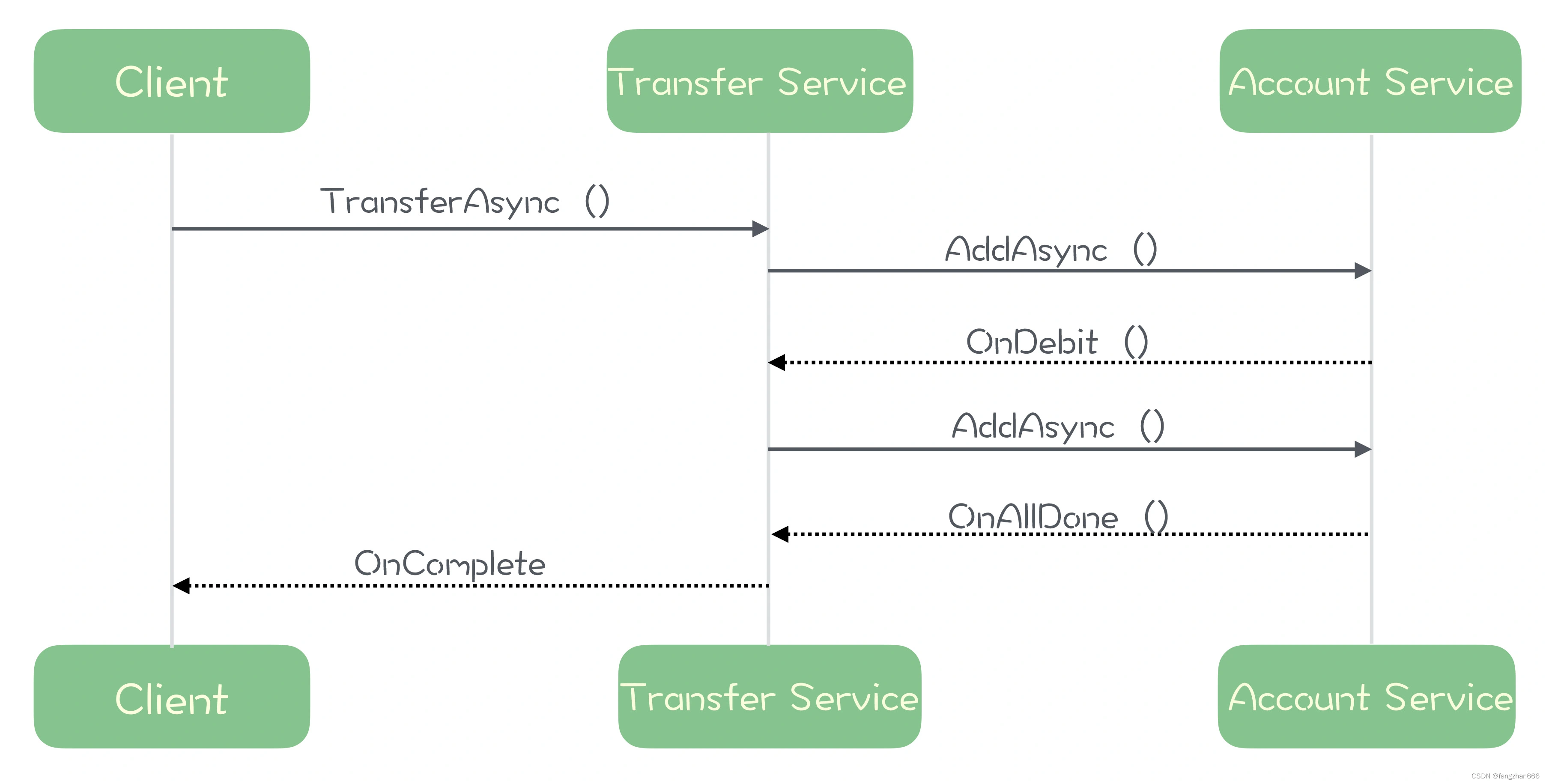
1、前言
最近因为工作需要写一些自动化脚本,里面需要用到正则表达式来匹配特定的字符串,于是查了一些正则表达式相关的资料。资料里面都提到:*匹配前面的子表达式0次或任意多次。我当时就纳闷,*到底是表示的是匹配的次数还是可以匹配任意字符呀?因为印象中,*也可以匹配任意字符。
后面有继续查阅资料,才弄明白自己混淆了正则表达式与通配符,*在正则表达式和通配符中的含义是不一样的。
类似的还有字符:?
2、正则表达式与通配符使用场景
有的场景,我们使用的是正则表达式,有的场景我们需要使用通配符。
由于我是在linux环境用得比较多,下面以shell脚本举例:
正则表达式使用场景:
正则表达式主要用来匹配文件中的字符串,主要操作有grep、awk、sed。简单来说,重点在于操作文件的具体内容,主要用于shell脚本中。
通配符的使用场景:
通配符也叫文件名替换,因此主要是用来匹配文件名并进行相关的操作,主要在shell命令行中使用。常见的操作有:
ls、find、cp、mv等。
总结就是:正则表达式主要用于shell脚本,而通配符主要用于shell命令行。
3、正则表达式与通配符具体的使用区别
3.1通配符的基本用法
通配符主要用于shell命令行中。常见的匹配规则有:
| 通配符 | 含义 | 举例 |
| * | 匹配0或多个任意字符 | a*匹配a开头的任意文件 |
| ? | 匹配任意单个字符 | a?.txt可以匹配ab.txt,ac.txt,但是不能匹配abc.txt |
| [] | 匹配括号中任意字符 | [abc].txt可以匹配a.txt 、b.txt、 c.txt |
| [!] | 匹配不在括号中的任意字符 | [!abc]*可以匹配不宜abc开头的任意文件 |
| [a-z] | 匹配a-z的任意单个字符,只能用于查找文件不能用于创建文件 | [a-z]*匹配a-z开头的任意文件 |
| {a,b,z} | 逗号分隔表示单个字符,可用于创建和查找文件 | {a,b,z}*表示以a或b或z开头的任意文件 |
| {a..z} | ..分隔表示连续字符,表示范围 | {a..z}*表示任意小写字母开头的文件 |
特别需要说明的是:
由于上面表中的一些字符,如*?[]等字符具有特殊的含义(用法),例如,*并不是代表这个字符本身,而是代表任意字符,因此如果需要匹配*本身,需要转义。转义用\表示,如
\*表示*本身,\*abc 可以匹配字符串 "*abc"
为了帮助大家更好的理解,下面做一些demo:
当前目录的结构如下:

ls [hs]* # 列出所有h或s开头的文件,包括h或s开头的文件夹内的文件 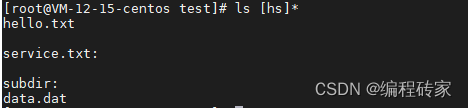
touch test{1..3}.txt # 创建text1到test3.txt
3.2 正则表达式的基本用法
正则表达式主要用于shell脚本中。常见用法如下:
| 元字符 | 含义 | 用法举例 |
| () | 表示一个字表达式,括号内是一个整体 | |
| * | 前一个子表达式或字符匹配0或任意多次 | ab*可以匹配a、ab、abb、abbb等 h(ab)*可以匹配h或hab或habab |
| ? | 前一个子表达式或字符匹配0或1次 | h(ab)*可以匹配h或hab,不能匹配habab |
| + | 前一个子表达式1次或以上,扩展正则表达式 | |
| . | 匹配出换行符\n之外的任意单个字符 | |
| [] | 匹配括号中任意一个指定字符,只匹配一个字符 | [aeiou]可以匹配google中的o e |
| [^] | 匹配不再括号中的任意一个字符 | |
| ^ | 匹配行首(当不位于[]内时) | ^hello匹配hello开头的字符串 |
| $ | 匹配行尾 | |
| \ | 转义字符,取消特殊含义 | \可以匹配字符*,此时*不再表示匹配次数 |
| {n} | 表示前面的字符恰好n次 | |
| {n,} | 表示前面的字符最少出现n次 | |
| {n,m} | 表示前面的字符出现n~m次 | |
| \1 | 引用第一个左括号以及与之对应的右括号所包括的所有内容,\2同理 |
同通配符的规则,一样,匹配上面表中的特殊字符(元字符)时,也需要转义:
例如\*表示*这个字符本身,次数*不再表示前面的字符可以出现的次数为任意次。