文章目录
- 线程池自查注意点
- 1、线程池的标准创建方式
- 2、线程池的任务调度流程
- 3、避免使用Executors快捷创建线程池
- 3.1、newSingleThreadExecutor()
- 3.2、newCachedThreadPool()
- 3.3、ScheduledThreadPool()
- 4、避免在方法中创建线程池
- 5、不要盲目使用同步队列
- 6、使用线程池,要确保ThreadLocal不会复用
线程池自查注意点
该记录首先将介绍线程池的基本概念,在介绍完之后再举例论证当前各项目中存在的线程池创建问题,用以自查。
1、线程池的标准创建方式
// 使用标准构造器构造一个普通的线程池
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数,即使线程空闲(Idle),也不会回收
int maximumPoolSize, // 线程数的上限
long keepAliveTime, TimeUnit unit, // 线程最大空闲(Idle)时长
BlockingQueue<Runnable> workQueue, // 任务的排队队列
ThreadFactory threadFactory, // 新线程的产生方式
RejectedExecutionHandler handler) // 拒绝策略
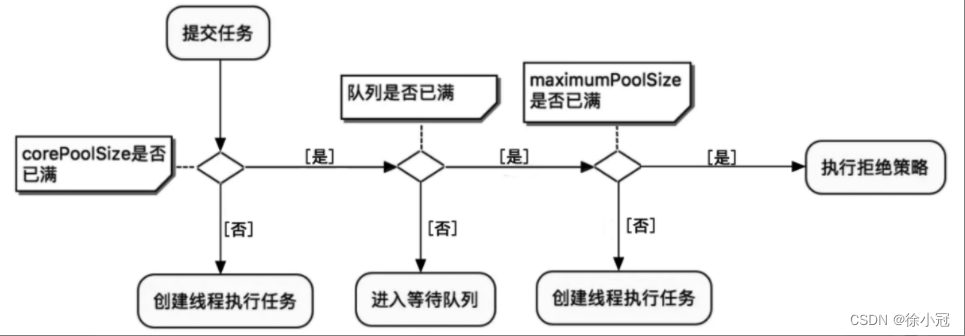
2、线程池的任务调度流程
(1)如果当前工作线程数量小于核心线程数量,执行器总是优先创建一个任务线程,而不是从线程队列中获取一个空闲线程。
(2)如果线程池中总的任务数量大于核心线程池数量,新接收的任务将被加入阻塞队列中,一直到阻塞队列已满。在核心线程池数量已经用完、阻塞队列没有满的场景下,线程池不会为新任务创建一个新线程。
(3)当完成一个任务的执行时,执行器总是优先从阻塞队列中获取下一个任务,并开始执行,一直到阻塞队列为空,其中所有的缓存任务被取光。
(4)在核心线程池数量已经用完、阻塞队列也已经满了的场景下,如果线程池接收到新的任务,将会为新任务创建一个线程(非核心线程),并且立即开始执行新任务。
(5)在核心线程都用完、阻塞队列已满的情况下,一直会创建新线程去执行新任务,直到池内的线程总数超出maximumPoolSize。如果线程池的线程总数超过maximumPoolSize,线程池就会拒绝接收任务,当新任务过来时,会为新任务执行拒绝策略。
调度流程图如下:
3、避免使用Executors快捷创建线程池
Executors工厂提供了4种快捷创建池的方法,这里将介绍为什么这几种线程池不能在生产环境直接使用,风险是哪些。
3.1、newSingleThreadExecutor()
public static ExecutorService newSingleThreadExecutor()
{
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(
1, // 核心线程数
1, // 最大线程数
0L, // 线程最大空闲(Idle)时长
TimeUnit.MILLISECONDS, //时间单位:毫秒
new LinkedBlockingQueue<Runnable>() //无界队列
));
}
使用该方法创建线程池所存在的问题在于使用的是无界队列,如果任务提交速度持续大于任务处理速度,就会造成队列大量阻塞。如果队列很大,很有可能导致JVM的OOM异常,甚至造成内存资源耗尽。FixedThreadPool()的潜在问题也是因此,不在赘述。
3.2、newCachedThreadPool()
public static ExecutorService newCachedThreadPool()
{
return new ThreadPoolExecutor(
0, // 核心线程数
Integer.MAX_VALUE, // 最大线程数
60L, // 线程最大空闲(Idle)时长
TimeUnit.MILLISECONDS, // 时间单位:毫秒
new SynchronousQueue<Runnable>() // 任务的排队队列,无界队列
);
}
以上代码通过调用ThreadPoolExecutor标准构造器创建一个核心线程数为0、最大线程数不设限制的线程池。所以,理论上“可缓存线程池”可以拥有无数个工作线程,即线程数量几乎无限制。“可缓存线程池”的workQueue为SynchronousQueue同步队列,这个队列类似于一个接力棒,入队出队必须同时传递,正因为“可缓存线程池”可以无限制地创建线程,不会有任务等待,所以才使用SynchronousQueue。
使用Executors创建的“可缓存线程池”的潜在问题存在于其最大线程数量不设限上。由于其maximumPoolSize的值为Integer.MAX_VALUE(非常大),可以认为可以无限创建线程,如果任务提交较多,就会造成大量的线程被启动,很有可能造成OOM异常,甚至导致CPU线程资源耗尽。
3.3、ScheduledThreadPool()
public ScheduledThreadPoolExecutor(int corePoolSize)
{
super(corePoolSize, // 核心线程数
Integer.MAX_VALUE, // 最大线程数
0, // 线程最大空闲(Idle)时长
NANOSECONDS,//时间单位
new DelayedWorkQueue() //任务的排队队列
);
}
使用Executors创建的“可缓存线程池”的潜在问题存在于其最大线程数量不设限上。由于其线程数量不设限,如果到期任务太多,就会导致CPU的线程资源耗尽。
4、避免在方法中创建线程池
一般我们可以交由spring管理构建单例的线程池bean,或者是成为类的静态成员,总之,让线程池在系统中作为单例存在提供服务即可,除非特殊需求,不考虑在方法中创建线程池。
除非是那种线程池开的太多占用了太多线程资源,才需要考虑动态的线程池创建和关闭,用以释放在空闲状态下的核心线程资源给其他的线程使用。原因是线程池的核心线程在空闲状态下,默认也是不会关闭的。
5、不要盲目使用同步队列
SynchronousQueue是一个比较特殊的阻塞队列实现类,SynchronousQueue没有容量,每一个插入操作都要等待对应的删除操作,反之每个删除操作都要等待对应的插入操作。也就是说,如果使用SynchronousQueue,提交的任务不会被真实地保存,而是将新任务交给空闲线程执行,如果没有空闲线程,就创建线程,如果线程数都已经大于最大线程数,就执行拒绝策略。使用这种队列需要将maximumPoolSize设置得非常大,从而使得新任务不会被拒绝。
列举一个例子
private Integer defaultExePoolSize = 30;
private ThreadPoolExecutor executor = new ThreadPoolExecutor(defaultExePoolSize, defaultExePoolSize, 0L, TimeUnit.MILLISECONDS,
new SynchronousQueue<Runnable>(),
new ThreadFactoryBuilder().setNameFormat("Livelihood-gate-writeoff-call-back-%d").build(),
new ThreadPoolExecutor.CallerRunsPolicy());
该线程池创建了一个核心线程数和最大线程数都为30的线程池,因为核心资源已经分配的够多了,其实占用了很多的系统线程资源。一般情况下我们使用线程池是为了异步去处理一些任务,从而提升系统的性能。但是该线程使用的是同步队列,则会造成什么影响呢?
只需要每秒30的并发,就可以让线程池进入拒绝状态,然而这是一处老代码了,为什么一直没有出问题是因为线程的拒绝策略选择的是调用者执行策略,即将原本应该异步处理的任务变为同步执行,虽然不会出问题,但是与使用线程池提升系统性能的初衷已经背道而驰了。
往往使用同步队列的场景,其最大线程数都取得是Integer最大值,这就需要大家考虑,因为并发请求太高而创建了大量线程造成cpu计算资源耗尽的风险。
6、使用线程池,要确保ThreadLocal不会复用
在早期的JDK版本中,ThreadLocal的内部结构是一个Map,其中每一个线程实例作为Key,线程在“线程本地变量”中绑定的值为Value(本地值)。早期版本中的Map结构,其拥有者为ThreadLocal,每一个ThreadLocal实例拥有一个Map实例。
在JDK 8版本中,ThreadLocal的内部结构发生了演进,虽然还是使用了Map结构,但是Map结构的拥有者已经发生了变化,其拥有者为Thread(线程)实例,每一个Thread实例拥有一个Map实例。另外,Map结构的Key值也发生了变化:新的Key为ThreadLocal实例。
在JDK 8版本中,每一个Thread线程内部都有一个Map(ThreadLocalMap),如果给一个Thread创建多个ThreadLocal实例,然后放置本地数据,那么当前线程的ThreadLocalMap中就会有多个“Key-Value对”,其中ThreadLocal实例为Key,本地数据为Value。
这里为什么map的持有者会发生变化,是因为,如果map的持有者是ThreadLocal,那么当线程消亡时,ThreadLocal中依然存在着改条记录,每个ThreadLocal中的map大小与线程数量成正相关
因为ThreadLocalMap拥有者变成了线程,这个map的key是ThreadLocal实例,value,是存储的值,ThreadLocalMap是会随着任务的结束而消亡,但是如果在线程池中,线程复用,这就会造成任务已经结束了,但是线程没有消亡,上一个任务的ThreadLocal依然保留下来了,因此,使用ThreadLocal去保存变量时,应该保证在线程任务完成时,通过钩子函数清空其ThreadLocal。
创建线程池里可以重写以下方法。
//任务执行之前的钩子方法(前钩子)
protected void beforeExecute(Thread t, Runnable r) { }
//任务执行之后的钩子方法(后钩子)
protected void afterExecute(Runnable r, Throwable t) { }
//线程池终止时的钩子方法(停止钩子)
protected void terminated() { }
后钩子)
protected void afterExecute(Runnable r, Throwable t) { }
//线程池终止时的钩子方法(停止钩子)
protected void terminated() { }
还记得为啥咱们的api实现类都有一个MDC.clear()吗?因为MDC就封装了几个ThreadLocal类型的属性,比如日志id,并且Tomcat也是通过线程池去调度任务的,tomcat的线程池没有提供在任务完成时清空其threadLocal,因此我们才需要在finally块中去清空。









![[附源码]计算机毕业设计疫苗药品批量扫码识别追溯系统Springboot程序](https://img-blog.csdnimg.cn/a50133befbc849f58525cdf9da2911fc.png)