文章目录
- 前言
- 零、组合优化问题基础
- 1. 定义
- (1)定义
- (2)常见问题
- 2. 方法
- (1)精确方法
- (2)近似方法
- (3)深度学习方法
- 3. 文章架构
- 一、概述
- 1. 神经网络
- (1)Hopfield 网络
- (2)指针网络Ptr-Net
- (3)图神经网络
- 3. 深度强化学习DRL
- (1)端到端方法
- (2)改进传统方法
- 二、原理
- 1. Pointer Network
- (1)求解TSP问题
- (2)Attention机制
- 2. Pointer Network+DRL
- (1)求解TSP问题
- (2)REINFORCE强化学习算法
- 3. 图神经网络
- (1)图定义
- (2)经典GNN
- 三、理论与方法
- 1. 基于DRL的端到端算法
- (1)基于Pointer Network-Seq2Seq
- (2)基于Pointer Network-Transformer
- (3)基于图神经网络
- 2. 基于DRL的局部搜索改进算法
- 3. 基于DL的多目标组合优化算法
- 4. 总结对比
- 四、应用综述
- 1. 网络与通信领域
- (1)资源分配
- (2)拓扑与路由优化
- (3)计算迁移
- 2. 其他领域
- (1)交通领域
- (2)生产制造领域
- (3)高性能计算领域
- (4)微电网能量管理领域
- 五、发展与展望
- 1. 模型方面
- 2. 研究对象方面
- 3. 深度强化学习训练算法方面
- 4. 工程实际方面
- 总结
前言
此文为文献阅读笔记。
[1]李凯文, 张涛, 王锐, 覃伟健, 贺惠晖, & 黄鸿. (2021). 基于深度强化学习的组合优化研究进展. 自动化学报, 47(11), 17.
零、组合优化问题基础
1. 定义
(1)定义
组合优化问题 (Combinatorial optimization problem, COP)是一类在离散状态下求极值的最优化问题。
(2)常见问题
旅行商问题(Traveling salesman problem, TSP)、
车辆路径问题 (Vehicle routing problem, VRP)、
车间作业调度问题 (Job-shop scheduling)、
背包问题 (Knapsack)、
最小顶点覆盖问题 (Minimum vertex cover, MVC)、
最小支配集题 (Minimum dominating problem, MDP) 等。
2. 方法
(1)精确方法
精确方法 (Exact approaches)采用分而治之的思想通过将原问题分解为子问题的方式进行求解,通过不断迭代求解得到问题的全局最优解。
分支定界法 (Branch and bound)
动态规划法 (Dynamic programming)
(2)近似方法
可以求解局部最优解的方法
近似算法 (Approximate algorithms)
贪心算法、局部搜索算法、线性规划和松弛算法、序列算法。
启发式算法 (Heuristic algorithms)
模拟退火算法、禁忌搜索、进化算法(如遗传算法, 差分进化算法等)、蚁群优化算法、粒子群算法、迭代局部搜索、变邻域搜索等。
(3)深度学习方法
深度神经网络 (Deep neural networks, DNN)
自动地对图像的特征进行学习
深度强化学习 (Deep reinforcement learning, DRL)
根据当前的环境状态做出动作选择, 并根据动作的反馈不断调整自身的策略, 从而达到设定的目标
3. 文章架构
第 1 节概述:对其产生、历史发展、方法分类以及优缺点进行了介绍;
第 2 节基本原理进行介绍;
第 3 节方法综述: 根据方法的不同类别, 对各个算法的原理、优缺点和优化性能进行了对比介绍;
第 4 节应用研究;
第 5 节总结.
一、概述
1. 神经网络
(1)Hopfield 网络
学习并解决单个小规模TSP问题实例。
(2)指针网络Ptr-Net
监督式学习的方式训练该网络并在 TSP问题上取得了较好的优化效果,可以非迭代搜索求解。
(3)图神经网络
与指针网络模型不同的是, 该类方法采用图神经网络对每个节点的特征进行学习
3. 深度强化学习DRL
(1)端到端方法
给定问题实例作为输入, 利用训练好的深度神经网络直接输出问题的解。
求解速度快、泛化能力强,但最优性很难保证。
(2)改进传统方法
求解速度仍然远不及端到端方法。
二、原理
1. Pointer Network
利用编码器 (Encoder) 对组合优化问题的输入序列进行编码得到特征向量, 再利用解码器 (Decoder) 结合Attention 计算方法以自回归 (Autoregressive) 的方式逐步构造解
(1)求解TSP问题
以求解TSP问题为例:
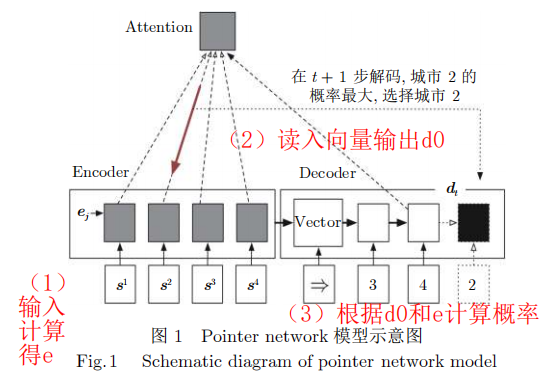
输入为城市坐标,输出为城市的顺序。
(2)Attention机制
u
j
t
=
v
T
tanh
(
W
1
e
j
+
W
2
d
t
)
,
j
∈
(
1
,
⋯
,
n
)
P
(
ρ
t
+
1
∣
ρ
1
,
⋯
,
ρ
t
,
X
t
)
=
softmax
(
u
t
)
\begin{aligned} & u_j^t=\boldsymbol{v}^{\mathrm{T}} \tanh \left(\boldsymbol{W}_1 \boldsymbol{e}_j+\boldsymbol{W}_2 \boldsymbol{d}_t\right), j \in(1, \cdots, n) \\ & P\left(\rho_{t+1} \mid \rho_1, \cdots, \rho_t, X_t\right)=\operatorname{softmax}\left(\boldsymbol{u}^t\right) \end{aligned}
ujt=vTtanh(W1ej+W2dt),j∈(1,⋯,n)P(ρt+1∣ρ1,⋯,ρt,Xt)=softmax(ut)
·
d
t
\boldsymbol{d}_t
dt 译码器当前计算得到的隐状态
·
e
e
e 编码器计算得到的隐状态
·
t
t
t 为第t步
·
W
\boldsymbol{W}
W 和
v
\boldsymbol{v}
v 均为神经网络的参数
·
j
j
j 第j个城市节点
·
u
j
t
u_j^t
ujt 代表在第
t
t
t 步解码过程中选择城市
j
j
j 的概率,
在每一步解码过程中, 对于每个城市 j j j, 均可以计算得到其 u j t u_j^t ujt值,此时可以选择具有最大概率值的节点添加到解当中, 按照该方式不断选择城市, 直至构造得到一个完整解.
2. Pointer Network+DRL
强化学习通过试错机制不断训练得到最优策略, 首先需要将组合优化问题建模为马尔科夫过程,其核心要素为状态、动作以及反馈。
(1)求解TSP问题
以TSP问题为例:
p
θ
(
π
∣
s
)
=
∏
n
t
=
1
p
θ
(
π
t
∣
s
,
π
1
:
t
−
1
)
p_\theta(\pi \mid s)=\prod_n^{t=1} p_\theta\left(\pi_t \mid s, \pi_{1: t-1}\right)
pθ(π∣s)=n∏t=1pθ(πt∣s,π1:t−1)
·状态
s
s
s为城市的坐标以及已经访问过的城市
·动作为第
t
t
t 步选择的城市
π
t
\pi_t
πt, 所有动作组成的城市访问顺序
π
\pi
π 即为组合优化问题的解
·反馈
r
r
r 是路径总距离的负数, 即最小化路径长度
·策略即为状态
s
s
s 到动作
π
\pi
π 的映射, 策略通常为随机策略, 即得到 的是选择城市的概率
p
θ
(
π
∣
s
)
p_\theta(\pi \mid s)
pθ(π∣s)
(2)REINFORCE强化学习算法
又名 基于蒙特卡洛的策略梯度方法:不断执行动作直到结束, 在一个回合结束之后计算总反馈, 然后根据总反馈对策略的参数进行更新
以TSP问题为例,总反馈为总路径长度的负数
−
L
(
π
)
-L(\pi)
−L(π)
∇
L
(
θ
∣
s
)
=
E
p
θ
(
π
∣
s
)
[
(
L
(
π
)
−
b
(
s
)
)
∇
ln
p
θ
(
π
∣
s
)
]
θ
←
θ
+
∇
L
(
θ
∣
s
)
\begin{aligned} & \nabla \mathcal{L}(\theta \mid s)= \mathrm{E}_{p_\theta(\pi \mid s)}\left[(L(\pi)-b(s)) \nabla \ln p_\theta(\pi \mid s)\right] \\ & \theta \leftarrow \theta+\nabla \mathcal{L}(\theta \mid s) \end{aligned}
∇L(θ∣s)=Epθ(π∣s)[(L(π)−b(s))∇lnpθ(π∣s)]θ←θ+∇L(θ∣s)
·
p
θ
(
π
∣
s
)
p_\theta(\pi \mid s)
pθ(π∣s) 为每步动作选择概率的累乘, 则
ln
p
θ
(
π
∣
s
)
\ln p_\theta(\pi \mid s)
lnpθ(π∣s) 计算为每步动作选择概率对数的求和, 以该值对参数
θ
\theta
θ 计算偏导可得梯度值
∇
ln
p
θ
(
π
∣
s
)
\nabla \ln p_\theta(\pi \mid s)
∇lnpθ(π∣s)
·
(
L
(
π
)
−
b
(
s
)
)
(L(\pi)-b(s))
(L(π)−b(s)) 决定了梯度下降的方向
·
b
(
s
)
b(s)
b(s) 代表策略的平均表现 (Baseline), 如果当前策略的表现比 “平均”好, 则对该策略进行正向激励, 反之亦然
·有多种方式对 b ( s ) b(s) b(s) 进行估计, 运用较多的方法是新增一个 Critic 神经网络计算 b ( s ) b(s) b(s), 即给定 一个 TSP 问题 s s s, 利用 Critic 神经网络估计该问题解的路径长度. Critic 网络与策略网络同步进行训练, 以策略网络训练过程中产生的 ( s , L ( π ) ) (s, L(\pi)) (s,L(π)) 作为训练集对 Critic 进行训练
3. 图神经网络
根据每个节点的原始信息 (如城市坐标) 和各个节点之间的关系 (如城市之间的距离), 利用图神经网络方法计算得到各个节点的特征向量, 根据各个节点的特征向量进行节点预测、边预测等任务
(1)图定义
图一般被定义为:
G
=
(
V
,
E
)
G=(V, E)
G=(V,E)
·
V
V
V为节点集合
·
E
E
E为边集合
不断学习节点的、邻居节点、边的特征,并进一步聚合,得到每个节点的特征向量,根据各个节点的特征向量完成预测、分类等任务
(2)经典GNN
以经典GNN为例:
h v ( t ) = ∑ u ∈ N ( v ) f ( x v , x ( v , u ) e , x u , h u ( t − 1 ) ) \boldsymbol{h}_v^{(t)}=\sum_{u \in N(v)} f\left(\boldsymbol{x}_v, \boldsymbol{x}_{(v, u)}^e, \boldsymbol{x}_u, \boldsymbol{h}_u^{(t-1)}\right) hv(t)=u∈N(v)∑f(xv,x(v,u)e,xu,hu(t−1))
·
h
v
(
t
)
\boldsymbol{h}_v^{(t)}
hv(t) 代表节点
v
v
v 的表征向量
·
N
(
v
)
N(v)
N(v) 代表
v
v
v 的邻居节点的集合
·
x
v
x_v
xv 是节点
v
v
v 的特征
·
x
(
v
,
u
)
e
x_{(v, u)}^e
x(v,u)e 是与
v
v
v 相连的边的特征
·
x
u
x_u
xu 是邻居节点
u
u
u 的特征
·
h
u
(
t
−
1
)
\boldsymbol{h}_u^{(t-1)}
hu(t−1) 是邻居节点
u
u
u 在上一步更新的特征向量
因此该公式根据节点 v v v 本身的特征、边的特征以及邻居节点 的特征对节点 v v v 的表征向量进行更新, 从 t = 0 t=0 t=0 开始 对不断对 h v ( t ) \boldsymbol{h}_v^{(t)} hv(t) 进行更新直到收敛, 从而得到节点 v v v 的准确特征向量
然后可以以一个全连接层神经网络映射到一个选择概率(如计算Q值的方式)。
三、理论与方法
1. 基于DRL的端到端算法
(1)基于Pointer Network-Seq2Seq
Vinyals 等
采用深度监督学习,得到的解的质量不会超过样本的解的质量。细节如上文所述。
Bello 等
以目标函数作为反馈;
采用REINFORCE强化学习算法进行训练;
引入Critic网络作为Baseline以降低训练方差;
超越了监督学习
Nazari 等
将输入分为静态(顾客位置)动态(顾客需求)两部分;
将编码器的输入层LSTM换位一维卷积层,降低计算成本;
速度更快,效果相当
(2)基于Pointer Network-Transformer
Transformer 的 Multi-head attention 机制可以使模型更好地提取问题的深层特征。
Deudon 等
借鉴Transformer改进指针网络;
编码层采用了与Transformer模型多头结构;
解码层将LSTM改为近三步的决策进行线性映射得到参考向量;
有效提高TSP的解质量
Kool 等
编码层采用了与Transformer模型多头结构;
解码层的解码过程中考虑的是第一步所做的决策和最近两步的决策;
Self-attention 计算方法;
文章设计了一种 Rollout baseline 来代替 Critic 神经网络;
贪婪策略;
在众多问题上,性能超越了以上所有前者,接近最优解
Ma 等
图指针网络 (Graph pointer network, GPN);
编码器包含两部分: Point encoder 以及 Graph encoder;
Point encoder 对城市坐标进行线性映射, 并输入到 LSTM中得到每个城市的点嵌入;
Graph encoder 通过 GNN 图神经网络对所有城市进行编码, 得到每个城市的图嵌入;
引入 Vector context 提高模型的泛化能力;
章采用分层强化学习方法 (Hierarchical RL, HRL) 对模型进行训练;
在求解大规模问题上表现更加优秀,小规模上则劣于Kool的方法
(3)基于图神经网络
Dai 等
利用structure2vec图神经网络进行建模;
计算Q值并采用贪婪策略;
采用深度 Q 学习 (Deep Q-learning, DQN) 算法对该图神经网络的参数进行训练;
TSP问题求解效果接近Bello的方法,其他问题也得到了接近最优化的解
Mittal 等
模型架构与Dai一样;
采用图卷积神经网络(GCN);
用于求解最大覆盖问题(MCP)、MVC问题等表现更加优秀
Li 等
与 TSP 问题不同, 对节点选择的顺序无要求;
使用 GCN 图神经网络直接输出所有点选择概率的估计值, 并基于该估计值以引导树搜索的方式构造可行解;
采用 Hindsight loss 方式输出多个概率分布, 在此基础上进行树搜索, 并采用局部搜索的方式对解进行再处理;
用于求解最小顶点覆盖问题、最大独立点集 (Maximal independent set, MIS)、极大团 (Maximal clique, MC)、适定性问题 (Satisfiability)
基于指针网络的方法适合有序列特性的组合优化问题,而图神经网络待解决的问题有无序列特性都可以。

2. 基于DRL的局部搜索改进算法
Chen 等
基于深度强化学习的组合优化问题搜索模型 NeuRewriter;
其策略由两部分构成: Region-picker 和 Rule-picker;
章利用 Actor-critic 方法对 Region-picker 和 Rule-picker 策略进行了训练;
其优化效果在作业车间调度问题上超越了 DeepRM和 Google OR-tools 求解器, 在 VRP 问题上超越了 Google OR-tools 求解器
Yolcu 等
利用深度强化学习对局部搜索中变量选择算子进行学习;
采用图神经网络对变量选择的策略进行参数化;
利用 REINFORCE 算法更新图神经网络的参数;
更少的步数内找到最优解,但时间更长
Gao 等
利用深度强化学习方法对大规模邻域搜索的 Destroy 和 Repair 算子进行学习;
采用图注意力神经网络 (Graph attention network) 对问题特征进行编码;
采用基于循环神经网络的解码器输出 Destroy 和 Repair 算子;
在解决CVRP问题上超越了Kool的方法
Lu 等
提出了Learn to improve (LSI)方法;
采用局部搜索的方式;
采用了 9 种不同的提升算子作为算子库;
采用深度强化学习训练提升算子的选择策略;
每次迭代, 算法根据问题特征和当前的解, 利用学习到的策略从算子库中选择提升算子
效果和速度都堪称一绝

3. 基于DL的多目标组合优化算法
Li 等
DRL-MOA;
借鉴 Pointer network 模型采用端到端的求解框架, 采用基于分解的思想将多目标问题分解为多个子问题;
效率远高于传统算法,泛化性好
4. 总结对比
端到端模型具有求解速度远超传统优化算法的优势;
但是很难保证解的优化效果
强化学习训练方法收敛比监督式训练方法慢, 但强化学习得到的模型具有更强的泛化能力.
四、应用综述
具体文献及方法省略,详情见原文。
1. 网络与通信领域
(1)资源分配
将有限的 CPU、内存、带宽等资源分配给不同的用户或任务需求
(2)拓扑与路由优化
对路由策略、传感器的连接拓扑进行优化, 以降低通信时延和成本
(3)计算迁移
通过将部分计算任务从本地迁移到远程设备以解决移动终端资源受限问题的一个有效途径
2. 其他领域
(1)交通领域
货物配送、城际交通规划、网约车(订单分配和四级载客区域)等
(2)生产制造领域
车间工作流调度等
(3)高性能计算领域
人工智能模型的训练是一个耗时极长的任务,合理地对计算资源进行规划和调度能够有效提高计算效率
(4)微电网能量管理领域
用电、储能等设备的启停控制;光伏发电、储氢装置、蓄电池的孤岛型复合能源系统;楼宇的智能能量管理等等
五、发展与展望
来基于深度强化学习的组合优化方法在多种组合优化问题上展示出了良好性能, 具有较强的泛化性能和快速的求解速度
1. 模型方面
直接采用深度神经网络模型输出的解通常较差, 大部分文献都需要进一步通过波束搜索、局部搜索、采样策略等方式进一步提升解的质量。
如何有效结合图神经网络和 Attention 机制是一个较好的研究点。
目前的机构关系仅限于节点、边和邻居节点。能否根据图论,去探寻更深层次的结构关系呢?
2. 研究对象方面
多目标优化、约束优化问题
3. 深度强化学习训练算法方面
目前对端到端模型的训练大多采用 REINFORCE、DQN 等传统训练算法, 具有采样效率低、收敛慢等缺陷, 如何根据组合优化问题的特性设计更加高效的强化学习训练算法
4. 工程实际方面
探索解决工程实际上的问题

![[附源码]计算机毕业设计JAVA学习资源共享与在线学习系统](https://img-blog.csdnimg.cn/78b0e29b6e2e43c2a0f15078d9b92b18.png)