1 Impala 基本介绍
impala 是 cloudera 提供的一款高效率的 sql 查询工具,提供实时的查询效果,官方测试性能比 hive 快 10 到 100 倍,其 sql 查询比 sparkSQL 还要更加快速,号称是当前大数据领域最快的查询 sql 工具,impala 是参照谷歌的新三篇论文(Caffeine--网络搜索引擎、Pregel--分布式图计算、Dremel--交互式分析工具)当中的 Dremel 实现而来,其中旧三篇论文分别是(BigTable,GFS,MapReduce)分别对应 HBase 和 HDFS 以及 MapReduce。
impala 是基于 hive 并使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点。
2 Impala与Hive关系
impala 是基于 hive 的大数据分析查询引擎,直接使用 hive 的元数据库metadata,意味着 impala 元数据都存储在 hive 的 metastore 当中,并且 impala 兼容 hive 的绝大多数 sql 语法。所以需要安装 impala 的话,必须先安装 hive,保证hive 安装成功,并且还需要启动 hive 的 metastore 服务。
Hive 元数据包含用 Hive 创建的 database、table 等元信息。元数据存储在关系型数据库中,如 Derby、MySQL 等。客户端连接 metastore 服务,metastore 再去连接 MySQL 数据库来存取元数据。有了 metastore 服务,就可以有多个客户端同时连接,而且这些客户端不需要知道 MySQL 数据库的用户名和密码,只需要连接 metastore 服务即可。
nohup hive --service metastore >> ~/metastore.log 2>&1 &
Hive 适合于长时间的批处理查询分析,而 Impala 适合于实时交互式 SQL 查询。可以先使用 hive 进行数据转换处理,之后使用 Impala 在 Hive 处理后的结果数据集上进行快速的数据分析。
3 Impala 与 Hive 异同
Impala 与 Hive 都是构建在 Hadoop 之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看 Impala 与 Hive 有很多的共同之处,如数据表元数据、ODBC/JDBC 驱动、SQL 语法、灵活的文件格式、存储资源池等。
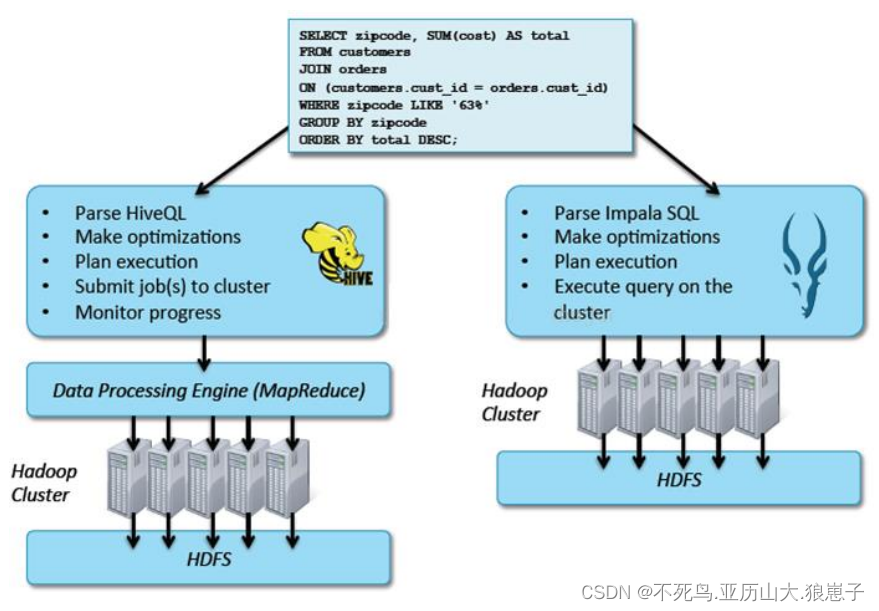
但是 Impala 跟 Hive 最大的优化区别在于:没有使用 MapReduce 进行并行计算,虽然 MapReduce 是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的 SQL 执行。与 MapReduce 相比,Impala 把整个查询分成一执行计划树,而不是一连串的 MapReduce 任务,在分发执行计划后,Impala 使用拉式获取数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。Impala 使用服务的方式避免每次执行查询都需要启动的开销,即相比 Hive 没了 MapReduce 启动时间。
3.1 Impala 使用的优化技术
使用 LLVM 产生运行代码,针对特定查询生成特定代码,同时使用 Inline 的方式减少函数调用的开销,加快执行效率。(C++特性)
充分利用可用的硬件指令(SSE4.2)。更好的 IO 调度,Impala 知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时 Impala 支持直接数据块读取和本地代码计算 checksum。
通过选择合适数据存储格式可以得到最好性能(Impala 支持多种存储格式)。
最大使用内存,中间结果不写磁盘,及时通过网络以 stream 的方式传递。
3.2 执行计划
Hive: 依赖于 MapReduce 执行框架 , 执行计划分成map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个 Query 会 被编译成多轮 MapReduce,则会有更多的写中间结果。由于 MapReduce 执行框架本身的特点,过多的中间过程会增加整个 Query 的执行时间。
Impala: 把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个 Impalad 执行查询,而不用像 Hive 那样把它组合成管道型的map->reduce 模式,以此保证 Impala 有更好的并发性和避免不必要的中间 sort 与shuffle。
3.3 数据流
Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
Impala: 采用拉的方式,后续节点通过 getNext 主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有 1 条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合 SQL 交互式查询使用。
3.4 内存使用
Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证 Query能顺序执行完。每一轮 MapReduce 结束,中间结果也会写入 HDFS 中,同样由于MapReduce 执行架构的特性,shuffle 过程也会有写本地磁盘的操作。
Impala: 在遇到内存放不下数据时,版本 1.0.1 是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得 Impala 目前处理 Query 会受到一定的限制,最好还是与 Hive 配合使用。
3.5 调度
Hive: 任务调度依赖于 Hadoop 的调度策略。
Impala: 调度由自己完成,目前只有一种调度器 simple-schedule,它会尽量满足数据的局部性,扫描数据的进程尽量靠近数据本身所在的物理机器。调度器目前还比较简单,在 SimpleScheduler::GetBackend 中可以看到,现在还没有考虑负载,网络 IO 状况等因素进行调度。但目前 Impala 已经有对执行过程的性能统计分析,应该以后版本会利用这些统计信息进行调度吧。
3.6 容错
Hive: 依赖于 Hadoop 的容错能力。
Impala: 在查询过程中,没有容错逻辑,如果在执行过程中发生故障,则直接返回错误(这与 Impala 的设计有关,因为 Impala 定位于实时查询,一次查询失败, 再查一次就好了,再查一次的成本很低)。
3.7 适用面
Hive: 复杂的批处理查询任务,数据转换任务。
Impala:实时数据分析,因为不支持 UDF,能处理的问题域有一定的限制,与 Hive 配合使用,对 Hive 的结果数据集进行实时分析。
4 Impala 架构
Impala 主要由 Impalad、 State Store、Catalogd 和 CLI 组成。
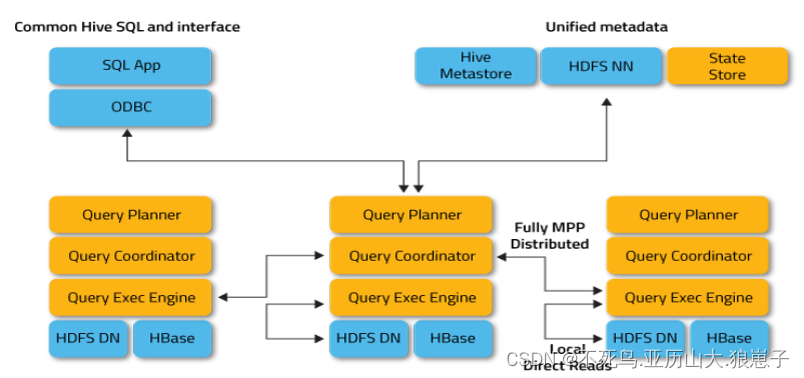
4.1 Impalad
Impalad: 与 DataNode 运行在同一节点上,由 Impalad 进程表示,它接收客户端的查询请求(接收查询请求的 Impalad 为 Coordinator,Coordinator 通过 JNI 调用 java前端解释 SQL 查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它 Impalad 进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给 Coordinator,由 Coordinator 返回给客户端。同时 Impalad 也与 State Store 保持连接,用于确定哪个 Impalad 是健康和可以接受新的工作。
在 Impalad 中启动三个 ThriftServer: beeswax_server(连接客户端),hs2_server(借用 Hive 元数据),be_server(Impalad 内部使用)和一个 ImpalaServer 服务。
4.2 Impala State Store
Impala State Store: 跟踪集群中的 Impalad 的健康状态及位置信息,由statestored 进程表示,它通过创建多个线程来处理 Impalad 的注册订阅和与各Impalad 保持心跳连接,各 Impalad 都会缓存一份 State Store 中的信息,当 State Store 离线后(Impalad 发现 State Store 处于离线时,会进入 recovery 模式,反复注册,当 State Store 重新加入集群后,自动恢复正常,更新缓存数据)因为 Impalad有 State Store 的缓存仍然可以工作,但会因为有些 Impalad 失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的 Impalad,导致查询失败。
4.3 CLI
CLI: 提供给用户查询使用的命令行工具(Impala Shell 使用 python 实现),同时 Impala 还提供了 Hue,JDBC, ODBC 使用接口。
4.4 Catalogd
Catalogd:作为 metadata 访问网关,从 Hive Metastore 等外部 catalog 中获取元数据信息,放到 impala 自己的 catalog 结构中。impalad 执行 ddl 命令时通过catalogd 由其代为执行,该更新则由 statestored 广播。
5 Impala 查询处理过程
Impalad 分为 Java 前端与 C++处理后端,接受客户端连接的 Impalad 即作为这次查询的 Coordinator,Coordinator 通过 JNI 调用 Java 前端对用户的查询 SQL进行分析生成执行计划树。
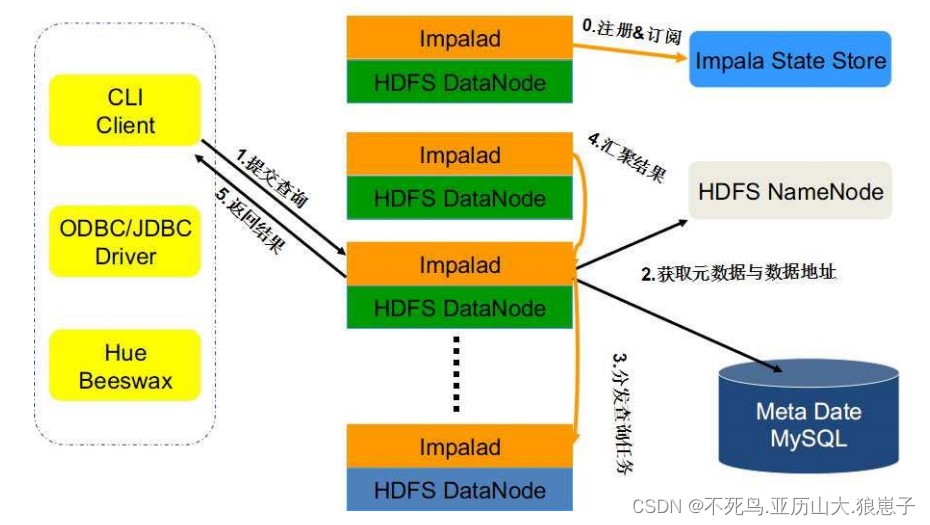
Java 前端产生的执行计划树以 Thrift 数据格式返回给 C++后端(Coordinator)(执行计划分为多个阶段,每一个阶段叫做一个 PlanFragment,每一个 PlanFragment 在执行时可以由多个 Impalad 实例并行执行(有些 PlanFragment 只能由一个 Impalad 实例执行,如聚合操作),整个执行计划为一执行计划树)。
Coordinator 根据执行计划,数据存储信息(Impala 通过 libhdfs 与 HDFS 进行交互。通过 hdfsGetHosts 方法获得文件数据块所在节点的位置信息),通过调度器(现在只有 simple-scheduler, 使用 round-robin 算法)Coordinator::Exec 对生成的执行计划树分配给相应的后端执行器 Impalad 执行(查询会使用 LLVM 进行代码生成,编译,执行),通过调用 GetNext()方法获取计算结果。
如果是 insert 语句,则将计算结果通过 libhdfs 写回 HDFS 当所有输入数据被消耗光,执行结束,之后注销此次查询服务。