthropic 提出了一种特殊的预训练方式,即用偏好模型预训练 (Preference Model Pretraining,PMP) 来替换一般预训练后的微调过程。微调LM被认为对样本数据的利用率更高,但对于哪种 RM 更好尚无定论。
-
近端策略优化 (Proximal Policy Optimization,PPO)
使用PPO优化奖励模型的策略。使用奖励模型的输出作为标量奖励,并使用PPO算法对监督策略进行微调,以优化该奖励。
训练方法:PPO的核心目的是将在线的人工学习转为离线学习,机器自己给自己打分。利用第二阶段训练好的奖励模型,在数据集中随机抽取问题,使用PPO模型生成多个回答,并用上一阶段训练好的RM模型分别给出质量分数。把回报分数按排序依次传递,产生策略梯度,通过强化学习的方式更新PPO模型参数。
最后步骤2和步骤3可以循环迭代,可以不断完善模型。
PPO算法补充说明:
长期以来出于工程和算法原因,人们认为用强化学习训练 LM 是不可能的。而目前多个组织找到的可行方案是使用策略梯度强化学习 (Policy Gradient RL) 算法、近端策略优化 (Proximal Policy Optimization,PPO) 微调初始 LM 的部分或全部参数。PPO 算法已经存在了相对较长的时间,有大量关于其原理的指南,因而成为 RLHF 中的有利选择。
我们将微调任务表述为 RL 问题。首先,该策略 (policy) 是一个接受提示并返回一系列文本 (或文本的概率分布) 的 LM。这个策略的行动空间 (action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级) ,观察空间 (observation space) 是可能的输入词元序列(词汇量 ^ 输入标记的数量,比较大) 。奖励函数是偏好模型和策略转变约束 (Policy shift constraint) 的结合。
PPO 算法确定的奖励函数具体计算如下:将提示 x 输入初始 LM 和当前微调的 LM,分别得到了输出文本 y1, y2,将来自当前策略的文本传递给 RM 得到一个标量的奖励 rθ。将两个模型的生成文本进行比较,计算差异的惩罚项,惩罚每个训练批次中生成大幅偏离初始模型的RL策略,以确保模型输出合理连贯的文本。
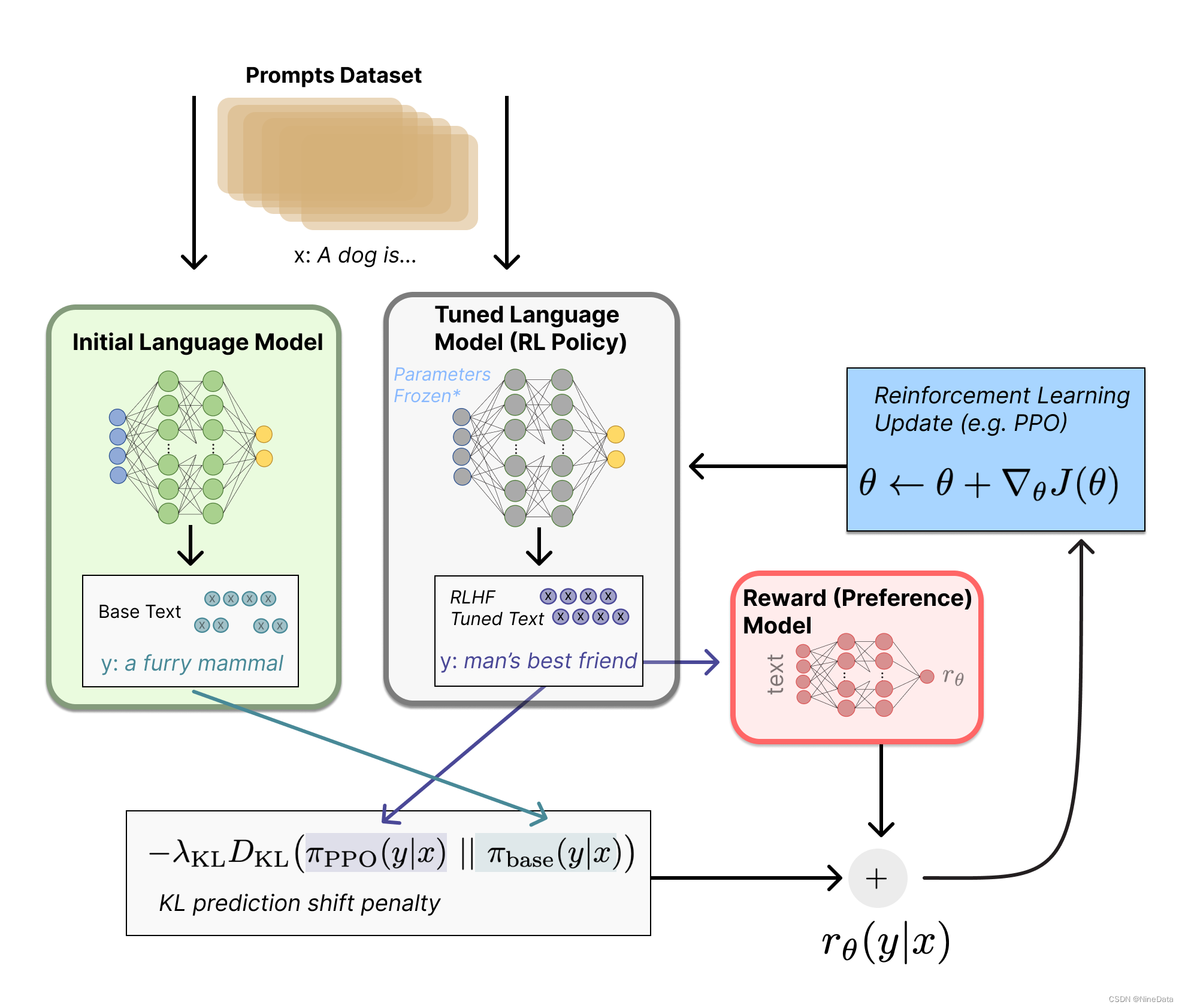
总体来说,ChatGPT 在人工标注的prompts和回答里训练出SFT监督策略模型,再通过随机问题由模型给出多个答案,然后人工排序,生成奖励模型,再通过PPO强化训练增强奖励效果。最终ChatGPT能够更好理解指令的意图,并且按指令完成符合训练者价值观的输出。
最后,大语言模型作为一个被验证可行的方向,其“大”体现在数据集广泛,参数和层数大,计算量大,其价值体现在通用性上,有广泛的应用场景。大语言模型能够发展,主要还是模型具备很好的并行扩展性,随着数据量和计算量的增加,主要挑战在工程和调优上。海外除了GPT、还有LLama、PaLM等,国内目前也有很多相应的研究,因为很多基础技术以前就存在,最近国内追赶速度也很快,我们预期国内半年左右能够到GPT 3.5水平。NineData也非常看好这个方向,并且已经将大语言模型应用到NineData平台的SQL开发中,支持通过自然语言直接查找、变更数据,提供数据库问题和知识问答、数据库SQL优化建议等多项能力,后续我们还将推出更多有价值的功能,欢迎登陆使用。https://www.ninedata.cloud
作者简介:
陈长城(天羽),玖章算术技术副总裁,前阿里云资深技术专家,在数据库领域深耕15年,主导了阿里数据库基础架构演进(IOE到分布式、异地多活、容器化存计分离)和云原生数据库工具体系建设。

参考文献:
Google Brain: “Attention is all you need”
OpenAI: “Improving Language Understanding by Generative Pre-training”
OpenAI: “Language Models are Unsupervised Multitask Learners”
OpenAI: “Language Models are Few-Shot Learner”
OpenAI: “Training language models to follow instructions with human feedback”
Luke Cheng:https://github.com/huggingface/blog/blob/main/zh/rlhf.md
Jay Alammar: http://jalammar.github.io/illustrated-transformer/
推荐阅读
使用AI优化慢SQL,开发秒变DBA
ChatGPT软件技术栈解密
玖章算术CEO叶正盛受邀AIGC论坛,分享NineData 在 AIGC 的应用实践
数据库开发工具界的ChatGPT来了