目录
- Text
- Fonts
- Glyphs
- Font Types
- The Font Dictionary
- Encodings
- Text State
- Font and Size
- Rendering Mode
- Drawing Text
- Positioning Text
- What’s Next
Text
在本章中,您将学习如何在页面上绘制文本。 绘图文本是 PDF 图形中最复杂的部分,但它也是帮助 PDF 击败竞争对手成为当今国际标准的原因。 当其他原始播放器将文本转换为光栅图像或矢量路径(以保持视觉完整性)时,PDF 的发明者知道用户需要可以搜索和复制的文本,而不仅仅是在屏幕上看起来漂亮。凭借 Adobe 工程师对字体的丰富经验和理解,他们能够将实际文本与视觉呈现相结合。
虽然PDF中的文本支持允许呈现来自表示任何语言的任何字体的任何字形,但其机制(您将很快看到)都是在Unicode之前创建的。这意味着使用其他文件格式的开发人员认为理所当然的许多事情,例如只需输入Unicode代码点并让渲染器完成所有艰苦的工作,在PDF中都必须手动完成。
既然你已经得到了合理的警告,那就开始吧!
Fonts
在前面的章节中,您学习了如何在页面上绘制矢量图形(或路径)以及光栅图形(图像)。这些类型的绘图操作相当简单,因为它们通常不需要额外的信息——只需要指令和(在光栅图像的情况下)图像数据。然而,文本需要更多的片段。其中最重要的是字体。
Glyphs
字体,有时也被称为字体程序,是一个被称为字形的独特绘图指令的集合。 一般来说,每个字形与你在前几章中自己绘制的路径或光栅没有什么不同。 然而,字体还包含了一堆关于各种字形的元数据,包括一种叫做编码的东西,它提供了一个从已知字符集(如ASCII、Unicode或Shift-JIS)到字形的映射。 并非每一种字体都有适用于每一种编码中的每个值的字形。
图4-1是一个不同编码的三个常见值及其在不同字体中的字形的例子。
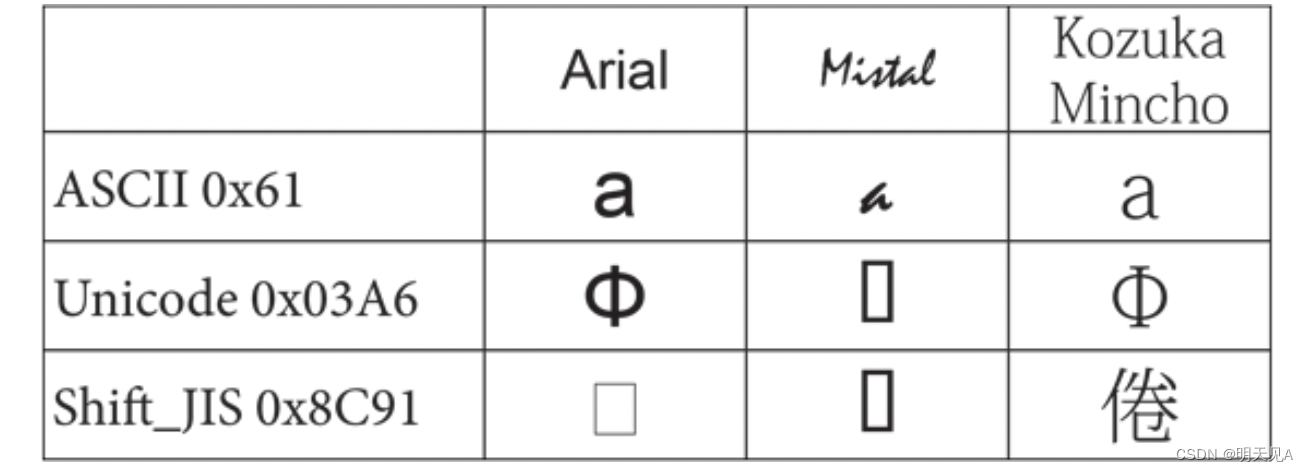
看起来像矩形的字形通常被称为 "not- def "字形。Notdef(未定义的缩写)是一种存在于所有字体中的特殊字形,用于在所要求的字形不存在的情况下进行填充的特定目的。如果你在你的PDF中看到这些字,你就知道你做错了什么 (虽然在这种情况下,它是故意的)。
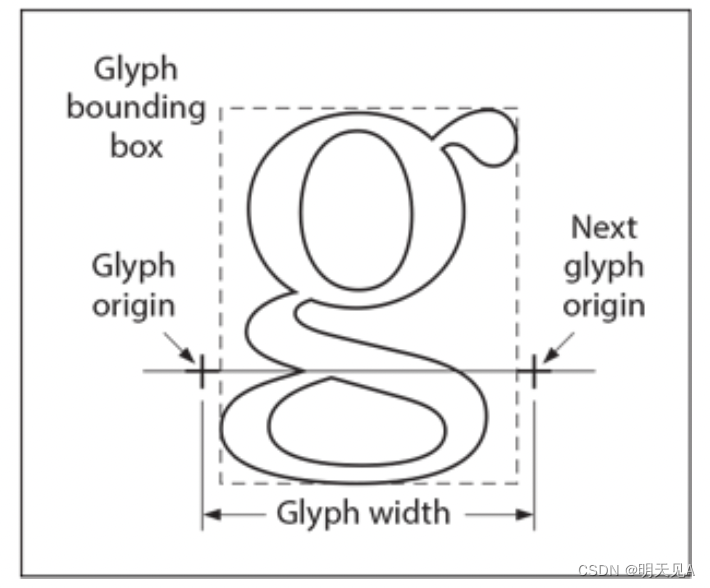
虽然一个字形主要与它的形状和外观有关,但它也有一组与之相关的值,称为字形度量。这些指标,有些是在字体本身中明确定义的,有些则是从一系列数值中计算出来的,这些指标使软件能够做一些诸如排版文字的事情。例如,要画 Hello,你需要知道 H 后面的 e 应该放在哪里。图4-2告诉你要把 e 放在 "下一个字形原点处。
Font Types
当最初的 Lisa 和 Macintosh 等图形界面首次出现时,它们附带的字体被称为“位图字体”,因为每个字形都被描述为位图或光栅图像。 虽然这对屏幕非常有用,但对于打印来说不够灵活,因此诞生了轮廓(基于路径)字体格式。
PDF 支持三种最常见的大纲格式:
Type 1
这是 Adobe 与打印机的 Postscript 语言一起创建的原始大纲格式。 使用简化版的 Postscript 描述字形轮廓。
TrueType
由 Apple 和 Microsoft 为其操作系统创建,这是最著名的字体格式。 使用此字体格式独有的特殊语言来描述字形轮廓。
OpenType
虽然 Type 1 和 TrueType 字体各有优势,但业界对“字体大战”感到厌倦,因此 OpenType 诞生了。 OpenType 结合了其他格式的优点,可选择将字形轮廓描述为 Type 1 或 TrueType。
对于这些字体类型,实际的字体程序在单独的字体文件中定义,该文件可以嵌入到 PDF 流对象中或从外部源获取。
PDF 还有两种 PDF 特有的字体,其中字形数据必须在 PDF 中定义:
Type 3
Type 3 字体最初是作为嵌入位图字体的一种方式提供的,实际上是一个 PDF 字典,其中每个字形都由标准内容流定义。 这不仅允许基于光栅的字形,而且允许使用任何/所有 PDF 图形运算符来定义字形。 尽管它们可能非常强大,但目前大多数 PDF 生成系统都没有使用它们。
Type 0
也称为复合字体或 CIDFont,Type 0 字体是通过从一种或多种其他字体中获取字形描述并创建混合或复合字体来创建的。 当使用中文、日文或韩文 (CJK) 中没有英文/拉丁字符的字体时,这最初是必需的,并且需要一种同时包含这两种字符的字体。 虽然不用于实际合并来自多种字体的字形,但它仍然是用于 Unicode 字体的方法,尤其是在处理双字节数据时。
The Font Dictionary
在第 1 章中,您看到了我们的第一个 PDF,它在页面上绘制了“Hello World”。 示例 4-1 显示了一些相关的部分,我们现在将更详细地研究这些部分。
Example 4-1. Parts of “Hello World.pdf”
1 0 obj
<<
/Type /Page
/Parent 5 0 R
/MediaBox [ 0 0 612 792 ]
/Resources 3 0 R
/Contents 2 0 R
>>
endobj
3 0 obj
<<
/Font <</F1 4 0 R >>
>>
endobj
4 0 obj
<<
/Type /Font
/Subtype /Type1
/Name /F1
/BaseFont/Helvetica
>>
endobj
在此示例中,您知道对象 #1 是页面,它只有最低限度的必要条件:MediaBox(用于页面大小)、Contents(用于绘图说明)和 Resources(用于 内容)。 有一个资源类型 Font,它有一个条目 F1,它是对象 #4 中的字体字典。
字体字典包含指定字体类型(即 Type 1 或 TrueType)的信息、其 PostScript 名称、编码以及当字体程序未嵌入 PDF 文件时可用于提供替代的信息。
ISO 32000-1:2008, 9.6.2.2 描述了标准 14(又名 Base 14)字体,每个 PDF 渲染器都需要了解并直接或通过适当的替代品提供这些字体。 此外,渲染器应该知道它们的指标,这将使我们(现在)不必从字体程序中确定这些值并将它们合并到字体字典中。 我们示例中的对象 #4 非常小,因为它使用了其中一种字体 (Helvetica)。 标准字体的完整列表是:
- Times-Roman
- Times-Bold
- Times-Italic
- Times-BoldItalic
- Helvetica
- Helvetica-Bold
- Helvetica-Oblique
- Helvetica-BoldOblique
- Courier
- Courier-Bold
- Courier-Oblique
- Courier-BoldOblique
- Symbol
- ZapfDingbats
为其中一种字体创建字体字典时,只有三个必需键:Type(值为 Font)、Subtype(值为 Type1)和 BaseName(值为前面列表中的一个值)。
您可能已经注意到,其中一些字体实际上包含您通常认为的样式(例如粗体或斜体)。 但是,在处理 PDF 时,没有样式,只有字体。 因此,如果您希望 Times 字体显示为斜体,则需要使用 Times-Italic 字体。
示例 4-2 是使用几种不同字体的“Hello World”的变体。
Example 4-2. “Font World” (four different fonts)
9 0 obj
<<
/Type/Page
/Contents 24 0 R
/MediaBox[0 0 612 792]
/Parent 5 0 R
/Resources 13 0 R
>>
endobj
13 0 obj
<<
/Font <<
/F1 14 0 R
/F2 13 0 R
/F3 12 0 R
/F4 11 0 R
>>
>>
endobj
14 0 obj
<<
/Type /Font
/Subtype /Type1
/BaseFont/Helvetica
>>
endobj
13 0 obj
<<
/Type /Font
/Subtype /Type1
/BaseFont/Symbol
>>
endobj
12 0 obj
<<
/Type /Font
/Subtype /Type1
/BaseFont/Courier-Bold
>>
endobj
11 0 obj
<<
/Type /Font
/Subtype /Type1
/BaseFont/Times-Italic
>>
endobj
24 0 obj
<</Length 182>>
stream
BT
/F1 48 Tf
1 0 0 1 10 100 Tm
(Hello World)Tj
0 50 Td
/F2 48 Tf
(Hello World)Tj
0 50 Td
/F3 48 Tf
(Hello World)Tj
0 50 Td
/F4 48 Tf
(Hello World)Tj
ET
endstream
endobj
Encodings
到目前为止,我们使用的文本都是简单的英文文本。 然而,PDF 将与标准 14 字体关联的文本视为标准编码,它是 ISO 32000-1:2008, D.2 中定义的 ISO Latin-1 (ISO 8859-1) 的子集。 如果您的 PDF 中的所有文本都可以用该编码表示,那么您就可以开始了。 然而,大多数人至少需要完整的 Latin-1 来表示其他基于罗马/拉丁语的语言(例如法语、西班牙语或德语)使用的其他标准字符。 要使用它们,您需要向字体字典添加显式编码,并像您所做的那样继续使用简单的文本字符串。
下面是使用 WinAnsiEncoding(也称为 Windows 代码页 1252)以其他语言写出一些文本的示例。
示例 4-3。 用其他语言绘制文本

14 0 obj
<<
/Type /Font
/Subtype /Type1
/BaseFont/Helvetica
/Encoding/WinAnsiEncoding
>>
endobj
24 0 obj
<</Length 182>>
stream
BT
/F1 48 Tf
1 0 0 1 10 100 Tm
(English)Tj
0 50 Td
/F2 48 Tf
(Français)Tj
0 50 Td
/F3 48 Tf
(Español)Tj
ET
endstream
endobj
为了支持任意非拉丁语系语言,有必要使用嵌入式字体,本书这一版没有涉及这个主题。
可以使用非嵌入字体支持 PDF 中的中文、日文和韩文 (CJK) 文本,但需要查看 PDF 的用户在其计算机上安装额外的字体。 我们不会介绍如何执行此操作,因为不推荐这样做。
Text State
现在您已经很好地掌握了字体和字形,让我们看看如何使用它们在页面上实际绘制文本(示例 4-4)。
示例 4-4。 Hello World.pdf 的部分内容
1 0 obj
<<
/Type /Page
/Parent 5 0 R
/MediaBox [ 0 0 612 792 ]
/Resources 3 0 R
/Contents 2 0 R
>>
endobj
2 0 obj
<< /Length 53 >>
stream
BT
/F1 24 Tf
1 0 0 1 260 600 Tm
(Hello World)Tj
ET
endstream
endobj
如果您检查对象 #2 处的内容流,您将看到五个您以前从未见过的新运算符。 第一个,BT,单独出现在第一行(即没有操作数)。 正如您可能猜到的那样,它代表“开始文本”,需要描述一系列与文本相关的说明。 它与 ET(结束文本)运算符配对,可以在内容流的最后一行看到。
正如 PDF 具有图形状态(有关更多信息,请参见第 36 页的“图形状态”),它也具有包含所有与文本绘图相关的属性的文本状态。 BT/ET 配对声明一个新的文本状态然后将其清除,就像 q 和 Q 处理图形状态一样。 但是,没有推送/弹出。 事实上,不允许嵌套 BT/ET 对。
Font and Size
虽然文本状态中有许多属性,您将在此处查看一些属性,但最重要的三个是要使用的字体、文本大小和放置文本的位置。
Tf 运算符指定字体资源的名称,即当前资源字典的字体子字典中的一个条目。 该条目的值是一个字体字典(请参阅第 66 页的“字体字典”)。 在前面的示例中,字体名为 F1,如果您回过头来参考图 4-1,您会发现它出现在对象 #3 的字体资源中。
正如您在第 42 页的“转换”中了解到的,PDF 使用通用的“用户单位”概念来定义对象的大小和位置。 在 PDF 中,标准字形大小在用户空间中是 1 个单位,紧密间隔的文本行的标称高度也是 1 个单位。 因此,为了以特定大小绘制字形,您需要对其进行缩放。 比例因子被指定为Tfoperator的第二个操作数,从而设置图形状态下的文本字体大小参数。 在我们的示例中,字体大小为 24。
还有第二种设置字形比例因子的方法,这类似于其他图形对象的缩放方式——使用变换矩阵。 对于特定于文本的转换,您可以使用 Tm 运算符,它采用与我们在第 2 章中看到的 cm 运算符相同的参数。在我们的示例中,没有发生额外的缩放,但文本被定位在 (260,600)。 这是为要绘制的第一个字形设置缩放比例和位置的常规方法。 但是,也可以这样做:
/F1 1 Tf
24 0 0 24 260 600 Tm
(Hello World)Tj
一种方法比另一种更好吗? 在现代系统和当前实现中,差异应该是无法区分的。 如果您正在尝试尽可能最好地实现您的内容,这将取决于字体的使用方式。 如果您仅使用单一大小的文本(在给定页面上),则最好将比例因子用作 Tf 的一部分,因为这样字形将由字体加载器预先缩放。 但是,如果您在页面上以多种尺寸使用相同的字体,那么以 1 个单位加载并每次使用 Tm 进行缩放可能是最佳选择——但前提是您经常来回切换。 否则,只需使用第二个 Tf 创建字体的第二个实例,如示例 4-5 所示。
示例 4-5。 在big text和little text中绘图

BT
/F1 24 Tf
1 0 0 1 100 150 Tm
(Big Text)Tj
/F1 12 Tf
1 0 0 1 100 100 Tm
(Small Text)Tj
ET
Rendering Mode
在第 39 页的“画家的模型”中,您了解到在 PDF 中绘制的路径可以根据结束路径描述的运算符(例如,f 与 S)进行填充、描边或两者兼而有之。 对于文本,不是使用不同的运算符,而是使用一个运算符 (Tr) 来设置文本呈现模式。 图 4-3 列出了可以与 Tr 一起使用的可能的操作数值以及它们对文本的影响。
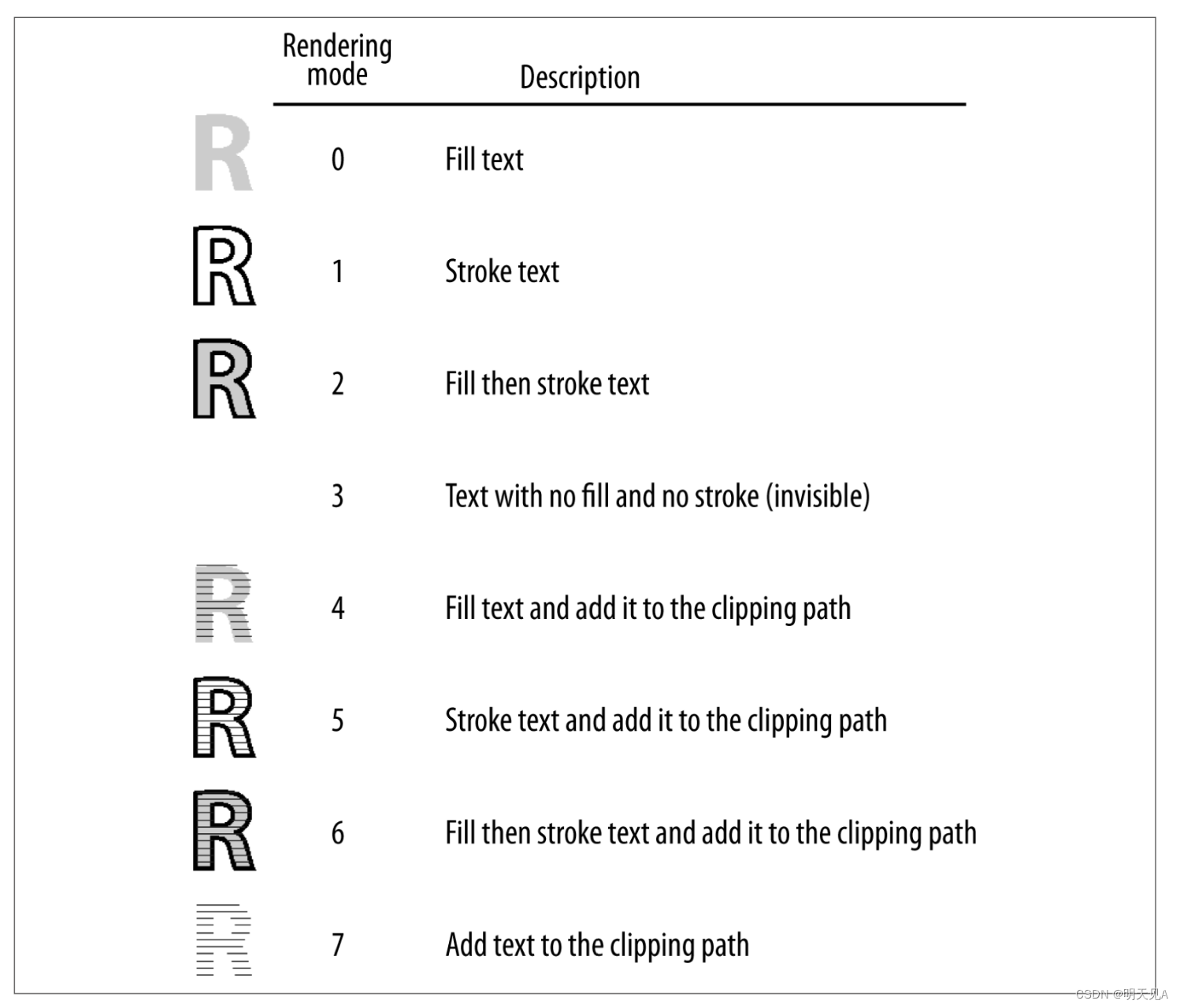
当您将渲染模式与您已知的图形状态属性结合使用时,您可以创建示例 4-6 中的文本。
示例 4-6 描边和填充文本

BT
/F1 80 Tf
1 0 0 1 100 100 Tm
1 0 0 RG
[2] 0 d
0.75 g
2 Tr
(ABC)Tj
ET
Drawing Text
如果您现在还没有弄清楚,Tj 运算符用于在页面上绘制文本(也称为“显示”字符串)。 这非常简单,因为操作符使 PDF 渲染器将第一个字形的“字形原点”与当前笔位置对齐并绘制字形。 然后渲染器将笔按字形的宽度前进到“下一个字形原点”并绘制下一个字形,以此类推整个字符串。
对于大多数文本呈现,这是完全可以接受的,也是大多数用户习惯于在屏幕上看到的。 但是,对于那些您希望更精确地控制字形定位的情况,您将需要使用 TJ 运算符。
许多字体包含有关如何更精确地将某些字形彼此相关的信息,称为字距调整。 但是,在绘制字符串时,Tj 运算符不支持这一点。
如果要使用该信息,您需要自己从字体中获取它,然后使用 TJ 运算符获得更具视觉吸引力的结果。
TJ 运算符不是将字符串作为操作数,而是采用数组。 该数组由一个或多个穿插有数字的字符串组成,其中数字用于调整文本位置 (Tm)。 数字以千分之一单位表示,该值是从当前水平坐标中减去的。
这意味着在默认坐标系中,正调整具有将下一个绘制的字形向左移动给定量的效果,而负调整会将下一个字形向右移动。
示例 4-7 显示了使用简单的 Tj 运算符绘制单词,并通过 TJ 手动调整字距。
示例 4-7 手动调整文本

BT
/F1 48 Tf
1 0 0 1 10 150 Tm
(AWAY)Tj
1 0 0 1 10 100 Tm
[ (A) 120 (W) 120 (A) 95 (Y) ] TJ
ET
Positioning Text
在前面的所有示例中,文本已使用 Tm 运算符显式定位。 然而,如果您只想在一个方向上移动笔(例如,向下到下一行,或向右移动),那将是一个相当重量级的操作。 对于更简单的运动,应使用 Td 运算符。 它有两个参数,tx 和 ty,代表如何在 X 和 Y 方向(分别)移动画笔。 如果任一参数为 0,则笔不会朝该方向移动。 示例 4-8 说明了使用 Td 绘制“4-square”。
示例 4-8 数字的“4 square”

BT
/F1 48 Tf
1 0 0 1 10 700 Tm
(1)Tj
0 -50 Td
(2)Tj
50 50 Td
(3)Tj
0 -50 Td
(4)Tj
ET
请记住,在 PDF 中,页面底部的 y 坐标为 0,因此要在页面下方绘制文本,请从高处开始并减去。
What’s Next
在本章中,您了解了字体和字形以及如何使用它们绘制文本。 接下来,您将从将内容放在页面上转变为使您的文档与导航功能更具交互性。