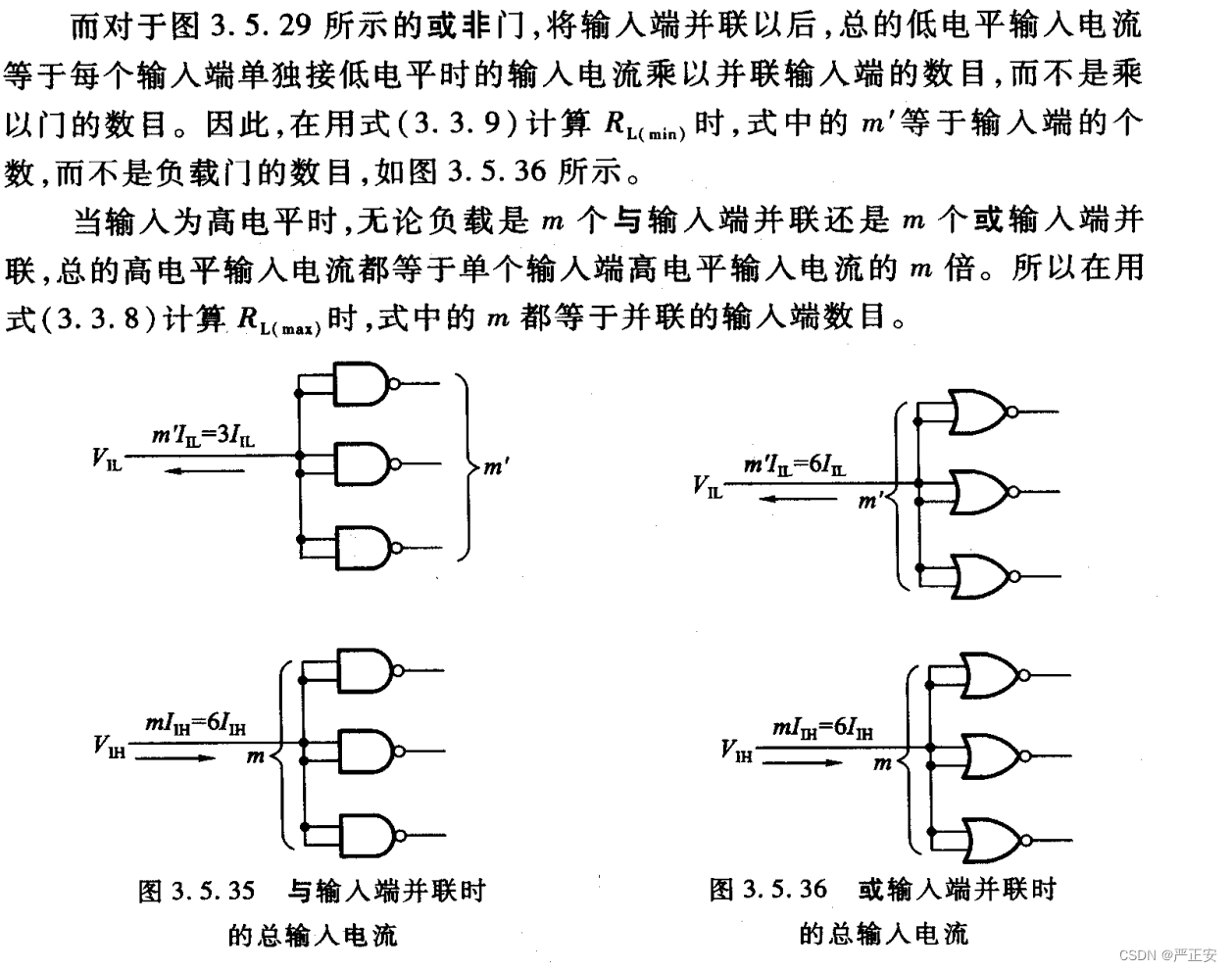
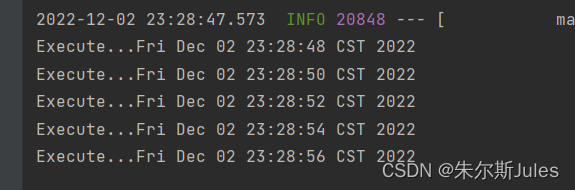
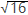现象
bt的堆栈信息
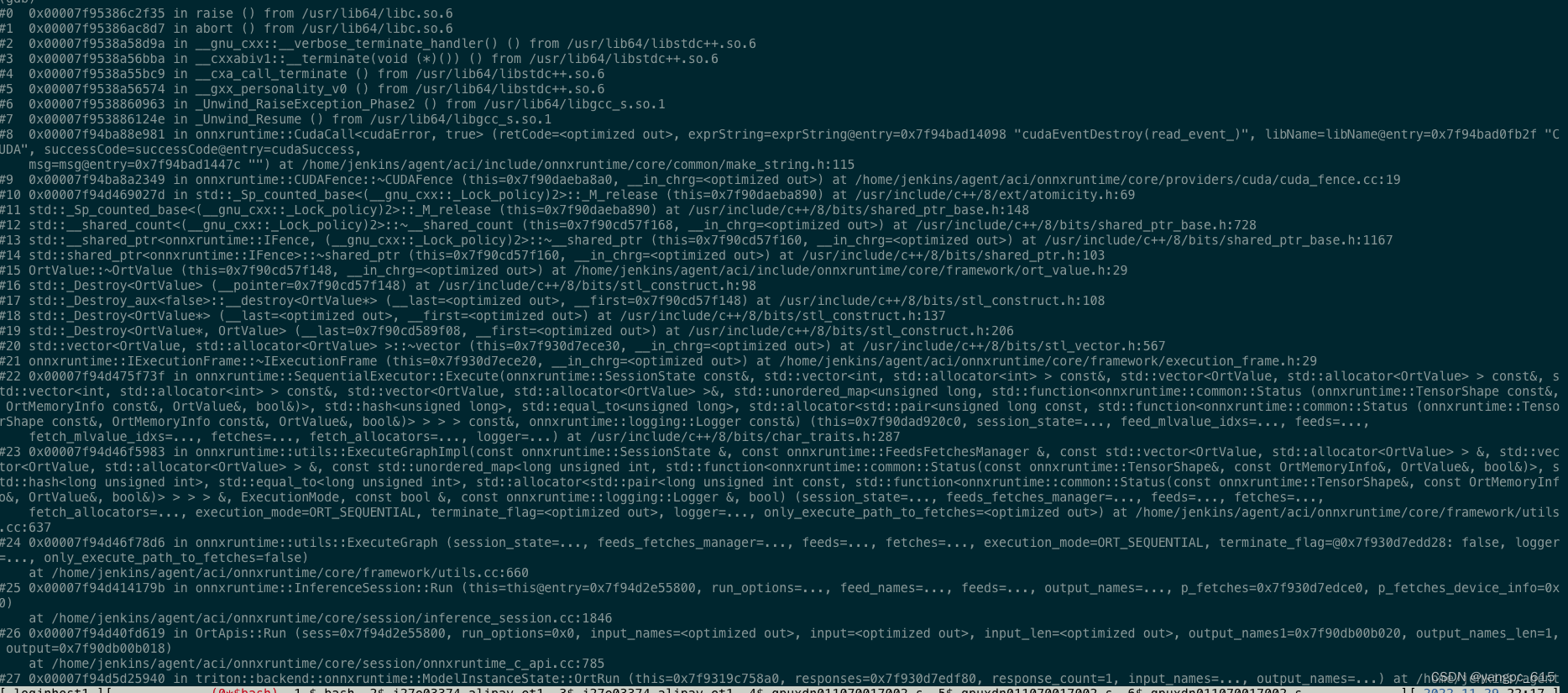
standard io上的错误输出

从报错信息上看是非法的内存访问,但是报错的位置不一定是真实的位置,因为GPU都是异步发起的,错误可能会被在后面的op捕捉。例如cudaEventDestory:
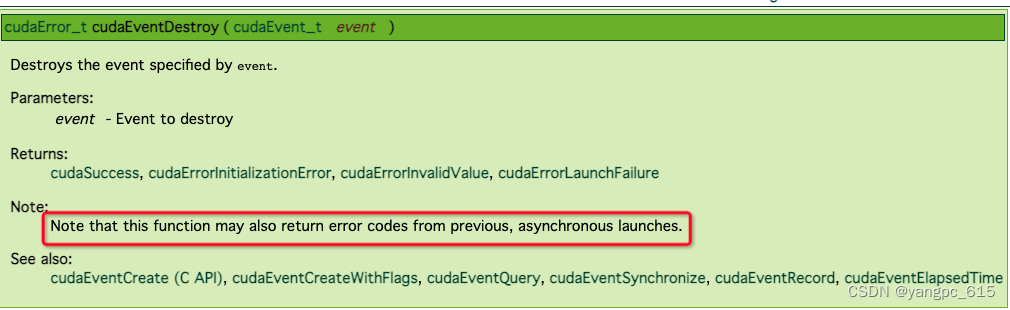
debug方式
思维方式
- 复现,解决问题一定要复现问题,不能复现的问题不能确定正真解决。所以首先要做的是复现。
- 定位,定位范围是逐渐缩小,优先排查自定义的代码。对于cuda-kernel,默认都是异步的操作,很多时候捕获错误的位置在抛出错误位置的后面。这种情况可以在可能出错的op后面加上下面代码:
CUDA_RETURN_IF_ERROR(cudaStreamSynchronize(stream));cuda-memcheck
命令行,使用cuda-memcheck的工具memcheck,当然它还有另外的三个工具,详情看文档。
cuda-memcheck --tool memcheck [application application-option]结果返回发生越界的thread号和block号。

然后通过block和thread的坐标信息,借助cuda-gdb工具,定位到具体的位置。
cuda-gdb
在编译时,给nvcc加上-g -G标识(cmake中是CMAKE_CUDA_FLAGS),就可以得到device的debug符号信息,其中的-G是标识开启device的debug编译。
set(CMAKE_CUDA_FLAGS "${CMAKE_CUDA_FLAGS} -g -G")Debug的操作指令:
# switch to the forced thread and block
cuda kernel 0 block (3,103,0) thread(0,0,0)
# condition breakpoint
b file:498 if blockIdx.y==103 && blockIdx.x==3
# set conditions for an existing breakpoint
condition 1 blockIdx.x == 0 && n > 3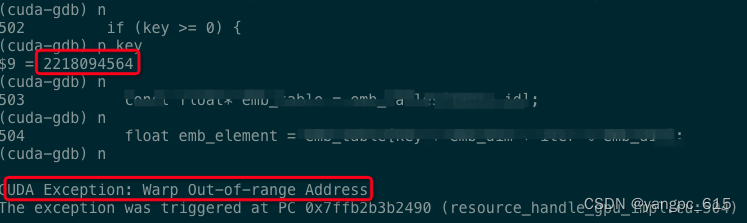
找到了具体越界的位置。
printf定位具体位置
对于代码比较简单,但是并发度很高的cuda-kernel-func,采用这个方式比较高效。但是需要注意:
- ort里的cuda代码默认是开启了O3的优化等级的。如果注释掉一些代码,相关的一些代码可能被优化掉。解决方法:把删除的代码中的变量,用printf加上,可以屏蔽这个优化,当然也可以开启nvcc的debug模式。
- cuda-kernel里的printf要注意数据的字节数,例如,int64的类型,在打印的时候需要加l(%ld),不然会引起错位,该字符串后面的输出,都会出现错误。
参考文档
https://on-demand.gputechconf.com/gtc/2014/presentations/S4580-cuda-gdb-cuda-memcheck-debugging-tools.pdf
https://ece.northeastern.edu/groups/nucar/Analogic/cuda-gdb.pdf

![[附源码]计算机毕业设计校园生活服务平台Springboot程序](https://img-blog.csdnimg.cn/9b7d66ed4ad04e8890f64ec54de6b142.png)