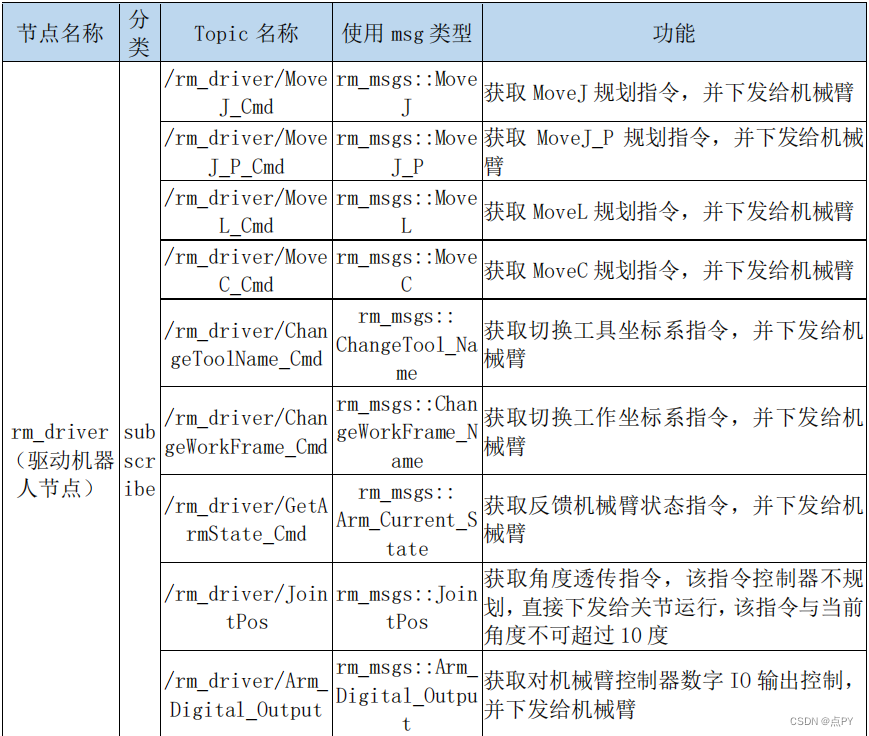
1、背景
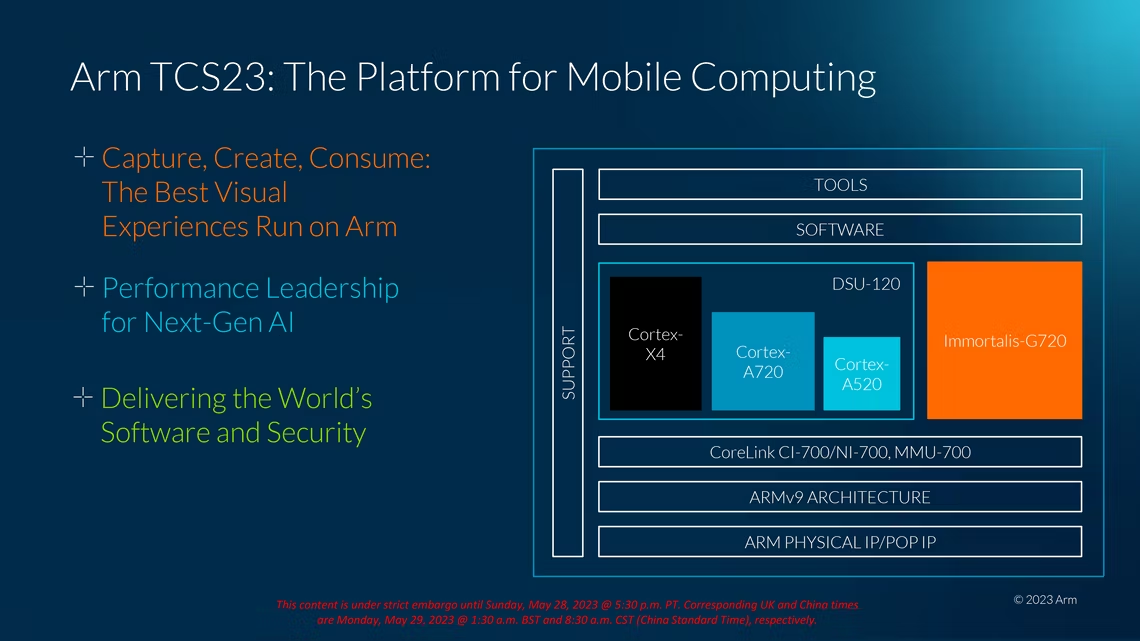
Arm 是一家设计智能手机的CPU内核的公司,并且每年它都会进行新的迭代,这些迭代随后将集成进芯片SOC,例如当年的旗舰 Snapdragon 、 MediaTek Dimensity。2023年,发布了新的旗舰级内核: Cortex-X4 超大核、Cortex-A720 性能大核和 Cortex-A520 功耗小核。这些core构成了公司新的 Arm v9.2 兼容设计和公司的 2023 年整体计算解决方案或 TCS23 的基础。除此之外,我们还看到了一个新的 DynamIQ 共享单元和一个更新的 Immortalis-G720 GPU。 这三个新内核都是去年的微架构继承者,主要侧重于引入 IPC 和提高效率。

2、仅支持64位 – 64-bit only: “Mission accomplished”

今年 Arm 的整体计算解决方案的最大变化之一是已经完全过渡到 64 位,即该core仅支持aarch64,不再支持aarch32了。事实上在2022年发布的几个core,也已经是仅支持aarch64了,但今年 Arm 的内核仅支持 AArch64。也就意味着在你的最新架构的Android机器上,跑不了32 位的应用程序了。注意,谷歌本身已经要求自 2019 年以来更新的所有应用程序都以 64 位二进制文件的形式上传。
正如 Arm 所说,64 位过渡被认为是“任务完成”。原因是中国应用市场阻碍了整个行业的转型,但中国应用商店中的绝大多数应用现在也都兼容 64 位。
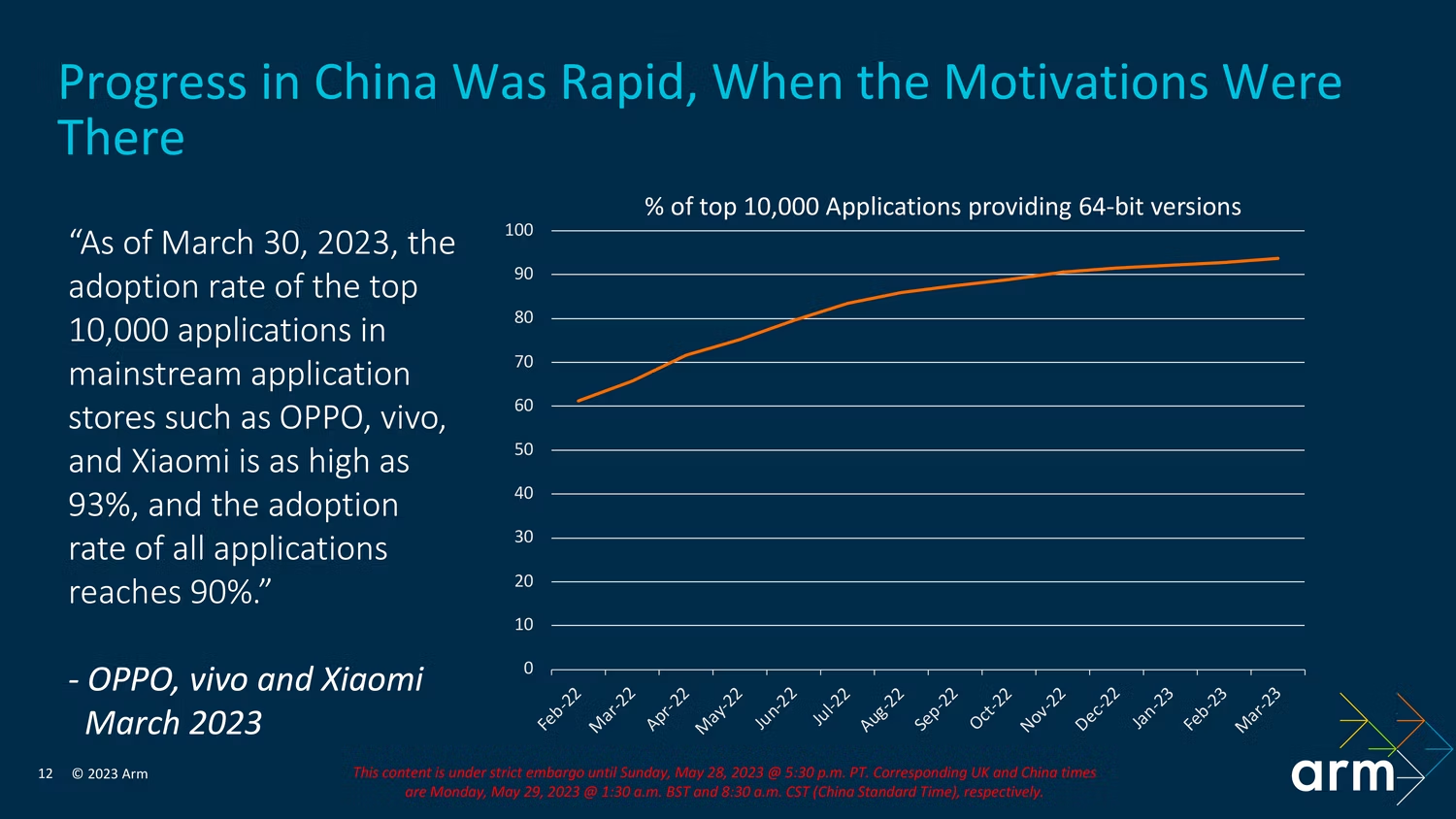
延迟的原因是缺乏同质化的应用生态系统,这意味着不同的应用商店需要不同标准的开发者。然而,由于 Arm 已与中国的多家应用商店合作,并且反复警告可能会发生转变,因此这些应用商店一直在鼓励开发人员也进行转换。

现在似乎是完全实现这种转变的时候了,无论如何,我们还需要几个月的时间才能在新的芯片SOC中应用这些arm core。
3、Arm Cortex-X4:更高的性能和更高的效率
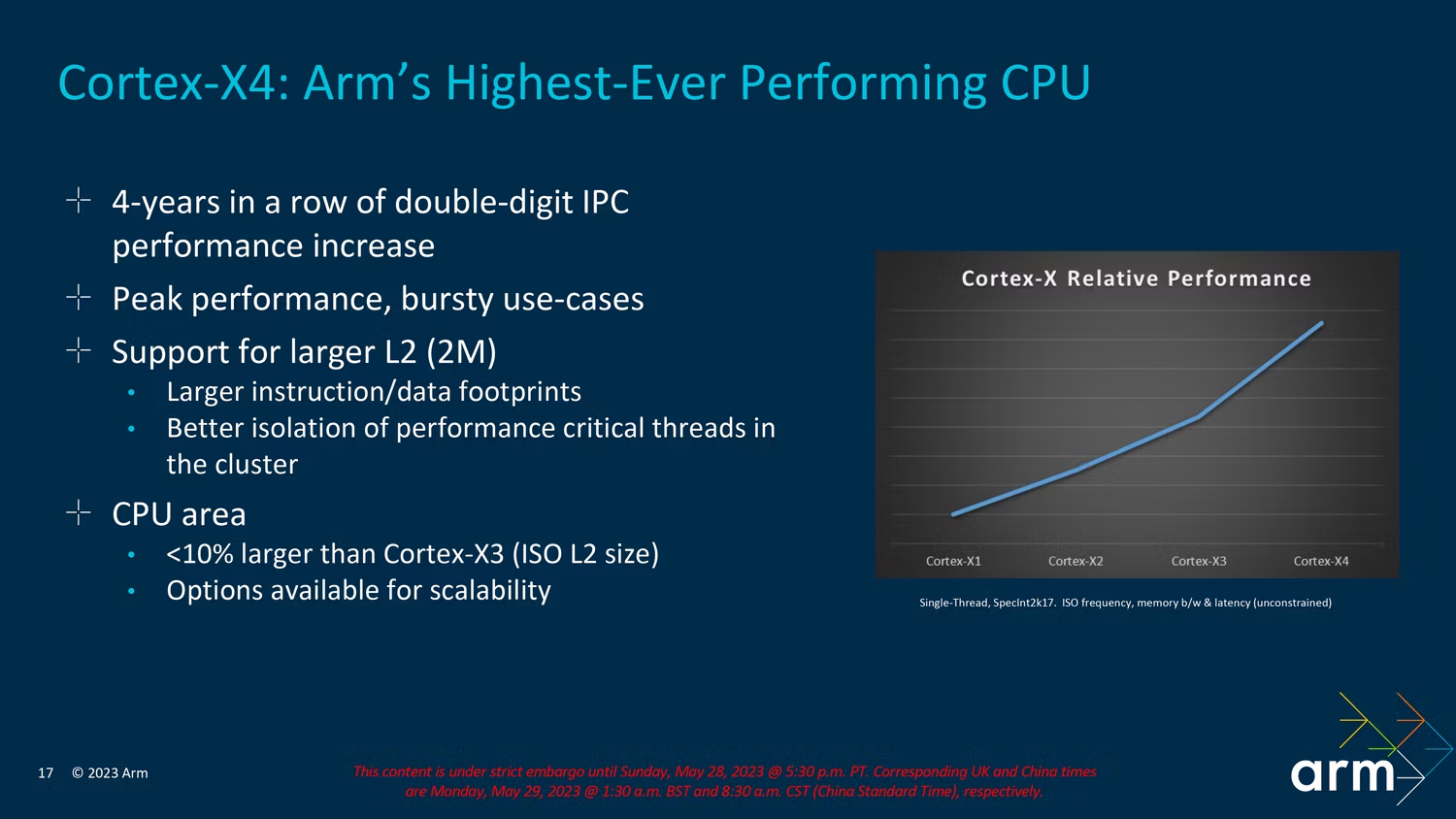
几年前,Arm 的 X 系列核心从 A 系列中分离出来,理念是它是一个超大核。通常情况下,芯片组制造商最多只会包括其中的一两个,因为他们非常耗电,尽管他们也有能力。
从上图可以看出,Cortex-X4 是迄今为止最强大的 Arm core,但这些计算能力是以功耗为代价的。Cortex-X4 与去年的 X3 类似,正如 Arm 所说,它甚至可以以与去年内核相同的频率运行,并且功耗降低多达 40%。它的物理尺寸大不到 10%,是有史以来最高效的 Cortex-X 内核。
至于这些 IPC 改进来自何处,X4 有许多前端和后端改进。在这些前端改进中,大量工作被投入到重写和改进分支预测上,因为不正确的分支预测在性能方面代价高昂。Arm 还承诺,2MB 的 L2 缓存大小会产生更高的性能,与其说是在基准测试中,不如说是在实际使用中。
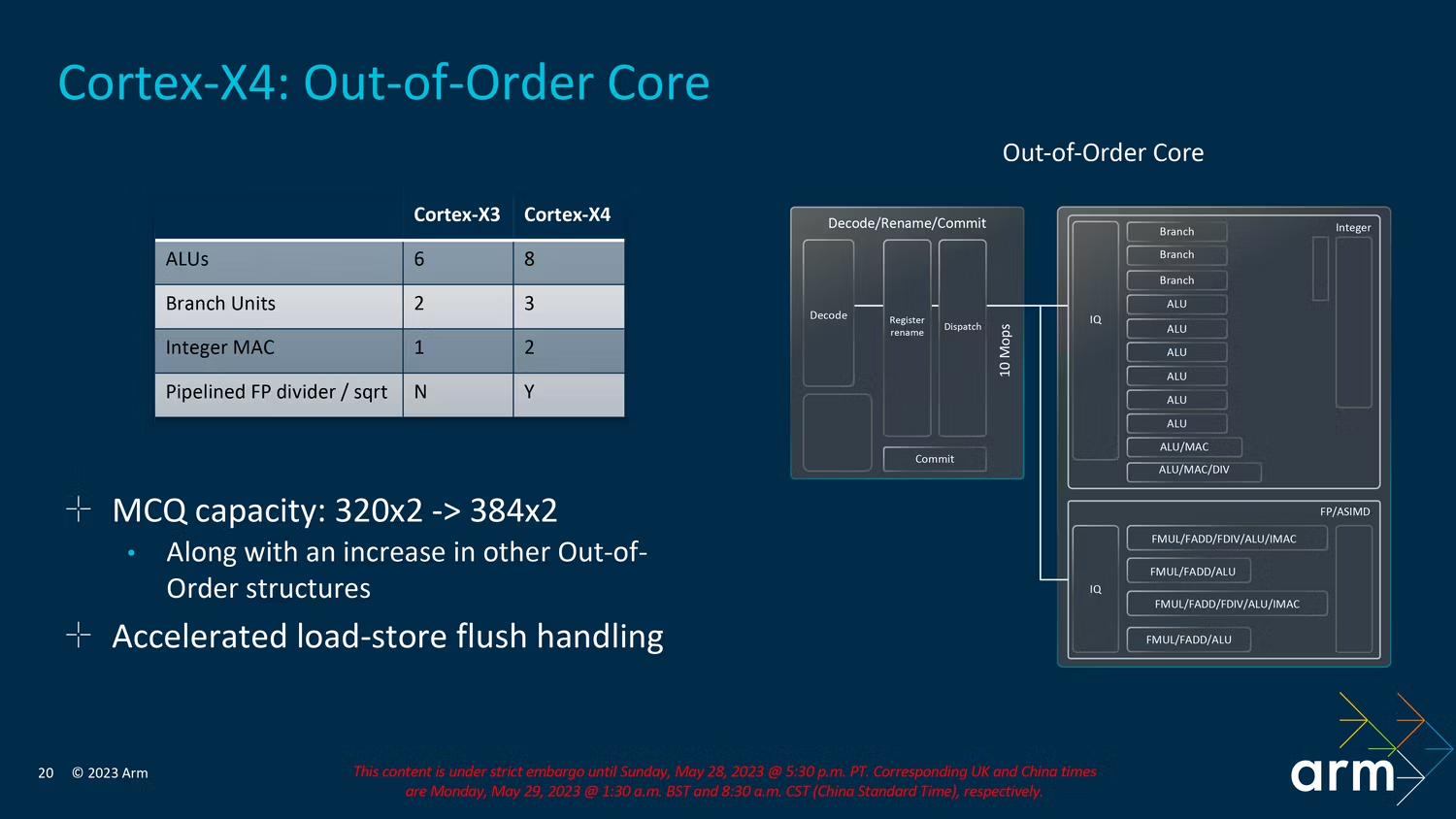
新的 Cortex-X4 内核将算术逻辑单元 (ALU) 的数量从 6 个增加到 8 个,添加了一个额外的分支单元(总共 3 个),添加了一个额外的乘法累加器单元,以及流水线浮点和平方根运算.
至于后端,也有许多改进。加载-存储地址生成已从每周期 3 条指令增加到 4 条指令,因为加载-存储管道被采用并拆分。L1 中还有一个双倍的翻译后备缓冲区。
所有这些结合在一起,为 Arm 的 Cortex-X4 带来了一些令人印象深刻的性能提升。总而言之,您可以预期 Cortex-X4 的性能平均提高 15%。在 Arm 共享的功率和性能曲线中,X4 在性能和功耗方面都领先于 X3。换句话说,15% 的性能提升伴随着相当大的功耗。不过,也值得一提的是,这并不是一个同类比较。Cortex-X3 去年配备了 1MB 的二级缓存,这意味着如果制造商今年坚持使用相同的二级缓存大小,则不一定会有 15% 的性能提升。
不过有一件事是肯定的,那就是如果您以最大速度运行 X4,它很可能是一个主要的耗电大户。今年我们可能会看到一些原始设备制造商继续做他们去年所做的事情,并开箱即用地限制今年的许多芯片SOC。例如,OnePlus 和 Oppo 都这样做,并且在以与 X3 相同的性能点运行时获得这些能效提升,这些公司继续这样做可能会受益。我们可能不会看到全面的 15% 的性能提升,但我们可能会看到明年的芯片SOC的效率进一步提高。
4、Arm Cortex-A720:平衡性能和功耗

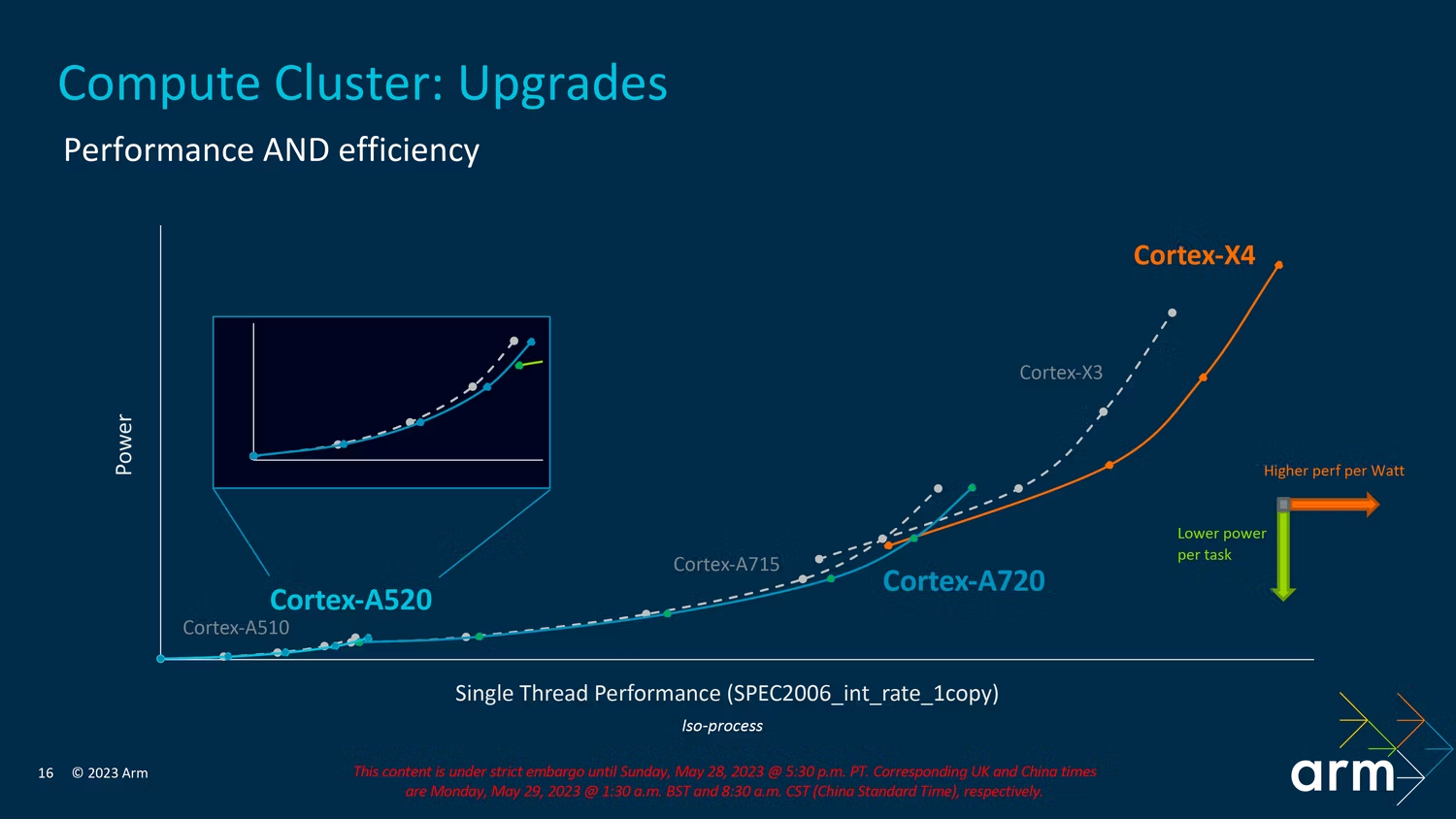
虽然 Arm 的 X 系列Core通常有点疯狂,但 A 系列内核通常旨在平衡功耗与性能。借助 Cortex-A720,Arm 承诺内核效率提高 20%,在与去年的 A715 相同的功率下提高性能。
至于今年A720的改进从何而来,大部分都在前端。从分支错误预测引擎中删除了一个周期,从而缩短了流水线,据说这一单周期下降导致基准测试增加了 1%。基准测试通常会导致最少的分支错误预测,这意味着这可能会以更显着(但在很大程度上无法衡量)的量改善整体现实世界的性能。

在乱序内核中,我们看到了一些结构上的改进,这些改进有助于在不影响内核占用的面积或效率的情况下提高性能。对于初学者,就像在 X4 中一样,浮点除法和平方根运算现在是流水线化的。还有从浮点数、NEON 和 SVE2 数字到整数的更快传输以及其他整体改进以加快处理速度。
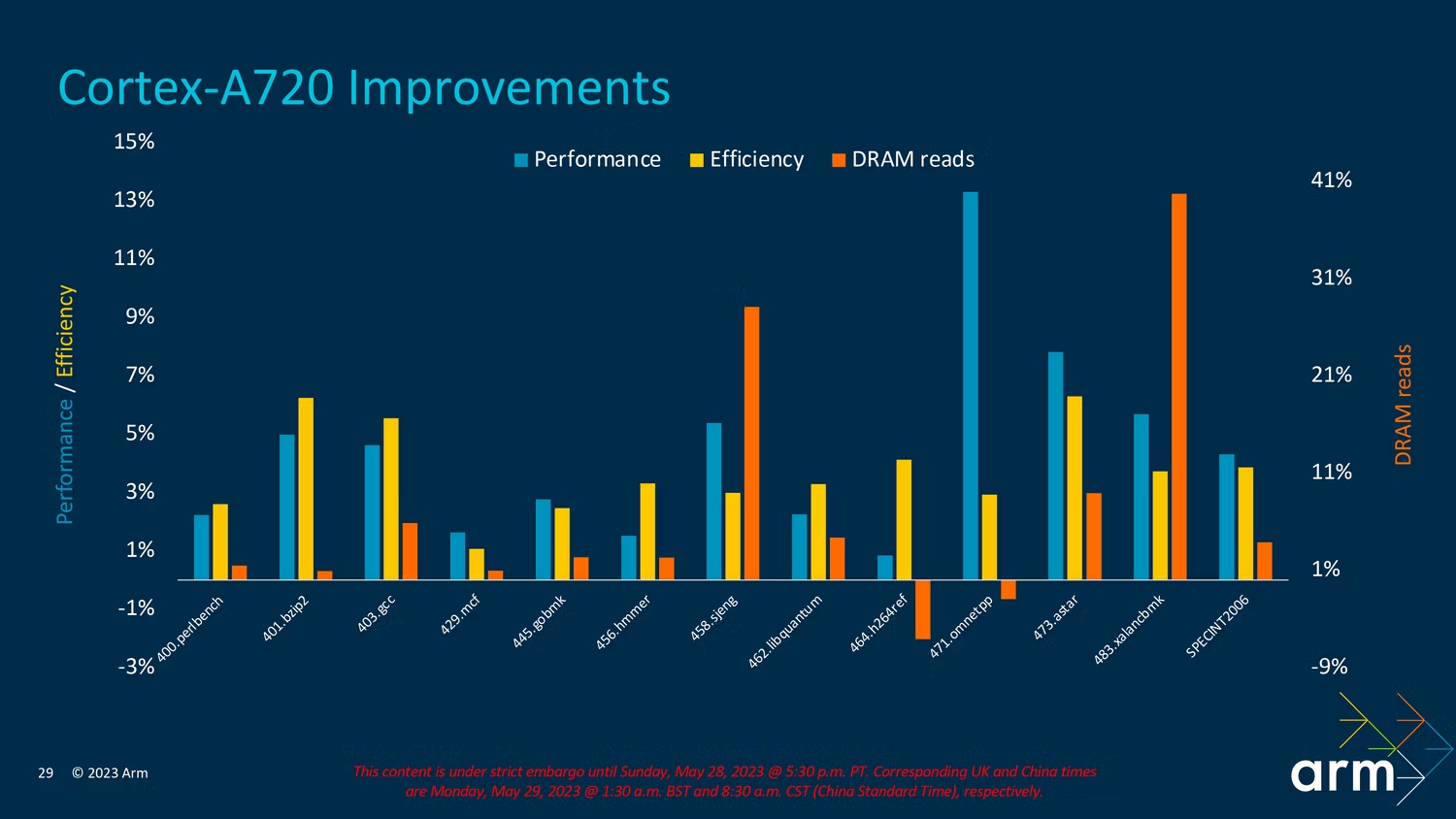
Arm 分享了上图来说明 A720 与去年的 A715 在性能和效率方面的比较,其中在 SPECint_base2006 中使用了 ISO 过程和 ISO 频率。缓存大小也保持不变,因此这是一个同类比较。
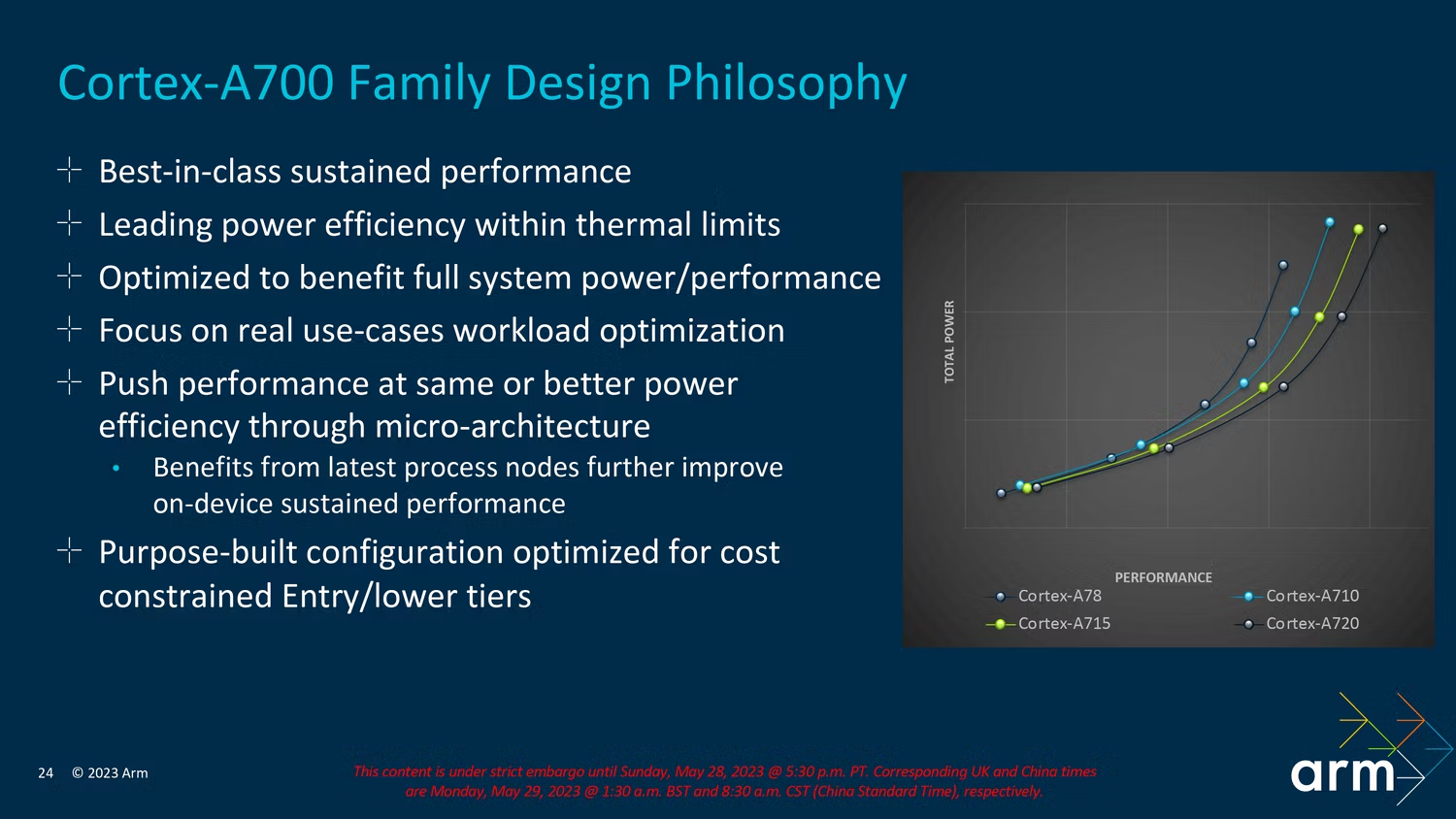
在功耗方面,A720 与去年的型号基本保持一致,但在相同功率水平下它的性能略高一些。对于 A720,就像 X4 一样,Arm 似乎更专注于强调它如何从去年的功率限制中获得更好的性能,而不是不断增加这些内核的能力。
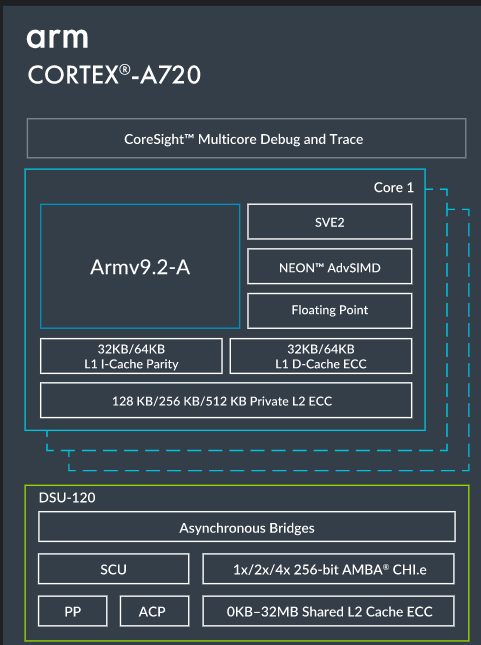
5、Arm Cortex A520:相同功耗点效率翻倍

当然,说到 Arm 的内核,并不仅仅关乎性能。X 系列将一切都投入原始计算能力,A7xx 平衡计算需求和功耗,而 A5xx 系列则完全专注于高效处理。它是单位面积功耗最低的 Arm v9.2 内核,并建立在我们看到的与 A510 相同的合并内核架构之上。
这种合并核心架构意味着一些资源可以在两个核心之间共享,其中两个核心可以组合成一个“复合体”。L2 高速缓存、L2 翻译后备缓冲区和向量数据路径在该复合体中共享。需要明确的是,这并不意味着它必须捆绑成两个内核,可以组装一个单核复合体以获得最佳性能。事实上,他们向我们展示的 Arm 的 TCS2023 核心布局之一涉及单个 X4 核心、五个 A720 核心和三个 A520 核心,这意味着至少有一个 A520 核心是隔离的。
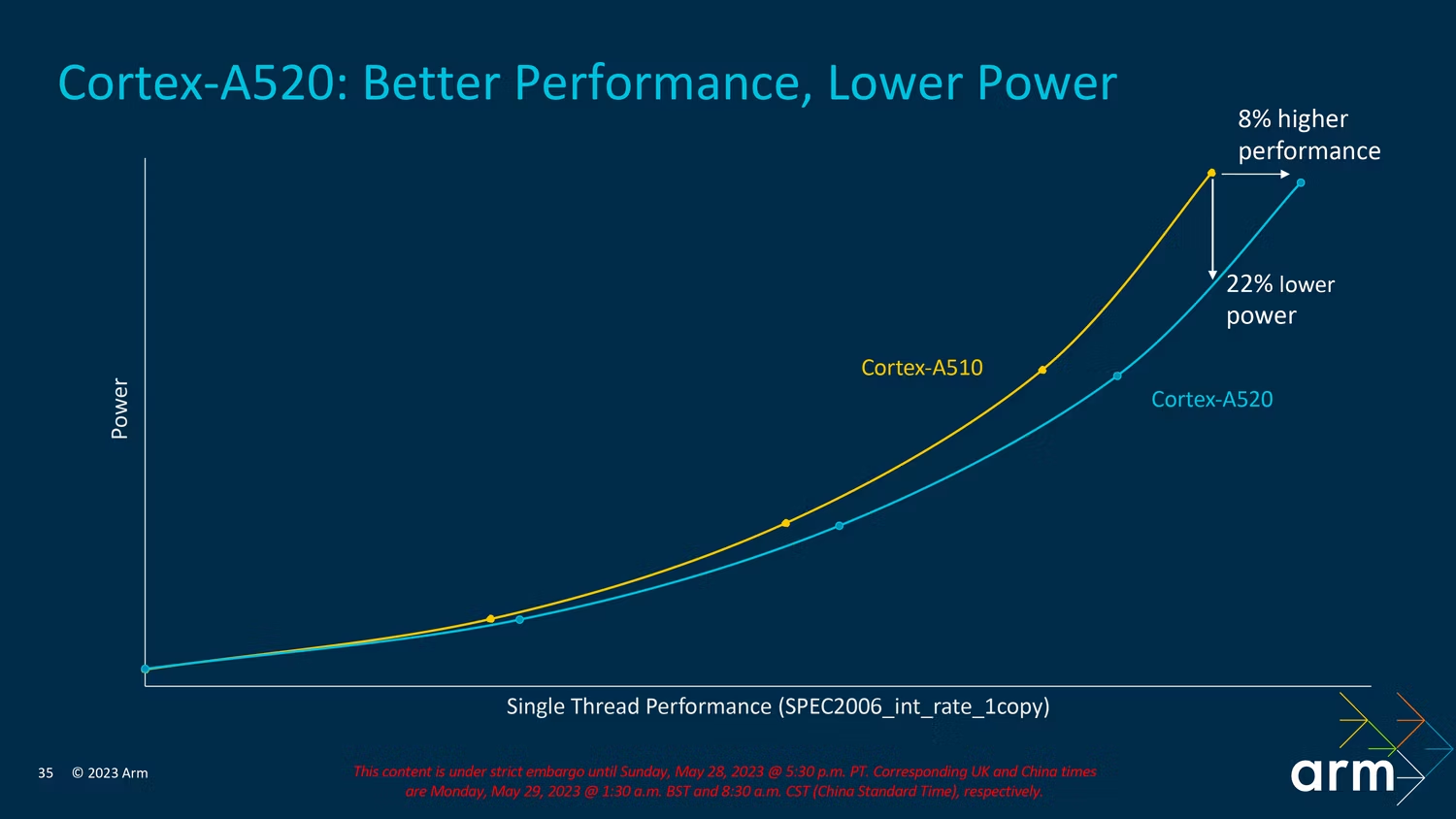
A520 是一种效率优先的设计,与其他内核一样,Arm 主要侧重于在与上一代相同的功率点上提高效率。这包括改进分支预测,同时删除或缩减某些性能特征。结果,通过更高的效率恢复了这种性能。同样有趣的是,Arm 移除了 A510 中的第三个 ALU,从而节省了发布逻辑和转发结果的功耗。
在现实世界的结果中,A520 似乎没有像 A720 和 X4 那样与其前辈相比有很大的飞跃。它在较低功率间隔下的许多功能与上图中的 A510 重叠,并且只有在性能的上层我们才能看到效率提升。两个内核之间在性能和功率方面的差异是有希望的,但尚不清楚在比较 A520 和 A510 时我们是否会看到任何实际的实际优势。毕竟,在现实世界中很难真正正确地衡量两者之间的性能和效率差异。

6、DSU-120:多达 14 个计算优势核心
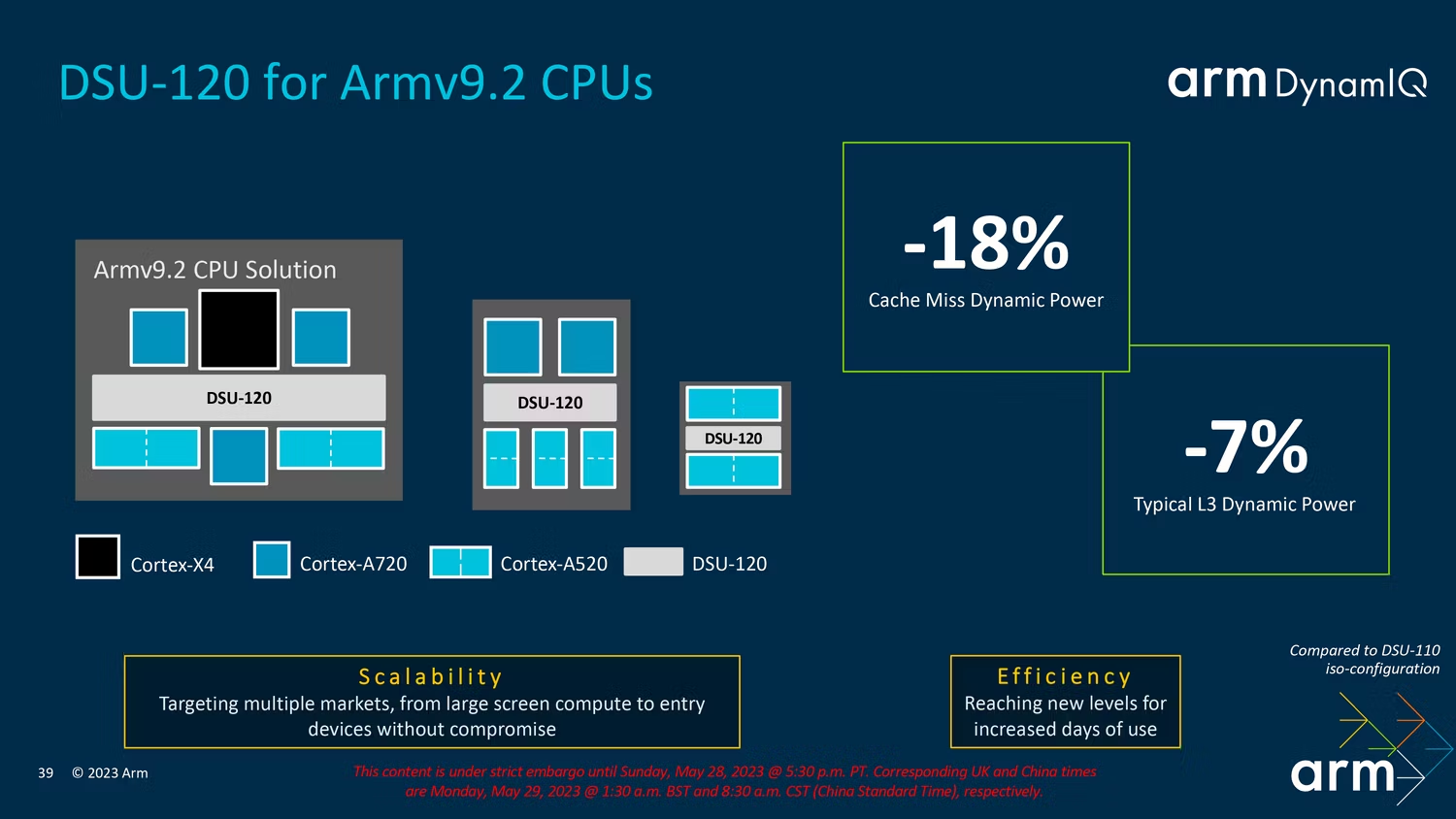
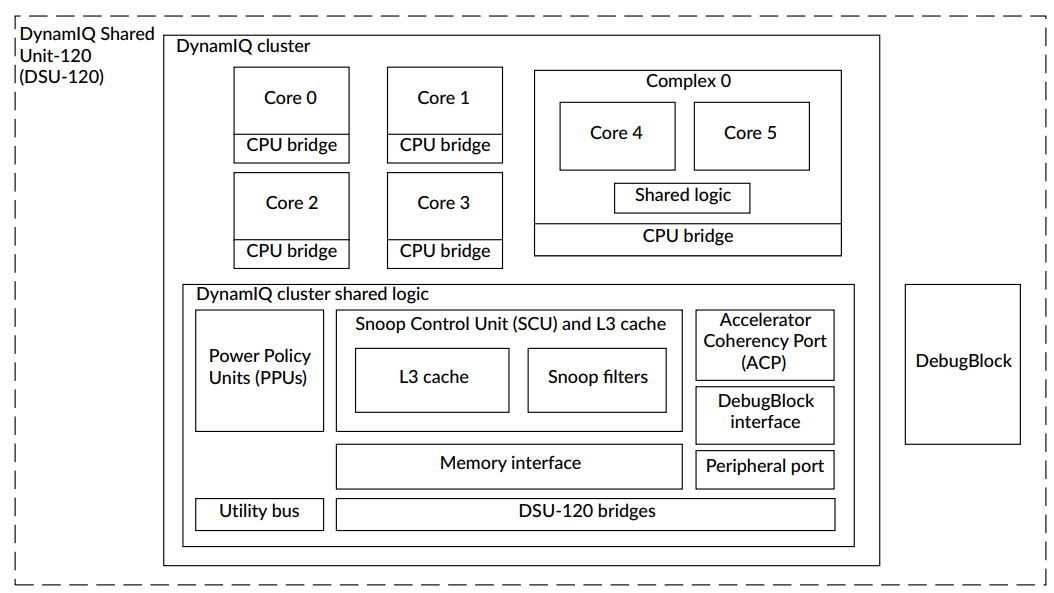
DynamIQ 共享单元或 DSU 是一个集成了一个或多个内核的 L3 内存系统、控制逻辑和外部接口,以形成一个多核集群。它本质上是 Arm 的结构,允许所有这些内核相互通信并共享资源,因此,对于任何希望使用 Arm 的内核设计构建芯片的芯片组制造商来说,这是一个相当重要的难题。
在 DSU-110 的基础上,Arm 对 DSU-120 进行了多项改进,这将有利于包含它的整个芯片。对于初学者来说,现在每个集群最多有 14 个核心(从 12 个增加),并支持高达 32MB 的 L3 缓存。它还大大提高了一些关键领域的效率,包括在缓存未命中的情况下,同时还减少了功耗。
在某种程度上,Arm 的 DSU 是 TCS23 的骨干,因为它构成了这些核心如何相互交互和共享数据的基础。这里的任何改进都会使整个集群受益,但似乎大多数变化都与功耗和效率有关。
7、效率是新目标

这个行业似乎已经发生了一段时间的变化,但我从这些核心中得到的主要第一印象是效率现在是游戏的名称。虽然我们被告知 X4 内核的速度有多快以及它如何成为公司有史以来最快的内核,但他们很快注意到以去年的峰值性能运行它的效率提高了。
总体而言,每一次性能提升都取决于该组件的效率有多高,而 DSU 的所有变化或多或少都体现在效率和功耗方面。性能很重要,但确实感觉整个行业都在努力提高当前的计算水平,而不是逐年大幅提高性能。
我们预计这些内核将构成联发科天玑 9400 和高通骁龙 8 Gen 3 的基础,但具体形式还有待观察。如前所述,Arm在自己的内部测试中谈到使用1+5+3的核心布局,但这并不意味着像联发科和高通这样的合作伙伴也会这样做。