JVM性能调优
- 1. JDK的体系结构
- 2. Java语言的跨平台特性
- 3.JVM整体结构及内存模型
- 3.1 内存模型
- 3.1.1 PC寄存器(线程私有)
- 3.1.2 虚拟机栈(线程私有)
- 1. 局部变量表
- 2. 操作数栈
本文是按照自己的理解进行笔记总结,如有不正确的地方,还望大佬多多指点纠正,勿喷。
1、JDK体系结构与跨平台特性介绍
2、JVM内存模型深度剖析
3、从jvisualvm来研究下对象内存流转模型
4、讲透Gc Root与STW机制
5、日均百万级订单交易系统JVM参数如何设置
6、JVM参数设置通用模型
1. JDK的体系结构
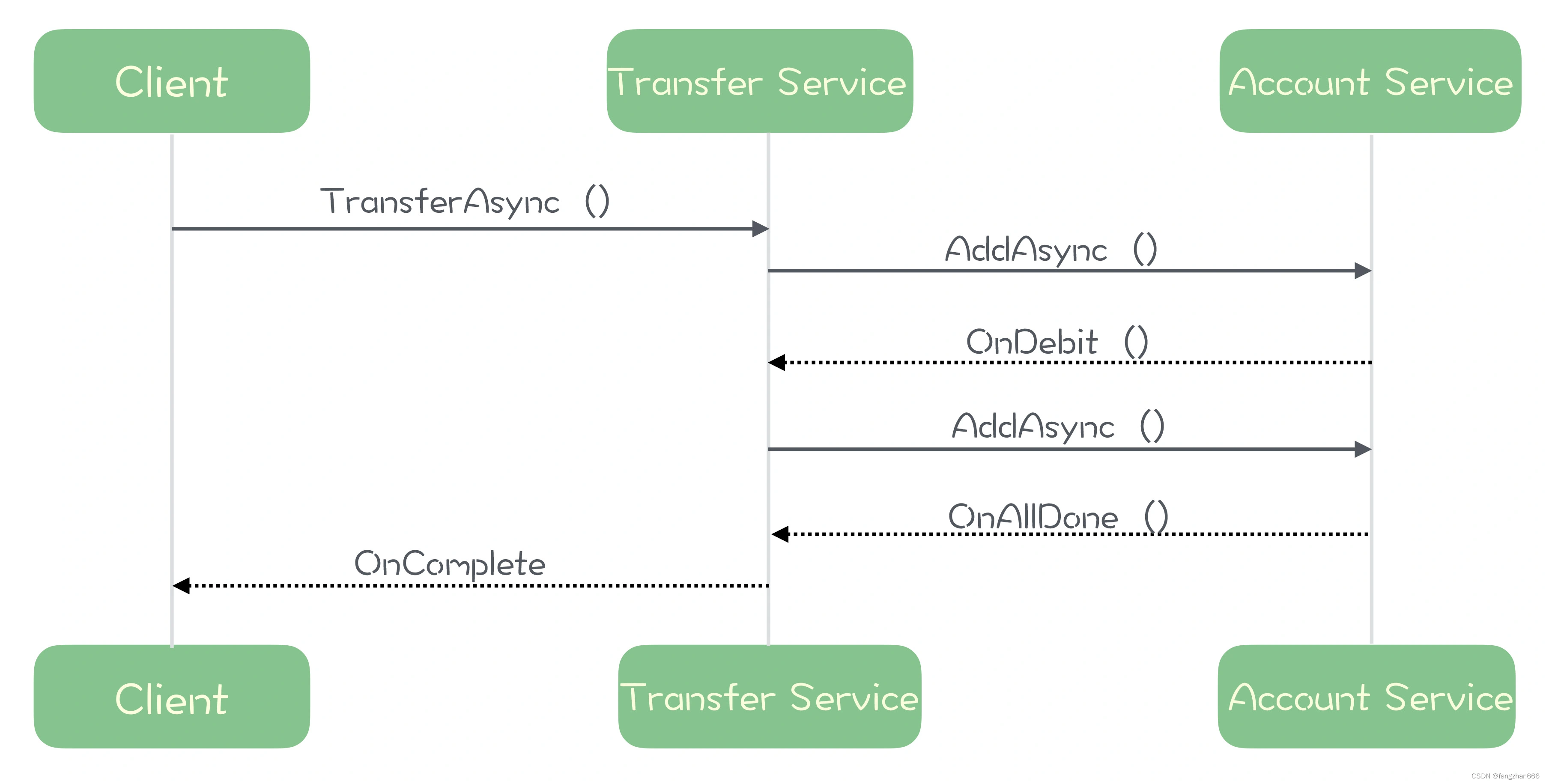
JDK: JDK提供了编译、运行Java程序所需的各种资源和工具;包括Java编译器,Java运行时环境【JRE】;开发工具包括编译工具(javac.exe) 打包工具(jar.exe)等。
JRE: 即JAVA运行时环境,JVM就是包括在JRE中,以及常用的JAVA类库等;
SDK: SDK是基于JDK进行扩展的,是解决企业级开发的工具包。如JSP、JDBC、EJB等就是由SDK提供的 ;
JVM(Java Virtual Machine),Java虚拟机,可以看做是一台抽象化的计算机,它有一套完整的体系架构,包括处理器、堆栈 、寄存器等。
在运行时环境,JVM会将Java字节码解释成机器码。机器码和平台相关的(不同硬件环境、不同操作系统,产生的机器码不同),所以JVM在不同平台有不同的实现。目前JDK默认使用的实现是Hotspot VM。
2. Java语言的跨平台特性
一次编译,到处执行(Write Once ,Run Anywhere)。 用Java创建的可执行二进制程序,能够不加改变的运行于多个平台。从软件层面屏蔽不同操作系统底层硬件与指令上的区别
其实跨平台就是JVM来做的,我们在下载JDK的时候,会让我们选择不同的操作系统按照相应的JDK就是为了对应不同的操作系统。
3.JVM整体结构及内存模型
官方文档参考:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.htmI#jvms-2.5.4
3.1 内存模型
Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为个不同的数据区。这些区域有各自的用途,以及创建和销毁事件。
JVM用来存储加载的类信息、常量、静态变量、编译后的代码等数据。
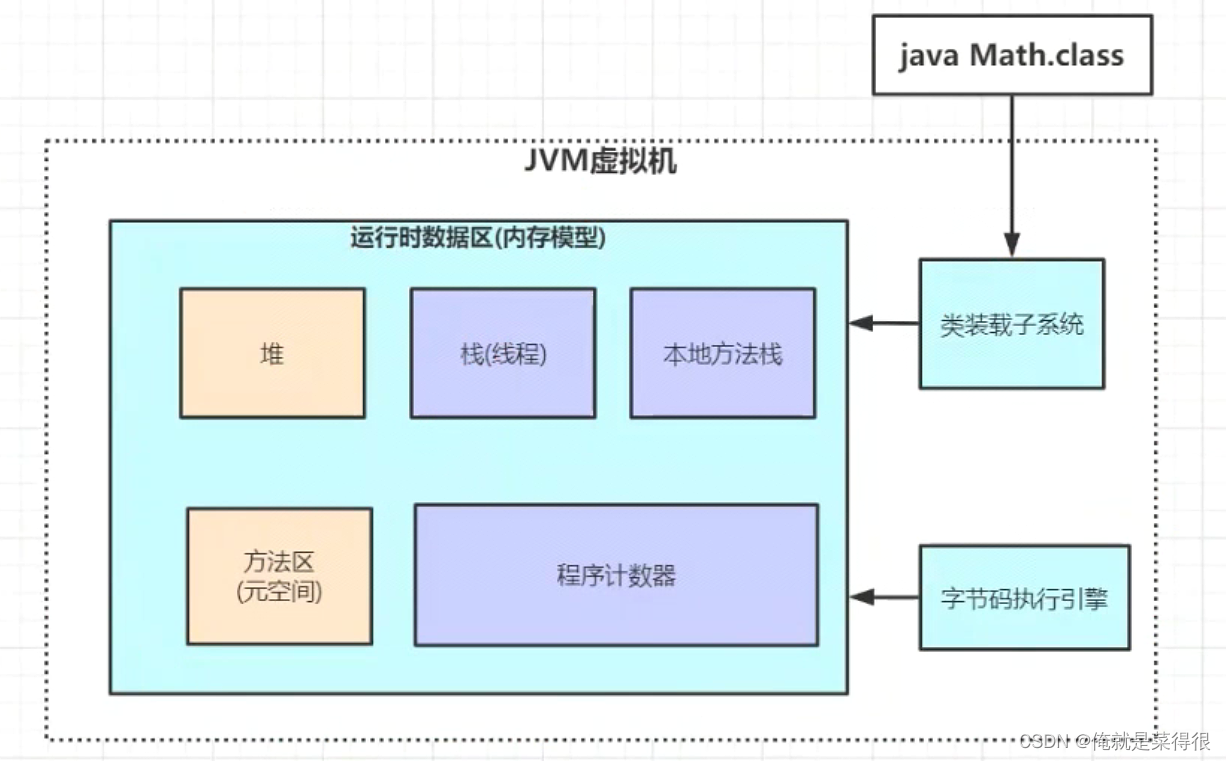
3.1.1 PC寄存器(线程私有)
PC寄存器,也叫程序计数器。JVM支持多个线程同时运行,每个线程都有自己的程序计数器。倘若当前执行的是JVM方法,则该寄存器中保存当前执行指令的地址;倘若执行的是native方法,则PC寄存器为空。
这个内存区域是唯一一个在虚拟机中没有规定任何OutOfMemoryError情况的区域。
3.1.2 虚拟机栈(线程私有)
栈里面是存局部变量的。每个线程有一个私有的栈,随着线程的创建而创建。栈里面存放着一种叫做“栈帧”的东西,每个方法在执行的时候会创建一个栈帧,存储了局部变量表(基本数据类型和对象引用),操作数栈,动态连接,方法出口等信息。
每个方法从调用到执行完毕,对应一个栈帧在虚拟机栈中的入栈和出栈。
(方法中的局部变量的空间可以进行释放)
通常所说的栈,一般是指虚拟机栈中的局部变量表部分。局部变量表所需的内存在编译期间完成分配。
栈的大小可以固定也可以动态扩展,当扩展到无法申请足够的内存,则OutOfMemoryError。
当栈调用深度大于JVM所允许的范围,会抛出StackOverflowError的错误
演示栈帧:
package ding;
public class Math {
public static final int initData = 666;
public static People people = new People();
public int compute(){
int a = 1;
int b = 2;
int c = (a + b) * 10;
return c;
}
public static void main(String[] args) {
Math math = new Math();
math.compute();
}
}
当我们的线程一开始运行main方法,马上分配一块自己专属的线程栈,只要线程开始运行main方法,会在这一大块线程栈里面给自己的mian方法分配一块自己专属的地方,放main方法自己的局部变量,比如math。然后compute一运行又会给compute分配栈内存区域,用来放compute的局部变量。整个JVM内部他给每一个方法都会分配一块专属的内存空间,我们把这块空间叫做栈内存空间。
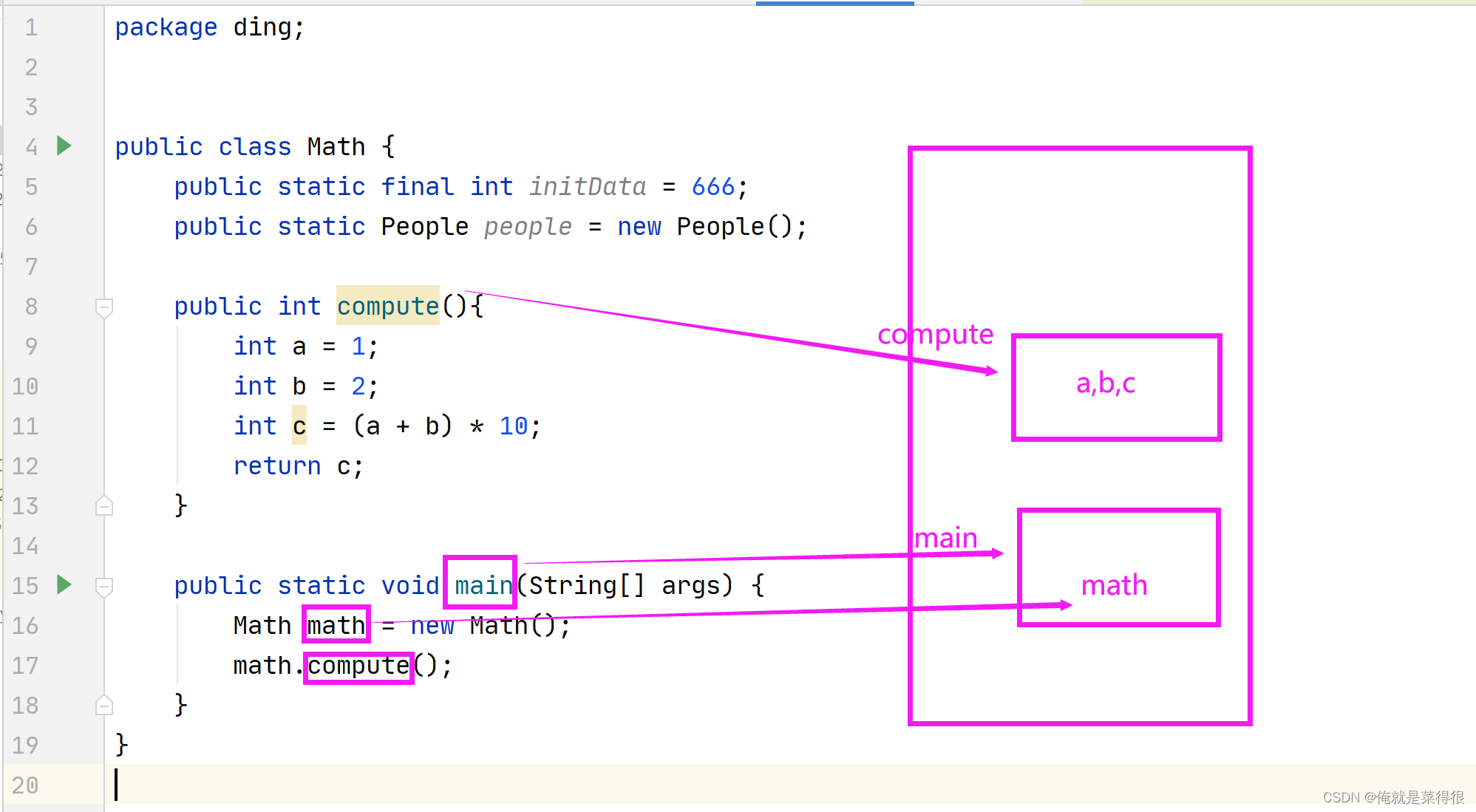
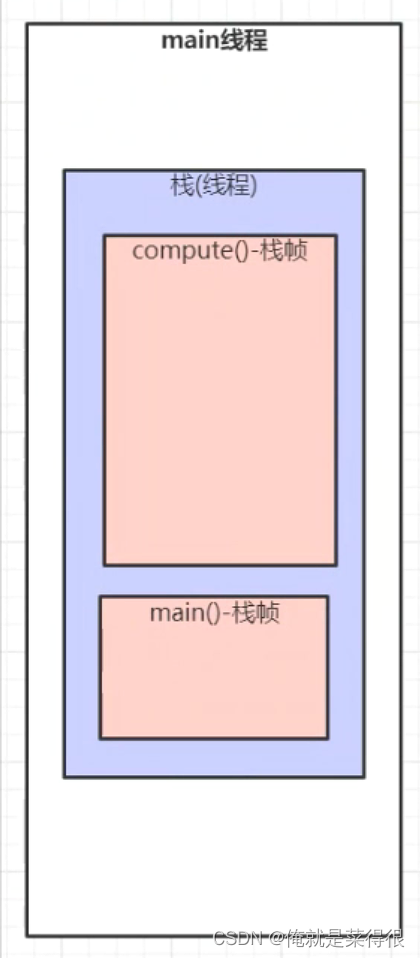
那这个里面的栈与数据结构的栈(先进后出)有什么不一样的吗?
这个栈就是数据结构里面的栈,是一样的,这个下面是栈底,上面是栈顶,就是mian在栈底,compute在栈顶,出的时候就是compute先出,然后main再出。
为什么用数据结构里面的栈存储内存空间呢?
比如这个compute方法他是后调用的,但是他会先执行完,然后释放空间。
如果是递归的话在内存里面也不是套娃,也是一个一个往上,有很多个compute,他是往栈顶一直走,不是套娃。
栈帧内部还是比较复杂的,除了放局部变量表之外,还有一块是操作数栈、动态链接、方法出口。
1. 局部变量表
就是放一些局部变量的
2. 操作数栈
看这个就需要看字节码文件
我们先来看字节码文件。
然后进行反汇编。打开终端

下面这个相当于是JVM的汇编语言。
Compiled from "Math.java"
public class ding.Math {
public static final int initData;
public static ding.People people;
public ding.Math();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public int compute();
Code:
0: iconst_1
1: istore_1
2: iconst_2
3: istore_2
4: iload_1
5: iload_2
6: iadd
7: bipush 10
9: imul
10: istore_3
11: iload_3
12: ireturn
public static void main(java.lang.String[]);
Code:
0: new #2 // class ding/Math
3: dup
4: invokespecial #3 // Method "<init>":()V
7: astore_1
8: getstatic #4 // Field java/lang/System.out:Ljava/io/PrintStream;
11: aload_1
12: invokevirtual #5 // Method compute:()I
15: invokevirtual #6 // Method java/io/PrintStream.println:(I)V
18: getstatic #4 // Field java/lang/System.out:Ljava/io/PrintStream;
21: ldc #7 // String test
23: invokevirtual #8 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
26: return
static {};
Code:
0: new #9 // class ding/People
3: dup
4: invokespecial #10 // Method ding/People."<init>":()V
7: putstatic #11 // Field people:Lding/People;
10: return
}
JVM的指令手册可以看:https://blog.csdn.net/weixin_44991304/article/details/120057916
我们首先来看compute方法,在这个方法里面的第一句话:
0: iconst_1这句话的意思就是讲jint类型常量1压入操作数栈。
这个前4行就是把变量a,b进行赋值。
就是先把1放到操作数栈里面,
然后是a在局部变量表里面,然后把操作数栈里面的1赋值给局部变量表里面的a。接着b也是这样的操作。