比赛的目标:本次竞赛的目标是评估8-12年级英语学习者(ELLs)的语言能力。利用英语学习者所写的论文数据集开发出能更好地支持所有学生的能力模型,帮助ELL学生在语言发展方面得到更准确的反馈,并加快教师的评分周期。
方法简介
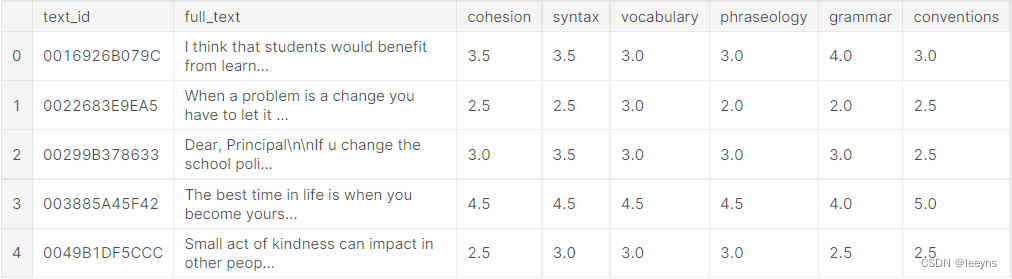
本次比赛是NLP的回归任务。模型的输入是8-12年级英语学习者的文本,输出的是针对cohesion, syntax, vocabulary, phraseology, grammar, conventions六个方面的打分。分数范围从1.0到5.0,增量为0.5。数据集的结构如下:
策略一:一般NLP任务的策略
本次比赛中最常见的策略是使用比如deberta等大规模预训练模型,对文本进行特征的提取,再提取特征的基础上进行回归任务。流程如下图所示,其中linear layers可以根据实验自行定义多层并加入不同的激活函数等。
假设batch size 为8.
策略二:SVR回归
通过预训练模型得到文本特征的embedding,再针对embedding训练SVR模型进行回归任务。使用SVR回归,可以利用不同的预训练模型得到不同的embedding,再利用这些embedding来做回归任务。这个策略在之前我没有怎么使用过,所以这里会提供一些代码。整体策略图如下:

代码如下:
# 首先得到word embeddings
for batch in tqdm(embed_dataloader_tr,total=len(embed_dataloader_tr)):
input_ids = batch["input_ids"].to(DEVICE)
attention_mask = batch["attention_mask"].to(DEVICE)
with torch.no_grad():
model_output = model(input_ids=input_ids,attention_mask=attention_mask)
sentence_embeddings = mean_pooling(model_output, attention_mask.detach().cpu())
# Normalize the embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
sentence_embeddings = sentence_embeddings.squeeze(0).detach().cpu().numpy()
all_train_text_feats.extend(sentence_embeddings)
all_train_text_feats = np.array(all_train_text_feats)
print('Train embeddings shape',all_train_text_feats.shape)
输出为:
Train embeddings shape (3911, 768)
这是由deberta base作为示例,这个输出是每一个样本最后的代表整个句子的embedding. 这样我们可以得到不同的模型输出的sentence embedding,将它们concatenate到一起,比如用2个不同的embedding size 均为768的模型。最后的输出则为 (3911, 768 * 2)
接下来训练SVR模型
from cuml.svm import SVR
import cuml
from sklearn.multioutput import MultiOutputRegressor
# 首先获取当前fold的训练数据和验证数据
train_folds = folds[folds['fold'] != fold].reset_index(drop=True)
valid_folds = folds[folds['fold'] == fold].reset_index(drop=True)
#得到对应的embeddings
train_folds_feats = all_train_text_feats[list(train_folds.index),:]
valid_folds_feats = all_train_text_feats[list(valid_folds.index),:]
clf = SVR(C=1)
"""
这里 C = 1是惩罚因子
表示错误项的惩罚系数C越大,即对分错样本的惩罚程度越大,因此在训练样本中准确率越高,但是泛化能力降低;相反,减小C的话,容许训练样本中有一些误分类错误样本,泛化能力强。对于训练样本带有噪声的情况,一般采用后者,把训练样本集中错误分类的样本作为噪声。
"""
# 依次训练针对不同Target的SVR
for i,t in enumerate(target_cols):
print(t,', ',end='')
clf = SVR(C=1)
clf.fit(train_folds_feats, dftr_[t].values)
ev_preds[:,i] = clf.predict(valid_folds_feats)
#############################################################################
# 或者定义multilabel_regressor,它可以直接训练出针对多输出的模型。
multilabel_regressor = MultiOutputRegressor(clf, n_jobs=-1)
multilabel_regressor.fit(train_folds_feats, train_folds[[t for t in CFG.target_cols]].values)
prediction = multilabel_regressor.predict(valid_folds_feats)









![[附源码]计算机毕业设计疫苗药品批量扫码识别追溯系统Springboot程序](https://img-blog.csdnimg.cn/a50133befbc849f58525cdf9da2911fc.png)