文章目录
- (零)前言
- (一)模型(LoRA)训练
- (1.1)数据准备
- (1.1.1)筛选照片
- (1.1.2)预处理照片
- (1.1.3)提示词(tags)处理
- (1.1.4)目录命名
- (1.2)训练工具
- (1.2.1)脚本训练
- (1.2.1.1)训练参数
- (1.2.1.2)训练过程(例)
- (1.2.2)图形化配置训练
- (1.2.2.1)启动图形界面
- (1.2.2.2)训练日志查看
- (1.2.3)训练结果
- (二)各epoch模型对比
- (2.1)使用:可选附加网络插件
- (2.1.1)安装
- (2.1.2)配置
- (2.1.3)配合脚本:X/Y/Z图表
- (2.2)生成/结果
- (2.3)自己用眼睛对比
- (2.4)注意事项
(零)前言
本篇主要提到Stable Diffusion的LoRA模型训练,其实在之前的那个索引文章里稍微提到过。
就是这篇啦:🔗《继续Stable-Diffusion WEBUI方方面面研究(内容索引)》
只不过是记流水账一样的介绍,难以讲清楚一些小问题,所以干脆新建一篇,补充详细一些。
(一)模型(LoRA)训练
基础模型(大模型)没有条件,这里提到的仅是LoRA模型。
(1.1)数据准备
(1.1.1)筛选照片
这部分感觉比深度伪造(deep fake)要轻松多了。
-
假设训练的是人物,准备自己的人像图片,20 - 40 张就可以了,当然我看模型也有100多张的,目前看来照片多角度丰富效果会比较好。
-
尽量简单背景,或进行人像抠图后填充简单颜色背景。
似乎不是每台电脑都正常能用插件抠图⚠️?
所以另外的选择可以在线抠图(你用PS自己弄不累嘛),比如:在线抠图,趣作图。抠图不好的话,那些原始素材中不是人物的东西可能也会被生成。 -
处理成同样的分辨率,避免后续自动处理。
-
最好是半身照片,少用大头照,最好不要全身带腿脚的照片(可以自行剪切)。
(1.1.2)预处理照片
用WEB UI的 训练 -> 预处理 标签页的功能,
- 将刚才准备好的照片目录作为输入目录。
- 将某个类似命名
.\xxyyzz\8_xxyyzz的目录作为输出目录。 - 调整到上一步用的同样的分辨率。
- 勾选使用 deepbooru 生成说明文字(tags)
- 点击【预处理】按钮后,等待图片预处理完成,检查图片和提示词文本。
(1.1.3)提示词(tags)处理
如果背景并不是很乱,发型配饰上没有个人特色,那么可以不处理:)哈哈。
算了😮💨,还是认真写两句:
- 如果背景很单纯,或已经比较好的抠图,确实可以不处理。
- 检查和图片同名的提示词文本内容,会发现生成了很多已经识别出来的关键词。
- 不在这些自动生成的关键词的图片内容,大概就是你的LoRA模型的特点。
- 如果某个物品是人物特诊的一部分,请删掉这个关键词。
- 可以加入人物名称到关键词第一位(无论是网上说法和实测似乎也没啥用,本条暂时保留)。
(1.1.4)目录命名
刚才提到预处理后的目录叫 .\xxyyzz\8_xxyyzz。
xxyyzz:是具体的模型简称。8:是里面每张图片训练的次数,这里我看到两种说法,一种是设为6-8,一种是根据图片数量至少设置100。
这个次数会乘以后面设置的训练参数的epoch数,最后会训练大概几千次吧。
⚠️ 非常值得关注的事项
- 最好不要用数字
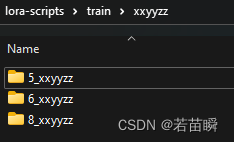
100,而是使用6-8这样的小数字x多个epoch,便于对比成果。 - 目录结构并不是在
\xxxxx\下只能有一个\8_xxxxx\,我们可以把大头照/半身照/全身照分别放入3个子目录。
每种目录中的文件设置不同的学习次数,比如大头少学习,半身主要学习,如下图的结构:
(1.2)训练工具
(1.2.1)脚本训练
- bmaltais/kohya_ss (图形化界面)
- Akegarasu/lora-scripts (编辑参数脚本训练)
实际上都是调用的kohya_ss的sd-scripts项目。
我比较倾向用脚本那个项目lora-scripts来训练。
写配置文件反而比较简单,WEB界面在训练这块用处不大。当然你也可以选自己喜欢的。
💡 大家应该注意到了。
lora-scripts这个训练LoRA的项目,以及WEBUI启动器,都是秋葉aaaki这位同学的(就像DeepFaceLab的作者伊佩罗夫当时也是在校学生一样)。他最近也完善了训练的WEB界面。
两个建议:
- 用别人做好的整合包吧,比如脚本训练用:https://www.bilibili.com/video/BV1fs4y1x7p2
- Python下载依赖时一定要换国内源,比如清华大学的:
-i https://pypi.tuna.tsinghua.edu.cn/simple。当然整合包的话已经换好了,否则可以参考我吐槽下载速度这块,实在慢到吐血(习惯了,Linux,Go,Python哪个不换国内源呢)。
(1.2.1.1)训练参数
我用的是lora-scripts,训练脚本train.ps1必须得改的几个参数:
- $pretrained_model :基础模型路径(最好填入WEB UI下的绝对路径,避免拷贝几个GB的数据)
- $train_data_dir :训练数据集路径(预处理完成的图片和提示词存放目录)
- $resolution :分辨率(需要多少预处理成多少,填写一致)
- $max_train_epoches :最大训练 epoch (1个epoch是一个完整的数据集通过神经网络一次并且返回一次的过程)
- $save_every_n_epochs :每几个 epoch 保存一次
- $output_name :模型保存名称
完整如下(参数可能改动和变化,和项目版本有关):
# LoRA train script by @Akegarasu
# Train data path | 设置训练用模型、图片
$pretrained_model = "./sd-models/model.ckpt" # base model path | 底模路径
$is_v2_model = 0 # SD2.0 model | SD2.0模型 2.0模型下 clip_skip 默认无效
$parameterization = 0 # parameterization | 参数化 本参数需要和 V2 参数同步使用 实验性功能
$train_data_dir = "./train/aki" # train dataset path | 训练数据集路径
$reg_data_dir = "" # directory for regularization images | 正则化数据集路径,默认不使用正则化图像。
# Network settings | 网络设置
$network_module = "networks.lora" # 在这里将会设置训练的网络种类,默认为 networks.lora 也就是 LoRA 训练。如果你想训练 LyCORIS(LoCon、LoHa) 等,则修改这个值为 lycoris.kohya
$network_weights = "" # pretrained weights for LoRA network | 若需要从已有的 LoRA 模型上继续训练,请填写 LoRA 模型路径。
$network_dim = 32 # network dim | 常用 4~128,不是越大越好
$network_alpha = 32 # network alpha | 常用与 network_dim 相同的值或者采用较小的值,如 network_dim的一半 防止下溢。默认值为 1,使用较小的 alpha 需要提升学习率。
# Train related params | 训练相关参数
$resolution = "512,512" # image resolution w,h. 图片分辨率,宽,高。支持非正方形,但必须是 64 倍数。
$batch_size = 1 # batch size
$max_train_epoches = 10 # max train epoches | 最大训练 epoch
$save_every_n_epochs = 2 # save every n epochs | 每 N 个 epoch 保存一次
$train_unet_only = 0 # train U-Net only | 仅训练 U-Net,开启这个会牺牲效果大幅减少显存使用。6G显存可以开启
$train_text_encoder_only = 0 # train Text Encoder only | 仅训练 文本编码器
$stop_text_encoder_training = 0 # stop text encoder training | 在第N步时停止训练文本编码器
$noise_offset = 0 # noise offset | 在训练中添加噪声偏移来改良生成非常暗或者非常亮的图像,如果启用,推荐参数为 0.1
$keep_tokens = 0 # keep heading N tokens when shuffling caption tokens | 在随机打乱 tokens 时,保留前 N 个不变。
$min_snr_gamma = 0 # minimum signal-to-noise ratio (SNR) value for gamma-ray | 伽马射线事件的最小信噪比(SNR)值 默认为 0
# Learning rate | 学习率
$lr = "1e-4"
$unet_lr = "1e-4"
$text_encoder_lr = "1e-5"
$lr_scheduler = "cosine_with_restarts" # "linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"
$lr_warmup_steps = 0 # warmup steps | 学习率预热步数,lr_scheduler 为 constant 或 adafactor 时该值需要设为0。
$lr_restart_cycles = 1 # cosine_with_restarts restart cycles | 余弦退火重启次数,仅在 lr_scheduler 为 cosine_with_restarts 时起效。
# Output settings | 输出设置
$output_name = "aki" # output model name | 模型保存名称
$save_model_as = "safetensors" # model save ext | 模型保存格式 ckpt, pt, safetensors
# Resume training state | 恢复训练设置
$save_state = 0 # save training state | 保存训练状态 名称类似于 <output_name>-??????-state ?????? 表示 epoch 数
$resume = "" # resume from state | 从某个状态文件夹中恢复训练 需配合上方参数同时使用 由于规范文件限制 epoch 数和全局步数不会保存 即使恢复时它们也从 1 开始 与 network_weights 的具体实现操作并不一致
# 其他设置
$min_bucket_reso = 256 # arb min resolution | arb 最小分辨率
$max_bucket_reso = 1024 # arb max resolution | arb 最大分辨率
$persistent_data_loader_workers = 0 # persistent dataloader workers | 容易爆内存,保留加载训练集的worker,减少每个 epoch 之间的停顿
$clip_skip = 2 # clip skip | 玄学 一般用 2
$multi_gpu = 0 # multi gpu | 多显卡训练 该参数仅限在显卡数 >= 2 使用
$lowram = 0 # lowram mode | 低内存模式 该模式下会将 U-net 文本编码器 VAE 转移到 GPU 显存中 启用该模式可能会对显存有一定影响
# 优化器设置
$optimizer_type = "AdamW8bit" # Optimizer type | 优化器类型 默认为 8bitadam,可选:AdamW AdamW8bit Lion SGDNesterov SGDNesterov8bit DAdaptation AdaFactor
# LyCORIS 训练设置
$algo = "lora" # LyCORIS network algo | LyCORIS 网络算法 可选 lora、loha、lokr、ia3、dylora。lora即为locon
$conv_dim = 4 # conv dim | 类似于 network_dim,推荐为 4
$conv_alpha = 4 # conv alpha | 类似于 network_alpha,可以采用与 conv_dim 一致或者更小的值
$dropout = "0" # dropout | dropout 概率, 0 为不使用 dropout, 越大则 dropout 越多,推荐 0~0.5, LoHa/LoKr/(IA)^3暂时不支持
(1.2.1.2)训练过程(例)
相比深度伪造(训练N天)来说,这个训练(N分钟)简直太轻松了。
当然功劳是LoRA模型,之前训练过嵌入式模型也很痛苦的。
在PowerShell中执行训练脚本train.ps1可以开始训练,并看到全过程:
prepare tokenizer
update token length: 225
Use DreamBooth method.
prepare images.
found directory train\xxxxx\10_xxxxx contains 40 image files
400 train images with repeating.
0 reg images.
no regularization images / 正則化画像が見つかりませんでした
[Dataset 0]
batch_size: 1
resolution: (576, 768)
enable_bucket: True
min_bucket_reso: 256
max_bucket_reso: 1024
bucket_reso_steps: 64
bucket_no_upscale: False
[Subset 0 of Dataset 0]
image_dir: "train\xxxxx\10_xxxxx"
image_count: 40
num_repeats: 10
shuffle_caption: True
keep_tokens: 0
caption_dropout_rate: 0.0
caption_dropout_every_n_epoches: 0
caption_tag_dropout_rate: 0.0
color_aug: False
flip_aug: False
face_crop_aug_range: None
random_crop: False
token_warmup_min: 1,
token_warmup_step: 0,
is_reg: False
class_tokens: xxxxx
caption_extension: .txt
[Dataset 0]
loading image sizes.
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 40/40 [00:00<00:00, 5000.66it/s]
make buckets
number of images (including repeats) / 各bucketの画像枚数(繰り返し回数を含む)
bucket 0: resolution (576, 768), count: 400
mean ar error (without repeats): 0.0
prepare accelerator
Using accelerator 0.15.0 or above.
loading model for process 0/1
load StableDiffusion checkpoint
loading u-net: <All keys matched successfully>
loading vae: <All keys matched successfully>
loading text encoder: <All keys matched successfully>
Replace CrossAttention.forward to use xformers
[Dataset 0]
caching latents.
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 40/40 [00:13<00:00, 2.99it/s]
import network module: networks.lora
create LoRA network. base dim (rank): 32, alpha: 32.0
create LoRA for Text Encoder: 72 modules.
create LoRA for U-Net: 192 modules.
enable LoRA for text encoder
enable LoRA for U-Net
prepare optimizer, data loader etc.
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
For effortless bug reporting copy-paste your error into this form: https://docs.google.com/forms/d/e/1FAIpQLScPB8emS3Thkp66nvqwmjTEgxp8Y9ufuWTzFyr9kJ5AoI47dQ/viewform?usp=sf_link
================================================================================
CUDA SETUP: Loading binary D:\xxxx\lora-scripts\venv\lib\site-packages\bitsandbytes\libbitsandbytes_cuda116.dll...
use 8-bit AdamW optimizer | {}
override steps. steps for 10 epochs is / 指定エポックまでのステップ数: 4000
running training / 学習開始
num train images * repeats / 学習画像の数×繰り返し回数: 400
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 400
num epochs / epoch数: 10
batch size per device / バッチサイズ: 1
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 4000
steps: 0%| | 0/4000 [00:00<?, ?it/s]epoch 1/10
steps: 10%|███████████████ | 400/4000 [05:33<50:00, 1.20it/s, loss=0.126]epoch 2/10
steps: 20%|██████████████████████████████▏ | 800/4000 [11:11<44:47, 1.19it/s, loss=0.105]saving checkpoint: ./output\xxxxx-000002.safetensors
epoch 3/10
steps: 30%|█████████████████████████████████████████████ | 1200/4000 [16:51<39:19, 1.19it/s, loss=0.123]epoch 4/10
steps: 40%|████████████████████████████████████████████████████████████ | 1600/4000 [22:20<33:30, 1.19it/s, loss=0.128]saving checkpoint: ./output\xxxxx-000004.safetensors
epoch 5/10
steps: 50%|███████████████████████████████████████████████████████████████████████████ | 2000/4000 [27:48<27:48, 1.20it/s, loss=0.117]epoch 6/10
steps: 60%|██████████████████████████████████████████████████████████████████████████████████████████▌ | 2400/4000 [33:17<22:11, 1.20it/s, loss=0.11]saving checkpoint: ./output\xxxxx-000006.safetensors
epoch 7/10
steps: 70%|█████████████████████████████████████████████████████████████████████████████████████████████████████████ | 2800/4000 [38:52<16:39, 1.20it/s, loss=0.112]epoch 8/10
steps: 80%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ | 3200/4000 [44:30<11:07, 1.20it/s, loss=0.124]saving checkpoint: ./output\xxxxx-000008.safetensors
epoch 9/10
steps: 90%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ | 3600/4000 [50:08<05:34, 1.20it/s, loss=0.117]epoch 10/10
steps: 92%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▋ | 3673/4000 [51:48<04:36, 1.18it/s, loss=0.112]
(1.2.2)图形化配置训练
前面虽然说过图形界面用处不大,但是作者完善了参数配置的图形界面。
比起自己修改配置文件,他的图形界面有2个很大的好处:
- 可以配置多组训练参数,随时载入。
- 通过TensorBoard查看训练日志。
(1.2.2.1)启动图形界面
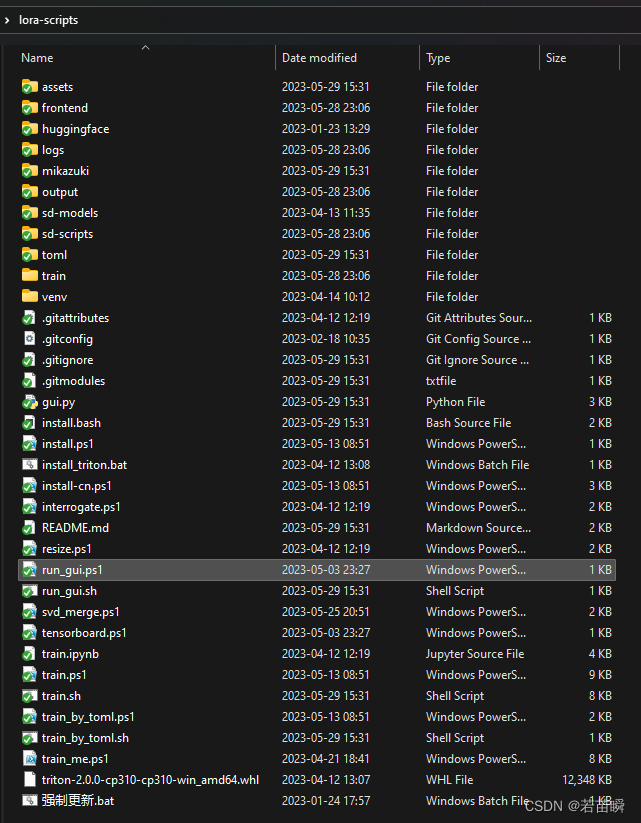
我们看看lora-scripts项目的结构,如下图。
直接脚本训练我们用的是train.ps1,
而启动图形界面就是选中的run_gui.ps1:
主要配置界面没啥好说的,配置的还是那些参数。
建议看下作者自己的发布。
(1.2.2.2)训练日志查看
这个才是重点。
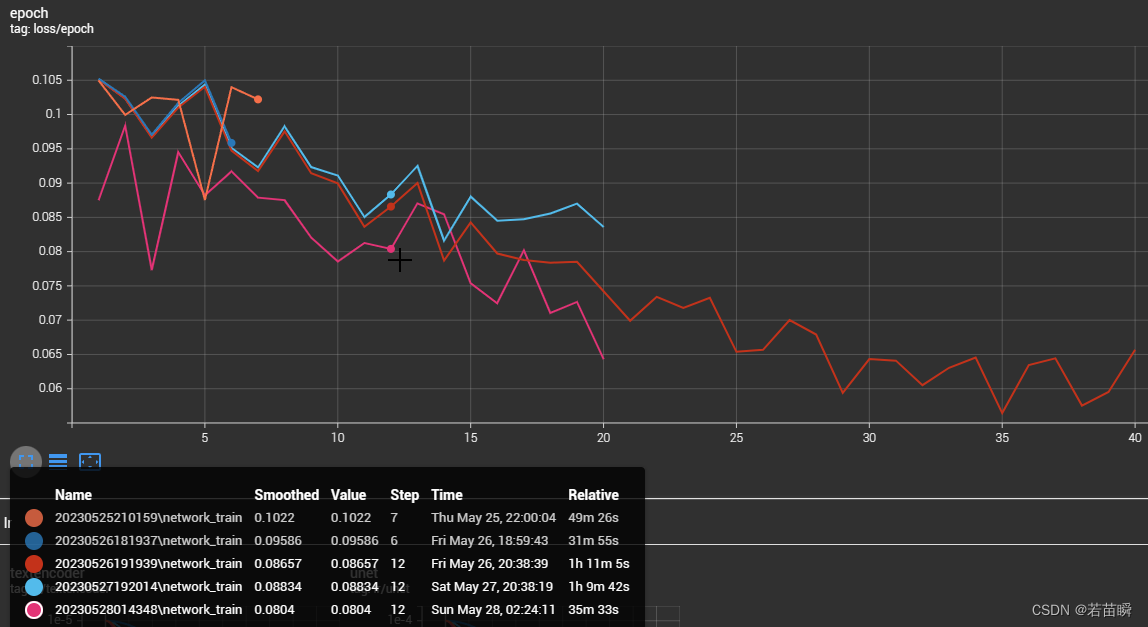
我们可以对比多次训练的结果,训练阶段的loss情况对比。
没用图形界面启动的训练,其实也是有日志记录的。
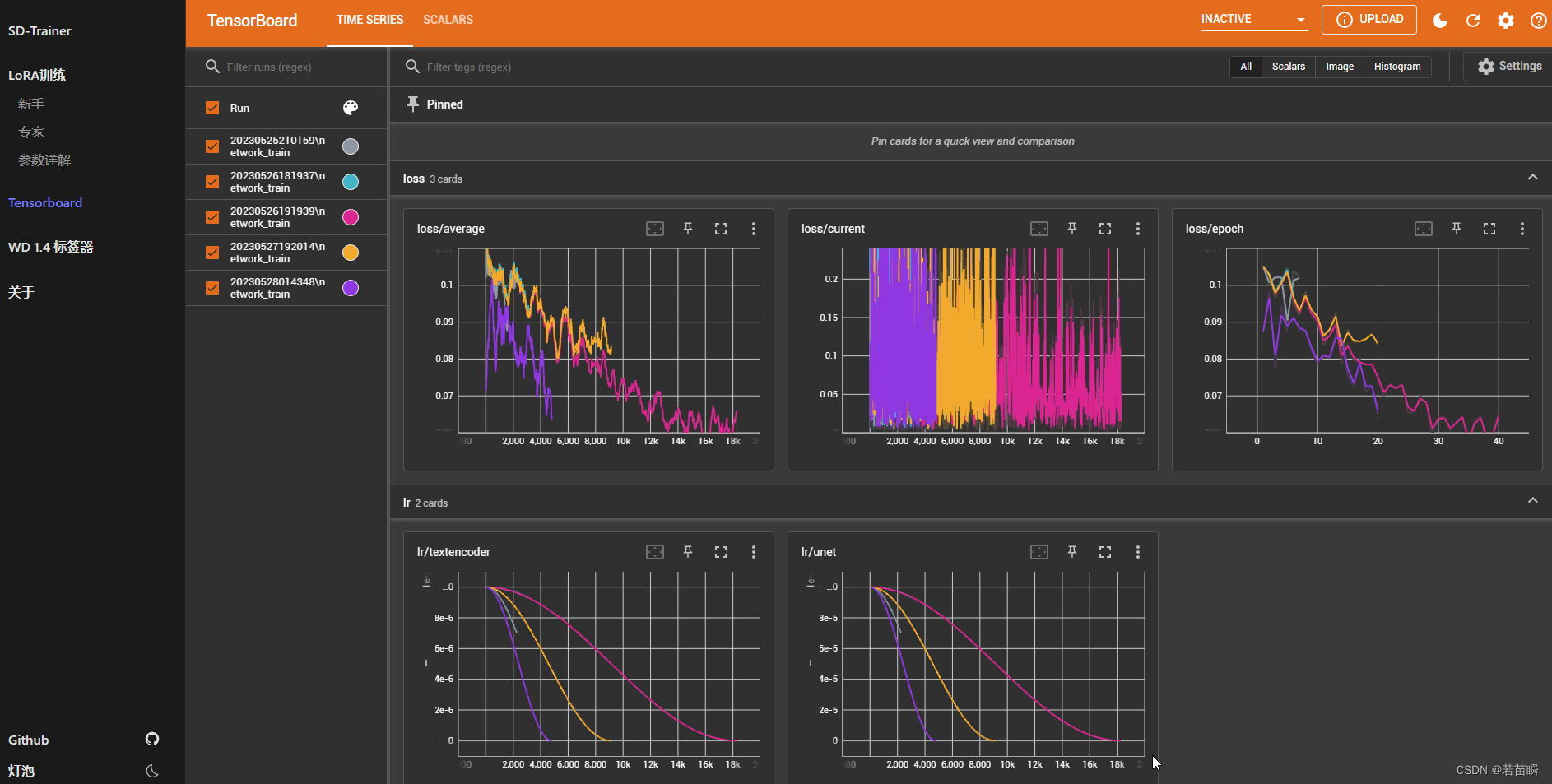
我们可以放大图表,对比各次训练的不同。
看看每个epoch的loss值,有没有训练很久不降反升的。
💡:这就是为啥图片目录不要直接100_xxyyzz的原因。
100太高了,导致只有一个epoch无法对比哪个更好。
如果100再乘以多个epoch,那么都不用想,肯定是过拟合了。
(1.2.3)训练结果
只看loss是不行的,需要避免欠拟合和过拟合,但我们通过日志本身又看不出来(只能看到loss)。
最好用插件:可选附加网络(LoRA插件) 来对比多个epoch生成的模型情况。
不像当然就是欠拟合,如果只能画大头照就是过拟合。
对比的目的是找出哪个阶段的模型能同时保持下面两个特性:
- 和目标长得像。
- 能有效的使用提示词改变图像(特别是大头照,半身,全身一类)。
(二)各epoch模型对比
如果你的参数设置比较正常,每1、2次epoch保存了模型。
那么你的output目录里面就会有一堆模型(除了最后一个,其它都有长长的数字后缀)。
这时就可以配合可选附加网络(LoRA插件)来进行多个epoch/权重的模型对比了。
(2.1)使用:可选附加网络插件
(2.1.1)安装
参考:🔗可选附加网络插件 (国内源)。
可以从WEB UI中直接安装。
安装后会在文生图下面出现单独的选项(上面还会出现一个标签页,暂时不管它)。
噢,对了,使用前你得把刚才那一堆阶段性和最终的LoRA模型,放入插件的模型目录,才能对比。
模型放这里:你的WEBUI目录\extensions\sd-webui-additional-networks\models\lora
(2.1.2)配置
配置界面如下,其实主要内容不在这里配置:)
这里只简单的在类型1里面选择一个模型,其它不用动。
如果看不到模型,请点下面的刷新,刷新都没有就是你没放要对比的模型到插件模型目录了。。。
(2.1.3)配合脚本:X/Y/Z图表
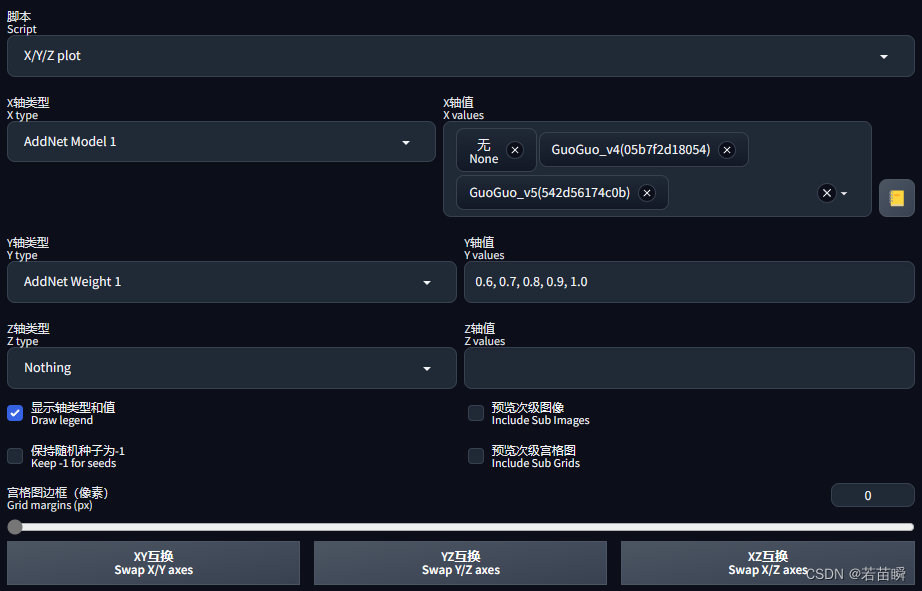
在最下面脚本中,选X/Y/Z plot。
我只想对比多个模型,以及不同权重,所以只有X/Y两个轴。
上面没配错的话,X轴选了模型1,只需按一下那个黄色书本的按钮,x轴对比的模型就列出来了。
下面截图大概意思:
- X轴是不同的LoRA模型(包括不用LoRA模型)—— 来自【可选附件网络模型1】(上面我们选的那个)。
- Y轴是不同的模型权重值 —— 权重来自【可选附件网络权重1】。
(2.2)生成/结果
⚠️和平时一样的输入提示词,但是提示词里面别再带Lora模型名字了。
其它参数也一样,正常录入就可以了。然后点【生成按钮】
……会等很久。
因为它需要生成的不再是一张图了,而是图片二维矩阵啊……
下面的例子我为了减少等待时间,没输入太多权重,也没对比太多模型。
过于像真人的输出打马赛克了见谅,而且这只是个X/Y图的例子,不太贴合主题。

(2.3)自己用眼睛对比
综合权重,选出比较像,而且能贴合提示词的那个模型。
把这个模型改名,当作正式版本用,别忘了得放入WEBUI的LoRA模型目录。
搞定😄
(2.4)注意事项
-
不仅可以对比多次epoch的结果,也可以对比多次生成的不同模型(比如筛选照片不同)
-
对比图不会自动保存,如果想细看,请自己存。
-
提示词里面别再带Lora模型名字。
-
可以多对比几次,用不同的关键词,半身,全身,不同背景等等(记住我们的目的,找到既像又有适应性)。
-
不要只看权重为1.0的。如果0.8,0.7像且没有过拟合也行啊。
-
输出模型太多时,先找loss低,总训练次数100次左右的,比如
000008,000010,000012,000014……等进行对比。假设找到最好的模型是000012,那么把其它移除,加入000011,000013和000012一起再对比。 -
训练时底模(基础模型)最好选
ChilloutmixNi.safetensors这种,对比时也优先用训练时的基础模型。
呃,如果你是歪果仁且来自西方国家,那么底模选v1-5 pruned.safetensors吧。
总之优先用”没有混合太多次“的基础模型,这样适应性强一些。
⭐️:Happy training…