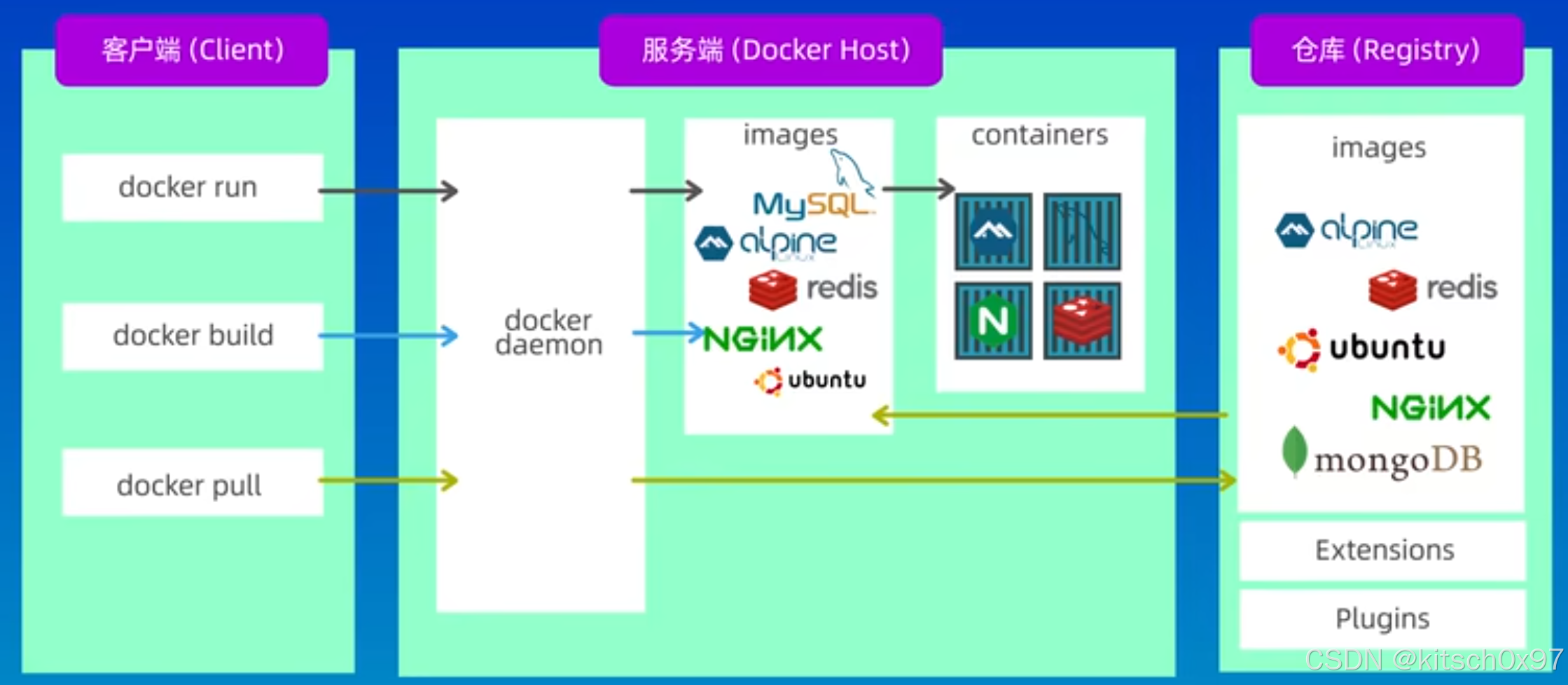
摘要:理解文档图像(如发票)是一个核心且具有挑战性的任务,因为它需要执行复杂的功能,如读取文本和对文档的整体理解。目前的视觉文档理解(VDU)方法将读取文本的任务外包给现成的光学字符识别(OCR)引擎,并专注于使用OCR输出进行理解任务。尽管基于OCR的方法显示出令人鼓舞的性能,但它们面临以下问题:1)使用OCR的高计算成本;2)OCR模型在语言或文档类型上的灵活性差;3)OCR错误会传播到后续处理过程。为了解决这些问题,本文提出了一种新的无OCR的VDU模型,名为Donut(即文档理解Transformer)。作为无OCR的VDU研究的第一步,我们提出了一个简单的架构(即Transformer)和预训练目标(即交叉熵损失)。Donut概念上简单但有效。通过广泛的实验和分析,我们展示了一个简单的无OCR的VDU模型Donut,在各种VDU任务中,无论是在速度还是准确性上都达到了最先进的性能。此外,我们提供了一个合成数据生成器,帮助模型的预训练在各种语言和领域中更具灵活性。代码、训练模型和合成数据可以在https://github.com/clovaai/donut中获取。
关键词:视觉文档理解,文档信息提取,光学字符识